C/C++教程
使用 Easysearch 打造企业内部知识问答系统

大家可能都有这样的经历,刚入职一家企业时,同事往往会给你分享一些文档资料,有可能是产品信息、规章制度等等。这些文档有的过于冗长,很难第一时间找到想要的内容。有的已经有了新版本,但员工使用的还是老版本。
基于这种背景,我们可以利用 Easysearch 加 LLM 实现一个内部知识的 QA 问答系统。这个系统将利用 LangChain 框架调用本地部署的大模型和 Easysearch,实现理解员工的提问,并基于最新的文档,给出精准答案。
开发框架
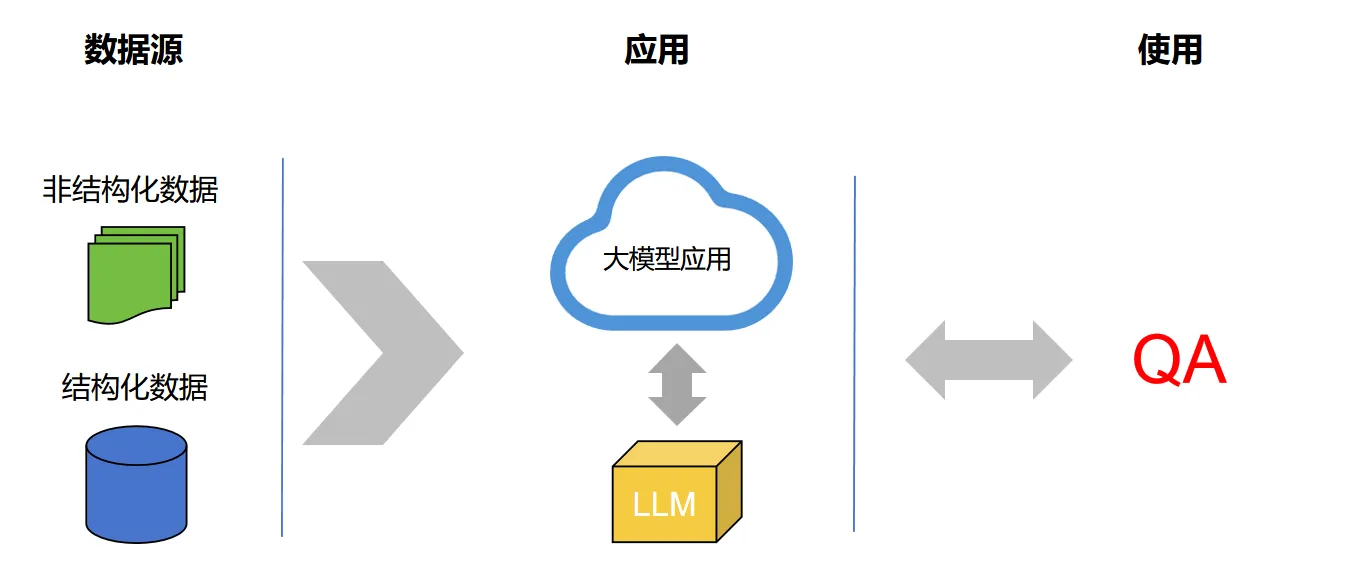
整个框架分为四个部分:
-
数据源:数据可以有很多种,可以是非结构化的,比如 PDF、docx、txt 等。也可以是结构化的数据,甚至代码也行。在本次示例中,我们使用 PDF 的非结构化数据。
-
大模型应用:应用与大模型交互,生成我们需要的答案。
-
大模型:系统执行相关任务需要用到的大模型,可以有多个。
-
Q&A 场景:基于大模型为引擎的 QA 场景,使用 web 框架,构建一个交互界面。
数据准备
本次我们使用的资料是 “INFINI 产品安装手册.pdf” ,文档部分内容展示如下:

首先我们使用 LangChain 的 document_loaders 来加载文件。document_loaders 集成了数百种数据源格式,可以很方便的加载数据。我们的数据的 pdf 格式的,导入 PyPDFLoader 类来进行处理。代码如下:
import os
# 导入 Document Loaders
from langchain_community.document_loaders import PyPDFLoader
# Load Pdf
base_dir = '.\\easysearch' # 文档的存放目录
docs = []
for file in os.listdir(base_dir):
file_path = os.path.join(base_dir, file)
if file.endswith('.pdf'):
loader = PyPDFLoader(file_path)
documents.extend(loader.load())
上面的代码将 pdf 文件的内容存储在 docs 这个列表中,以便后续进行处理。
文本分割
