C/C++教程
AutoMQ 开源可观测性方案:夜莺 Flashcat

01
引言
在现代企业中,随着数据处理需求的不断增长,AutoMQ [1] 作为一种高效、低成本的流处理系统,逐渐成为企业实时数据处理的关键组件。然而,随着集群规模的扩大和业务复杂性的增加,确保 AutoMQ 集群的稳定性、高可用性和性能优化变得尤为重要。因此,集成一个强大而全面的监控系统对于维护 AutoMQ 集群的健康运行至关重要。夜莺监控系统(Nightingale)[2] 以其高效的数据采集、灵活的告警管理和丰富的可视化能力,成为企业监控AutoMQ 集群的理想选择。通过使用夜莺监控系统,企业可以实时掌握 AutoMQ 集群的运行状态,及时发现和解决潜在问题,优化系统性能,确保业务的连续性和稳定性。
AutoMQ 概述
AutoMQ 是一种基于云重新设计的流处理系统,它在保持与 Apache Kafka 100% 兼容的前提下,通过将存储分离至对象存储,显著提升了系统的成本效益和弹性能力。具体来说,AutoMQ 通过构建在 S3 上的流存储库 S3Stream,将存储卸载至云厂商提供的共享云存储 EBS 和 S3,提供低成本、低延时、高可用、高可靠和无限容量的流存储能力。与传统的 Shared Nothing 架构相比,AutoMQ 采用了 Shared Storage 架构,显著降低了存储和运维的复杂性,同时提升了系统的弹性和可靠性。AutoMQ 的设计理念和技术优势使其成为替换企业现有 Kafka 集群的理想选择。通过采用 AutoMQ,企业可以显著降低存储成本,简化运维,并实现集群的自动扩缩容和流量自平衡,从而更高效地应对业务需求的变化。此外,AutoMQ 的架构支持高效的冷读操作和服务零中断,确保系统在高负载和突发流量情况下的稳定运行。它的存储结构如下:
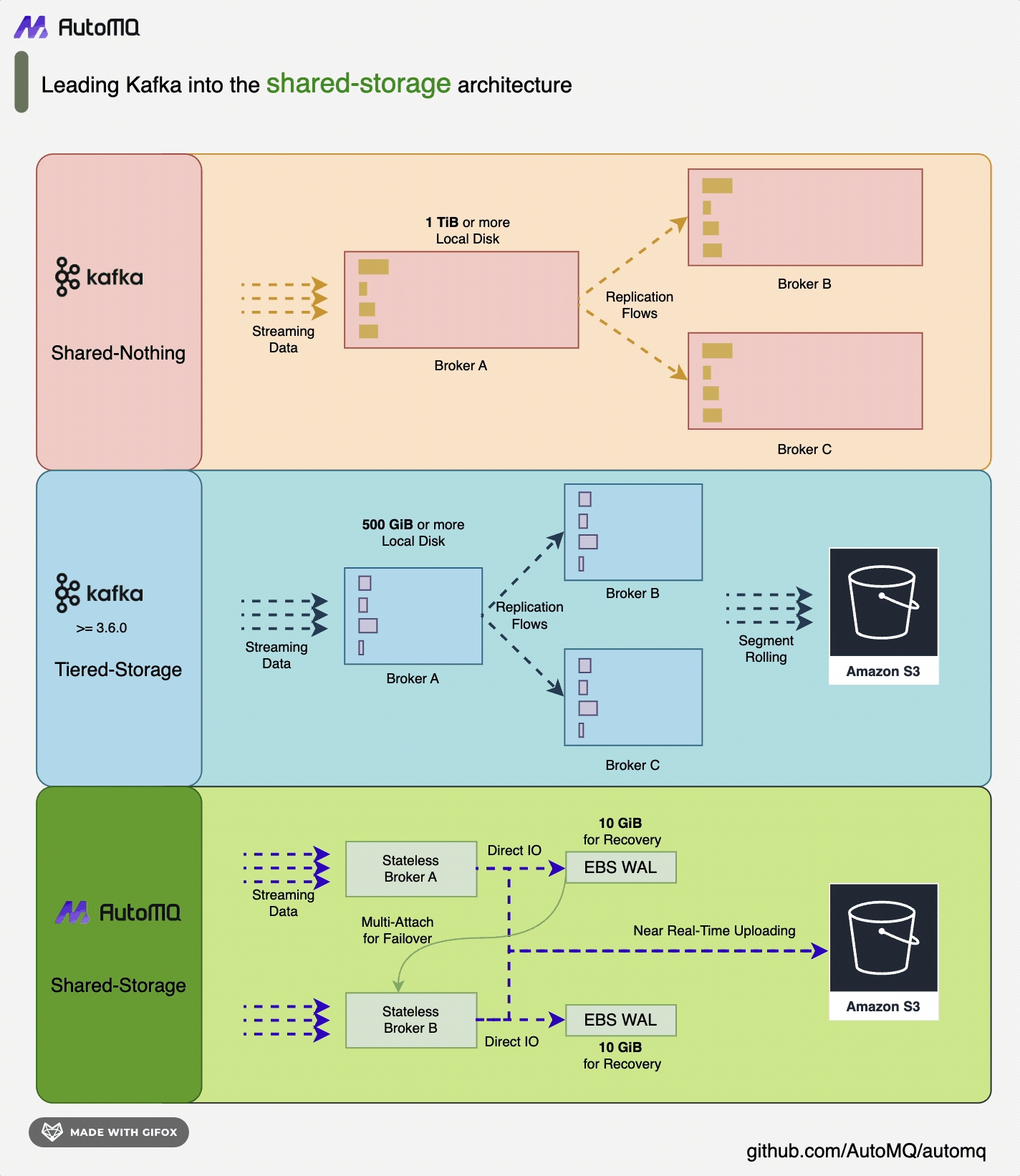
AutoMQ 存储结构
夜莺概述
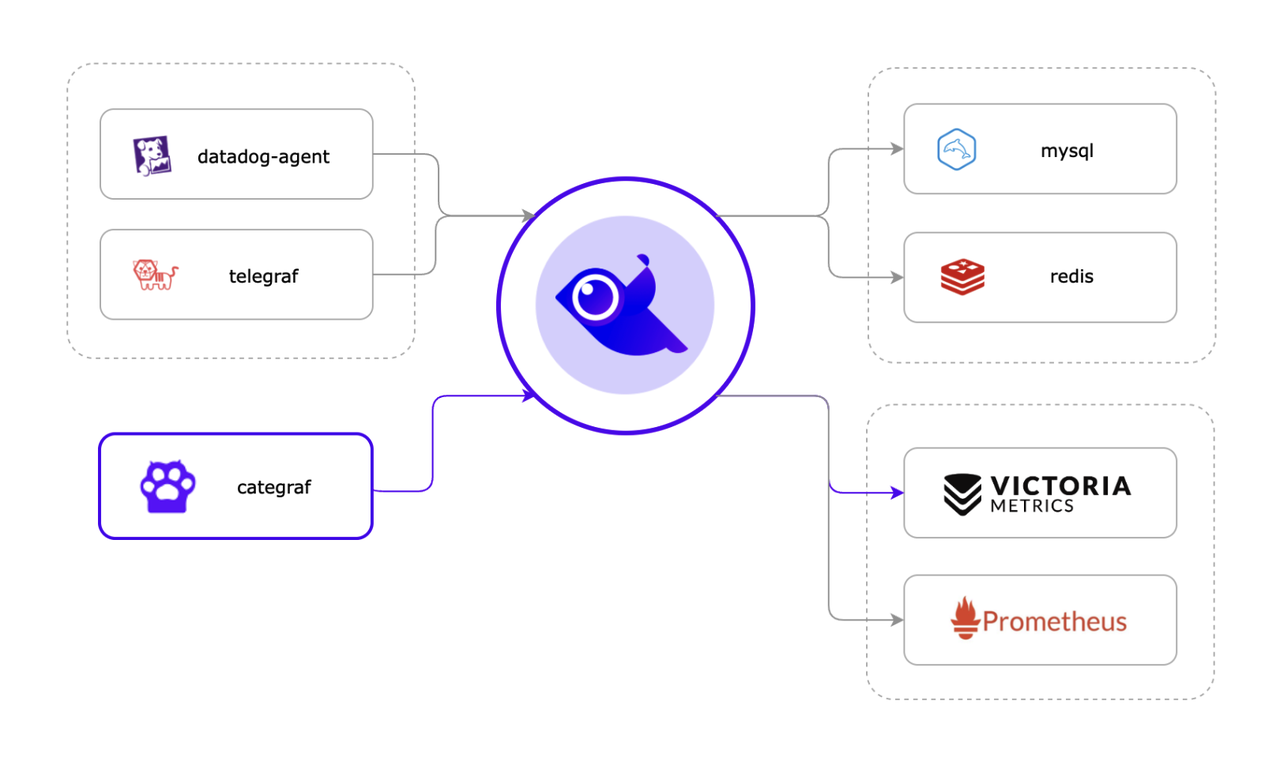
夜莺监控系统(Nightingale)是一款开源的云原生观测分析工具,采用 All-in-One 设计理念,集数据采集、可视化、监控告警和数据分析于一体。其主要优势包括高效的数据采集能力、灵活的告警策略和丰富的可视化功能。夜莺与多种云原生生态紧密集成,支持多种数据源和存储后端,提供低延迟、高可靠性的监控服务。通过使用夜莺,企业可以实现对复杂分布式系统的全面监控和管理,快速定位和解决问题,从而优化系统性能和提高业务连续性。
02
前置条件
为了实现集群状态的监控,你需要如下环境:
- 部署一个可用的 AutoMQ 节点/集群,并开放 Metrics 采集端口
- 部署夜莺监控及其依赖环境
- 部署 Prometheus [4] 以获取 Metrics 数据
03
部署 AutoMQ、Prometheus 以及夜莺监控
部署 AutoMQ
参考 AutoMQ 文档:集群方式部署 | AutoMQ [5] 。在部署启动前,添加如下配置参数以开启 Prometheu 的拉取接口。通过以下参数启动 AutoMQ 集群以后,每个节点将会额外开放一个 HTTP 接口供我们拉取 AutoMQ 的监控指标。这些指标的格式均遵循 Prometheus Metrics 的格式。
