Python教程
【Python爬虫】批量爬取图片的简单案例

本文主要是介绍【Python爬虫】批量爬取图片的简单案例,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
@TOC
1.原理
网页中的图片有自己的URL,访问这些URL可以直接得到图片,譬如,访问下面这个URL,你就能得到一张图片:
https://img-blog.csdnimg.cn/a3bad4725ba94301b7cba7dd8209fea4.png#pic_center
所以,批量爬取图片的过程,就是批量获取URL的过程
2.寻找批量的图片URL的储存地址
- 各个网站批量获得图片URL的方式略有不同,此处先以必应举例。
2.1 百度
- 打开百度进行图片搜索,并按下F12打开开发者模式
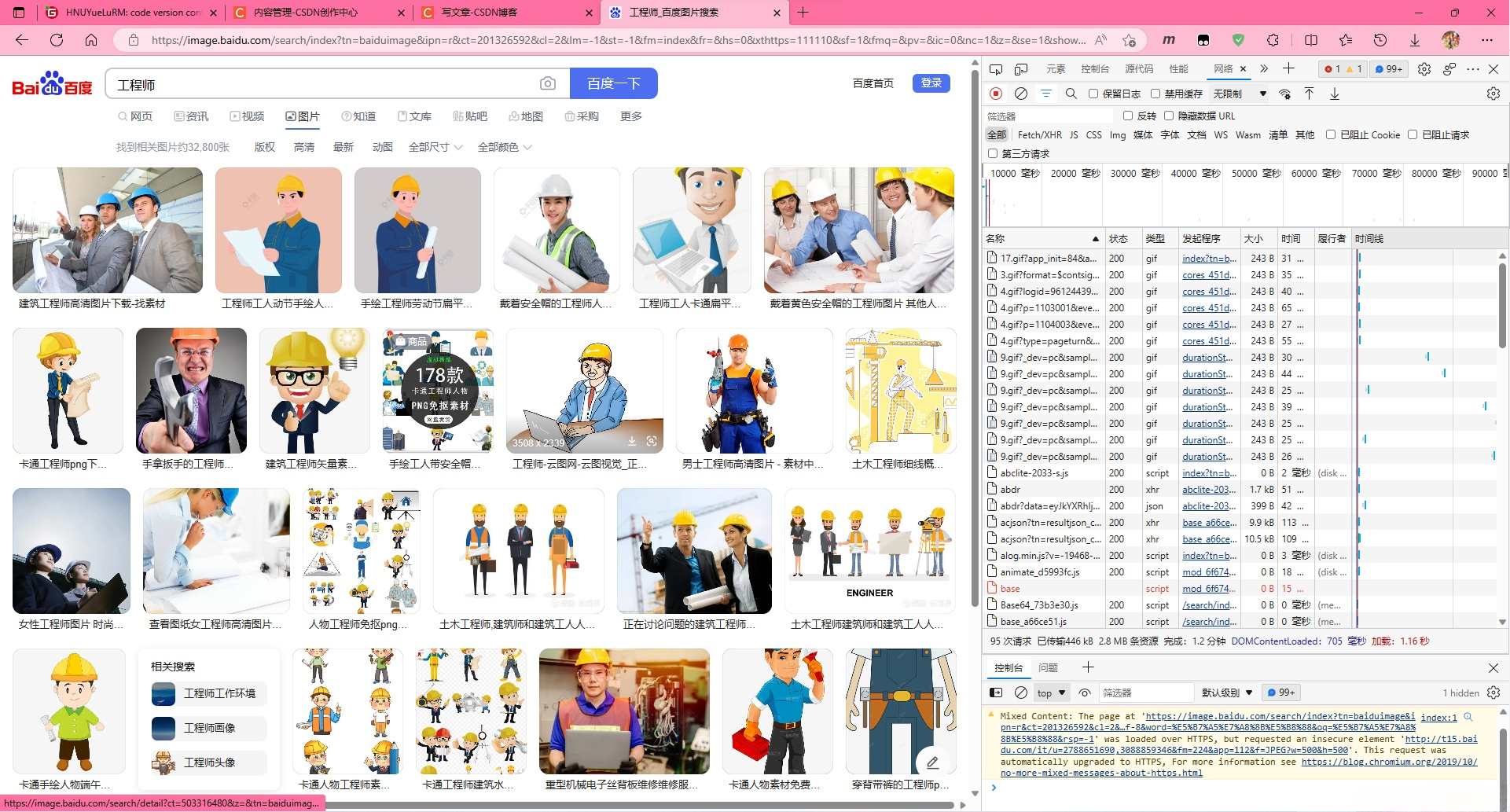