一个文件的文本内容可能很大,无法适应许多模型的上下文窗口,也不利于检索和存储。因此,通常我们会将文本内容分割成更小的块,这将帮助我们在运行时只检索文档中最相关的部分。LangChain 提供了工具来进行处理文本分割,非常方便。
我们将把文档分割成 1000 个字符的块,每个块之间有 200 个重叠字符。这种重叠有助于减少将语句与相关的重要上下文分离的可能性。
# 2.将Documents切分成块 from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=20) chunked_documents = text_splitter.split_documents(docs)
上面的代码将 docs 的内容按 1000 字符大小进行切分,存储在 chunked_documents 中,以便后续进行处理。
注意,实际运行中,切分及重叠的大小,都会影响应用效果,需自行调试。
向量库 Easysearch
接下来,我们将这些文本块转换成向量的形式,并存储在一个向量数据库中。在本示例中,我们使用 mxbai-embed-large 模型来生成向量,然后将向量和原始内容存入 easysearch 。
本地部署模型,我使用的是 ollama ,大家可以使用自己喜欢的工具。
# 3. 定义embedding模型 from langchain_community.embeddings import OllamaEmbeddings ollama_emb = OllamaEmbeddings( model="mxbai-embed-large", ) # 4. 定义 easysearch 集群的信息,以及存放向量的索引名称 infini from langchain_community.vectorstores import EcloudESVectorStore ES_URL = "https://192.168.56.3:9200" USER = "admin" PASSWORD = "e5ac1b537785ae27c187" indexname = "infini" docsearch = EcloudESVectorStore.from_documents( chunked_documents, ollama_emb, es_url=ES_URL, user=USER, password=PASSWORD, index_name=indexname, verify_certs=False, )
通过上面的步骤,我们成功将文本块转换成了向量,并存入到了 easysearch 集群的 infini 索引中。

