C/C++教程
如何通过 CloudCanal 实现从 Kafka 到 AutoMQ 的数据迁移

01
引言
随着大数据技术的飞速发展,Apache Kafka 作为一种高吞吐量、低延迟的分布式消息系统,已经成为企业实时数据处理的核心组件。然而,随着业务的扩展和技术的发展,企业面临着不断增加的存储成本和运维复杂性问题。为了更好地优化系统性能和降低运营成本,企业开始寻找更具优势的消息系统解决方案。其中,AutoMQ [1] 作为一种基于云重新设计的消息系统,凭借其显著的成本优势和弹性能力,成为了企业的理想选择。
1.1 AutoMQ 介绍
AutoMQ 基于云重新设计了 Kafka,将存储分离至对象存储,在保持与 Apache Kafka 100% 兼容的前提下,为用户提供高达10倍的成本优势和百倍的弹性优势。AutoMQ 通过构建在S3上的流存储库 S3Stream,将存储卸载至云厂商提供的共享云存储 EBS 和 S3,提供低成本、低延时、高可用、高可靠和无限容量的流存储能力。与传统的Shared Nothing 架构相比,AutoMQ 采用了 Shared Storage 架构,显著降低了存储和运维的复杂性,同时提升了系统的弹性和可靠性。AutoMQ 的设计理念和技术优势使其成为替换企业现有 Kafka 集群的理想选择。通过采用 AutoMQ,企业可以显著降低存储成本,简化运维,并实现集群的自动扩缩容和流量自平衡,从而更高效地应对业务需求的变化。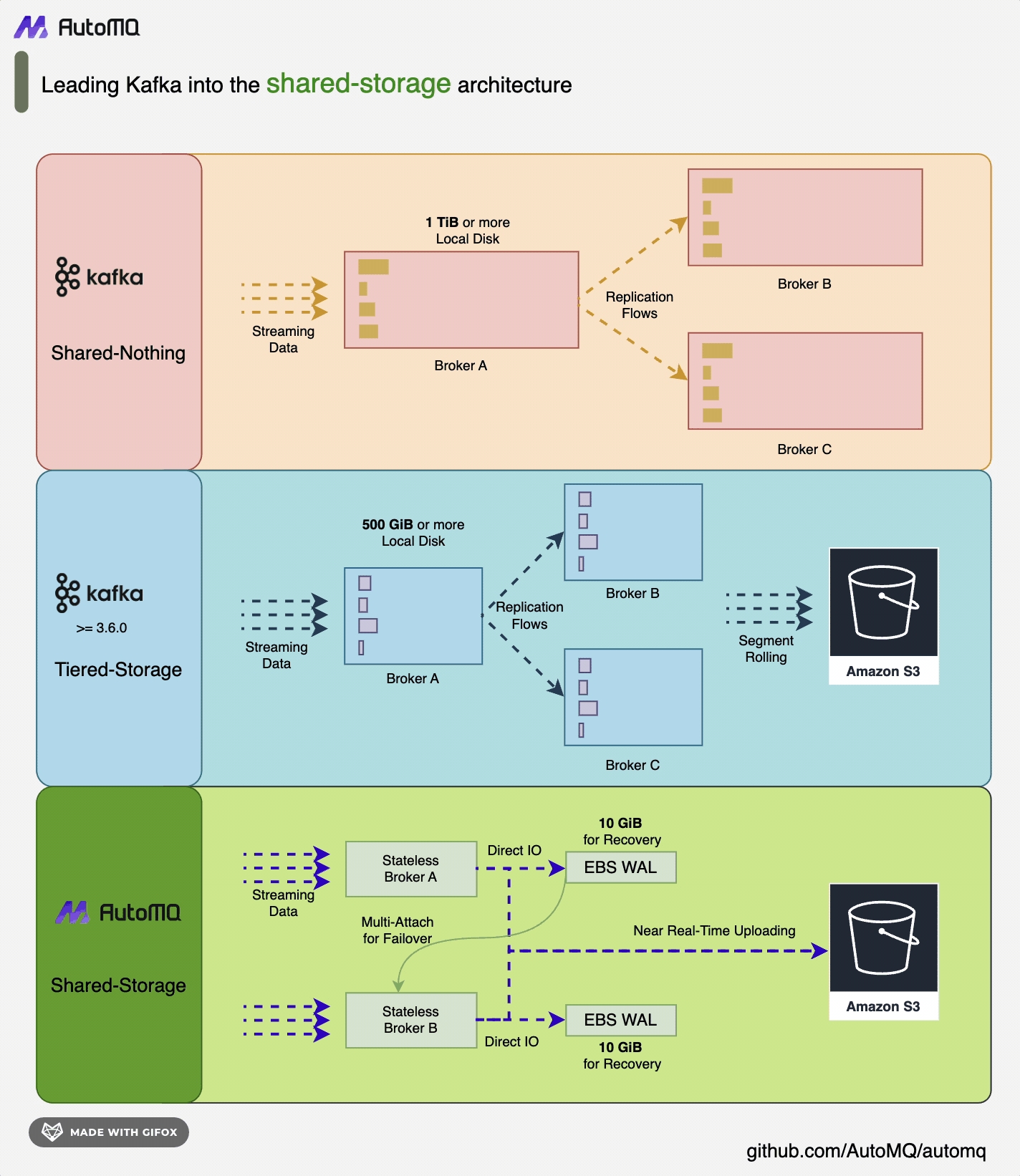
1.2 CloudCanal 概述
CloudCanal [2] 是一款数据同步、迁移工具,帮助企业构建高质量数据管道,具备实时高效、精确互联、稳定可拓展、一站式、混合部署、复杂数据转换等优点。CloudCanal 支持数据迁移、数据同步、结构迁移和同步、数据校验和订正等功能,能够满足企业在数据管理过程中对于数据质量和稳定性的高要求。通过消费源端数据源的增量操作日志,CloudCanal 可以准实时地在对端数据源重放操作,以达到数据同步的目的。
1.3 数据迁移的必要性
在企业的日常运营中,数据系统的升级和迁移是不可避免的。例如,当企业的电商平台面临流量激增和数据量爆炸式增长时,现有的 Kafka 集群可能无法满足需求,导致性能瓶颈和存储成本的显著增加。为了应对这些挑战,企业可能决定迁移到更具成本效益和弹性的 AutoMQ 系统。在这种迁移过程中,全量同步和增量同步都是关键步骤。全量同步可以将 Kafka 中的所有现有数据迁移到 AutoMQ,确保基础数据的完整性。增量同步则在全量同步完成后,实时捕捉和同步 Kafka 中的新增和变更数据,确保在迁移过程中,两个系统之间的数据保持一致。接下来,我将以增量同步为例,详细介绍如何使用 CloudCanal 实现从 Kafka 到 AutoMQ 的数据迁移,确保数据在迁移过程中保持一致和完整。