- 在更多工具中打开“网络”
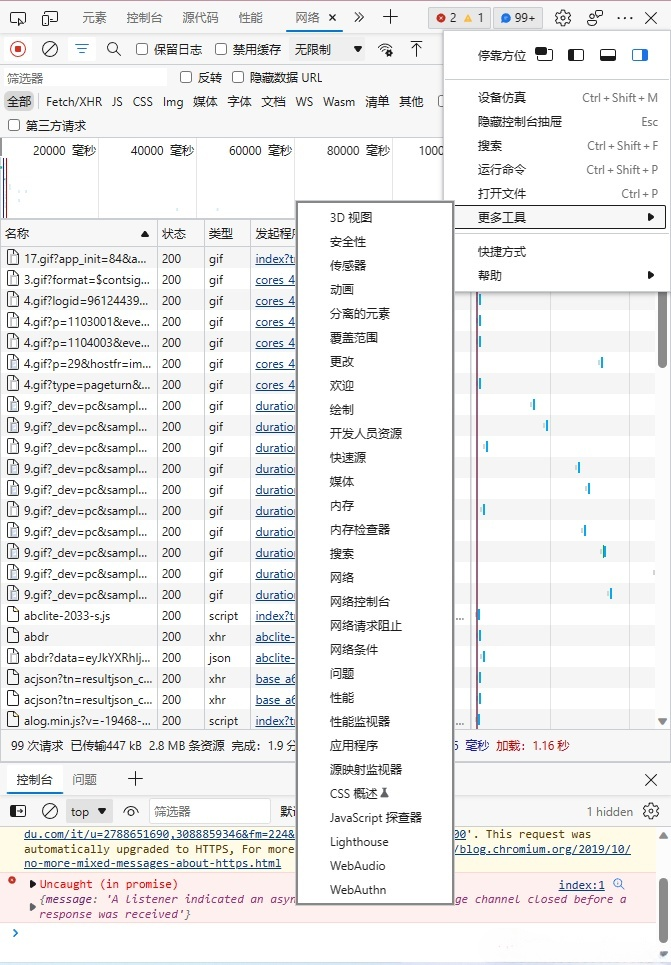
- 找到这类请求
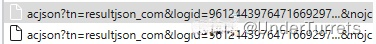
- 相应的描述如图
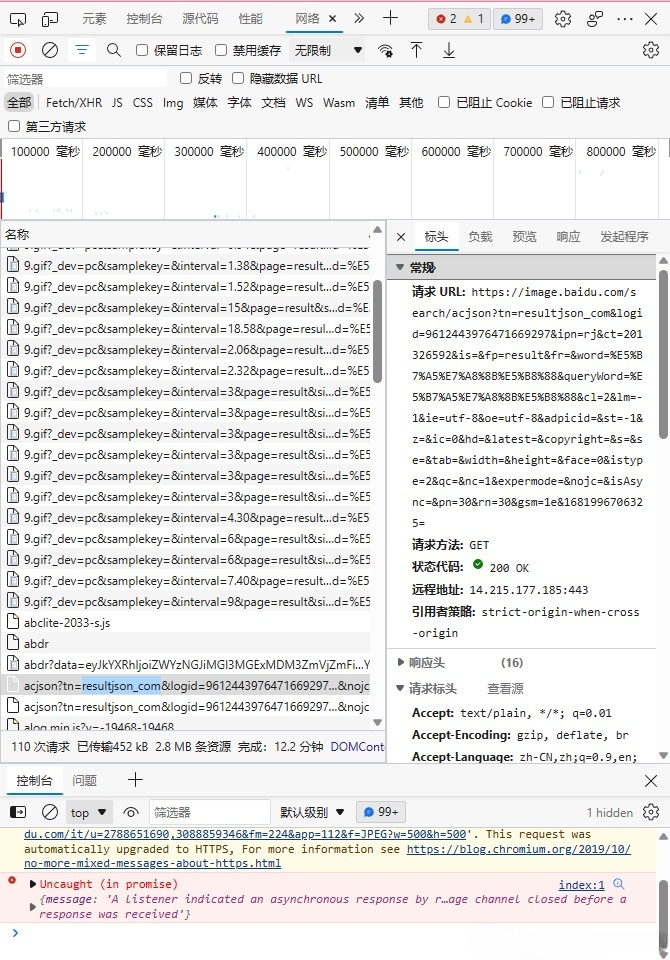
- 事实上,百度图片的URL信息都储存在这类请求中。这类请求的完整URL如下:
https://image.baidu.com/search/acjson?tn=resultjson_com&logid=9612443976471669297&ipn=rj&ct=201326592&is=&fp=result&fr=&word=%E5%B7%A5%E7%A8%8B%E5%B8%88&queryWord=%E5%B7%A5%E7%A8%8B%E5%B8%88&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1681996706325=
