C/C++教程
【2024年】第6天 退化学习率 (1)——在训练的速度与精度之间找到平衡(pytorch)

本文主要是介绍【2024年】第6天 退化学习率 (1)——在训练的速度与精度之间找到平衡(pytorch),对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
- 优化器的参数lr表示学习率,代表模型在反向优化中沿着梯度方向调节的步长大小。
- 这个参数用来控制模型在优化过程中调节权重的幅度。
- 在训练中这个参数常被手动调节,用于对模型精度的提升。
- 设置学习率的大小,是在精度和速度之间找到一个平衡点。
- 如果学习率的值特别大,那么训练速度会提升,但结果的精度不够。
- 如果学习率的值比较小,那么训练结果的精度提升,但训练会耗费太多的时间。
- 通过增大批次处理样本的数量也可以起到退化学习率的效果。
- 但是这种方法要求训练时的最小批次要与实际应用中的最小批次一致。
- 一旦满足了训练时的最小批次与实际应用中的最小批次一致的条件,建议优先选择增大批次处理样本数量的方法,因为这会减少一些开发量和训练中的计算量。
1. 设置学习率的方法——退化学习率
- 退化学习率又称为学习率的衰减,它的本意是希望在训练过程中能将大学习率和小学习率各自的优点都发挥出来,即在训练刚开始时,使用大的学习率加快速度,训练到一定程度后使用小的学习率来提高精度。
- 我们可以做一个实例,让学习率随着训练步数的增加而变小,实现退化学习率的效果。
- 为了实现上述的目标,我们首先定义一个逻辑回归拟合二维数据的网络模型,代码如下所示:
import torch.nn as nn
import torch
import numpy as np
import matplotlib.pyplot as plt
# 继承nn.Module类,构建网络模型
class LogicNet(nn.Module):
def __init__(self, inputdim, hiddendim, outputdim): # 初始化网络结构
super(LogicNet, self).__init__()
self.Liner1 = nn.Linear(inputdim, hiddendim) # 定义全连接层
self.Liner2 = nn.Linear(hiddendim, outputdim) # 定义全连接层
self.criterion = nn.CrossEntropyLoss() # 定义交叉熵函数, 一定要加上括号,不可以直接写。
def forward(self, x): # 搭建用两个全连接层构建的网络模型
x = self.Liner1(x) # 将输入数据传入第1个全连接层
x = torch.tanh(x) # 对第一个连接层的结果进行非线性变换,使用激活函数tanh实现
x = self.Liner2(x) # 将网络数据传入第2个链接层
return x
def predict(self, x): # 实现LogicNet类的预测接口
# 调用自身网络模型,并对结果进行softmax处理,分别得出预测数据属于每一类的概率
pred = torch.softmax(self.forward(x), dim=1)
return torch.argmax(pred, dim=1) # 返回每组预测概率中最大值的索引
def getloss(self, x, y): # 实现LogicNet类的损失值接口
y_pred = self.forward(x)
loss = self.criterion(y_pred, y) # 计算损失值的交叉熵
return loss
- 然后我们实现让学习率随着训练的步数的增加而变小,实现退化学习率的效果,代码如下:
import sklearn.datasets # 数据集
import torch
import numpy as np
import matplotlib.pyplot as plt
from code_04_moons import LogicNet
X, Y = sklearn.datasets.make_moons(20, noise=0.2) # 生成两组半圆形数据
model = LogicNet(inputdim=2, hiddendim=3, outputdim=2) # 实例化模型
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 定义Adam优化器
xt = torch.from_numpy(X).type(torch.FloatTensor) # 将numpy数据转化为张量
yt = torch.from_numpy(Y).type(torch.LongTensor)
epochs = 1000 # 定义迭代次数
losses = [] # 定义列表,用于接收每一步的损失值
lr_list = [] # 定义列表,用于接收每一步的学习率
for i in range(epochs):
loss = model.getloss(xt, yt)
losses.append(loss.item()) # 保存中间状态的损失值
optimizer.zero_grad() # 清空之前的梯度
loss.backward() # 反向传播损失值
optimizer.step() # 更新参数
# 实现退化学习率的功能
if i %50 == 0:
for p in optimizer.param_groups: # 将学习率乘以0.99
p['lr'] *= 0.99
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(epochs), lr_list, color='r') # 输出学习率的可视化结果
plt.show()
运行结果: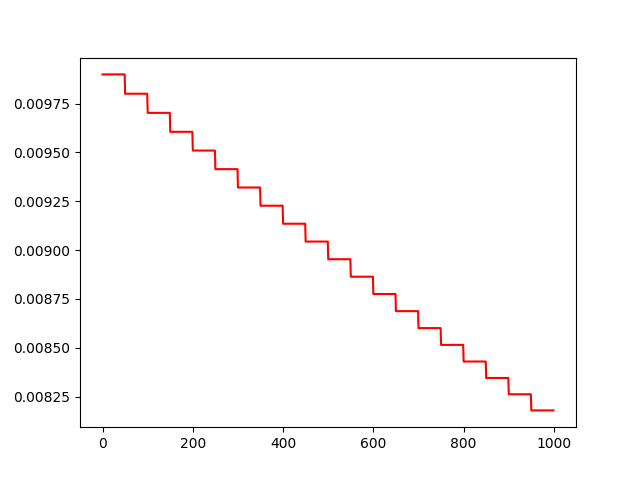
- 退化学习率功能即是实现了每训练50步,就将学习率乘以0.99的功能,,从而达到了退化学习率的效果。