02
前置条件
在进行数据迁移之前,需要确保以下前提条件已经满足。本文将以一个 Kafka 节点和一个 AutoMQ 节点为例,演示增量同步的过程。
-
**Kafka 节点:**一个已部署并运行的 Kafka 节点,确保 Kafka 节点能够正常接收和处理消息,Kafka节点的网络配置允许与 CloudCanal 服务通信。
-
**AutoMQ 节点:**一个已部署并运行的 AutoMQ 节点,确保 AutoMQ 节点能够正常接收和处理消息,AutoMQ 节点的网络配置允许与 CloudCanal 服务通信。
-
CloudCanal 服务: 已部署和配置好的 CloudCanal 服务。
03
部署 AutoMQ、kafka 以及 CloudCanal
3.1 部署 AutoMQ
参考 AutoMQ 官网文档: QuickStart | AutoMQ [3]
3.2 部署 Kafka
参考 Apache Kafka 官方文档:QuickStart | Kafka [4]
3.3 部署 CloudCanal
安装与启动
1. 安装基础工具
## ubuntu sudo apt update sudo apt install apt-transport-https ca-certificates curl gnupg-agent software-properties-common sudo apt-get install -y lsof sudo apt-get install -y bc sudo apt-get install -y p7zip-full
2. 下载安装包登录 CloudCanal 官方网站 [5],点击下载私有部署版按钮,获取软件包下载链接。下载并解压到文件夹/opt/
cd /opt
# 下载
wget -cO cloudcanal.7z "${软件包下载链接}"
# 解压
7z x cloudcanal.7z -o./cloudcanal_home
cd cloudcanal_home/install_on_docker
install_on_docker目录内容包括
- 镜像: images 目录下四个 tar 结尾的压缩文件
- docker 容器编排文件: docker-compose.yml 文件
- 脚本:一些管理 CloudCanal 容器以及维护的脚本
3. 准备 Docker 环境请确保以下端口未被占用
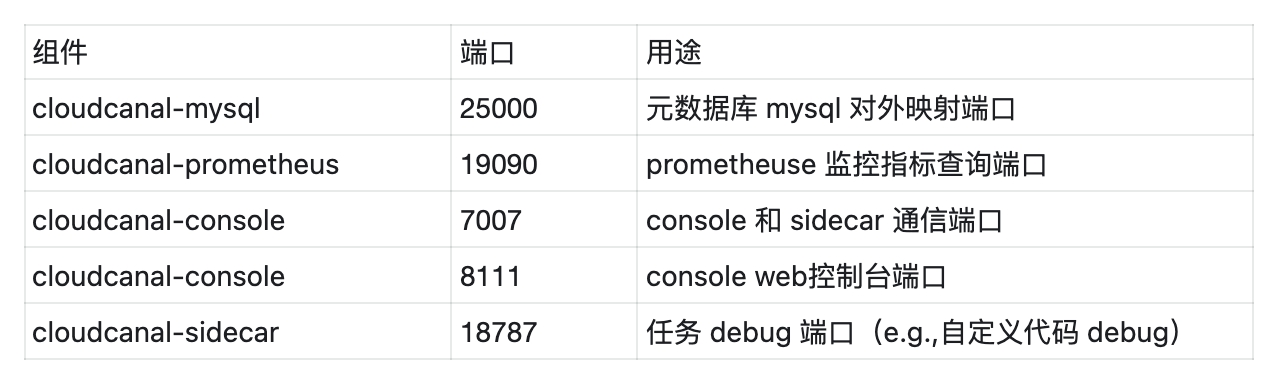
如果你没有 docker 和 docker compose 环境,可参考 Docker 官方文档 [6] (版本 17.x.x 及以上)。也可直接使用目录中提供的脚本进行安装:
## ubuntu,进入 install_on_docker 目录 bash ./support/install_ubuntu_docker.sh
- 启动 CloudCanal,执行安装脚本以启动:
## ubuntu bash install.sh
出现如下标识即安装成功

激活 CloudCanal
安装成功后,你可以通过 http://{ip}:8111 在浏览器中访问 CloudCanal 的控制台。
注意:如果无法正常访问页面,可以尝试通过脚本更新当前 CloudCanal 的版本,可使用如下命令:
# 进入安装目录 cd /opt/cloudcanal_home/install_on_docker # 停止当前 CloudCanal sudo bash stop.sh # 更新并启动新的 CloudCanal sudo bash upgrade.sh
1. 进入登录界面后,通过试用账号登录
-
账号: test@clougence.com
-
密码: clougence2021
-
默认验证码: 777777
2. 登录成功,需要激活 CloudCanal 账号即可正常使用。申请免费许可证并激活: 许可证获取 | CloudCanal [7],激活成功后,主界面状态为:

04
数据迁移过程
4.1 准备源端 Kafka 数据
可以选择如下方式:
- CloudCanal 提供的 Mysql->Kafka 数据同步过程,参考:MySQL 到 Kafka 同步 | CloudCanal [8]
- 通过 Kafka SDK 准备数据
- 通过 Kafka 提供的脚本手动生产消息
这里我将通过 Kafka SDK 的方式进行数据准备,下面是参考代码:
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class KafkaTest {
private static final String BOOTSTRAP_SERVERS = "${kafka_broker_ip:port}"; //修改为你自己的 Kafka 节点地址
private static final int NUM_TOPICS = 50;
private static final int NUM_MESSAGES = 500;
public static void main(String[] args) throws Exception {
KafkaTest test = new KafkaTest();
test.createTopics();
test.sendMessages();
}
// 创建50个 Topic,格式为 Topic-n
public void createTopics() {
