Javascript
基于JSON的大型语言模型代理与Ollama及LangChain的应用

到现在为止,我们已经意识到,我们可以通过给LLM提供更多的工具来显著增强它们的能力。
例如,即使是ChatGPT,在付费版本中也可以直接使用Bing搜索引擎和Python解释器。OpenAI更进一步,提供了经过微调的大规模语言模型,用于工具使用,你可以将可用工具与提示一起传递给API端点。然后,模型会决定是直接回复,还是先使用可用工具之一。
需要注意的是,这些工具不仅限于用于检索额外信息;它们可以是任何东西,甚至可以让大模型预订晚餐。我之前做过一个项目,该项目允许大模型通过预定义的一组工具与图数据库交互,我称之为语义接口层。

一个代理型的大型语言模型(LLM)与图数据库进行交互。图由作者提供。
实际上,这些工具通过提供动态实时的信息访问、通过记忆实现个性化以及通过知识图谱实现复杂关系的识别和理解,增强了像GPT-4这样的大型语言模型。共同作用下,它们使LLM能够提供更准确的推荐,随着时间的推移,更好地理解用户偏好,并访问更广泛且最新的信息,从而带来更互动和适应性的用户体验。正如之前所述,除了在查询时可以检索额外信息之外,它们还让LLM能够影响其环境,比如在日历中安排会议。
尽管OpenAI通过其经过微调的模型让我们对工具使用感到满意,但事实是,大多数其他LLM在功能调用和工具使用方面不如OpenAI。我试过了Ollama中大多数可用的模型,大多数模型无法一致生成预定义的结构化输出来驱动代理。另一方面,也有一些模型经过微调专门用于功能调用。然而,这些模型要么未充分文档化,要么仅限于功能调用,不能用于其他用途。
最终,我决定按照现有的LangChain JSON代理实现方式,使用基于JSON的代理与Mixtral 8x7b结合。我使用Mixtral 8x7b作为电影代理,通过语义层与图形数据库Neo4j互动。该代码可在Langchain模板中找到,并附有一个[Jupyter笔记本]。如果你对这些工具的实现感兴趣,可以查看我的先前博客文章。本文将讨论如何实现基于JSON的LLM代理。
语义层里的工具LangChain 文档中的示例(JSON 代理,HuggingFace 示例)使用的工具仅接受单个字符串输入。由于语义层的工具需要更复杂的输入,我不得不深入研究一下。这里有一个推荐工具的输入示例。
all_genres = [
"动作",
"冒险",
"动画",
"儿童",
"喜剧",
"犯罪",
"纪录片",
"剧情",
"奇幻",
"犯罪悬疑片",
"恐怖",
"IMAX",
"音乐剧",
"悬疑",
"浪漫",
"科幻",
"悬疑",
"战争",
"西部",
]
class RecommenderInput(BaseModel):
movie: Optional[str] = Field(description="用于推荐的电影")
genre: Optional[str] = Field(
description=(
"用于推荐的类型。可选类型包括:" f"{all_genres}"
)
)
推荐系统有两个可选的输入:电影名称和类型。此外,我们列出了类型参数的可用值。虽然这些输入相对简单,但它们比单一字符串输入更为复杂,因此在实现时需要稍微调整。
基于 JSON 的 LLM 代理指令在我的实现过程中,我从现有的 hwchase17/react-json 提示中得到了很大的启发,该提示可以在 LangChain hub 中找到。该提示采用了以下系统消息。
请尽量准确地回答以下问题。你可以使用以下工具:
{tools}
使用工具的方法是通过提供一个json对象。
具体来说,这个json对象应该包含一个`action`键(工具的名称)和一个`action_input`键(工具的输入)。
