Java教程
低配 Spring—Golang IOC 框架 dig 原理解析

0 前言
本期分享的主题是 Golang 中的 IOC 框架 dig,内容涉及到个人对编程风格的理解、对 dig 使用方法的介绍以及对 dig 底层原理的剖析.
文章内容的目录树结构如下图:
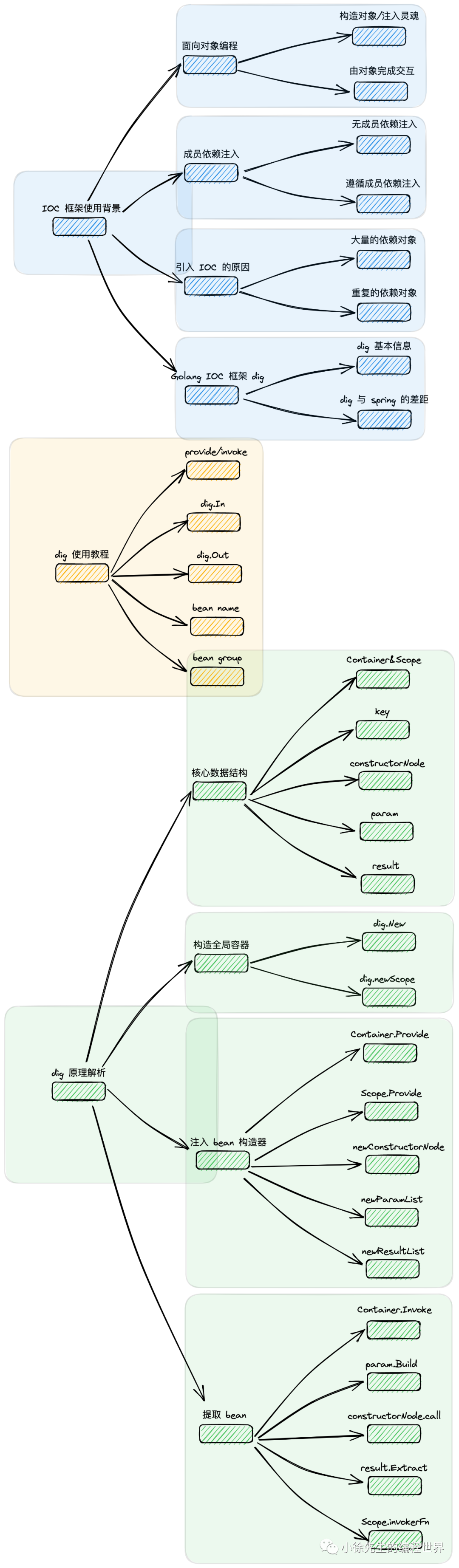
1 IOC 框架使用背景
在引入 IOC 概念之前,我们需要先补充一些前置设定:这里主要针对“面向对象编程”和“成员依赖注入”两个问题进行探讨.
1.1 面向对象编程
首先抛出一个经典问题:“面向对象和面向过程有什么区别?”
这是个抽象的问题,本质上可以划分到哲学的范畴,涉及到个人看待世界的角度.
我是个俗人,不太会聊哲学,但是代码领域的问题,我挺能聊.
下面,我们就化抽象为具象,尝试用代码实现一个场景——“把一只大象装进冰箱”.

在面向过程编程的视角下:
解决问题的核心是化整为零,把大问题拆解为一个个小问题,再针对小问题进行逐个击破.
在执行纲领的指导下,我们在编写代码时需要注重的是步骤的拆分与流程的串联.
下面展示一下伪代码:
func putElephantIntoFridge(){
// 打开冰箱门
openFridge()
// 把大象放进冰箱
putElephant()
// 关闭冰箱门
openFridge()
}
与面向过程相对,在面向对象编程的视角之下:
一切皆为对象.
在本场景中,我选择把大象和冰箱都看成是有灵魂的角色,并且准备在交互场景中给予它们更多的参与感.
于是,这里首先塑造出大象和冰箱这两种角色(声明对象类);其次再给对应的角色注入灵魂(赋予属性和方法);最后,把主动权交还给各个角色,由它们完成场景下的互动:
(1)构造对象/注入灵魂
就以大象装冰箱的场景为例,我们首先我们构造出大象和冰箱两个对象,并赋予其对应的能力,比如:
-
• 大象是有生命的,它会有自己的情绪,会有行动的能力;
-
• 冰箱作为容器,除了一些基本信息之外,最重要是具有装载事物的能力.
// 大象
type Elephant struct{
// 年龄
Age int
// 名字
Name string
// 体重
Weight int
// 身高
Height int
// ...
}
// 大象是会移动的. 试试它自己会自己爬进冰箱吗
func (e *Elephant)Move(){
// ...
}
// 注意,大象进入冰箱可能会被冻哭
func (e *Elephant) Cry(){
// ...
}
// 冰箱
type Fridge struct{
// 冰箱里存放的东西
Things map[string]interface{}
// 高度
Height int
// 宽度
Width int
// 品牌
Brand string
// 电压
Voltage int
// ...
}
// 冰箱具有装载东西的能力
func (f *Fridge)PutSomethingIn(name string, something interface{}){
// 开门
f.Open()
// 把东西放进冰箱
f.Things[name] = something
// 关门
f.Close()
}
// 打开冰箱门
func (f *Fridge)Open(){
// ...
}
// 关上冰箱门
func (f *Fridge)Close(){
// ...
}
(2)由对象完成交互
接下来,在场景的描述中,我们首先构造出参与其中的各个对象,然后通过各对象本身固有的能力完成交互.
func main(){
// new 一只大象
elephant := NewElephant()
// new 一个冰箱
fridge := NewFridge()
// 冰箱装大象
fridge.PutSomethingIn(elephant.Name, elephant)
}
通过上述例子,希望能帮助大家对面向对象的编程哲学产生更直观的感受.
1.2 成员依赖注入
在日常业务代码的编写中,我个人会比较推崇面向对象的代码风格,原因如下:
-
• 面向对象编程具有封装、多态、继承的能力,有利于系统模块之间的联动
-
• 将系统各模块划分为一个个对象,划分边界、各司其职,使得系统架构层级分明、边界清晰
-
• 对象中的核心成员属性能够被复用,避免重复构造
上述的第三点需要基于面向对象编程+成员依赖注入的代码风格加以保证.
成员依赖注入是我在依赖注入Dependency Injection(DI)概念的基础上小小调整后得到的复合概念,其指的是,在程序运行过程中,当对象A需要依赖于另一个对象B协助完成工作时,不会在代码中临时创建对象B的实例,而是遵循以下几个步骤:
-
• 前置将对象B声明为对象A的成员属性
-
• 在初始化对象A的构造函数暴露出A对B的依赖
-
• 于是在A初始化前,先压栈完成B的初始化工作
-
• 将初始化后的B注入A的构造函数,完成A的初始化
-
• 在A的生命周期内,完成对成员属性B的复用,不再重复创建
下面进一步举正反例子,对比成员依赖注入这一思想对代码风格带来的影响:
背景中,我们有三个对象,分别是:
-
• 和数据源打交道的 DAO
-
• 和第三方服务通信交互的 Client
-
• 聚集了核心业务流程的 Service,且 Service 会依赖于 DAO 和 Client 的能力
(1)无成员依赖注入
首先给出不遵循成员依赖注入的代码反例:
type Service struct{
// ...
}
func (s *Service) HandleSomeLogic(ctx context.Context, req ...)error{
// do some logic need dao proxy
dao := NewDAO()
dao.Create(...)
// do some logic need client proxy
client := NewClient()
client.Send(...)
}
在上述代码中,存在的两个局限性在于:
-
• dao、client 等核心组件的生命周期局限于一个业务方法中,因此会被重复创建. 这类组件内部本身还有依赖,其初始化过程通常是比较”重“的. 因此其多次重复创建/销毁的行为可能会带来严重的性能损耗
-
• Service 与 dao、client 强耦合,模块定位丧失灵活度. 这一点目前看来说得不够直观,可以相较第(2)部分来看
(2)遵循成员依赖注入
// 根据对 dao 模块的使用,就近将其声明为抽象的 interface
type xxxCreator interface{
Create(...)