Properties props = new Properties();
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
try (AdminClient adminClient = AdminClient.create(props)) {
List<NewTopic> topics = new ArrayList<>();
for (int i = 1; i <= NUM_TOPICS; i++) {
topics.add(new NewTopic("Topic-" + i, 1, (short) 1));
}
adminClient.createTopics(topics).all().get();
System.out.println("Topics created successfully");
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
// 为50个 Topic-n 分别发送序号从1到1000共一千条消息,消息格式为 Json格式
public void sendMessages() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
try (KafkaProducer<String, String> producer = new KafkaProducer<>(props)) {
for (int i = 1; i <= NUM_TOPICS; i++) {
String topic = "Topic-" + i;
for (int j = 1; j <= NUM_MESSAGES; j++) {
String key = "key-" + j;
String value = "{\"userId\": " + j + ", \"action\": \"visit\", \"timestamp\": " + System.currentTimeMillis() + "}";
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
producer.send(record, (RecordMetadata metadata, Exception exception) -> {
if (exception == null) {
System.out.printf("Sent message to topic %s partition %d with offset %d%n", metadata.topic(), metadata.partition(), metadata.offset());
} else {
exception.printStackTrace();
}
});
}
}
System.out.println("Messages sent successfully");
}
}
}
创建完成后,可以通过各种可视化工具查看 Kafka 节点状态,比如 Redpanda Console [9]、Kafdrop [10] 等。这里我选择 Redpanda Console,可以看到当前已经有了 50 个Topic,并且每个 Topic 下有500条初始消息。
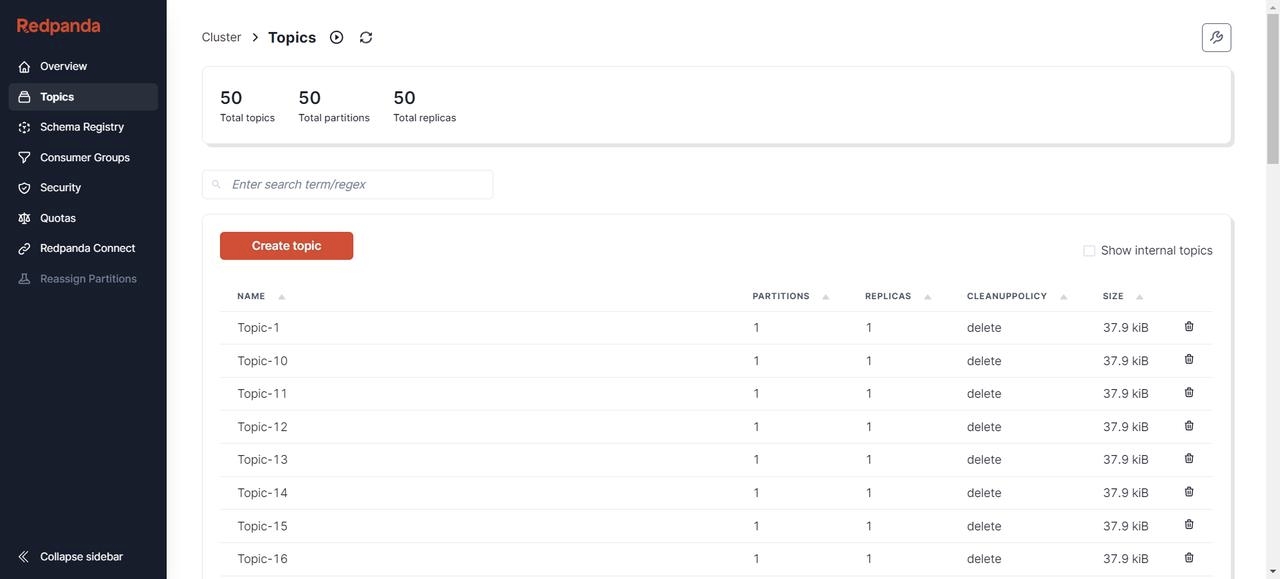
其中消息的格式为 Json:
{
"action": "INSERT/UPDATE/DELETE",
"bid": 1,
"before": [],
"data": [{
"id":"string data",
"username":"string data",
"user_id":"string data",
"ip":"string data",
"request_time":"1608782968300","request_type":"string data"}],
"db": "access_log_db",
"schema": "",
"table":"access_log",
"dbValType": {
"id":"INT",
"username":"VARCHAR",
"user_id":"INT",
"ip":"VARCHAR",
"request_time":"TIMESTAMP",
"request_type":"VARCHAR",},
"jdbcType": {
"id":"0",
"username":"0",
"user_id":"0",
"ip":"0",
"request_time":"0",
"request_type":"0",},
"entryType": "ROWDATA",
"isDdl": false,
"pks": ["id"],
"execTs": 0,
"sendTs": 0,
"sql": ""}
并且,AutoMQ 节点当前并无任何数据:
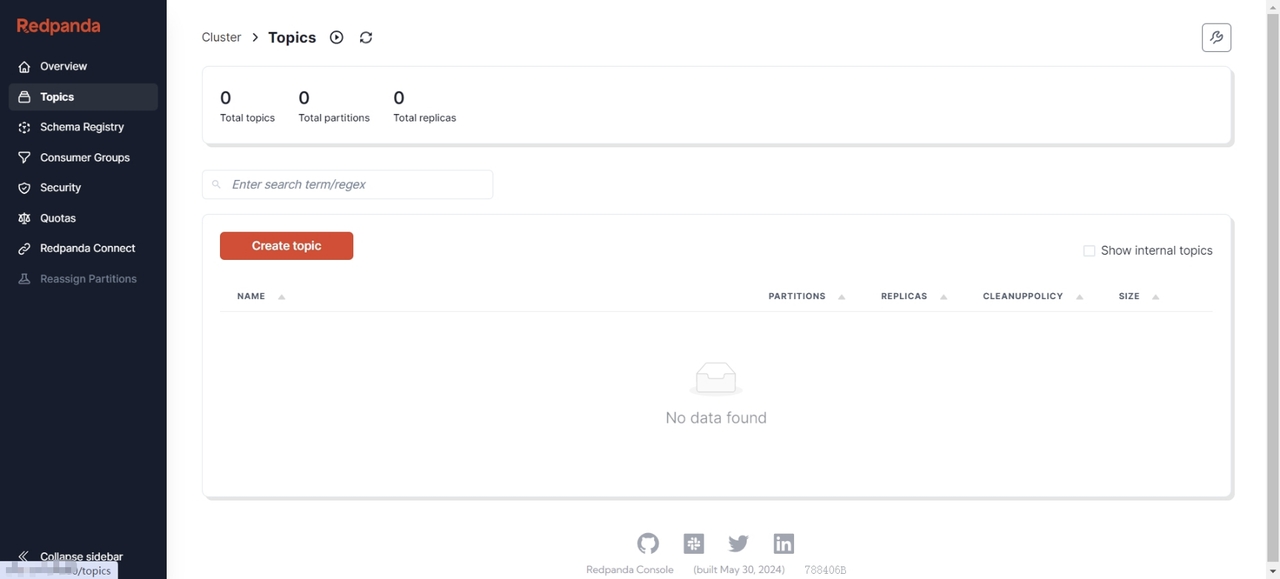
添加 CloudCanal 数据源
CloudCanal 界面上方 数据源管理 -> 新增数据源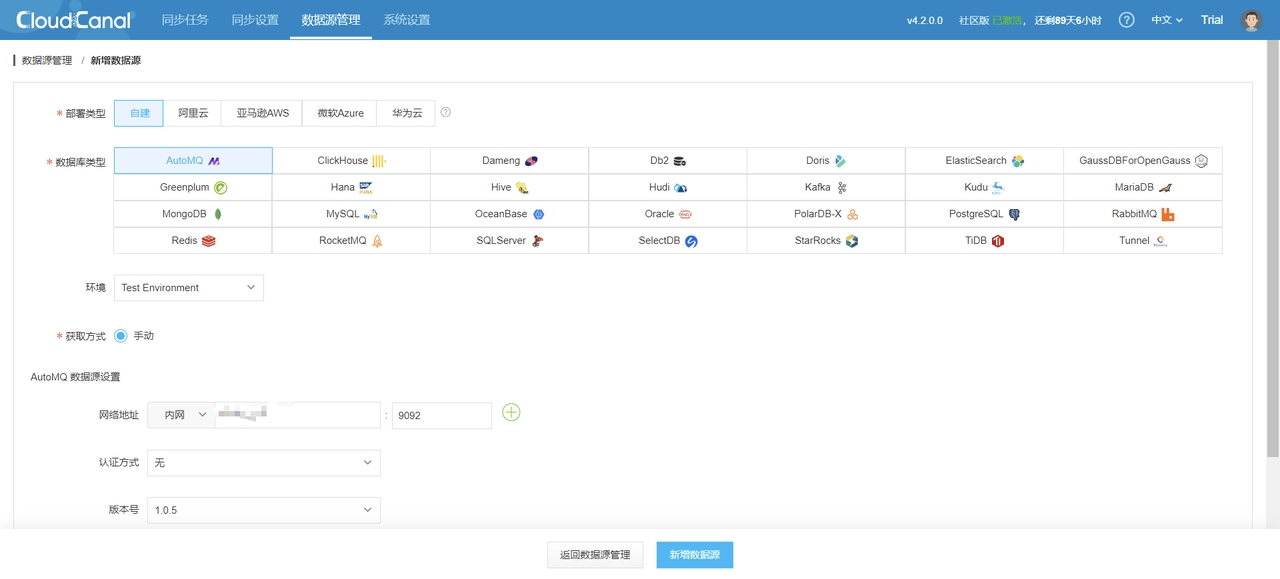
同理增加 Kafka 数据源,并对两个节点都进行连接测试,可以得到如下结果: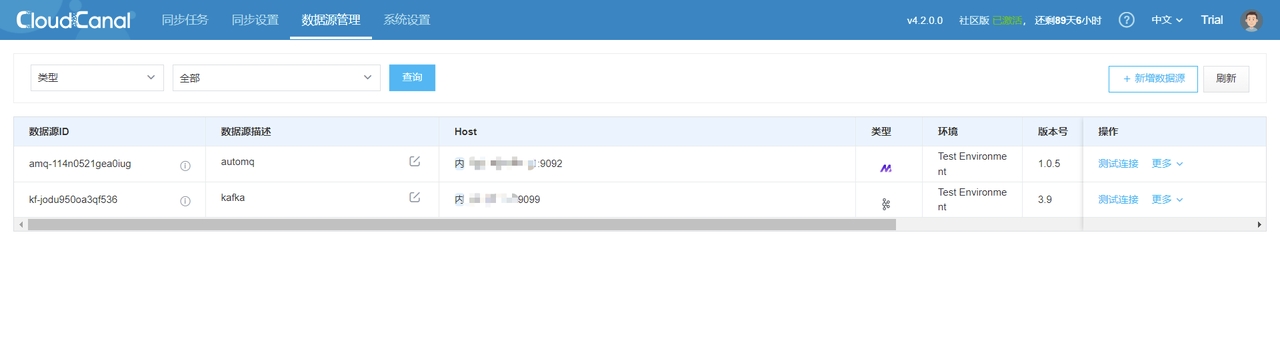
4.3 创建数据迁移任务
1. CloudCanal 界面上方 同步任务->创建任务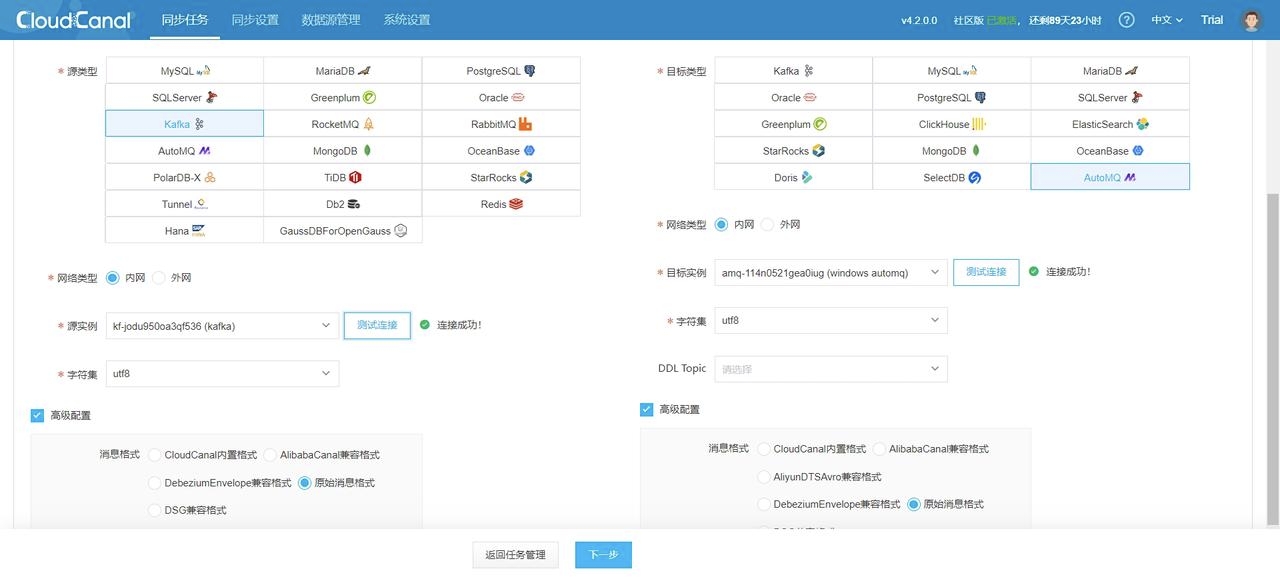