bin/kafka-server-start.sh ... --override s3.telemetry.metrics.exporter.type=prometheus --override s3.metrics.exporter.prom.host=0.0.0.0 --override s3.metrics.exporter.prom.port=8890 ....
当启用 AutoMQ 监控指标后,可以在任意一台节点上通过 HTTP 协议拉取到 Prometheus 格式的监控指标,地址为:http://{node_ip}:8890,响应结果示例如下:
....
kafka_request_time_mean_milliseconds{otel_scope_name="io.opentelemetry.jmx",type="DescribeDelegationToken"} 0.0 1720520709290
kafka_request_time_mean_milliseconds{otel_scope_name="io.opentelemetry.jmx",type="CreatePartitions"} 0.0 1720520709290
...
关于指标介绍,可以参考 AutoMQ 官网文档:Metrics | AutoMQ [6] 。
部署 Prometheus
Prometheus 可以通过下载二进制包部署,也可以通过 Docker 方式部署。以下是这两种部署方式的介绍。
二进制部署
为了方便使用,你可以新建一个脚本,并根据需要修改 Prometheus 的下载版本,最后执行脚本即可完成部署。首先,新建脚本:
cd /home vim install_prometheus.sh # !!! 粘贴下面的脚本内容 并保存退出 # 授予权限 chmod +x install_prometheus.sh # 执行脚本 ./install_prometheus.sh
脚本内容如下:
version=2.45.3
filename=prometheus-${version}.linux-amd64
mkdir -p /opt/prometheus
wget https://github.com/prometheus/prometheus/releases/download/v${version}/${filename}.tar.gz
tar xf ${filename}.tar.gz
cp -far ${filename}/* /opt/prometheus/
# config as a service
cat <<EOF >/etc/systemd/system/prometheus.service
[Unit]
Description="prometheus"
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml --storage.tsdb.path=/opt/prometheus/data --web.enable-lifecycle --web.enable-remote-write-receiver
Restart=on-failure
SuccessExitStatus=0
LimitNOFILE=65536