}
// 根据对 client 模块的使用,就近将其声明为抽象的 interface
type sender interface{
Send(...)
}
// 声明 Service 类,并将依赖的核心模块 dao 和 client 声明为成员属性. 同时将成员类型抽象为 interface
type Service struct{
client sender
dao xxxCreator
}
// 在构造器函数中将依赖的核心成员变量作为入参,在调用构造器方法的入口处进行注入
func NewService(client *Client, dao *DAO)*Service{
return &Service{
client:client,
dao:dao,
}
}
// 在业务方法中,复用 Service 的 dao、client 成员变量,完成相应的工作
func (s *Service) HandleSomeLogic(ctx context.Context, req ...)error{
// do some logic need dao proxy
s.dao.Create(...)
// do some logic need client proxy
s.client.Send(...)
}
这种成员依赖注入风格的代码具有的特点包括:
-
• 依赖的核心组件一次注入,永久复用,没有重复创建所带来的成本
-
• 就近将成员抽象为 interface 后,基于多态的思路,Service 本身的定位更加灵活,取决于注入的成员变量的具体实现
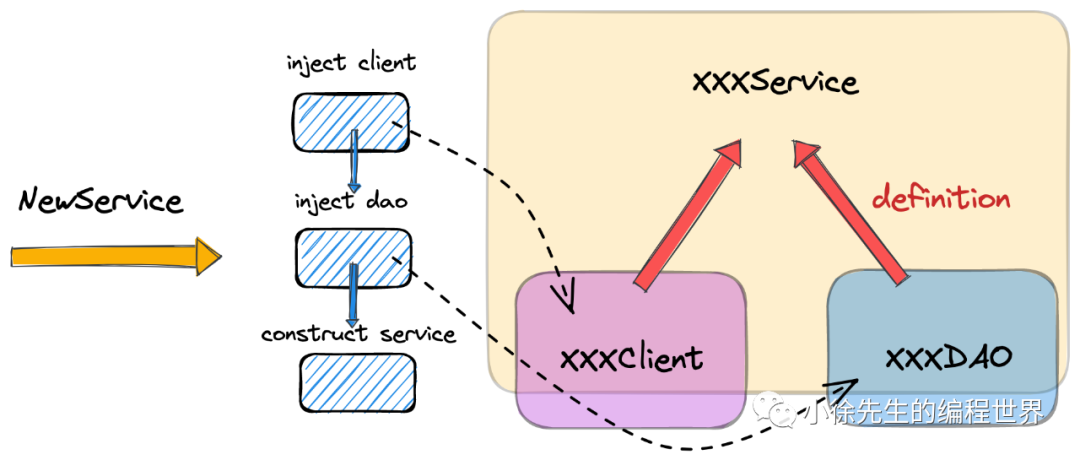
举例说明,把 dao 和 client 定义为 interface 后,
-
• 当注入和食物数据库交互的 foodDAO 和食物服务交互的 foodClient 时,service 就被定位成处理食物业务的模块
-
• 当注入和饮品数据库交互的 drinkDAO 和饮品服务交互的 drinkClient 时,service 就被定位成处理饮品业务的模块
-
• …
foodClient + foodDAO -> foodSerivce
drinkClient + drinkDAO -> drinkSerivce
…
// 注入的成员变量的属性,决定了 service 本身的定位
// foodClient + foodDAO -> foodService
foodService := NewService(&foodClient{},&foodDAO{})
// drinkClient + drinkDAO -> drinkService
drinkService := NewService(&drinkClient{},&drinkDAO{})
更进一步,倘若我们需要编写模块的单测代码,还可以实现 mock 成员变量的注入,从而实现外置依赖的代码逻辑的打桩,让单测逻辑能够好地聚焦在 Service 领域的业务代码:
mockService := NewService(&mockClient{},&mockDAO{})
- • 当注入 mockDAO 和 mockClient 时,service 就被成为了一个仅用于测试的 mock 业务模块.
1.3 引入 IOC 的原因
在 1.2 小节的基础上做个延伸性的探讨,倘若所有代码都严格遵循这种成员依赖注入的风格,一旦系统架构变得复杂,就会有新的问题产生:
(1)大量的依赖对象
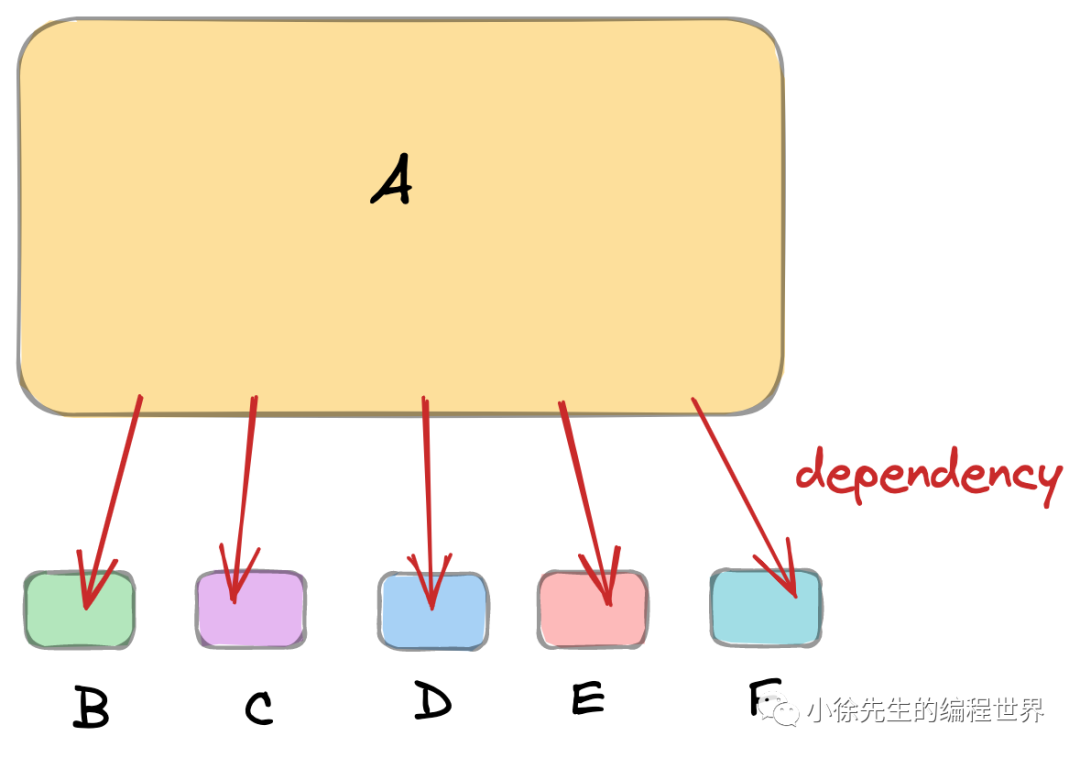
倘若对象A依赖的成员模块数量很大,每个成员都需要由构造器的调用方通过入参进行显式注入,这样编写起来代码复杂度过高:
type A struct{
B *B
C *C
D *D
E *E
F *F
...
}
func NewA(b *B, c *C, d *D, e *E, f *F, ... )*A{
// ...