2. 选择任务规格,这取决于你需要迁移的数据量大小: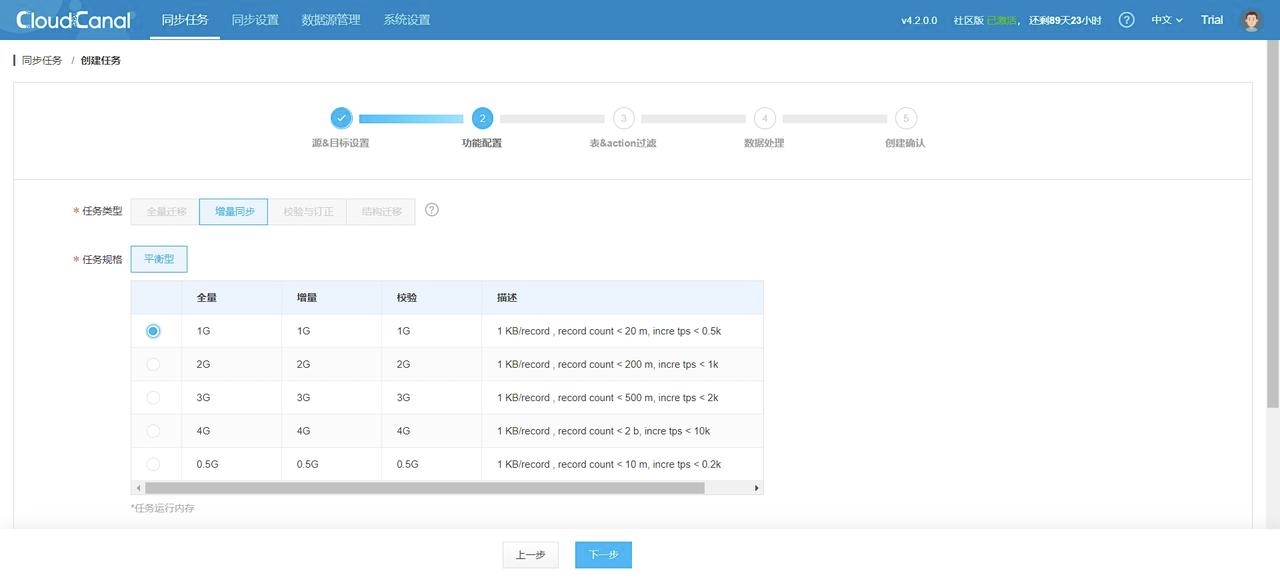
3. 选择需要进行数据迁移的 Topics: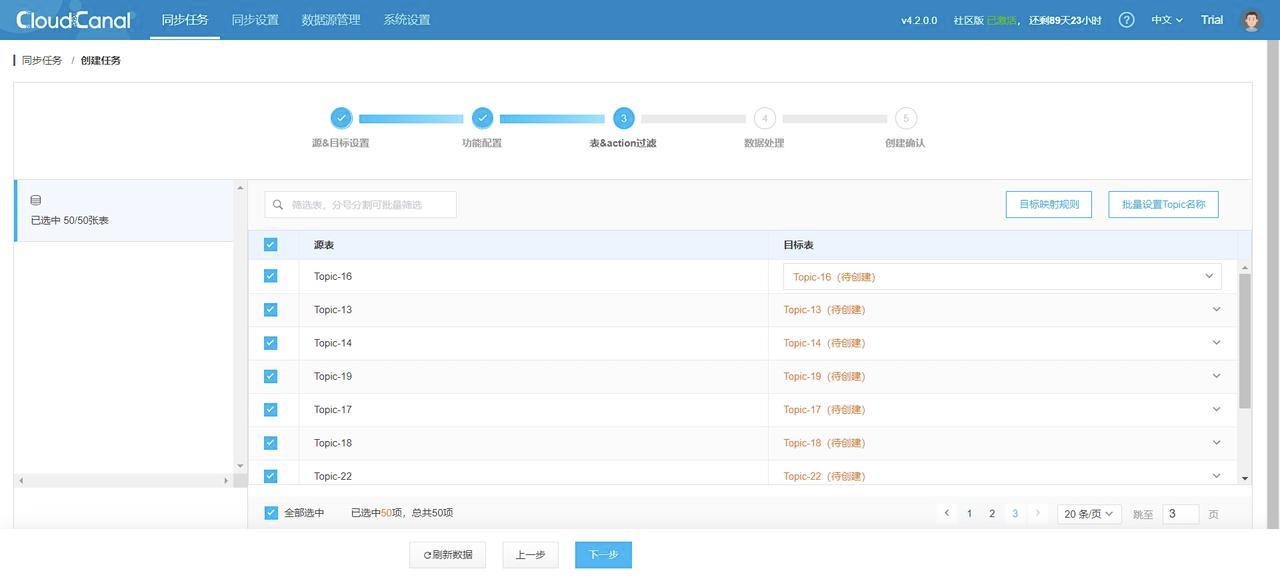
4. 任务确定: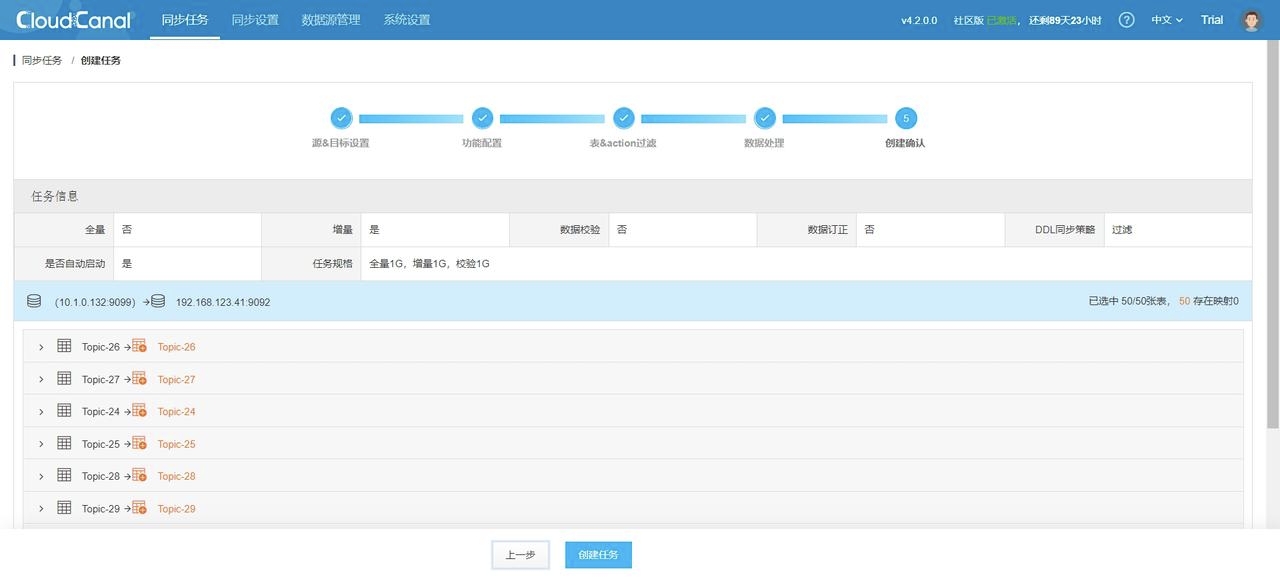
5. 任务创建完成后默认自动启动,会跳转到任务列表,你还需要更改源数据源配置以开启心跳配置,能及时更新任务状态,步骤为 任务详情->源数据源配置->修改配置->生效配置: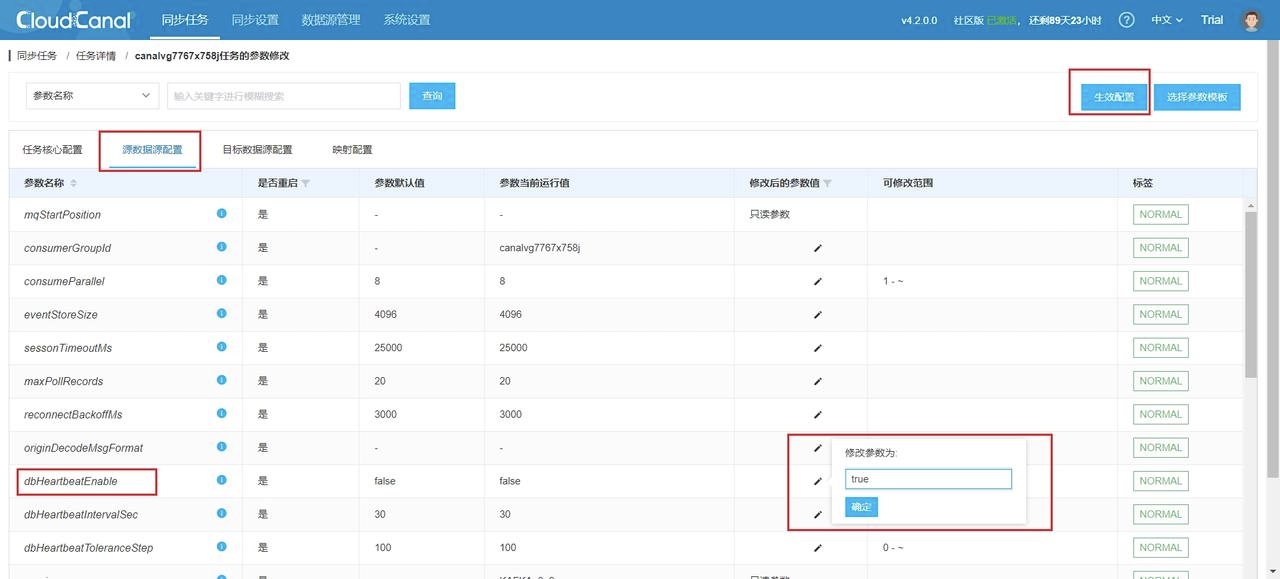
6. 随后等待任务重启完成,即可看到如下情况: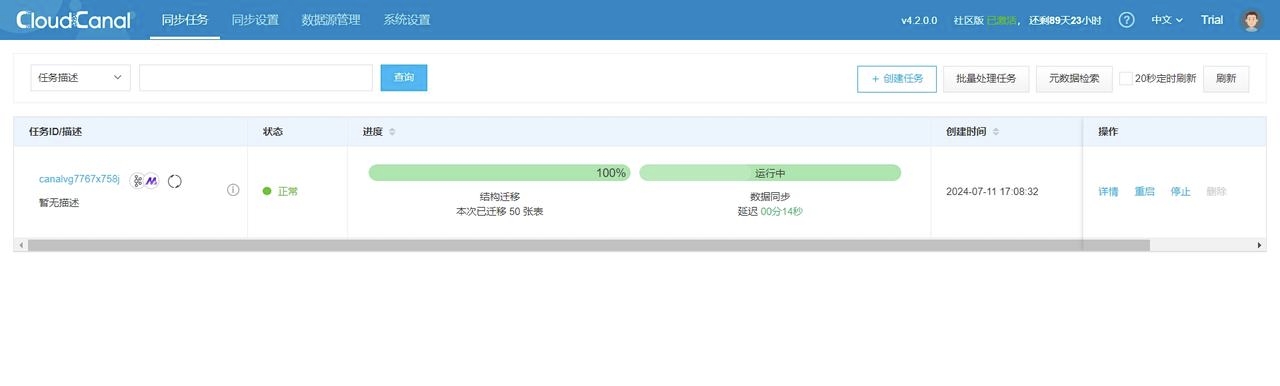
注意:如果遇到关于连接问题以及任务延迟过高等问题可以参考 CloudCanal 官方文档:FAQ 索引 | CloudCanal [11]
7. 验证 AutoMQ 中是否已经正确创建了 Topic 结构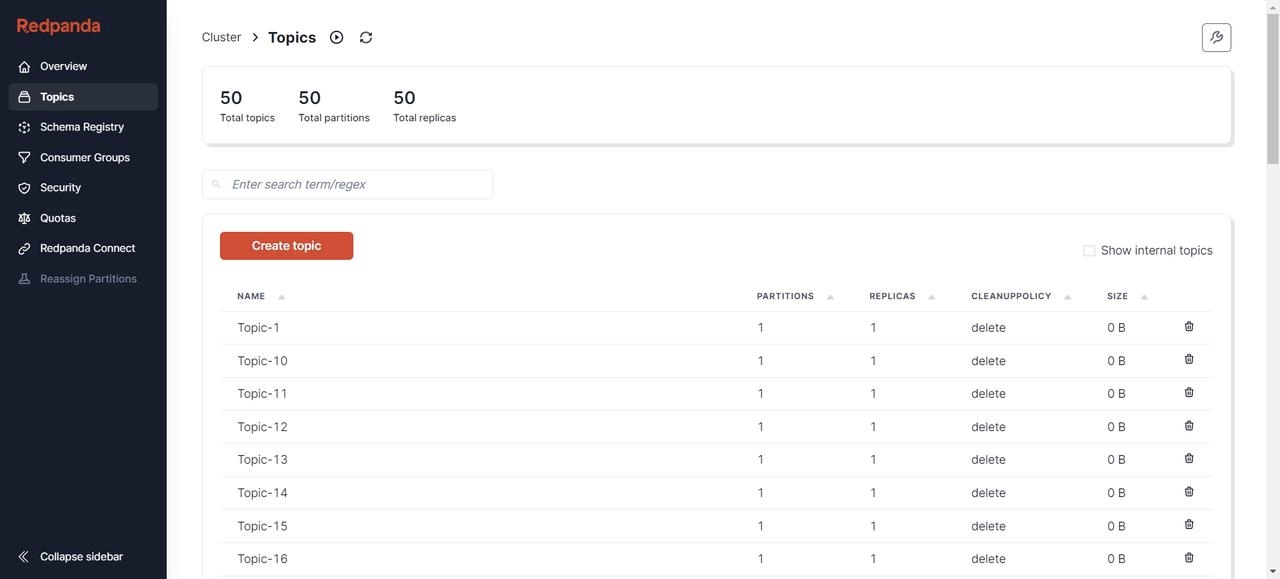
4.4 准备增量数据
任务已经正常运行,接下来我们需要准备增量数据,使得迁移任务能够将增量数据同步到 AutoMQ。这里我们仍然通过 Kafka SDK 新增数据。新增数据之后,我们可以通过 任务详情->增量同步->查看日志->任务运行日志 中查看任务执行情况:
2024-07-11 17:16:45.995 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64 2024-07-11 17:16:45.995 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64 2024-07-11 17:16:45.996 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64 2024-07-11 17:16:45.996 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64 2024-07-11 17:16:45.996 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64 2024-07-11 17:16:45.997 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64 2024-07-11 17:16:45.997 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64 2024-07-11 