我们看看 infini 索引内容是怎样的
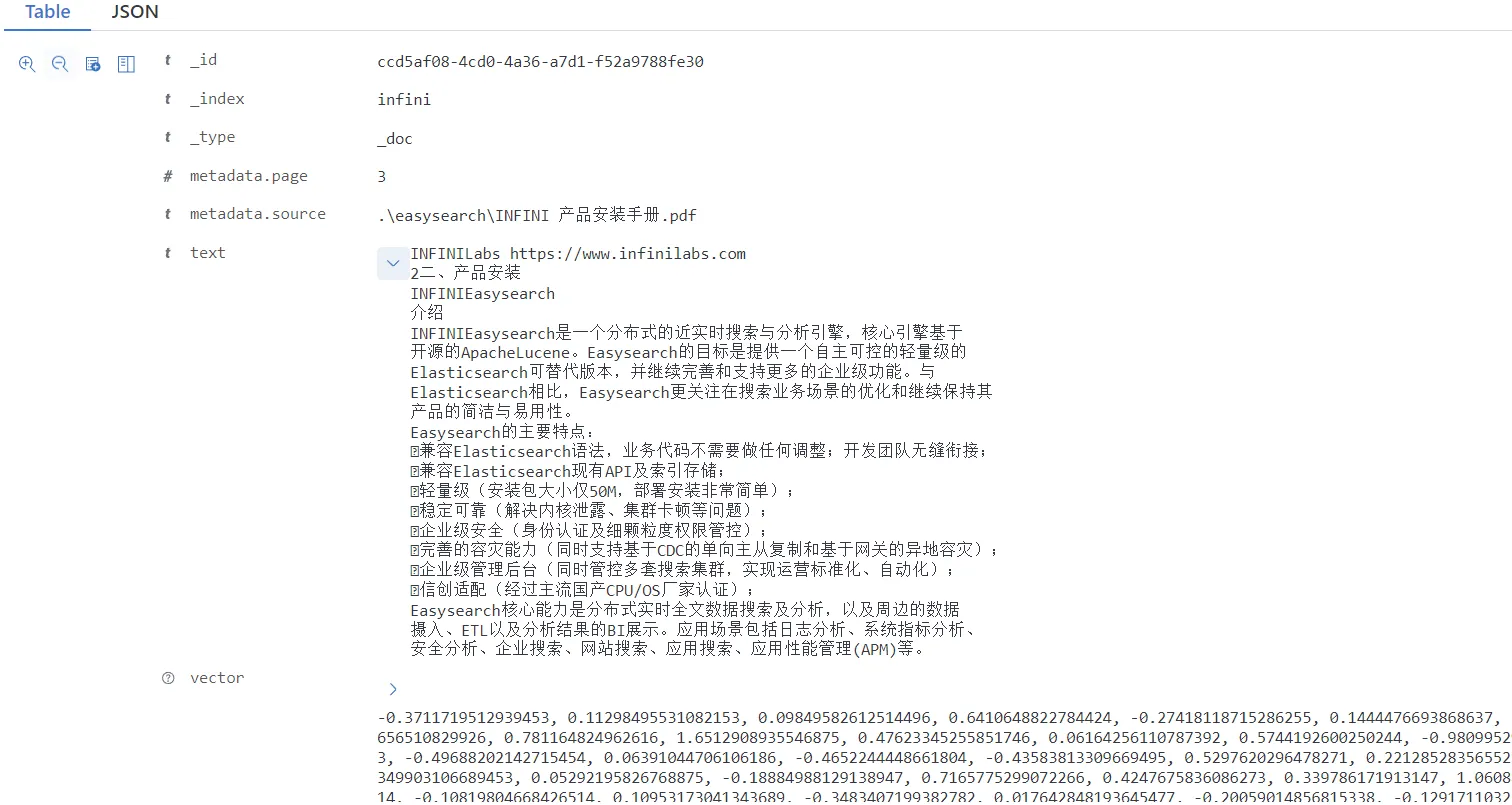
text 字段存放了文本块的原始内容,vector 字段存放着对应的向量表示。
检索及生成答案
在这一步,我们会定义一个生成式大模型。然后创建一个 RetrievalQA 链,它是一个检索式问答模型,用于生成问题的答案。
在 RetrievalQA 链中有下面两大重要组成部分。
-
LLM 是大模型,负责回答问题。
-
retriever(vectorstore.as_retriever())负责根据用户的问题检索相关的信息。先是找最近似的“向量块”,再把”向量块“对应的“文档块”作为知识信息,和问题一起传递进入大模型。之所以要先检索,是因为从互联网信息训练而来的大模型不可能拥有一个私营企业的内部知识。
# 5. Retrieval 准备模型和Retrieval链
import logging
# MultiQueryRetriever工具
from langchain.retrievers.multi_query import MultiQueryRetriever
# RetrievalQA链
from langchain.chains import RetrievalQA
# # 设置Logging
logging.basicConfig()
logging.getLogger('langchain.retrievers.multi_query').setLevel(logging.INFO)
# # 实例化一个大模型工具
from langchain_community.chat_models import ChatOllama
llm = ChatOllama(model="qwen2:latest")
from langchain.prompts import PromptTemplate
my_template = PromptTemplate(
input_variables=["question"],
template="""You are an AI language model assistant. Your task is
to generate 3 different versions of the given user
question in Chinese to retrieve relevant documents from a vector database.