}
(2)重复的依赖对象
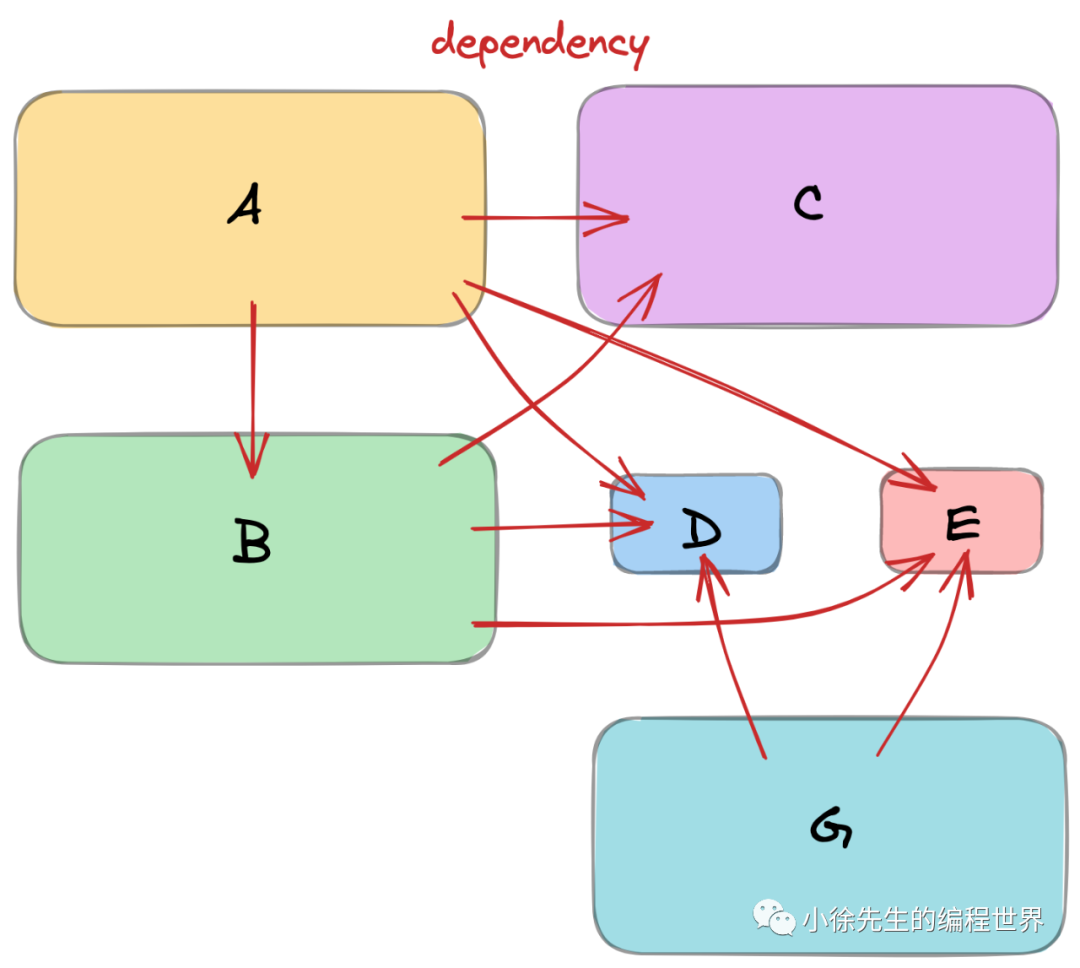
此外,依赖路径可能存在交叉的情况,最终形成一张错综复杂的依赖网,此时就会产生两个问题:
-
• 倘若某个子对象被多个父对象所依赖,如何保证子对象维持为单例状态,能够被全局复用
-
• 如何梳理好复杂的依赖路径,保证依赖注入流程的正常执行
举个代码示例如下:
type A struct{
B *B
C *C
D *D
E *E
F *F
...
}
type B struct{
C *C
D *D
E *E
F *F
...
}
type C struct{
D *D
E *E
F *F
...
}
type G struct{
E *E
F *F
..
}
梳理完上述问题后,我们的诉求也逐渐清晰:
-
• 需要有一个全局的容器,实现对各个组件进行缓存复用
-
• 需要有一个全局管理对象,为我们梳理各对象间的依赖路径,依次完成依赖注入的工作
而本文的主题—— IOC 框架,扮演的正是这样一个角色.
IOC,全称 Inversion of Control 控制反转,指的是将业务组件的创建、复制、管理工作委托给业务代码之外的容器进行统一管理. 我们通常把容器称为 container,把各个业务组件称为 bean.
由于各个 bean 组件之间可能还存在依赖关系,因此 container 的另一项能力就是在需要构建 bean 时,自动梳理出最优的依赖路径,依次完成依赖项的创建工作,最终产出用户所需要的 bean.
在这个依赖路径梳理的过程中,倘若 container 发现存在组件缺失,导致 bean 的依赖路径无法达成,则会抛出错误终止流程. 通常这个流程会在编译阶段或者程序启动之初执行,因此倘若依赖项存在缺失,也能做到尽早抛错、及时止损,引导开发人员提前解决代码问题.
1.4 Golang IOC 框架 dig
(1)dig 基本信息
聊到 IOC 框架,JAVA 中的 Spring 是一座绕不过的大山. 相对于生态成熟资源丰富的 JAVA 而言,Golang 中成熟可用的 IOC 框架就相对有限.
而今天我们要介绍的主角是由 uber 开源的 dig,git开源地址为:https://github.com/uber-go/dig,本文走读的源码版本为 tag v1.15.
(2)dig 与 spring 的差距
dig 能够为研发人员提供到前文提及的两项核心能力:
-
• bean 单例管理
-
• bean 依赖路径梳理
同时,本着实事求是的态度,我们也如实阐述一下 dig 相比于 spring 所缺失的能力:
(1)只有 IOC,不具有 AOP (Aspect Oriented Programming)的能力
(2)在同一个 key 下(bean type + bean name/group)只支持单例,不支持原型
(3)将 bean 注入 container 的方式相对单调,强依赖于构造器函数的模式
(4)由于依赖于构造器函数,因此不能解决循环依赖问题(事实上,在Golang 中,本就不支持循环依赖的模式,跨包之间的循环依赖引用,会在编译层面报错)
(5)bean 没有支持丰富的生命周期方法
2 dig 使用教程
2.1 provide/invoke
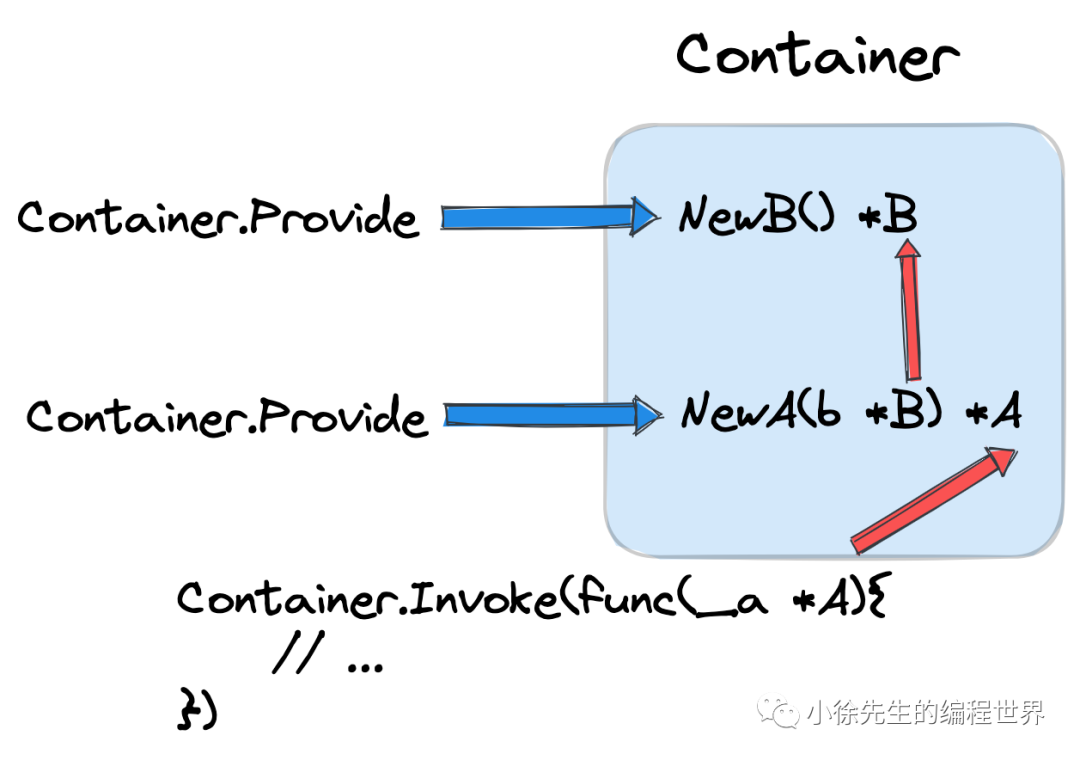
首先给出代码示例,供大家更直观地感受通过 dig 实现依赖注入、路径梳理、bean 复用的能力:
-
• 存在 bean A、bean B,其中 bean A 依赖于 bean B
-
• 声明 bean A 和 bean B 的构造器方法,A 对 B 的依赖关系需要在构造器函数 NewA 的入参中体现
-
• 通过 dig.New 方法创建一个 dig container
-
• 通过 container.Provide 方法,分别往容器中传入 A 和 B 的构造器函数
-
• 同归 container.Invoke 方法,传入 bean A 的获取器方法 func(_a *A),其中需要将获取器函数的入参类型设置为 bean A 的类型
-
• 在获取器方法运行过程中,入参通过容器取得 bean A 实例,此时可以通过闭包的方式将 bean A 导出到方法外层
// bean A,内部又依赖了 bean B
type A struct {
b *B
}
// bean A 构造器函数
func NewA(b *B) *A {
return &A{
b: b,
}
}
// bean B
type B struct {
Name string
}
// bean B 构造器函数
func NewB() *B {
return &B{
Name: "i am b",
}
}
// 使用示例
func Test_dig(t *testing.T) {
// 创建一个容器
c := dig.New()
// 注入各个 bean 的构造器函数
_ = c.Provide(NewA)
_ = c.Provide(NewB)
// 注入 bean 获取器函数,并通过闭包的方式从中取出 bean
var a *A
_ = c.Invoke(func(_a *A) {
a = _a
})
t.Logf("got a: %+v, got b: %+v", a, a.b)
}
输出结果:
/Users/didi/my_first_test/main_test.go:45: got a: &{b:0xc0005056d0}, got b: &{Name:i am b}
2.2 dig.In
2.1 小节介绍的基本用法中,我们需要将 bean A 依赖的子 bean 统统在构造器函数中通过入参的方式进行声明,倘若依赖数量较大的话,在声明构造器函数时可能存在不便,此时可以通过内置 dig.In 标识的方式替代构造函数,标志出 A 中所有可导出的成员变量均为依赖项.