- 其中的pn参数,决定了展示的图片个数,且是30的倍数
- queryWord参数和word参数,是搜索的关键词
- 访问这个URL,会得到如下杂乱的信息
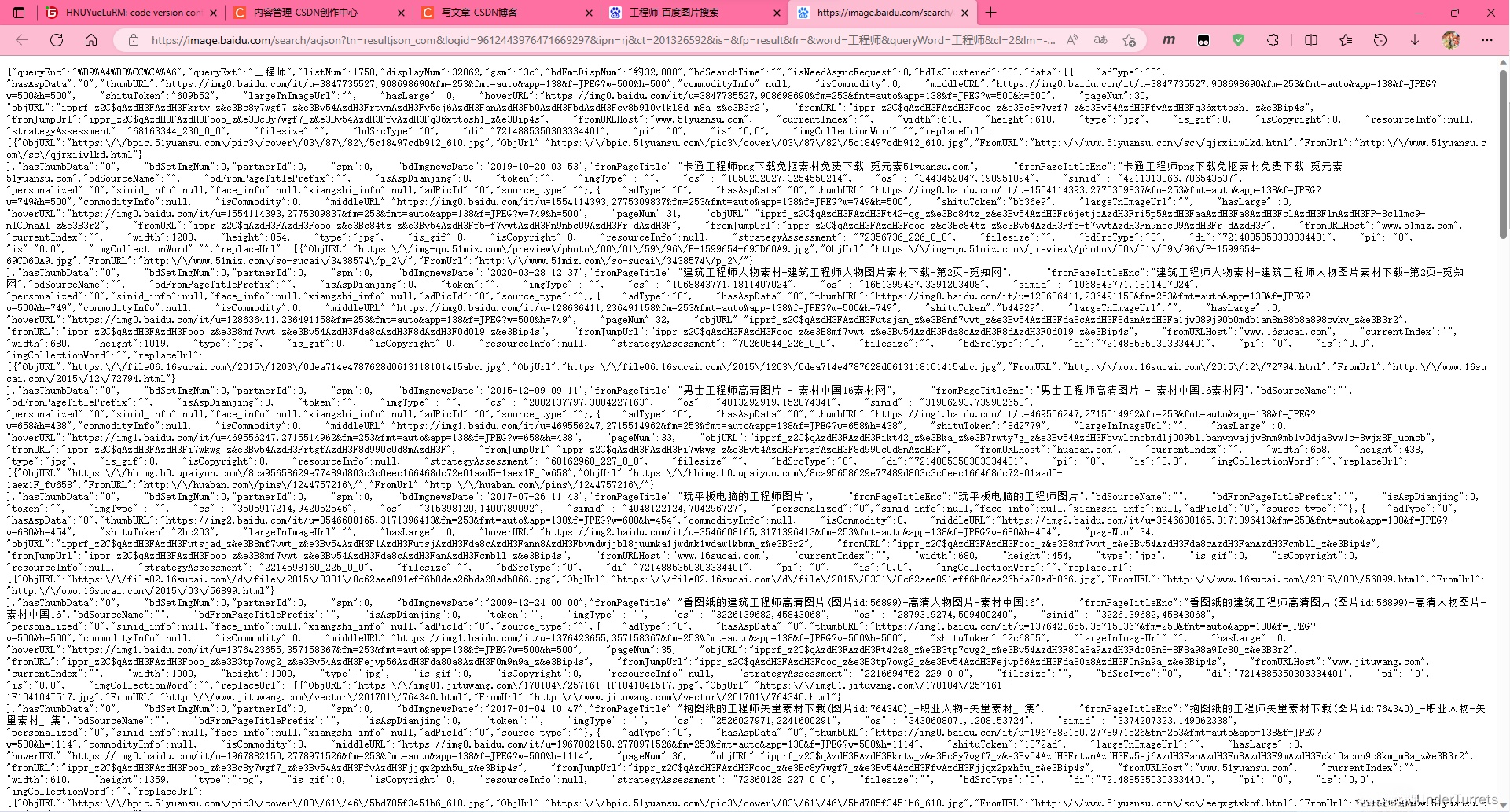
- 只要把这些信息进行恰到的处理,就可以从中提取出所有图片的URL
2.2 搜狗
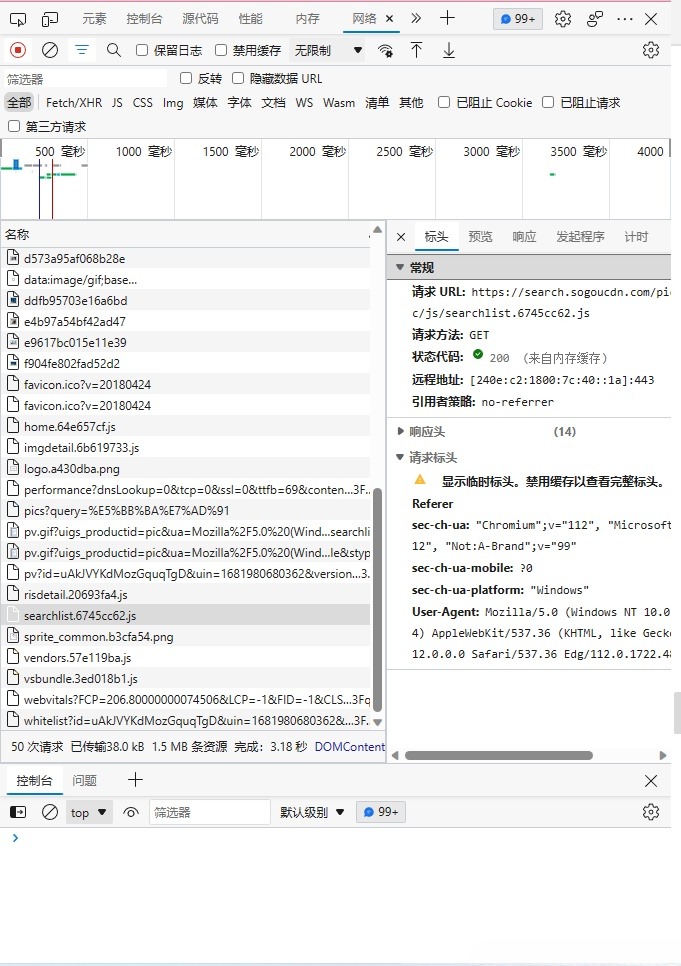
- 搜狗与百度存储图片URL的请求头名字不同,如下:
2.3 必应
必应存储图片URL的请求头如下: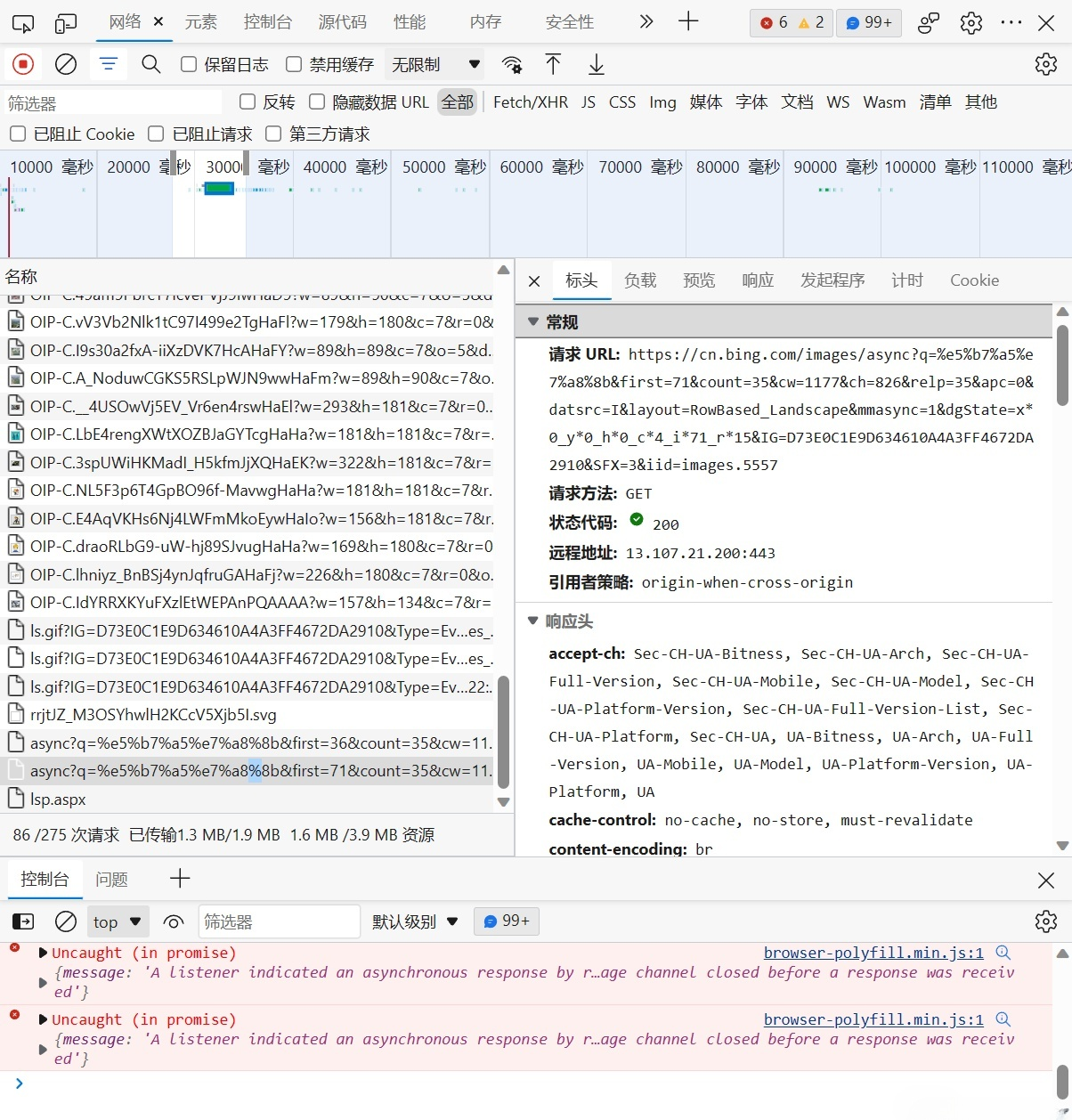
2.4 总结
- 只要找到了网站批量存储图片URL的请求头,就可以通过访问这个请求头,获得其中的文本数据。接下来,我将以必应为例,讲解如何从杂乱的信息中,批量提取图片URL。
3.处理存储图片URL的请求头
- 上文中我们提及,这类请求头中的信息非常的杂乱。但是,我们可以用正则化筛选出图片的URL,如图:


- 可以看到,通过这个正则表达式,所有图片的URL都被提取出来
4.完整demo
有了批量的图片URL,下载已经易如反掌。使用urlretrieve函数可以直接将远程数据下载到本地。详情请看接下来的完整demo:
# Created by Han Xu
# email:736946693@qq.com
import requests
import urllib.request
import urllib.parse
import os
import re
class Spider_bing_image():
def __init__(self):
"""
@:brief
@:return
"""
self.path=input("type in the path where you want to reserve the images:")
self.url = 'https://www4.bing.com/images/async?'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.48'}
self.keyword = input("type in the keywords used to search in bing:")
self.paginator = int(input("Type in the number of pages you want.Each page has almost 30 images:"))
def get_urls(self):
"""
@:brief Get the URLs that you need to visit.