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=prometheus
[Install]
WantedBy=multi-user.target
EOF
systemctl enable prometheus
systemctl restart prometheus
systemctl status prometheus
随后修改 Prometheus 的配置文件,增加采集 AutoMQ 可观测数据的任务,并重启 Prometheus,执行命令:
# config 配置文件内容填下面的 vim /opt/prometheus/prometheus.yml # 重启 Prometheus systemctl restart prometheus
配置文件内容参考如下,请将下列中的client_ip修改为 AutoMQ 开放的可观测数据暴露地址:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "automq"
static_configs:
- targets: ["{client_ip}:8890"]
部署完成后,我们可以通过浏览器访问 Prometheus,查看是否真正采集到了 AutoMQ 的 Metrics数据,访问http://{client_ip}:9090/targets: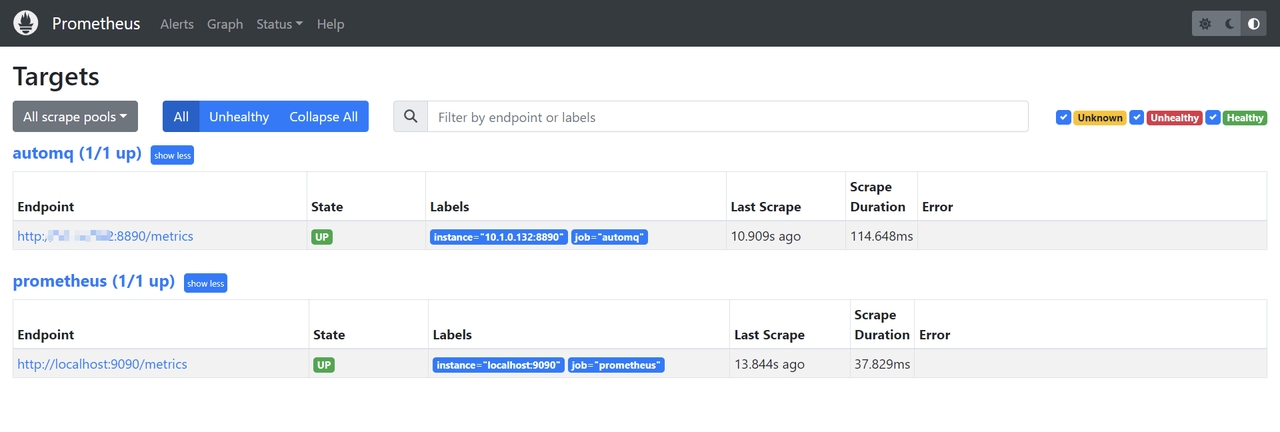
Docker 部署
如果你已经有一个在运行的 Prometheus Docker 容器,请先执行命令删除该容器:
docker stop prometheus docker rm prometheus
新建配置文件,并在 Docker 启动时进行挂载:
mkdir -p /opt/prometheus vim /opt/prometheus/prometheus.yml # 配置内容参考上述 “二进制部署” 中的配置
启动 Docker 容器:
docker run -d --name=prometheus -p 9090:9090 -v /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml -m 500m prom/prometheus --config.file=/etc/prometheus/prometheus.yml --enable-feature=otlp-write-receiver --web.enable-remote-write-receiver
这样你便得到了一个采集 AutoMQ Metrics 的 Prometheus 服务,关于更多 AutoMQ Metrics 与 Prometheus 集成的介绍,可以参考:将 Metrics 集成到 Prometheus | AutoMQ [7]。
部署夜莺监控
夜莺监控可以通过下面三种方式进行部署,关于更详细的部署说明可以参考官方文档 [8]:
- Docker compose 方式部署
- 二进制方式部署
- Helm 方式部署
接下来我将采用二进制的方式进行部署。
下载夜莺
请在夜莺 Github releases [9] 页中选择合适的版本进行下载,这里我们采用的版本是v7.0.0-beta.14。如果你是 amd 架构的机器,可直接执行如下命令:
cd /home # 下载 wget https://github.com/ccfos/nightingale/releases/download/v7.0.0-beta.14/n9e-v7.0.0-beta.14-linux-amd64.tar.gz mkdir -p /home/flashcat # 解压文件到 /home/flashcat 文件夹 tar -xzf /home/n9e-v7.0.0-beta.14-linux-amd64.tar.gz -C /home/flashcat # 进入主目录 cd /home/flashcat
配置依赖环境
夜莺依赖 MySQL 和 Redis,因此需要提前安装这两个环境。你可以通过 Docker 方式部署,也可以通过执行命令进行安装,参考命令如下:
# install mysql
yum -y install mariadb*
systemctl enable mariadb
systemctl restart mariadb
mysql -e "SET PASSWORD FOR 'root'@'localhost' = PASSWORD('1234');"
# install redis
yum install -y redis
systemctl enable redis
systemctl restart redis
这里 Redis 设置的是无密码的。并且这里指定 MySQL 数据库的密码为1234,如果你需要更改为其他的密码,要在夜莺的配置文件中进行配置,以保证夜莺能连接到你的数据库。修改夜莺配置文件:
vim /home/flashcat/etc/config.toml
修改 [DB] 下的用户名和密码:
[DB]
# postgres: host=%s port=%s user=%s dbname=%s password=%s sslmode=%s
# postgres: DSN="host=127.0.0.1 port=5432 user=root dbname=n9e_v6 password=1234 sslmode=disable"
# sqlite: DSN="/path/to/filename.db"
DSN = "{username}:{password}@tcp(127.0.0.1:3306)/n9e_v6?charset=utf8mb4&parseTime=True&loc=Local&allowNativePasswords=true"
# enable debug mode or not
导入数据库表
执行如下命令:
mysql -uroot -p1234 < n9e.sql
请通过数据库工具检测是否成功导入数据库表:
> show databases; +--------------------+ | Database | +--------------------+ | n9e_v6 | +--------------------+ > show tables; +-----------------------+ | Tables_in_n9e_v6 | +-----------------------+ | alert_aggr_view | | alert_cur_event | | alert_his_event | | alert_mute | | alert_rule | | alert_subscribe | | alerting_engines | | board | | board_busigroup | | board_payload | | builtin_cate | | builtin_components | | builtin_metrics | ······