dig.In 方式的使用示例如下,其中需要注意的点是:
-
• 作为依赖 bean 的成员字段需要声明为可导出类型
-
• 内置了 dig.In 标识的 bean,在通过 Invoke 流程与 container 交互时必须使用 struct 类型,不能使用 pointer 形式
type A struct {
dig.In
B *B
}
type B struct {
Name string
}
func NewB() *B {
return &B{
Name: "i am b",
}
}
func Test_dig(t *testing.T) {
// 创建一个容器
c := dig.New()
// 注入各个 bean 的构造器函数
_ = c.Provide(NewB)
// 使用 bean A 的 struct 形式,与 container 进行 Invoke 交互
var a A
_ = c.Invoke(func(_a A) {
a = _a
})
t.Logf("got a: %+v, got b: %+v", a, a.B)
}
输出结果:
/Users/didi/my_first_test/main_test.go:64: got a: {In:{_:{}} B:0xc00048e3b0}, got b: &{Name:i am b}
2.3 dig.Out
与 2.2 小节中的 dig.In 对偶,我们可以通过 dig.Out 声明,在 Provide 流程中将某个类的所有可导出成员属性均作为 bean 注入到 container 中.
与 dig.In 相仿,dig.Out 在使用时同样有两个注意点:
其中需要注意的点是:
-
• 需要作为注入 bean 的成员字段需要声明为可导出类型
-
• 内置了 dig.Out 标识的 bean,在通过 Provide 流程与 container 交互时必须使用 struct 类型,不能使用 pointer 形式
type A struct {
dig.In
B *B
C *C
}
type B struct {
Name string
}
func NewB() *B {
return &B{
Name: "i am b",
}
}
type C struct {
Age int
}
func NewC() *C {
return &C{
Age: 10,
}
}
// 内置了 dig.Out
type OutBC struct {
dig.Out
B *B
C *C
}
// 返回 struct 类型,不得使用 pointer
func NewOutBC() OutBC {
return OutBC{
B: NewB(),
C: NewC(),
}
}
func Test_dig(t *testing.T) {
// 创建一个容器
c := dig.New()
// 注入各 dig.Out 的构造器函数,需要是 struct 类型
_ = c.Provide(NewOutBC)
var a A
_ = c.Invoke(func(_a A) {
a = _a
})
t.Logf("got a: %+v, got b: %+v, got c: %+v", a, a.B, a.C)
}
输出结果:
/Users/didi/my_first_test/main_test.go:63: got a: {In:{_:{}} B:0xc0003fdd10 C:0xc000510a40}, got b: &{Name:i am b}, got c: &{Age:10}
2.4 bean name
此外,倘若存同种类型存在多个不同的 bean 实例,上层需要进行区分使用,此时 container 要如何进行标识和管理呢,答案就是通过 name 标签对 bean 进行标记,示例代码如下:
type A struct {
dig.In
// 分别需要名称为 b1 和 b2 的 bean
B1 *B `name:"b1"`
B2 *B `name:"b2"`
}
type OutB struct {
dig.Out
// 分别提供名称为 b1 和 b2 的 bean
B1 *B `name:"b1"`
B2 *B `name:"b2"`
}
func NewOutB() OutB {
return OutB{
B1: NewB1(),
B2: NewB2(),
}
}
type B struct {
Name string
}
func NewB1() *B {
return &B{
Name: "i am b111111",
}
}
func NewB2() *B {
return &B{
Name: "i am b222222",
}
}
func Test_dig(t *testing.T) {
// 创建一个容器
c := dig.New()
// 注入各个 bean 的构造器函数
_ = c.Provide(NewOutB)
var a A
_ = c.Invoke(func(_a A) {
a = _a
})
t.Logf("got a: %+v, got b1: %+v, got b2: %+v", a, a.B1, a.B2)
}
输出结果:
/Users/didi/my_first_test/main_test.go:59: got a: {In:{_:{}} B1:0xc000110c70 B2:0xc000110c80}, got b1: &{Name:i am b111111}, got b2: &{Name:i am b222222}
2.5 bean group
倘若依赖的是 bean list 该如何处理,这就需要用到 dig 中的 group 标签.
需要注意的点是,在通过内置 dig.Out 的方式注入 bean list 的时候,需要在 group tag 中声明 flatten 标志,避免 group 标识本身会将 bean 字段上升一个维度.
type A struct {
dig.In
// 依赖的 bean list
Bs []*B `group:"b_group"`
}
type B struct {
Name string
}
func NewB1() *B {
return &B{
Name: "i am b111111",
}
}
func NewB2() *B {
return &B{
Name: "i am b222222",
}
}
type BGroup struct {
dig.Out
// 提供 bean list
Bs []*B `group:"b_group,flatten"`
}
// 返回提供 bean list 的构造器函数
func NewBGroupFunc(bs ...*B) func() BGroup {
return func() BGroup {
group := BGroup{
Bs: make([]*B, 0, len(bs)),
}
group.Bs = append(group.Bs, bs...)
return group
}
}
func Test_dig(t *testing.T) {
// 创建一个容器
c := dig.New()
// 注入各个 bean 的构造器函数
_ = c.Provide(NewBGroupFunc(NewB1(), NewB2()))
var a A
_ = c.Invoke(func(_a A) {
a = _a
})
t.Logf("got a: %+v, got b1: %+v, got b2: %+v", a, a.Bs[0], a.Bs[1])
}
/Users/didi/my_first_test/main_test.go:62: got a: {In:{_:{}} Bs:[0xc000074da0 0xc000074db0]}, got b1: &{Name:i am b111111}, got b2: &{Name:i am b222222}
3 dig 原理解析
下面明确一下 dig 框架的实现原理,首先拆解一下宏观流程中的要点:
-
• 基于注入构造函数的方式,实现 bean 的创建
-
• 基于反射的方式,实现 bean 类型到到构造函数的映射
-
• 在运行时而非编译时实现 bean 的依赖路径梳理
在 dig 的实现中,bean 依赖路径的梳理时机是在服务运行阶段而非编译阶段,因此这个流程应该和业务代码解耦,专门声明一个 factory 模块聚合处理的 bean 的创建工作. 避免将 bean 获取操作零星散落在业务流程各处,这样倘若某个 bean 存在依赖缺失,则会导致服务 panic.