@:return return a list of the URLs
"""
keyword = urllib.parse.quote(self.keyword)
params = []
for i in range(1, self.paginator + 1):
params.append(
"q={}&first={}&count=35&cw=1233&ch=946&relp=35&datsrc=I&layout=RowBased_Landscape&apc=0&mmasync=1&dgState=x*303_y*1355_h*185_c*1_i*36_r*8&IG=6A228D01DCE044E685557DE143D55D91&SFX=2&iid=images.5554".format(
keyword,30 * i))
urls = []
for i in params:
urls.append(self.url + i)
return urls
def get_path(self):
"""
@:brief Get the path where you want to reserve the images.
@:return
"""
dirname="./"+self.path
dirname_origin = dirname
int_index = 0
while(True):
IsExist = os.path.exists(dirname)
if (IsExist==False):
os.mkdir(dirname)
IsCreate=True
break
else:
int_index+=1
dirname=dirname_origin+"({})".format(int_index)
return dirname+"/"
def get_image_url(self, urls):
"""
@:brief Get the URLs of images.
@:return a list of URLs of images
"""
image_url = []
pattern_string="http[^%&]+.jpg"
pattern = re.compile(pattern=pattern_string)
for url in urls:
url_txt = requests.get(url, headers=self.headers).text
url_list=pattern.findall(url_txt)
for i in url_list:
if i:
image_url.append(i)
return image_url
def get_image(self,image_url):
"""
@:brief download the images into the path you set just
@:return
"""
m = 1
for img_url in image_url:
#定义一个flag用于判断下载图片是否异常
flag=True
try:
#urlretrieve() 方法直接将远程数据下载到本地
print("第{}张图片的URL是{}".format(m,img_url))
print("保存于{}".format(os.getcwd()+self.path[1:]))
urllib.request.urlretrieve(img_url, self.path + str(m) + '.jpg')
except BaseException as error:
flag=False
print(error)
if(flag):
#下载完成提示
print('**********第'+str(m)+'张图片下载完成********')
#每下载完后一张,m累加一次
m = m + 1
print('下载完成!')
return
def __call__(self, *args, **kwargs):
"""
@brief the constrcution of the class
@:return
"""
self.path=self.get_path()
urls = self.get_urls()
image_url = self.get_image_url(urls)
self.get_image(image_url)
return
本文由博客一文多发平台 OpenWrite 发布!
这篇关于【Python爬虫】批量爬取图片的简单案例的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
您可能喜欢
-
Python编程基础详解11-24
-
Python编程基础教程11-21
-
Python编程基础与实践11-20
-
Python编程基础与高级应用11-20
-
Python 基础编程教程11-19
-
Python基础入门教程11-19
-
在FastAPI项目中添加一个生产级别的数据库——本地环境搭建指南11-17
-
`PyMuPDF4LLM`:提取PDF数据的神器11-16
-
四种数据科学Web界面框架快速对比:Rio、Reflex、Streamlit和Plotly Dash11-16
-
获取参数学习:Python编程入门教程11-14
-
Python编程基础入门11-14
-
Python编程入门指南11-14
-
Python基础教程11-13
-
Python编程基础指南11-12
-
Python基础编程教程11-12
栏目导航
