人工智能学习
SDXL Turbo实时文本到图像生成模型

建议先关注、点赞、收藏后再阅读。
SDXL Turbo在11 月 28 日发布,一种新的文本到图像模式。 。
SDXL Turbo 通过新的蒸馏技术实现了最先进的性能,能够以前所未有的质量生成单步图像,将所需的步骤数从 50 减少到仅 1。
-
该技术利用对抗性训练和分数蒸馏的组合。
-
目前是在允许个人、非商业用途的非商业研究许可证下发布的。
SDXL Turbo 基于一种称为对抗扩散蒸馏 (ADD) 的新颖蒸馏技术,该技术使模型能够一步合成图像输出并生成实时文本到图像输出,同时保持高采样保真度。 值得注意的是,SDXL Turbo 尚未用于商业用途。
对抗扩散蒸馏的优点
SDXL Turbo 在扩散模型技术方面取得了新进展,在 SDXL 1.0 的基础上进行迭代,并为文本到图像模型实现了一种新的蒸馏技术:对抗扩散蒸馏。 通过整合 ADD,SDXL Turbo 获得了与 GAN(生成对抗网络)共有的许多优势,例如单步图像输出,同时避免了其他蒸馏方法中常见的伪影或模糊。
与其他扩散模型相比的性能优势
为了选择 SDXL Turbo,我们通过使用相同的提示生成输出来比较多个不同的模型变体(StyleGAN-T++、OpenMUSE、IF-XL、SDXL 和 LCM-XL)。 然后,人类评估者会随机看到两个输出,并被要求选择最符合提示方向的输出。 接下来,用相同的方法完成图像质量的附加测试。 在这些盲测中,SDXL Turbo 能够以一步击败 LCM-XL 的 4 步配置,并且仅用 4 步击败 SDXL 的 50 步配置。 通过这些结果,我们可以看到 SDXL Turbo 的性能优于最先进的多步模型,其计算要求显着降低,而无需牺牲图像质量。
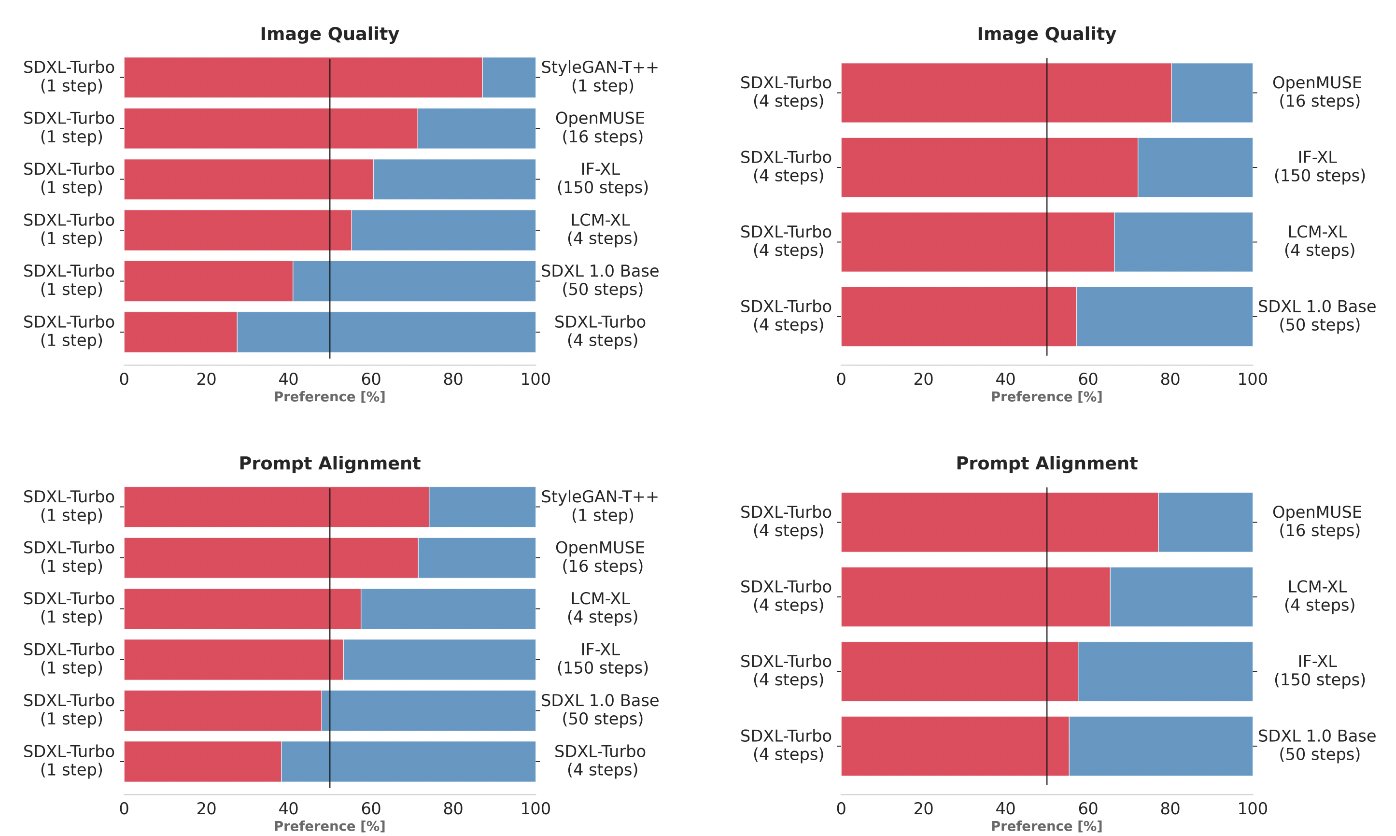
此外,SDXL Turbo 还显着提高了推理速度。 在 A100 上,SDXL Turbo 在 207 毫秒内生成 512x512 图像(即时编码 + 单个去噪步骤 + 解码,fp16),其中单个 UNet 前向评估占用了 67 毫秒。
-
酒店香薰厂家:创造独特客户体验12-24
-
程序员出海做 AI 工具:如何用 similarweb 找到最佳流量渠道?12-22
-
自建AI入门:生成模型介绍——GAN和VAE浅析12-20
-
游戏引擎的进化史——从手工编码到超真实画面和人工智能12-20
-
利用大型语言模型构建文本中的知识图谱:从文本到结构化数据的转换指南12-20
-
揭秘百年人工智能:从深度学习到可解释AI12-20
-
复杂RAG(检索增强生成)的入门介绍12-20
-
基于大型语言模型的积木堆叠任务研究12-20
-
从原型到生产:提升大型语言模型准确性的实战经验12-20
-
啥是大模型112-20
-
英特尔的 Lunar Lake 计划:一场未竟的承诺12-20
-
如何在本地使用Phi-4 GGUF模型:快速入门指南12-20
-
2025年数据与AI的十大发展趋势12-20
-
用Graph Maker轻松将文本转换为知识图谱12-20
-
视觉Transformer详解12-20