3.1 核心数据结构
在方法链路的源码走读和原理解析之前,先对 dig 中几个重要的数据结构进行介绍:
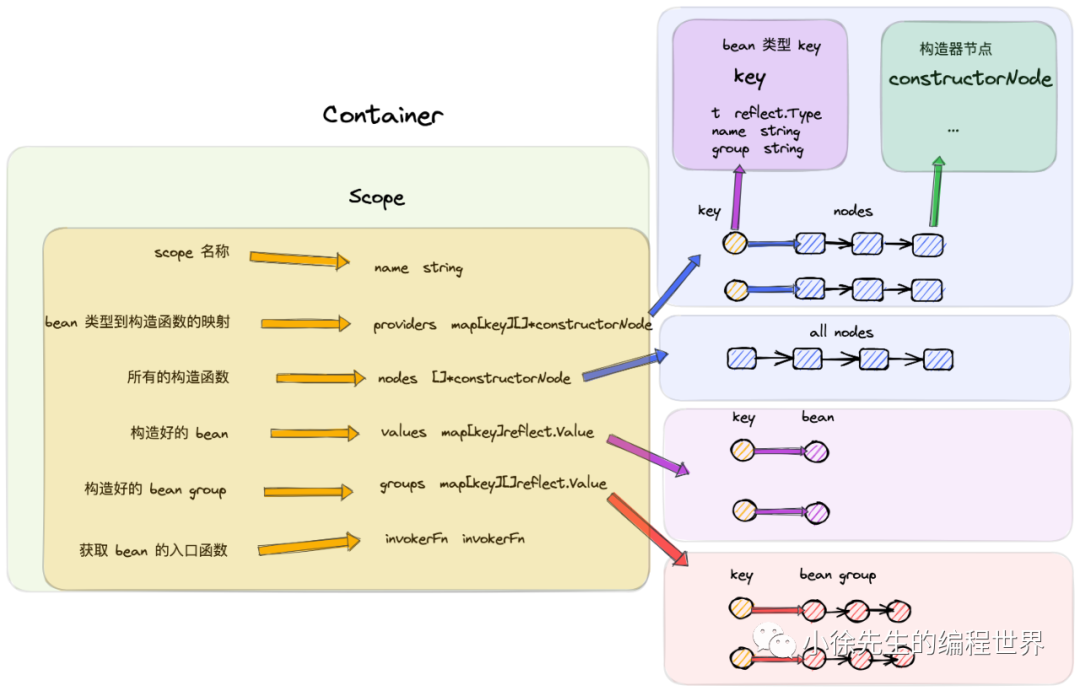
(1)Container&Scope
Container 即存放和管理 bean 的全局容器.
Scope 是一个范围块,本质上是一棵多叉树中的一个节点,拥有自己的父节点和子节点列表.
一个 Container 由一棵 Scope 多叉树构成,手中持有的是 root Scope 的引用.
目前在笔者的工程实践中未涉及到对 Scope 的使用,通常只使用一个 root Scope 就足以满足完使用诉求.
因此,在本文的介绍中,大家可以简单地把 Container 和 Scope 认为是等效的概念.
// 容器
type Container struct {
// root Scope 节点
scope *Scope
}
// 范围块
type Scope struct {
// 一个 scope 块名称
name string
// 构造器函数集合. key 是由 bean 类型和名称/组名构成的唯一键,val 是构造器函数列表. 可以看出,同一个 key 下,可能有多个构造器函数重复注入,但最终只会使用首个
providers map[key][]*constructorNode
// 注册到该 scope块中的所有构造器函数
nodes []*constructorNode
// bean 缓存集合. key 的概念同 providers 中的介绍. val 为 bean 单例.
values map[key]reflect.Value
// bean group 缓存集合. key 的概念同 providers 中的介绍. val 为 相同 key 下的 bean 数组.
groups map[key][]reflect.Value
// ...
// 从 scope 块中获取 bean 时的入口函数
invokerFn invokerFn
// 父 scope
parentScope *Scope
// 子 scope 列表
childScopes []*Scope
}
(2)key
key 是容器中的唯一标识键,由一个二元组构成. 其中一维是 bean 的类型 reflect.Type,另一维是 bean 名称 name 或者 bean 组名 group.
此处 name 字段和 group 字段是互斥关系,二者只会取其一. 因为一个 bean 被 provide 的时候,就会明确其是 single 类型还是 group 类型.
// 唯一标识键.
type key struct {
// bean 的类型
t reflect.Type
// 以下二者只会其一失效
// bean 名称
name string
// bean group 名称
group string
}
(3)constructorNode
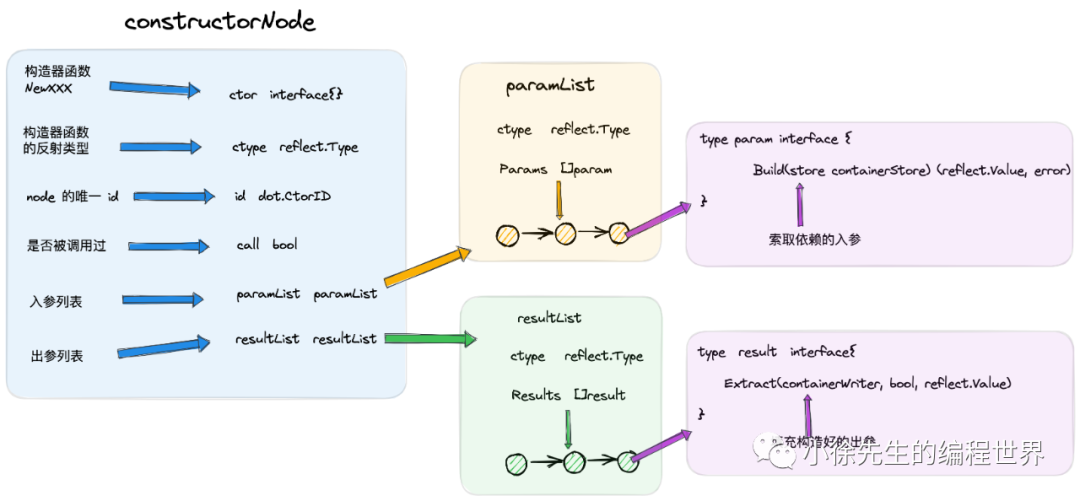
constructorNode 是构造器函数的封装节点,包含的核心字段包括:
-
• ctor:bean 构造器函数
-
• ctype:bean 构造器函数类型
-
• called:构造器函数是否已被执行过
-
• paramList:构造器函数依赖的入参
-
• resultList:构造器函数产生的出参
// 构造器节点
type constructorNode struct {
// 构造器函数
ctor interface{
// 构造器函数类型
ctype reflect.Type
// 构造器函数的位置信息,比如包、文件、代码行数等
location *digreflect.Func
// 节点 id
id dot.CtorID
// 构造器函数是否被执行过了
called bool
// 入参 list
paramList paramList
// 出参 list
resultList resultList
// ...
}
(4)param
paramList 是构造器节点的入参列表:
-
• ctype:构造器函数的类型
-
• params:入参列表
type paramList struct {
// 构造器函数类型
ctype reflect.Type
// 入参列表
Params []param
}
入参 param 本身是个 interface,核心方法是 Build,逻辑是从存储介质(容器) containerStore 中提取出对应于当前 param 的 bean,然后通过响应参数返回其 reflect.Value.
type param interface {
// ...
Build(store containerStore) (reflect.Value, error)
// ...
}
param 的实现类包括:
单个实体 bean,除了我们内置 dig.In 标识和通过 group 标签标识的情况,其他的入参 bean 都属于 paramSingle 的形式.
type paramSingle struct {
Name string
Optional bool
Type reflect.Type
}
通过 group 标签标识的 bean group
type paramGroupedSlice struct {
// ...