2. 退化学习率接口(lr_scheduler)实现退化学习率
- 在pytorch的优化器的optim模块中,将退化学习率的多种实现方法封装到lr_sched-uler接口中,我们可以很方便的使用
- 保证我们网络模型的结构不变的前提下,使用lr_scheduler接口实现退化学习率。
import sklearn.datasets # 数据集
import torch
import numpy as np
import matplotlib.pyplot as plt
from code_04_moons import LogicNet
X, Y = sklearn.datasets.make_moons(20, noise=0.2) # 生成两组半圆形数据
model = LogicNet(inputdim=2, hiddendim=3, outputdim=2) # 实例化模型
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 定义Adam优化器
xt = torch.from_numpy(X).type(torch.FloatTensor) # 将numpy数据转化为张量
yt = torch.from_numpy(Y).type(torch.LongTensor)
epochs = 1000 # 定义迭代次数
losses = [] # 定义列表,用于接收每一步的损失值
lr_list = [] # 定义列表,用于接收每一步的学习率
# 设置退化学习率,每50步乘以0.99
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=50, gamma=0.99)
for i in range(epochs):
loss = model.getloss(xt, yt)
losses.append(loss.item()) # 保存中间状态的损失值
optimizer.zero_grad() # 清空之前的梯度
loss.backward() # 反向传播损失值
optimizer.step() # 更新参数
scheduler.step() # 调用退化学习率对象
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(epochs), lr_list, color='r') # 输出学习率的可视化结果
plt.show()
运行结果: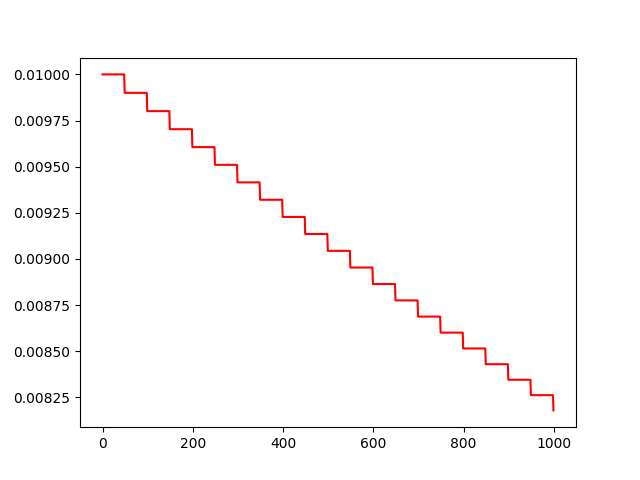
- 我们可以看到使用了lr_scheduler接口的StepLR类实例化了一个退化学习率对象。
- 该对象会被调用,通过StepLR实例化的设置即可以实现学习率每50步乘以0.99的退化效果。
3. lr_scheduler接口中的退化学习率种类
-
lr_scheduler接口还支持了多种退化学习率的实现,每种退化学习率都是通过一个类来实现的,具体的介绍如下:
- 等间隔调整学习率StepLR:每训练指定步数,学习率调整为lr=lrxgamma(gamma为手动设置的退化率参数)
- 多间隔调整学习率MultiStepLR:按照指定的步数来调整学习率。调整方式也是lr=lrxgamma.
- 指数衰减调整学习率ExponentialLR:每训练一步,学习率呈指数型衰减,即学习率调整为lr=lrxgammastep (step为训练的步数)
- 余弦退火函数调整学习率ReduceLROnPlateau:每训练一步,学习率呈余弦函数型衰减。(余弦退火指的是按照弦函数的曲线进行衰减)
- 根据指标调整学习率ReduceLROnPlateau:当某指标(loss或accuracy)在最近几次训练中均没有变化(下降或升高超过给定阈值)时,调整学习率。
- 自定义调整学习率LambdaLR:为不同参数组设定不同学习率调整策略。
-
其中LambdaLR最为灵活,可以根据需求指定任何策略的学习率变化。
-
它在fine-tune(微调模型中的一种方法)中特别有用,不但可以为不同层设置不同的的学习率,而且可以为不同层设置不同的学习率调整策略。
这篇关于【2024年】第6天 退化学习率 (1)——在训练的速度与精度之间找到平衡(pytorch)的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
您可能喜欢
-
Easysearch、Elasticsearch、Amazon OpenSearch 快照兼容对比07-29
-
基于 SASL/SCRAM 让 Kafka 实现动态授权认证07-29
-
AutoMQ 开源可观测性方案:夜莺 Flashcat07-29
-
云原生周刊:Cilium v1.16.0 发布|2024072907-29
-
如何通过 CloudCanal 实现从 Kafka 到 AutoMQ 的数据迁移07-29
-
cosmos 开发能做到跨链吗-icode9专业技术文章分享07-28
-
tar 打包时排除log目录-icode9专业技术文章分享07-28
-
unzip 指定解压目录-icode9专业技术文章分享07-28
-
possible SYN flooding on port 443. Sending cookies 什么意思-icode9专业技术文章分享07-28
-
易优如何解除绑定微信公众号-icode9专业技术文章分享07-27
-
安装 Eyoucms安装使用-icode9专业技术文章分享07-27
-
TtpeScript学习手记07-26
-
SendGrid 中单个类别(标签)名称的长度限制通常为 128 个字符。 怎么写-icode9专业技术文章分享07-26
-
SendGrid 怎么设置回复邮箱-icode9专业技术文章分享07-26
-
response, err := s.sd.SendWithContext(ctx, m) 怎么获取到唯一ID 请求ID-icode9专业技术文章分享07-26
栏目导航