修改夜莺配置文件
你需要修改夜莺的配置文件,进行 Prometheus 数据源的设置:
vim /home/flashcat/etc/config.toml
# 修改 [[Pushgw.Writers]] 部分的内容为
[[Pushgw.Writers]]
# Url = "http://127.0.0.1:8480/insert/0/prometheus/api/v1/write"
Url = "http://{client_ip}:9090/api/v1/write"
启动夜莺
在夜莺的根目录 /home/flashcat下执行:./n9e。成功启动后,可在浏览器中访问 http://{client_ip}:17000,默认的登录账号和密码为:
- 账号:root
- 密码:root.2020
接入 Prometheus 数据源
左侧边栏集成 -> 数据源 -> Prometheus。
至此,我们的夜莺监控就部署结束了。
04
夜莺监控 AutoMQ 集群状态
接下来,我将介绍夜莺监控提供的一部分功能,帮助你更好地了解夜莺与 AutoMQ 集成的可用功能。
即时查询
选择内置的 AutoMQ 指标: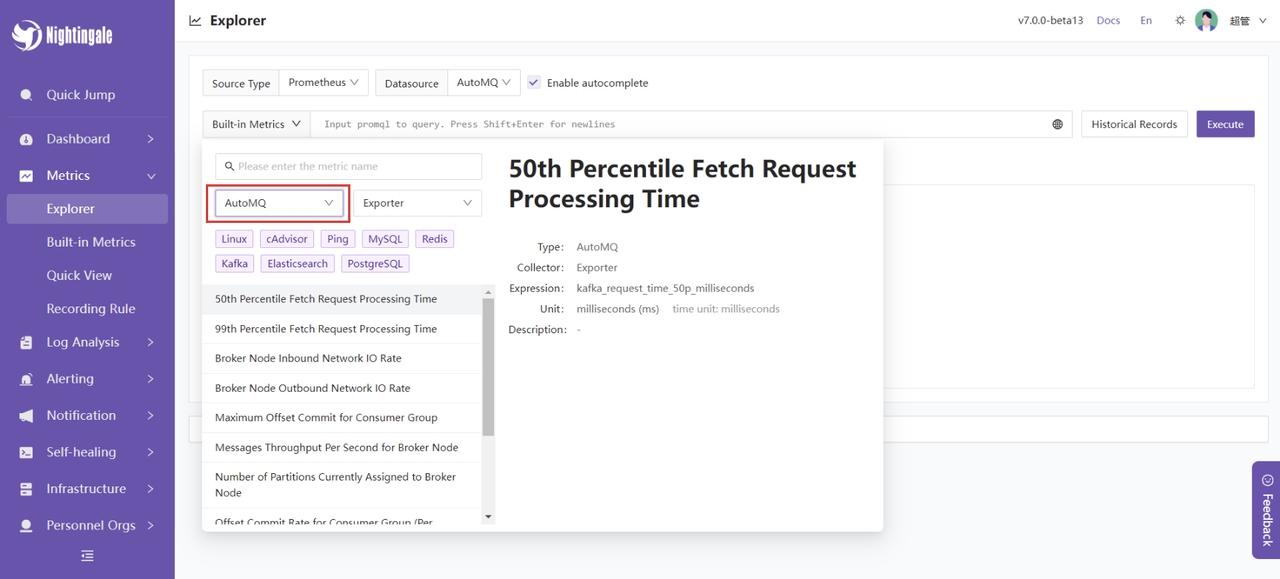
可以尝试查询一些数据,比如Fetch请求处理时间的平均值 kafka_request_time_50p_milliseconds: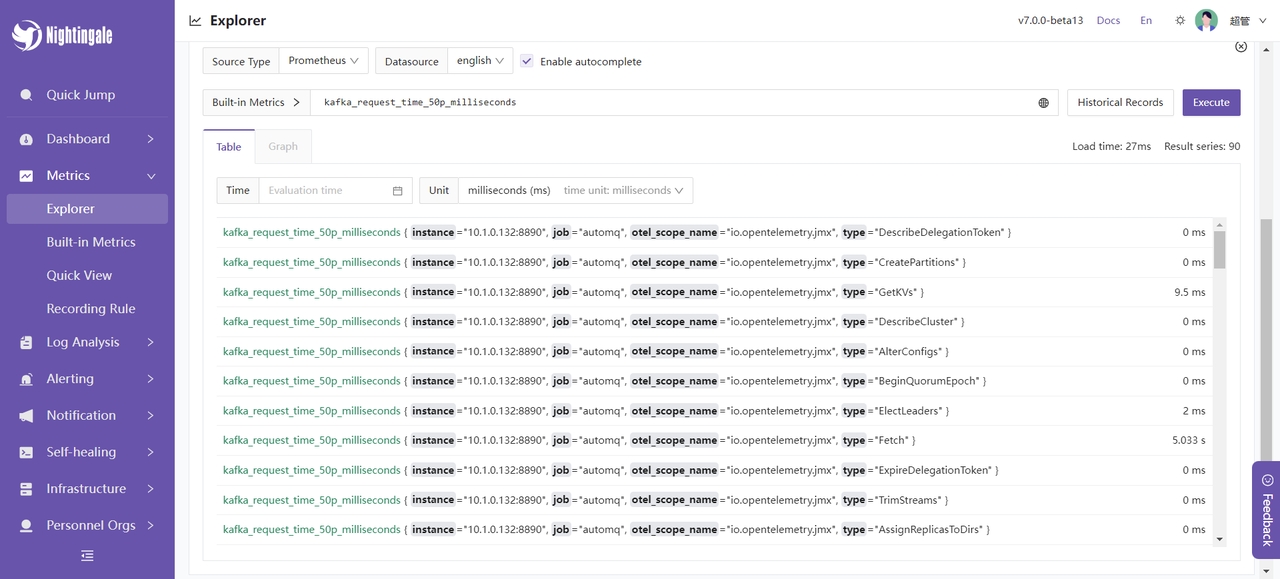
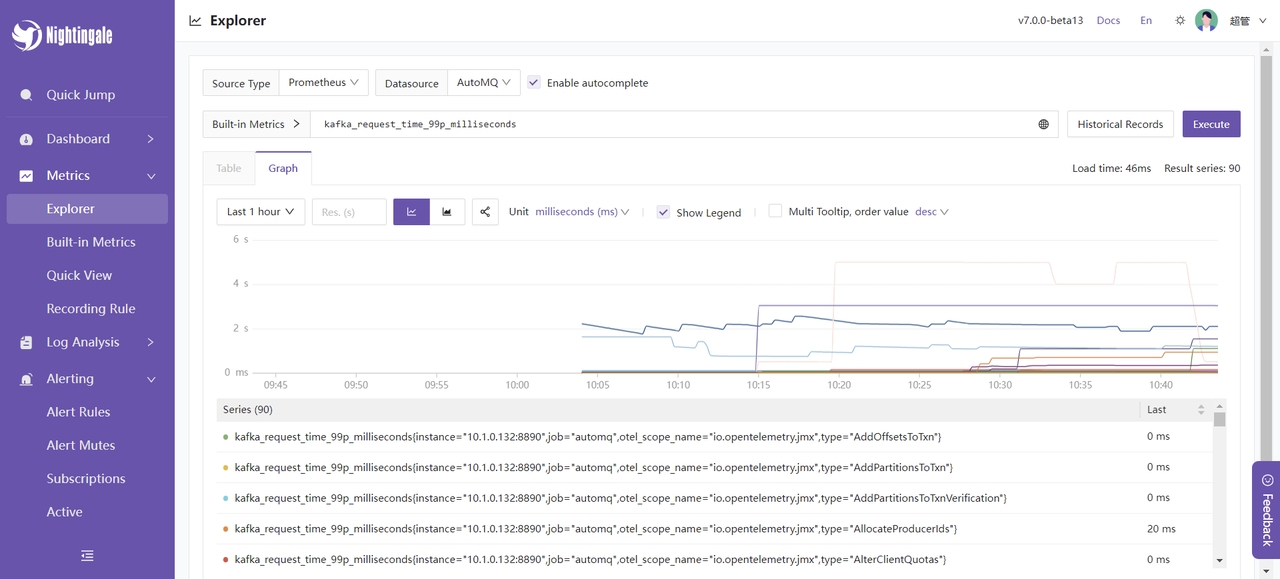
同时你也可以自定义一些指标,并利用表达式对指标进行聚合: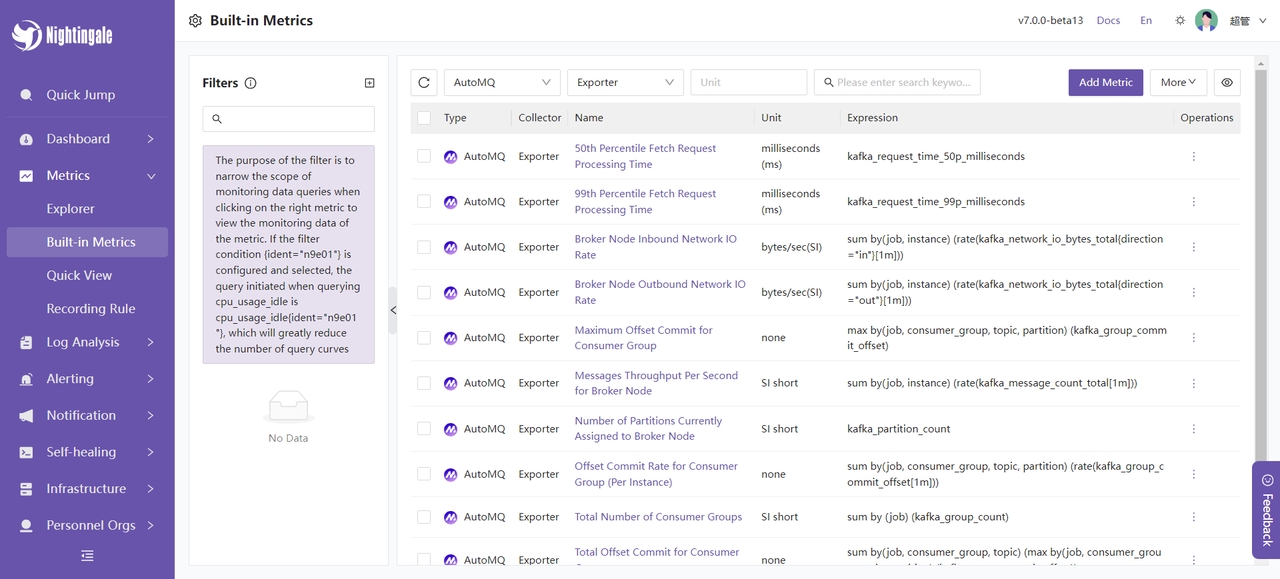
警报功能
选择左侧边栏警报 -> 警报规则 -> 新建规则。比如我们可以给 kafka_network_io_bytes_total设置报警,这个指标的意义是 Kafka Broker 节点通过网络发送或接收的字节总数,通过对这个指标设置表达式,就能够计算 Kafka Broker 节点的入站网络 I/O 速率。表达式为:
sum by(job, instance) (rate(kafka_network_io_bytes_total{direction="in"}[1m]))
设置警报规则: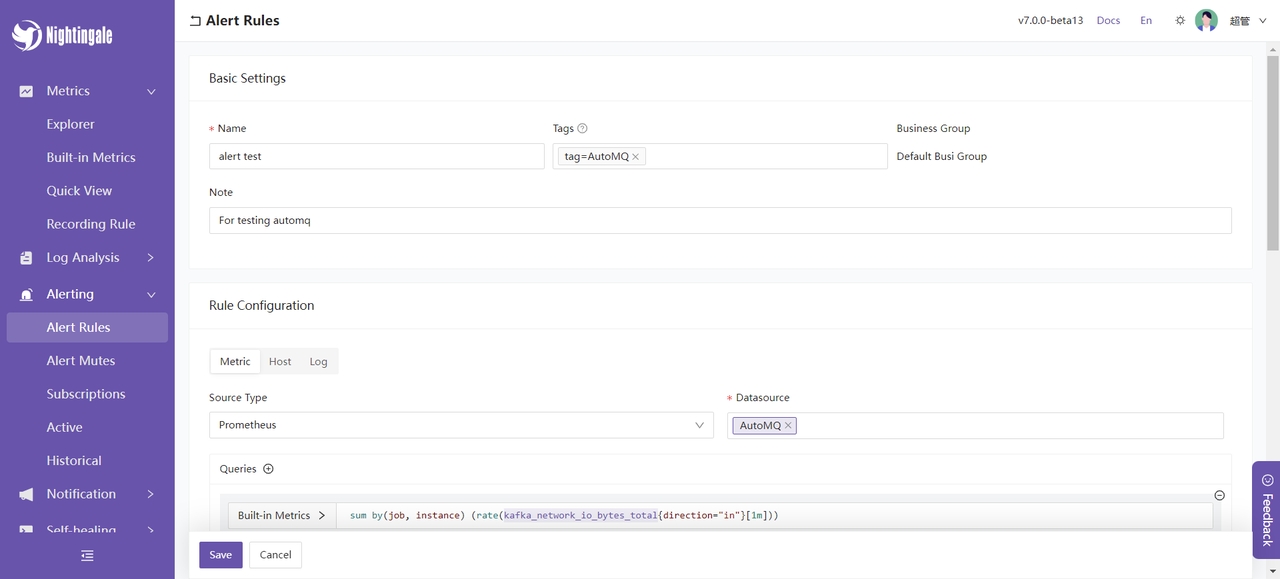
Data preview: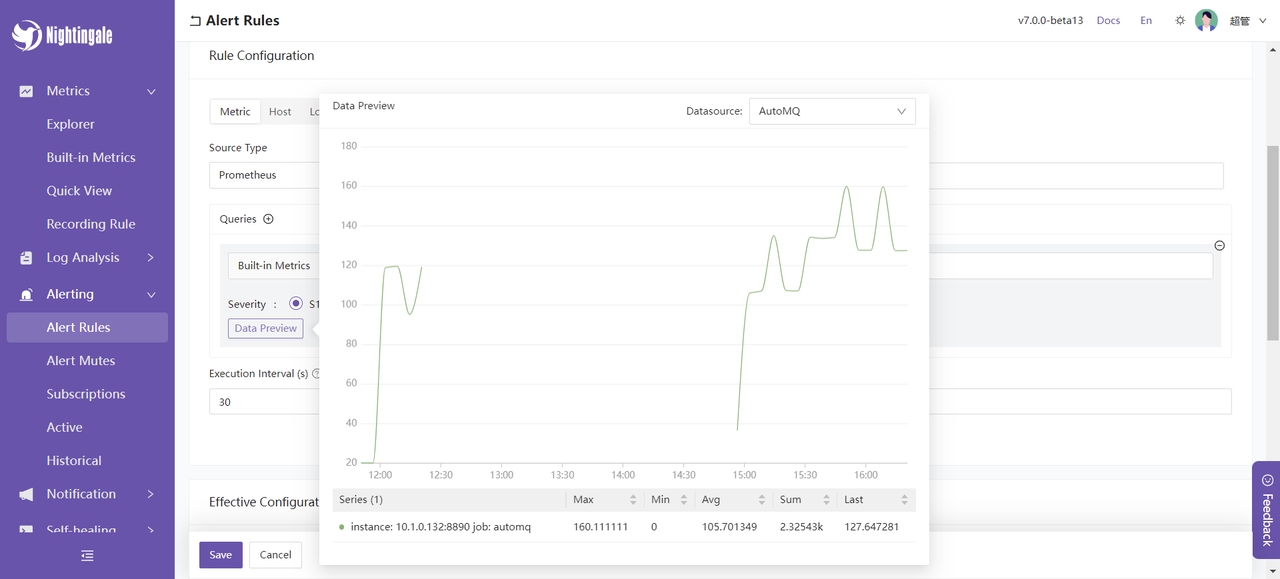
同时你也可以设置发生警报时会通知到的群组:
创建完告警后,让我们来模拟高并发的消息处理场景:短时间内总共2500000条消息被发送到 AutoMQ 节点,我采用的方式是通过 Kafka SDK 的方式进行消息发送,一次共 50 个 Topic ,给每个 Topic 发送 500 条消息,共 100 次。示例如下:
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class KafkaTest {
private static final String BOOTSTRAP_SERVERS = "http://{}:9092"; // your automq broker ip
private static final int NUM_TOPICS = 50;
private static final int NUM_MESSAGES = 500;
public static void main(String[] args) throws Exception {
KafkaTest test = new KafkaTest();
// test.createTopics(); // create 50 topics
for(int i = 0; i < 100; i++){
test.sendMessages(); // 25,000 messages will be sent each time, and 500 messages will be sent to each of 50 topics.
}
}
public void createTopics() {
Properties props = new Properties();
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
try (AdminClient adminClient = AdminClient.create(props)) {
List<NewTopic> topics = new ArrayList<>();
for (int i = 1; i <= NUM_TOPICS; i++) {
topics.add(new NewTopic("Topic-" + i, 1, (short) 1));
}
adminClient.createTopics(topics).all().get();
System.out.println("Topics created successfully");
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
public void sendMessages() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
try (KafkaProducer<String, String> producer = new KafkaProducer<>(props)) {
for (int i = 1; i <= NUM_TOPICS; i++) {
String topic = "Topic-" + i;
for (int j = 1; j <= NUM_MESSAGES; j++) {
String key = "key-" + j;
String value = "{\"userId\": " + j + ", \"action\": \"visit\", \"timestamp\": " + System.currentTimeMillis() + "}";