Group string
// ...
Type reflect.Type
// ...
}
内置了 dig.In 的 bean
type paramObject struct {
Type reflect.Type
Fields []paramObjectField
FieldOrders []int
}
// 内置了 dig.In 的 bean 中依赖的子 bean
type paramObjectField struct {
// 子 bean 的名称
FieldName string
// 子 bean 的索引
FieldIndex int
// 把子 bean 封装成 param 的类型
Param param
}
(5)result
resultList 是构造器函数节点的出参列表:
-
• ctype:构造器函数的类型
-
• Results:出参列表
type resultList struct {
// 构造器函数的类型
ctype reflect.Type
// 将出参封装成了 result 列表
Results []result
// ...
}
出参 result 本身是个 interface,核心方法是 Exact,方法逻辑是将已取得的 bean reflect.Value 填充到容器 containerWriter 的缓存 map values 当中.
type result interface {
// ...
Extract(containerWriter, bool, reflect.Value)
// ...
}
result 的实现类包括:
单个实体 bean,除了我们内置 dig.Out 标识和通过 group 标签标识的情况,其他的出参 bean 都属于 resultSingle 的形式.
type resultSingle struct {
Name string
Type reflect.Type
// If specified, this is a list of types which the value will be made
// available as, in addition to its own type.
As []reflect.Type
}
基于 group 标签标识的 bean group
type resultGrouped struct {
// Name of the group as specified in the `group:".."` tag.
Group string
// Type of value produced.
Type reflect.Type
// ...
Flatten bool
// ...
}
内置了 dig.out 的 bean.
type resultObject struct {
Type reflect.Type
Fields []resultObjectField
}
// 内置了 dig.Out 的 bean 中依赖的子 bean
type resultObjectField struct {
// 子 bean 名称
FieldName string
// 子 bean 索引
FieldIndex int
// 子 bean 封装成 result 的形式
Result result
}
3.2 构造全局容器
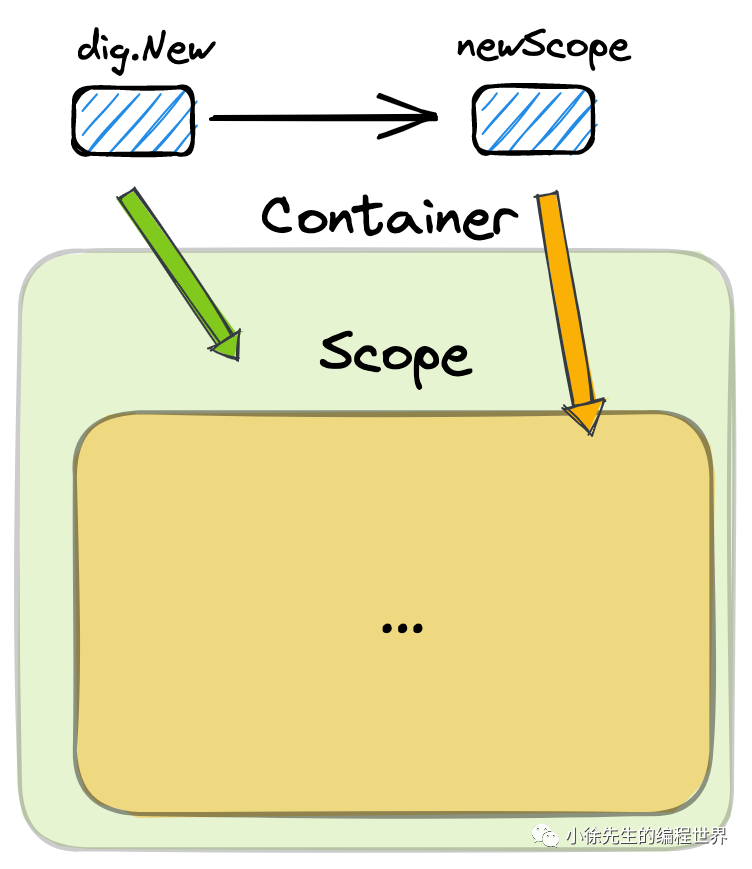
(1)dig.New
创建 dig 容器通过 dig.New 方法执行,方法中会创建一个 Container 实例,并创建一个 rootScope 注入其中.
func New(opts ...Option) *Container {
s := newScope()
c := &Container{scope: s}
for _, opt := range opts {
opt.applyOption(c)
}
return c
}
(2)dig.newCope
newScope 方法中创建了一个 Scope 实例,对 Scope 数据结构中的几个 map 成员变量进行了初始化.
值得一提的是,此处声明了获取bean 的入口函数 invokerFn 为 defaultInvoker. 其核心逻辑我们在 3.4 小节第(6)部分展开介绍.
func newScope() *Scope {
s := &Scope{
providers: make(map[key][]*constructorNode),
// ...
values: make(map[key]reflect.Value),
// ...
groups: make(map[key][]reflect.Value),
// ...
invokerFn: defaultInvoker,
// ...
}
// ...
return s
}
func defaultInvoker(fn reflect.Value, args []reflect.Value) []reflect.Value {
return fn.Call(args)
}
3.3 注入 bean 构造器
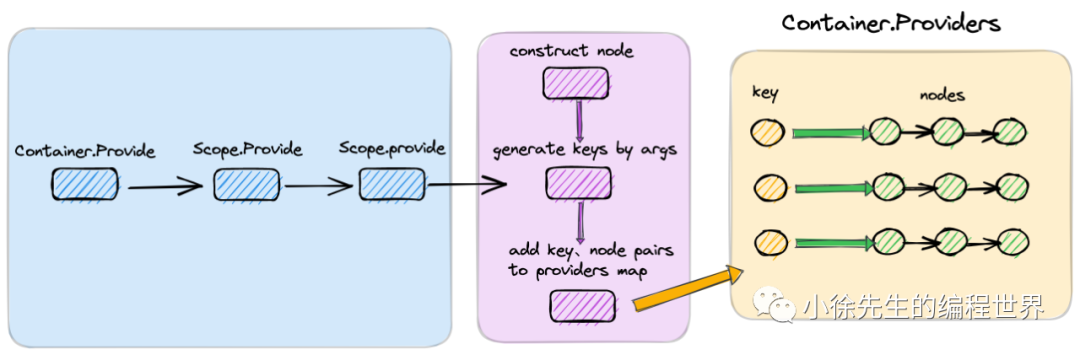
在 dig 中,将 bean 注入的方式有两类:
-
• 一种是在 bean 中内置 dig.In 标识,执行一次 Invoke 方法会自动完成 bean 的注入工作
-
• 另一种是通过 Container.Provide 方法,传入 bean 的构造器函数.
Container.Provide 是主链路,接下里沿着该方法进行源码走读.
(1)Container.Provide
经由 Container.Provide -> Scope.Provide 的链路调用后,完成了对构造器函数的类型和配置的检查,随后步入 Scope.provide 方法中.
func (c *Container) Provide(constructor interface{}, opts ...ProvideOption) error {
return c.scope.Provide(constructor, opts...)
}
func (s *Scope) Provide(constructor interface{}, opts ...ProvideOption) error {
ctype := reflect.TypeOf(constructor)
// 构造器函数类型校验
if ctype == nil {
return errors.New("can't provide an untyped nil")
}
if ctype.Kind() != reflect.Func {
return errf("must provide constructor function, got %v (type %v)", constructor, ctype)
}
// 配置项校验
var options provideOptions
for _, o := range opts {
o.applyProvideOption(&options)
}
if err := options.Validate(); err != nil {
return err
}
// 调用核心函数 Scope.provide
if err := s.provide(constructor, options); err != nil {
// ...
}
return nil
}
(2)Scope.provide
Scope.provide 方法中完成的工作是:
-
• 调用 newConstructorNode 方法,将构造器函数封装成一个 node 节点
-
• 调用 Scope.findAndValidateResults 方法,通过解析构造器出参的类型以及用户定制的 bean 名称/组名,封装出对应于出参个数的 key
-
• 将一系列 key-node 对添加到 Scope.providers map 当中,供后续的 invoke 流程使用
-
• 将新生成的 node 添加到 Scope.nodes 数组当中
func (s *Scope) provide(ctor interface{}, opts provideOptions) (err error) {
// ...