By generating multiple perspectives on the user question,
your goal is to help the user overcome some of the limitations
of distance-based similarity search. Provide these alternative
questions separated by newlines. Original question: {question}""",
)
# # 实例化一个MultiQueryRetriever
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=docsearch.as_retriever(), llm=llm,prompt=my_template,include_original=True)
# # 实例化一个RetrievalQA链
qa_chain = RetrievalQA.from_chain_type(llm,retriever=retriever_from_llm)
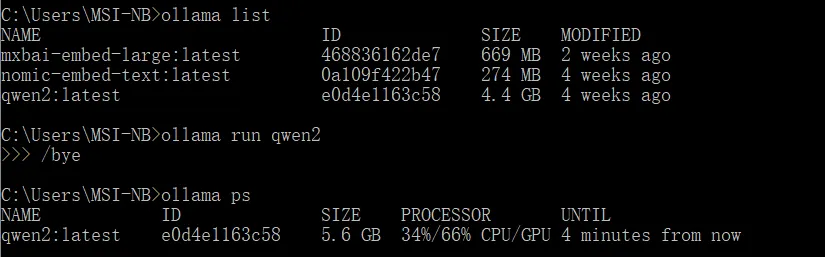
这里我们使用 ollama 在本地部署一个 qwen2 大模型,负责问题改写和生成答案。
启动 qwen2 大模型:ollama run qwen2
我们获取到用户问题后,先通过 MultiQueryRetriever 类调用大模型 qwen2 进行改写,生成 3 个同样语义的问题,然后再调用 easyearch 进行向量检索,搜索相关内容。
最后把所有相关内容,合并、去重后,与原始问题一起提交给大模型 qwen2,进行答案生成。
虽然这里使用的是向量检索,但实际上我们可以同时使用全文检索和向量检索。这也是使用 easysearch 作为检索库的优势之一。
前端展示
这一步我们创建一个 Flask 应用(需要安装 Flask 包)来接收用户的问题,并生成相应的答案,最后通过 index.html 对答案进行渲染和呈现。
在这个步骤中,我们使用了之前创建的 RetrievalQA 链来获取相关的文档和生成答案。然后,将这些信息返回给用户,显示在网页上。
# 6. Q&A系统的UI实现
from flask import Flask, request, render_template
app = Flask(__name__) # Flask APP
@app.route('/', methods=['GET', 'POST'])
def home():
if request.method == 'POST':
# 接收用户输入作为问题
question = request.form.get('question')
# RetrievalQA链 - 读入问题,生成答案
result = qa_chain({"query": question})
# 把大模型的回答结果返回网页进行渲染
return render_template('index.html', result=result)
return render_template('index.html')
if __name__ == "__main__":
app.run(host='0.0.0.0',debug=True,port=5000)
效果演示
我们模仿用户进行提问。

Q&A 系统进行回答,回答速度取决于本地的计算资源。

内容校验,在原始文档内用 ctrl+F 搜索关键字 LOGGING_ES_ENDPOINT 得到如下内容。

嗯,回答的还不错,达到预期目的。如果还有其他要求,可修改 my_template 中的提示词或者替换成别的大模型也是可以的。
小结
通过这次示例,我们演示了如何基于 LangChain 和 easysearch 以及大模型,快速开发出一个内部知识问答系统。怎么样,是不是觉得整个流程特别简单易懂?
如有任何问题,请随时联系我,期待与您交流!
-
AssumeRole接口是什么-icode9专业技术文章分享07-30
-
易优本地安装运行环境-icode9专业技术文章分享07-30
-
阿里云ECS服务器快速搭建企业建站环境-icode9专业技术文章分享07-30
-
易优如何解除绑定微信公众号-icode9专业技术文章分享07-30
-
hive的学习流程步骤-icode9专业技术文章分享07-30
-
判断数组中是否存在元素a 有就从数组删除该元素 没有就添加的代码-icode9专业技术文章分享07-30
-
Easysearch、Elasticsearch、Amazon OpenSearch 快照兼容对比07-29
-
基于 SASL/SCRAM 让 Kafka 实现动态授权认证07-29
-
AutoMQ 开源可观测性方案:夜莺 Flashcat07-29
-
云原生周刊:Cilium v1.16.0 发布|2024072907-29
-
如何通过 CloudCanal 实现从 Kafka 到 AutoMQ 的数据迁移07-29
-
cosmos 开发能做到跨链吗-icode9专业技术文章分享07-28
-
tar 打包时排除log目录-icode9专业技术文章分享07-28
-
unzip 指定解压目录-icode9专业技术文章分享07-28
-
possible SYN flooding on port 443. Sending cookies 什么意思-icode9专业技术文章分享07-28