17:16:45.997 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64 2024-07-11 17:16:45.998 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64 2024-07-11 17:16:45.998 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64 2024-07-11 17:16:45.998 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64 2024-07-11 17:16:45.999 [incre-fetch-from-buffer-14-thd-0] INFO c.c.c.mq.worker.reader.kafka.KafkaIncreEventBroker - getWithoutAck successfully, batch:64, real:64
05
验证迁移结果
验证AutoMQ是否正确同步到消息: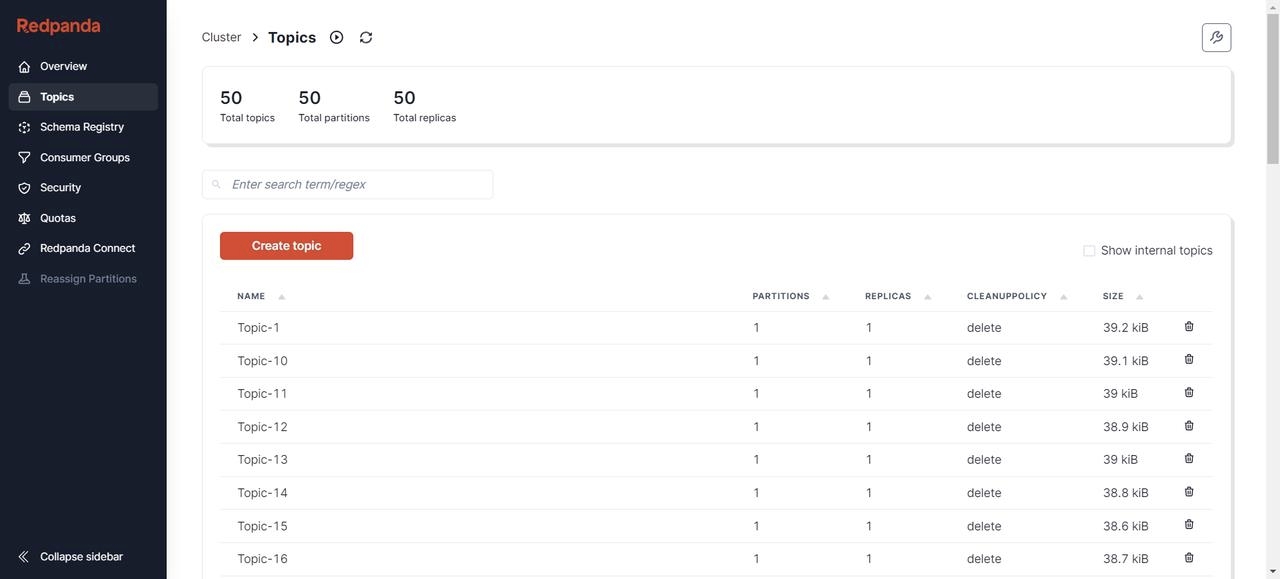

多次新增数据后依旧正常完成迁移: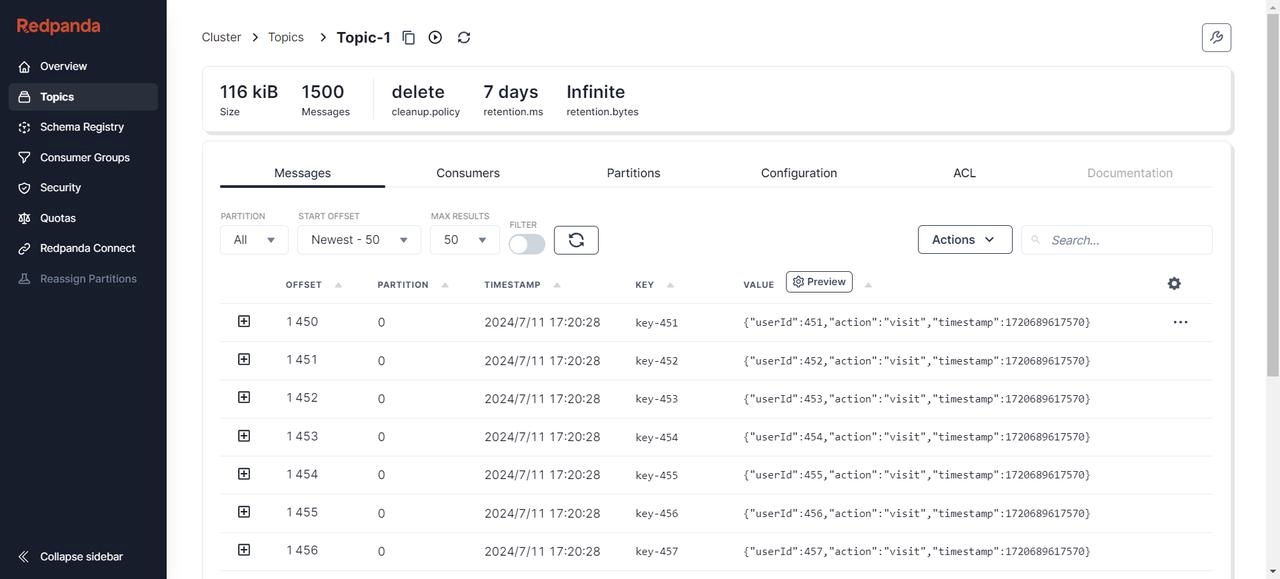
可以看到在增量同步任务执行期间对 Kafka 新增的数据都已经同步到了 AutoMQ 中。至此,我们的迁移过程已经全部完成。
06
总结
随着企业数据规模的不断扩大和业务需求的多样化,数据迁移和同步变得尤为重要。通过本文的介绍,我们详细探讨了如何利用 CloudCanal 实现从 Kafka 到 AutoMQ 的增量同步数据迁移,以应对存储成本和运维复杂性的问题。在迁移过程中,增量同步技术确保了数据的一致性和业务的连续性,为企业提供了一个高效、可靠的解决方案。希望本文能够为你在数据迁移和同步方面提供有价值的参考和指导,帮助实现系统的平滑过渡和性能优化!
引用
[1] AutoMQ: https://docs.automq.com/zh/docs/automq-opensource/HSiEwHVfdiO7rWk34vKcVvcvn2Z
[2] CloudCanal: https://www.clougence.com/?src=cc-doc
[3] QuickStart | AutoMQ: https://docs.automq.com/zh/docs/automq-opensource/EvqhwAkpriAomHklOUzcUtybn7g
[4] QuickStart | Kafka: https://kafka.apache.org/quickstart