// 将构造器封装成一个节点
n, err := newConstructorNode(
// 构造器函数
ctor,
s,
// 创建构造器时,可以通过 dig.Option 实现对 bean 或者 bean group 的命名设置
constructorOptions{
ResultName: opts.Name,
ResultGroup: opts.Group,
// ...
},
)
// 根据构造器的响应参数类型,构造出一系列的 key
keys, err := s.findAndValidateResults(n.ResultList())
// 创建一个 oldProviders map 用于在当前这次 Provide 操作发生错误时进行回滚
oldProviders := make(map[key][]*constructorNode)
for k := range keys {
oldProviders[k] = s.providers[k]
// 将本次 Provide 操作新生成的 key 和 node 注入到 Scope 的 providers map 当中
s.providers[k] = append(s.providers[k], n)
}
// 循环依赖检测,倘若报错,会将 providers map 进行回滚,并抛出错误
for _, s := range allScopes {
// ...
}
// 将新生成的 node 添加到全局 nodes 数组当中
s.nodes = append(s.nodes, n)
// ...
return nil
}
(3)newConstructorNode
newConstructorNode 方法完成了将构造器函数 ctor 封装成节点的任务,其中包含几个核心步骤:
-
• 调用 newParamList 方法,将入参封装成 param 列表的形式,但还没有真正从 container 中获取 bean 执行 param 的填充动作
-
• 调用 newResultList 方法,将出参封装成 result 列表的形式,同样只做封装,没有执行将 result 注入容器的处理
-
• 结合构造器函数 ctor、入参列表 param list 和出参列表 result list,构造 constructorNode 并返回
func newConstructorNode(ctor interface{}, s *Scope, origS *Scope, opts constructorOptions) (*constructorNode, error) {
// 获取构造器函数的反射类型
cval := reflect.ValueOf(ctor)
ctype := cval.Type()
cptr := cval.Pointer()
// 创建构造器函数入参的 param list
params, err := newParamList(ctype, s)
// 创建构造器出参的 result list
results, err := newResultList(
ctype,
resultOptions{
Name: opts.ResultName,
Group: opts.ResultGroup,
// ...
},
)
// 创建 constructorNode 实例,并返回
n := &constructorNode{
ctor: ctor,
ctype: ctype,
// ...
id: dot.CtorID(cptr),
paramList: params,
resultList: results,
// ...
s: s,
// ...
}
// ...
return n, nil
}
(4)newParamList
newParamList 方法中,会根据 reflect 包的能力,获取到构造器函数的入参信息,并将其调用 newParam 方法将每个入参封装成 param 的形式.
func newParamList(ctype reflect.Type, c containerStore) (paramList, error) {
// 通过反射获取到构造器函数的入参个数
numArgs := ctype.NumIn()
// 构造 paramList 实例
pl := paramList{
ctype: ctype,
Params: make([]param, 0, numArgs),
}
// 遍历构造器函数的每个入参,将其封装一个 param
for i := 0; i < numArgs; i++ {
p, err := newParam(ctype.In(i), c)
// ...
pl.Params = append(pl.Params, p)
}
return pl, nil
}
在 newParam 方法中,会根据入参的类型,采用不同的构造方法,包括 paramSingle 和 paramObject 的类型.
func newParam(t reflect.Type, c containerStore) (param, error) {
switch {
// ...
// 内置了 dig.In 的类型
case IsIn(t):
return newParamObject(t, c)
// ...
// 默认为 paramSingle 类型
default:
return paramSingle{Type: t}, nil
}
}
(5)newResultList
newParamList 方法中,会根据 reflect 包的能力,获取到构造器函数的出参信息,并将其调用 newReject 方法将每个出参封装成 result 的形式.
func newResultList(ctype reflect.Type, opts resultOptions) (resultList, error) {
// 根据反射获取够构造器函数的出参个数
numOut := ctype.NumOut()
// 构造 resultList 实例
rl := resultList{
ctype: ctype,
Results: make([]result, 0, numOut),
resultIndexes: make([]int, numOut),
}
// 遍历出参,将除了 error 之外的出参都封装成 result 添加到 resultList 当中
resultIdx := 0
for i := 0; i < numOut; i++ {
t := ctype.Out(i)
// 出参为 error 时忽略
if isError(t) {
rl.resultIndexes[i] = -1
continue
}
// 出参封装成 result
r, err := newResult(t, opts)
// ...
rl.Results = append(rl.Results, r)
rl.resultIndexes[i] = resultIdx
resultIdx++
}
return rl, nil
}
在 newResult 方法中,会根据出参的类型,采用不同的构造方法,包括 resultSingle 和 resultObject、resultGroup 的类型.
func newResult(t reflect.Type, opts resultOptions) (result, error) {
switch {
// ...
// 内置了 dig.Out 的类型
case IsOut(t):
return newResultObject(t, opts)
// 包含了 group 的类型
case len(opts.Group) > 0:
// ...
// 默认为 resultSingle
default:
return newResultSingle(t, opts)
}
}
3.4 提取 bean
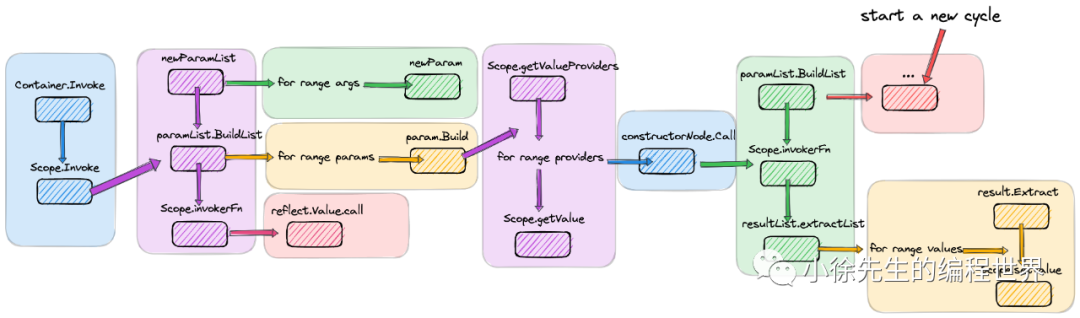
从容器中提取 bean 的入口是 Container.Invoke 方法,需要将 bean 提取器函数作为 Invoke 的第一个入参,并将提取器函数的入参声明成 bean 对应的类型.
在 dig 提取 bean 的链路中,正是根据提取器函数的入参类型作反射,从容器中提取出对应的 bean.
(1)Container.Invoke
在 Container.Invoke-> Scope.Invoke 的链路中:
-
• 针对提取器函数 function 和配置项 opts 进行了校验
-
• 通过 shallowCheckDependencies 方法进行了依赖路径的梳理,保证容器中已有的组件足以支撑构造出本次 Invoke 需要获得的 bean
-
• 调用 newParamList 方法,通过提取器函数的入参,构造出所需的 params 列表
-
• 调用 paramList.BuildList 方法,真正地从容器中提取到对应的 bean 集合,通过 args 承载
-
• 调用 Scope.invokerFn 方法,传入提取器函数 function 和对应的入参 args,通过反射机制真正地执行提取器函数 function,在执行过程中,入参 args 就已经是从容器中获取到的 bean 了
func (c *Container) Invoke(function interface{}, opts ...InvokeOption) error {
return c.scope.Invoke(function, opts...)