`action`字段中只能包含以下值:{tool_names}
$JSON_BLOB应该只包含一个操作,不要返回多个操作的列表。这里是一个有效的$JSON_BLOB示例:
{
"action": $TOOL_NAME,
"action_input": $INPUT
}
始终使用以下格式: 问题:输入的问题 思路:你应该始终考虑下一步要做什么 操作:
$JSON_BLOB
观察结果: ...(这种思路/操作/观察可以重复N次) 思路:我现在知道了最终的答案 最终答案:原问题的最终答案 开始!请始终使用确切字符`最终答案`进行回复。
首先,提示定义了可用的工具,稍后我们会详细介绍这些工具。提示中最重要的部分是指导LLM输出应该是什么样的。当LLM需要调用函数时,应该使用以下的JSON结构:
{
"action": $TOOL_NAME,
"action_input": $INPUT
}
// 注意:此为原始英文文本中的模板格式,其中 $TOOL_NAME 和 $INPUT 为占位符。
那就是为什么它被称为基于 JSON 的智能代理:我们要求 LLM 在需要使用任何工具时生成一个 JSON。不过,这只是输出定义的一部分。完整的输出应该遵循以下结构:
思考:你应该始终考虑接下来该做什么
行动:(这里可以输入具体的行动描述,例如 $JSON_BLOB)
$JSON_BLOB ``` 观察:行动的后果 ...(这个思考/行动/观察过程可以重复N次,直到得到满意的结果) 最终答案:对原始问题的最终回答
LLM 在输出的思想部分中应始终解释它正在做什么。当它想要使用任何可用的工具时,应提供一个 JSON 数据块作为操作数据。观察部分专门用于工具的输出,当代理决定可以向用户提供答案时,应使用最终答案键。这里有一个电影代理人使用这种结构的例子。 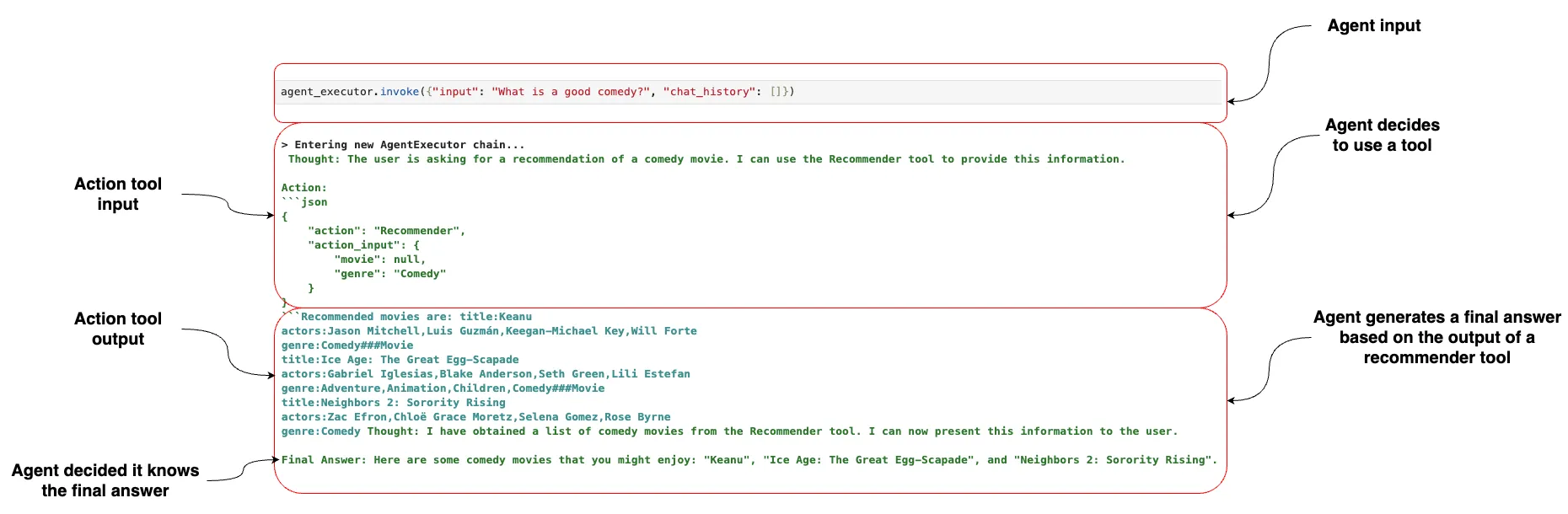 在这个例子中,我们让代理推荐一部好的喜剧作品。由于代理可用的工具之一是一个推荐工具,它决定通过提供描述其输入的 JSON 格式来利用推荐工具。幸运的是,LangChain 内置了一个这样的 JSON 代理输出解析器。接下来,LLM 从工具那里得到了响应,并将其作为提示中的观察结果。由于工具提供了所需的所有信息,LLM 认为已经获得了足够的信息来构建最终答案,并将其返回给用户。 我发现很难通过提示让Mixtral只在需要用到工具时才使用JSON语法。在我的实验中,当它不想使用任何工具时,有时会错误地使用以下JSON输入。
{{
"action": Null,
"action_input":""
}}
LangChain中的解析输出的函数不会因为动作为空或类似情况而忽略它,而是返回一个未定义空工具的错误信息。我尝试向工程师寻求这个错误的解决方案,但未能以一致的方式解决。因此,我决定添加一个假的闲聊工具来应对,这样当用户想要闲聊时,代理就可以调用这个工具了。
response = (
"创建一个最终答案,说明他们是否有关于电影或演员的问题。"
)
class SmalltalkInput(BaseModel):
query: Optional[str] = Field(description="用户查询")
class SmalltalkTool(BaseTool):
name = "Smalltalk"
description = "当用户问候你或想要闲聊时很有用"
args_schema: Type[BaseModel] = SmalltalkInput
def _run(
self,
query: Optional[str] = None,
run_manager: Optional[CallbackManagerForToolRun] = None,
) -> str:
"""使用工具."""