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
producer.send(record, (RecordMetadata metadata, Exception exception) -> {
if (exception == null) {
System.out.printf("Sent message to topic %s partition %d with offset %d%n", metadata.topic(), metadata.partition(), metadata.offset());
} else {
exception.printStackTrace();
}
});
}
}
System.out.println("Messages sent successfully");
}
}
}
随后我们可以在夜莺控制台看到报警信息: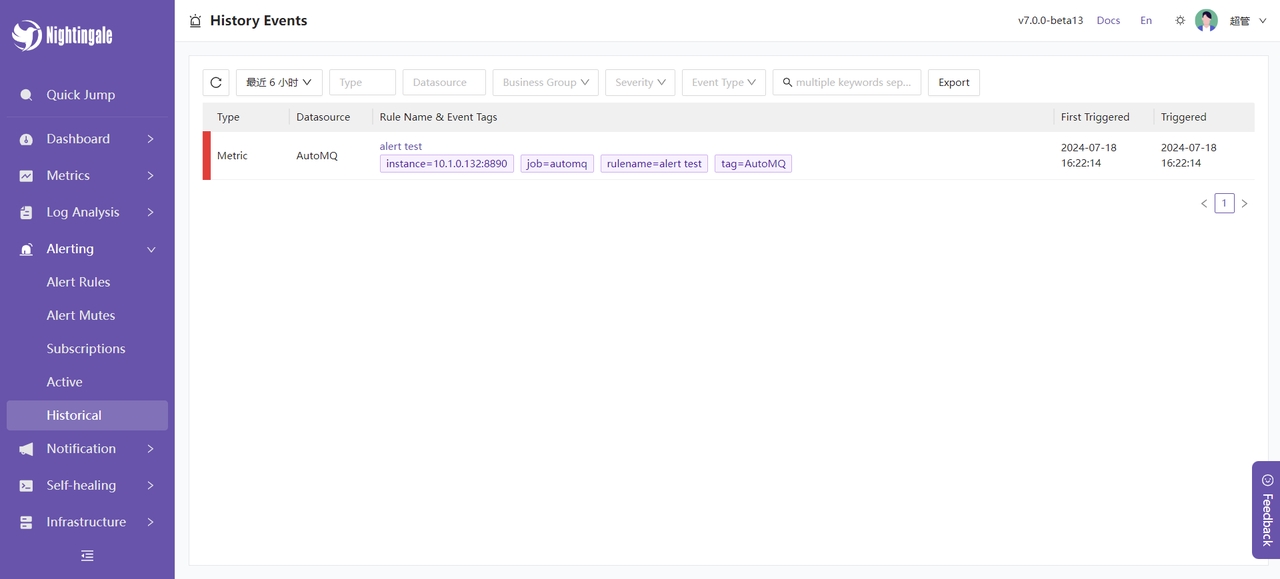
告警详细信息: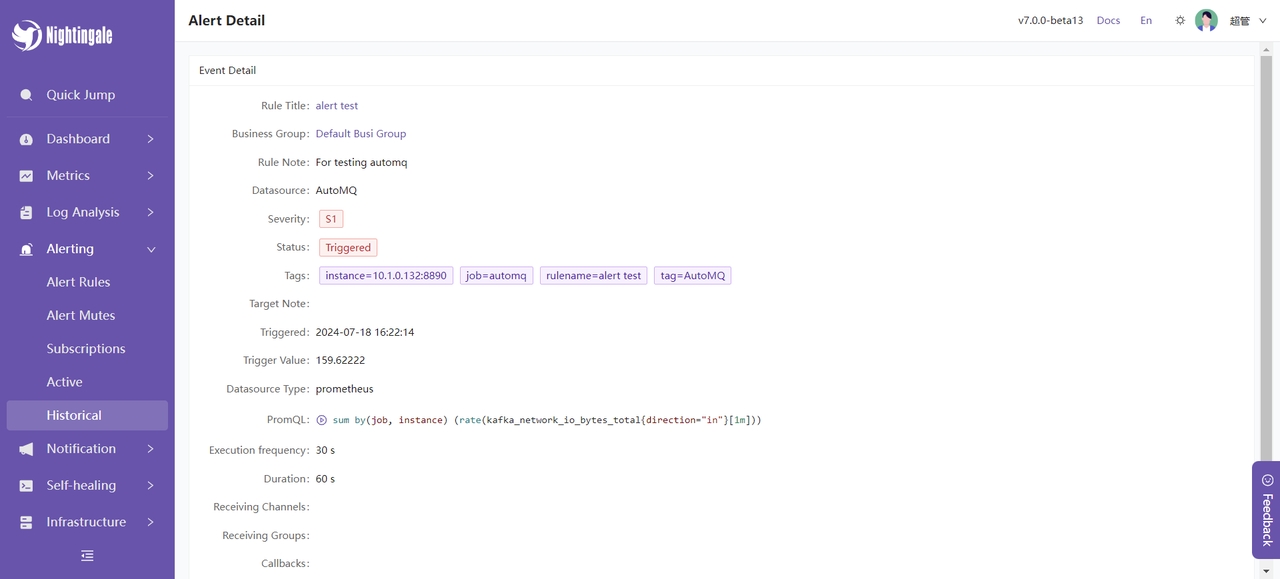
仪表盘
首先我们可以利用已知的指标建立自己的仪表盘,如下所示是对 AutoMQ 消息请求处理时间,消息总数,网络 IO 比特数进行的统计仪表盘: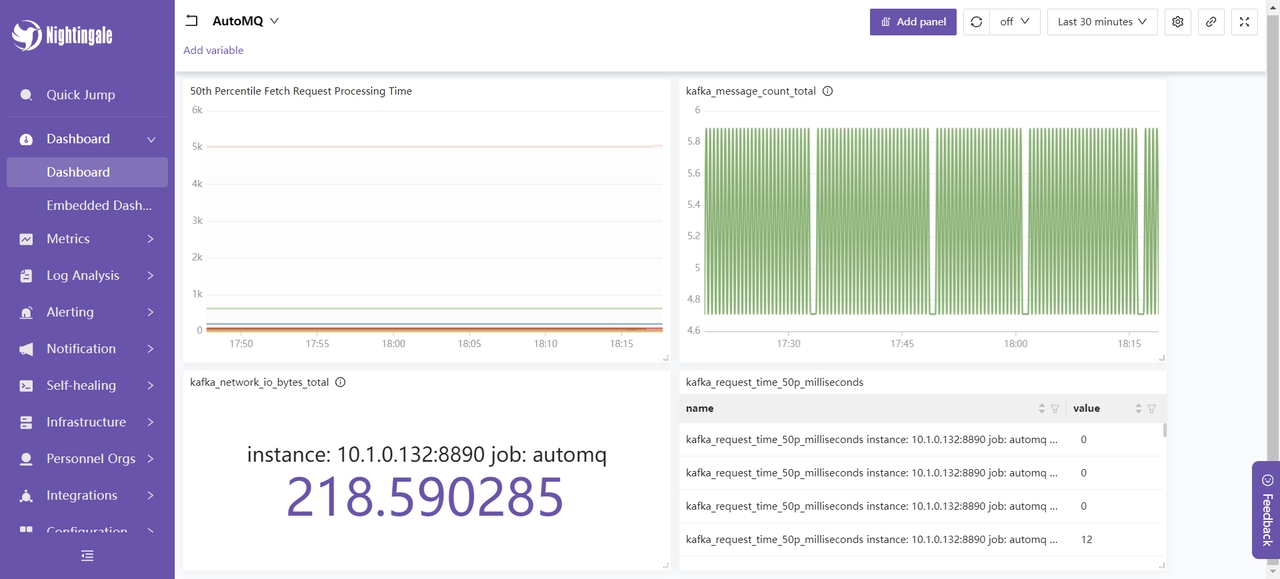
同时,我们也可以利用官方内置的仪表盘进行监测。左侧边栏 -> 聚合 -> 模板中心:
选择 AutoMQ,可以看到有几个 DashBoard 可以选用: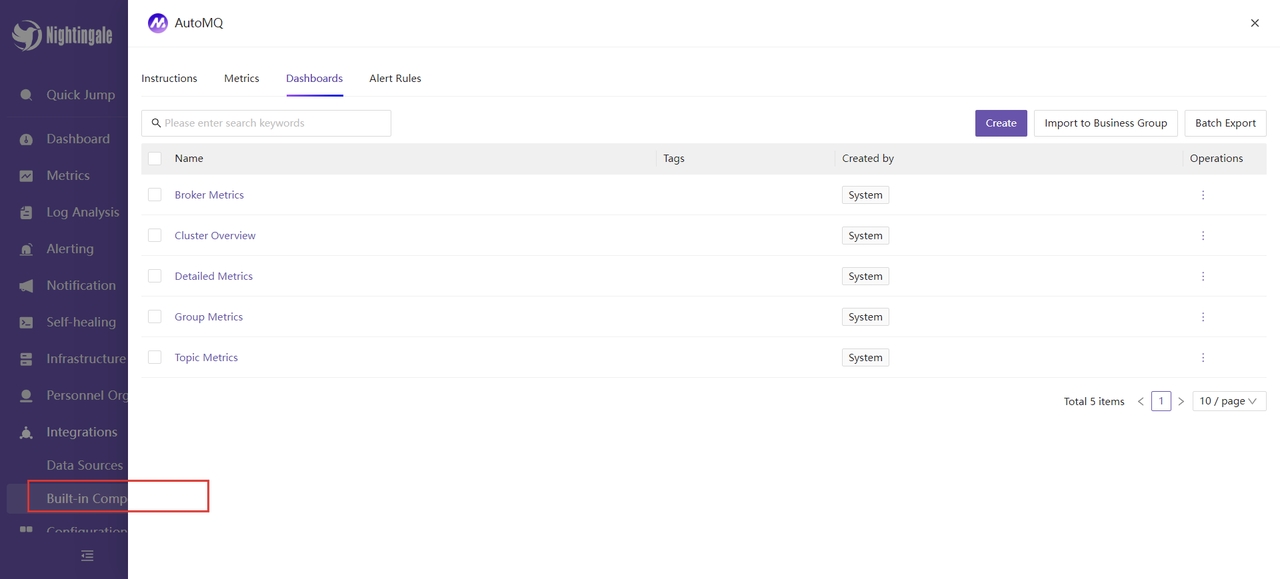
我们选择 Topic Metrics 仪表盘,展示内容如下: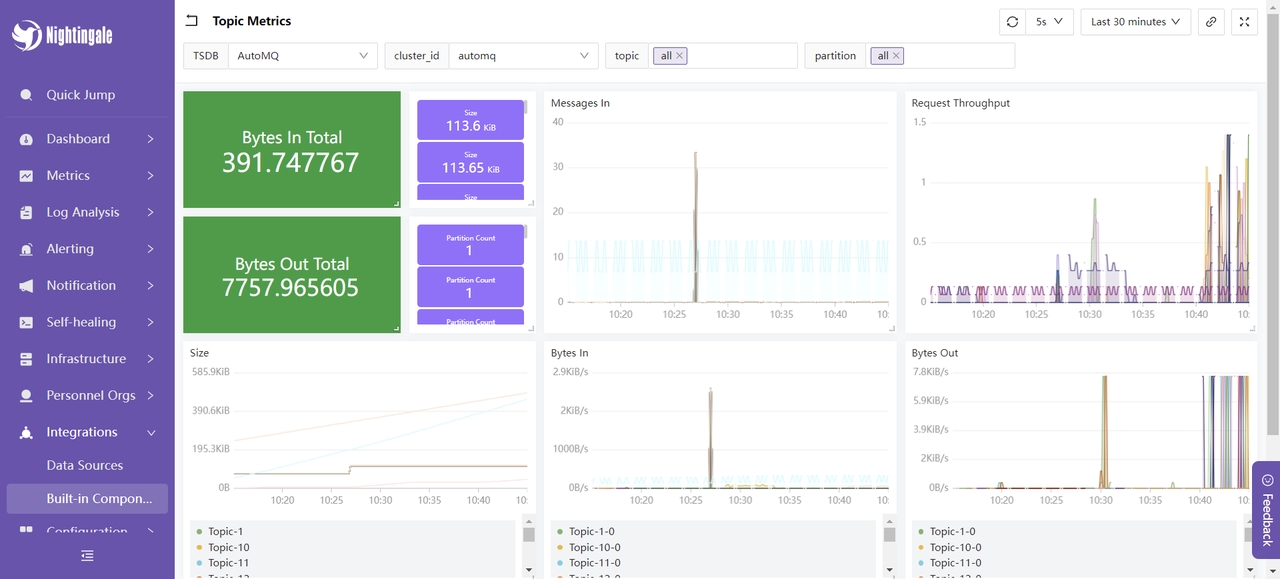
这里展示了 AutoMQ 集群在最近一段时间内的消息输入和输出的占用情况、消息输入和请求的速率、消息大小等。这些指标用于监控和优化 AutoMQ 集群的性能和稳定性:通过消息输入和输出的占用情况,可以评估生产者和消费者的负载,确保集群能正常处理消息流量;消息输入速率用于实时监控生产者发送消息的速率,从而识别潜在的瓶颈或突发流量;请求速率帮助了解客户端请求的频率,以便优化资源分配和处理能力;消息大小指标则用于分析消息的平均大小,从而调整配置以优化存储和网络传输效率。通过监控这些指标,能够及时发现并解决性能问题,确保 AutoMQ 集群的高效和稳定运行。至此,我们的集成过程已完成。关于更多的使用方式,你可以参考夜莺的官方文档 [10] 进行体验。
05
总结
通过本文的介绍,我们详细阐述了如何使用夜莺监控系统(Nightingale)对 AutoMQ 集群进行全面监控。我们从AutoMQ 和夜莺的基本概念入手,逐步讲解了如何部署 AutoMQ、Prometheus 和夜莺,并配置监控和告警规则。通过这种集成,企业可以实时掌握 AutoMQ 集群的运行状态,及时发现和解决潜在问题,优化系统性能,确保业务的连续性和稳定性。夜莺监控系统以其强大的数据采集能力、灵活的告警机制和丰富的可视化功能,成为企业监控复杂分布式系统的理想选择。希望本文能为您在实际应用中提供有价值的参考,助力您的系统运维更加高效和稳定。
引用
[1] AutoMQ:https://www.automq.com/zh