[5] CloudCanal 官方网站: https://www.clougence.com/?src=cc-doc-install-linux
[6] Docker 官方文档: https://docs.docker.com/engine/install/
[7] 许可证获取 | CloudCanal: https://www.clougence.com/cc-doc/license/license_use
[8] MySQL 到 Kafka 同步 | CloudCanal: https://www.clougence.com/cc-doc/bestPractice/mysql_kafka_sync
[9] Redpanda Console: https://redpanda.com/redpanda-console-kafka-ui
[10] Kafdrop: https://github.com/obsidiandynamics/kafdrop
[11] FAQ 索引 | CloudCanal: https://www.clougence.com/cc-doc/faq/cloudcanal_faq_list
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com?utm_source=openwrite
-
Rakuten 乐天积分系统从 Cassandra 到 TiDB 的选型与实战01-10
-
CMS内容管理系统是什么?如何选择适合你的平台?01-09
-
CCPM如何缩短项目周期并降低风险?01-08
-
Omnivore 替代品 Readeck 安装与使用教程01-08
-
Cursor 收费太贵?3分钟教你接入超低价 DeepSeek-V3,代码质量逼近 Claude 3.501-07
-
PingCAP 连续两年入选 Gartner 云数据库管理系统魔力象限“荣誉提及”01-06
-
Easysearch 可搜索快照功能,看这篇就够了01-05
-
BOT+EPC模式在基础设施项目中的应用与优势01-04
-
用LangChain构建会检索和搜索的智能聊天机器人指南01-03
-
图像文字理解,OCR、大模型还是多模态模型?PalliGema2在QLoRA技术上的微调与应用01-03
-
混合搜索:用LanceDB实现语义和关键词结合的搜索技术(应用于实际项目)01-03
-
停止思考数据管道,开始构建数据平台:介绍Analytics Engineering Framework01-03
-
如果 Azure-Samples/aks-store-demo 使用了 Score 会怎样?01-03
-
Apache Flink概述:实时数据处理的利器01-03
-
使用 SVN合并操作时,怎么解决冲突的情况?-icode9专业技术文章分享01-01