}
func (s *Scope) Invoke(function interface{}, opts ...InvokeOption) error {
// 检查 bean 获取器函数类型
ftype := reflect.TypeOf(function)
if ftype == nil {
return errors.New("can't invoke an untyped nil")
}
if ftype.Kind() != reflect.Func {
return errf("can't invoke non-function %v (type %v)", function, ftype)
}
// 根据 bean 获取器函数的入参,获取其所需要的 param list(bean list)
pl, err := newParamList(ftype, s)
// 检查容器是否拥有足以构造出 bean 的完整链路,若有缺失的内容,则报错
if err := shallowCheckDependencies(s, pl); err != nil {
return errMissingDependencies{
Func: digreflect.InspectFunc(function),
Reason: err,
}
}
// 从容器中获取对应的 bean list
args, err := pl.BuildList(s)
// 调用 bean Scope.invokerFn 方法,在内部会执行用户传入的 bean 获取器函数,在函数中会真正地取得 bean.
returned := s.invokerFn(reflect.ValueOf(function), args)
// ...
}
(2)param.Build
paramList.BuildList 方法,会遍历 params 列表,对每个 param 依次执行 param.Build 方法,从容器中获取到 bean 填充到 args 数组中并返回.
func (pl paramList) BuildList(c containerStore) ([]reflect.Value, error) {
args := make([]reflect.Value, len(pl.Params))
// 遍历 paramList,从容器中获取 list 中的每个 param,并添加到 args 数组中返回
for i, p := range pl.Params {
var err error
args[i], err = p.Build(c)
if err != nil {
return nil, err
}
}
return args, nil
}
以 param interface 的实现类 paramSingle 为例,paramSingle.Build 方法的执行步骤包括:
-
• 倘若 bean 已经构造过了,则通过 container.getValue 方法直接从 container.values 中获取缓存好的 bean 单例进行复用
-
• 调用 container.getValueProviders 方法,获取 bean 对应的 constructorNode
-
• 调用 constructorNode.Call 方法,通过执行 bean 的构造器函数创建 bean 并将其注入到 container.values 缓存 map 中
-
• 再次调用 container.getValue 方法,从 container.values 缓存 map 中获取 bean 并返回
func (ps paramSingle) Build(c containerStore) (reflect.Value, error) {
// ...
var providers []provider
var providingContainer containerStore
// 尝试从容器缓存的 values map 中直接获取 bean. 倘若能获取到,说明对应的 constructorNode 此前已经执行过了,此时无需重复执行.(同一 key 对应的 bean 为单例,后续统一复用)
if v, ok := container.getValue(ps.Name, ps.Type); ok {
return v, nil
}
// 通过容器的 providers map,获取到 bean 类型对应的 constructorNode
providers = container.getValueProviders(ps.Name, ps.Type)
if len(providers) > 0 {
providingContainer = container
break
}
// 执行 constructorNode,生成 bean 并注入到 container.values map 中.
for _, n := range providers {
err := n.Call(n.OrigScope())
if err == nil {
continue
}
// ...
}
// 再一次从 containers.values 中获取 bean,此时必然能够成功获取到,因为上面刚刚实现了 bean 的注入操作.
v, _ = providingContainer.getValue(ps.Name, ps.Type)
return v, nil
}
(3)constructorNode.call
constructorNode.call 方法核心步骤包括:
-
• 通过 constructorNode.called 标识,保证每个构造器函数不被重复执行
-
• 调用 shallowCheckDependencies 方法,检查构造器节点 constructorNode 入参对应的 paramList 的依赖路径是否完成
-
• 调用 paramList.BuildList 方法,将构造器节点依赖的入参 args 构造出来(此时会递归进入 3.4小节第(2)部分,从容器中提取 bean 填充构造器函数的入参 )
-
• 调用 Scope.invoker 方法,将构造器函数 constructorNode.ctor 及其入参 args 传入,通过reflect 包的能力真正执行构造器函数,完成 bean 的构造
-
• 调用 resultList.ExactList 方法,将构造生成的 bean 添加到 container.values 缓存 map 中
-
• 将 constructorNode.called 标识标记为 true,代表构造器函数已经执行过了
func (n *constructorNode) Call(c containerStore) (err error) {
// 每个 constructor 只会执行一次
if n.called {
return nil
}
// 倘若容器中的依赖项不全,导致 bean 无法构建成功,此处直接抛错
if err := shallowCheckDependencies(c, n.paramList); err != nil {
return errMissingDependencies{
Func: n.location,
Reason: err,
}
}
// ...
// constructorNode 中的构造器函数同样有依赖的入参,此时需要先从容器中获取依赖入参对应的 bean
// 于是,调用 paramList.BuildList 方法开启了新一轮的递归压栈调用
args, err := n.paramList.BuildList(c)
receiver := newStagingContainerWriter()
// 调用 Scope.invokerFn 方法,内部会通过反射真正地执行当前 constructorNode 对应的构造器函数,并将出参返回
results := c.invoker()(reflect.ValueOf(n.ctor), args)
// 通过 resultList.ExtractList 方法将出参封装成 result,添加到一个临时的 stagingContainerWriter 缓存中
if err := n.resultList.ExtractList(receiver, false /* decorating */, results); err != nil {
return errConstructorFailed{Func: n.location, Reason: err}
}
// 将stagingContainerWriter 缓存的数据统统添加到 container.values map 中
receiver.Commit(n.s)
// 标识当前 constructorNode 已经被调用过了
n.called = true
return nil
}
(4)result.Extract
在 resultList.ExtractList 方法中,会遍历传入的 results,分别执行 result.Extract 方法,依次将 bean 添加到 container.values 缓存 map 中.
func (rl resultList) ExtractList(cw containerWriter, decorated bool, values []reflect.Value) error {
// 遍历出参,依次将其添加到 containerWriter 中
for i, v := range values {
if resultIdx := rl.resultIndexes[i]; resultIdx >= 0 {
rl.Results[resultIdx].Extract(cw, decorated, v)
continue
}
// ...
}
return nil
}
同样以 resultSingle 为例,方法核心逻辑是以 result 的名称和类型组成唯一的 key,以 bean 为 value,将 key-value 对添加到 contaienr.values 缓存 map.
func (rs resultSingle) Extract(cw containerWriter, decorated bool, v reflect.Value) {
// ...
cw.setValue(rs.Name, rs.Type, v)
// ...
}
(5)Scope.invokerFn
Scope 的 invokerFn 是获取 bean 的入口函数,默认使用 defaultInvoker 函数.
func newScope() *Scope {
s := &Scope{
providers: make(map[key][]*constructorNode),
// ...
values: make(map[key]reflect.Value),
// ...
groups: make(map[key][]reflect.Value),
// ...
invokerFn: defaultInvoker,
// ...
}
// ...
return s
}
defaultInvoker 函数的形参分别为构造器函数及其依赖的入参,方法内部会依赖 reflect 库的能力,执行构造器函数,并将响应结果返回.
func defaultInvoker(fn reflect.Value, args []reflect.Value) []reflect.Value {
return fn.Call(args)
}
func (v Value) Call(in []Value) []Value {
// v 必须作为一个可导出的函数.
v.mustBe(Func)
v.mustBeExported()
return v.call("Call", in)
}
4 总结
最后来盘点一下本期我们讨论到的内容:
-
• 介绍了引入 Golang IOC 框架 dig 的背景——面向对象编程+成员依赖注入的代码风格
-
• 介绍了 dig 的基本用法:(1)创建容器 dig.New;(2)注入 bean 方法:Container.Provide;(3)提取 bean 方法:Container.Invoke
-
• 基于源码走读的方式,串讲了通过 dig 创建容器、注入 bean 构造器和提取 bean 三条方法链路的底层实现细节
-
这代码注释给我看破防了……07-29
-
提供个性化内容的15个最佳IP地理定位API07-29
-
新课终于做完了...07-29
-
测试工程师在敏捷项目中扮演什么角色?07-27
-
逆天的数学 | 数学科普07-27
-
纪录片|数学漫步之旅07-27
-
高中概率学习中如何刻画复杂的事件07-27
-
向量的投影与投影向量07-27
-
二项式定理相关问题07-27
-
Adobe国际认证(证书)认证价值详解07-26
-
01.计算机组成原理和结构07-25
-
城域网07-25
-
为什么API经济在经济不确定时期表现突出07-25
-
Python实现Java mybatis-plus 产生的SQL自动化测试SQL速度和判断SQL是否走索引07-24
-
轻松获取天气信息:免费天气API一览07-24