return response
这样一来,代理可以在用户问候它时选择使用一个模拟工具,这样我们就不会再遇到解析空或未定义工具名的问题。 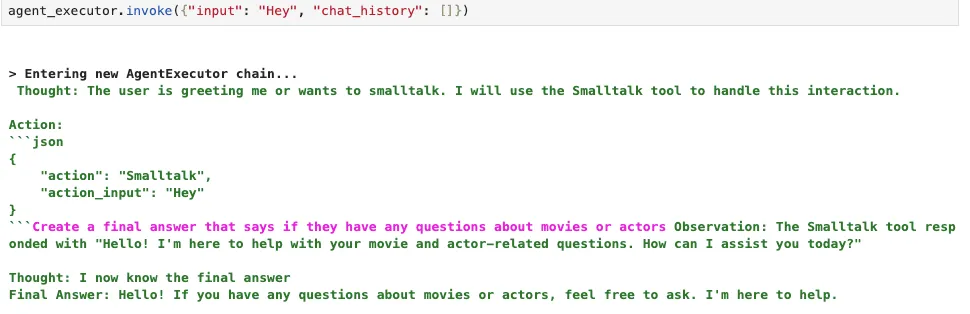 这个变通方法效果相当不错,所以我决定保留它。如前所述,大多数模型没有经过训练来在不需要操作时生成所需的动作输入或文本,所以我们只能利用当前可用的功能。然而,有时模型在第一次迭代时也不会调用任何工具,这得看具体情况。但是,提供类似闲聊工具这样的退出选项似乎可以防止出错。 ## 在系统提示中定义工具输入项 如前所述,我需要弄清楚如何定义稍微复杂一些的工具输入定义,以便LLM能够正确理解这些输入。有趣的是,在实现了一个自定义函数后,我发现了一个现有的LangChain函数,它可以将自定义的Pydantic工具输入定义转换为JSON对象,Mixtral可以识别。
from langchain.tools.render 导入 render_text_description_and_args # 渲染文本描述和参数
tools = [RecommenderTool(), InformationTool(), Smalltalk()]
tool_input = render_text_description_and_args(tools)
print(tool_input) # 打印工具输入
生成如下字符串说明:
"Recommender":"当你需要推荐电影时很有用",
"args":{
"参数":{
"movie":{
{
"title":"电影",
"description":"用于推荐的电影",
"type":"string"
}
},
"genre":{
{
"title":"类型名称",
"description":"用于推荐的电影类型。可选选项为:['动作', '冒险', '动画', '儿童', '喜剧', '犯罪', '纪录片', '戏剧', '奇幻', '黑色电影(Film-Noir)', '恐怖', 'IMAX', '音乐', '悬疑', '浪漫', '科幻', '惊悚', '战争', '西部']",
"type":"string"
}
}
}
},
"Information":"当你需要回答关于各种演员或电影的问题时很有用",
"args":{
"参数":{
"entity":{
{
"title":"实体",
"description":"问题中提到的电影或人",
"type":"string"
}
},
"entity_type":{
{
"title":"实体类型",
"description":"实体的类型。可选选项为 '电影' 或 '人'",
"type":"string"
}
}
}
},
"Smalltalk":"当你问候或者想要闲聊时很有用",
"args":{
"参数":{
"query":{
{
"title":"查询",
"description":"用户的查询",
"type":"string"
}
}
}
}
我们可以直接将这个工具描述复制到系统提示中,Mixtral 就能用这些定义好的工具了,这还挺酷的。 ## 结论如下 基于JSON的代理大部分工作是由Harrison Chase和LangChain团队完成的,我对此非常感谢。我所要做的就是找到各个组件,把它们拼起来就好了。如前所述,不要期望代理能达到GPT-4那样的性能。然而,我认为像Mixtral这样的更强大的开源LLM今天可以用来做代理(需要稍微多一些异常处理)。我期待更多的开源LLM能够被微调成代理。 代码可以在 [Langchain 模板](https://github.com/langchain-ai/langchain/tree/master/templates/neo4j-semantic-ollama) 中找到,也可以在 [Jupyter 笔记本文件](https://github.com/tomasonjo/blogs/blob/master/llm/ollama_semantic_layer.ipynb) 中找到。
-
Vue3教程:新手入门全面指南11-15
-
Vue3教程:新手入门与基础实践11-15
-
Vue教程:初学者必备的Vue.js入门指南11-15
-
useCallback教程:React Hook入门与实践11-15
-
React中使用useContext开发:初学者指南11-15
-
拖拽排序js案例详解:新手入门教程11-15
-
React中的自定义Hooks案例详解11-15
-
受控组件项目实战:从零开始打造你的第一个React项目11-14
-
React中useEffect开发入门教程11-14
-
React中的useMemo教程:从入门到实践11-14
-
useReducer开发入门教程:轻松掌握React中的useReducer11-14
-
useRef开发入门教程:轻松掌握React中的useRef用法11-14
-
useState开发:React中的状态管理入门教程11-14
-
React教程:新手入门及初级实战指南11-14
-
自制GPT模型玩起来:基于TensorFlow.js的简易实现11-14