[2] 夜莺监控:https://flashcat.cloud/docs/content/flashcat-monitor/nightingale-v7/introduction/
[3] 夜莺架构:https://flashcat.cloud/docs/content/flashcat-monitor/nightingale-v7/introduction/
[4] Prometheus:https://prometheus.io/docs/prometheus/latest/getting_started/
[5] 集群方式部署 | AutoMQ:https://docs.automq.com/zh/docs/automq-opensource/IyXrw3lHriVPdQkQLDvcPGQdnNh
[6] Metrics | AutoMQ:https://docs.automq.com/zh/docs/automq-opensource/ArHpwR9zsiLbqwkecNzcqOzXn4b
[7] 将 Metrics 集成到 Prometheus:https://docs.automq.com/zh/automq/observability/integrating-metrics-with-prometheus
[8] 部署说明:https://flashcat.cloud/docs/content/flashcat-monitor/nightingale-v7/install/intro/
[9] 夜莺 Github releases:https://github.com/ccfos/nightingale
[10] 夜莺官方文档:https://flashcat.cloud/docs/content/flashcat-monitor/nightingale-v7/overview/
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com?utm_source=openwrite
-
获取apk的md5值有哪些方法?-icode9专业技术文章分享11-20
-
xml报文没有传 IdentCode ,为什么正常解析没报错呢?-icode9专业技术文章分享11-20
-
如何知道代码有没有进行 Schema 验证?-icode9专业技术文章分享11-20
-
Mycat教程:新手快速入门指南11-20
-
WebSocket入门:轻松掌握WebSocket基础11-20
-
WebSocket入门指南:轻松搭建实时通信应用11-19
-
Nacos安装资料详解:新手入门教程11-19
-
Nacos安装资料:新手入门教程11-19
-
升级 Gerrit 时有哪些注意事项?-icode9专业技术文章分享11-19
-
pnpm是什么?-icode9专业技术文章分享11-19
-
将文件或目录压缩并保留到指定的固定目录怎么实现?-icode9专业技术文章分享11-19
-
使用 tar 命令压缩文件并且过滤掉某些特定的目录?-icode9专业技术文章分享11-19
-
Nacos安装入门教程11-18
-
Nacos安装入门:轻松掌握Nacos服务注册与配置管理11-18
-
Nacos配置中心入门:新手必读教程11-18
