C/C++教程
探索C语言结构体:编程中的利器与艺术

✨✨ 欢迎大家来到贝蒂大讲堂✨✨
🎈🎈养成好习惯,先赞后看哦~🎈🎈
所属专栏:C语言学习
贝蒂的主页:Betty‘s blog

1. 常量与变量
1. 什么是结构体
在C语言中本身就自带了一些数据类型,如:char,int,float,double等数据类型都被称为内置类型,但是在实际生活中我们发现这些基本的数据类型是不够用的,当描述一个复杂的对象时候,如一个学生,一本书时,这时仅靠内置类型就有点捉襟见肘了。所以C语言除了内置类型之外又有了自定义类型,今天我们要学习的便是自定义类型之一——结构体
2. 结构体基础
2.1 结构体声明
结构体定义由关键字 struct 和结构体名组成,结构体名可以根据需要自行定义。struct 语句定义了一个包含多个成员的新的数据类型,struct 语句的格式如下:
struct tag {
member-list
member-list
member-list …
} variable-list ;
- tag是结构体标签,定义你需要的结构体名,如book,student等。
- member-list 是标准的变量定义,比如 int i; 或者 float f;,也可以定义数组char s[20]。
- variable-list 结构变量,定义在结构的末尾,最后一个分号之前,您可以指定一个或多个结构变量,也可以省略。
下列是常见的结构体定义方式:
(1) 普通结构体
struct student
//声明一个学生的结构体
{
int age;//年龄
char sex[8];//性别
int weight;//体重
char tele[20];//电话
}s;
(2) 嵌套结构体
结构体和函数一样可以嵌套使用,也就是说在一个结构体中可以使用另外一个结构体,也可以包含指向自己结构体类型的指针,而通常这种指针的应用是为了实现一些更高级的数据结构如链表和树等。
struct student
{
int age;//年龄
char sex[8];//性别
int weight;//体重
char tele[20];//电话
};
struct people
{
int num;//序号
struct student s;//学生
};
struct list
{
int num;//序号
struct list* next;//指向自己的结构体指针
};
- 但是结构体中不能包含一个同类型的结构体变量,因为这样结构体大小无法确定
struct node
{
int num;
struct node s;
//错误定义
};
(3) 匿名结构体
匿名结构体是不定义结构体名称,而直接定义其成员的一种方式。这种结构体只能使用一次。并且两个匿名结构体的成员如果都相同的话,这两个匿名结构体也是不同的。
struct//匿名结构体
{
int num;
char name[20];
//.....
};
struct
{
int a;
char b;
float c;
}x;
struct
{
int a;
char b;
float c;
}*p;
p = &x;//两种结构体不同无法赋值
(4) typedef简化结构体
因为结构体名称在使用时前缀较长,这时我们就可以使用typedef来简化。
typedef struct student
{
int age;//年龄
char sex[8];//性别
int weight;//体重
char tele[20];//电话
}stu;//之后就可以用stu代替struct student
- 不能使用简化结构体提前在结构体内部创建变量
typedef struct student
{
int age;//年龄
char sex[8];//性别
int weight;//体重
char tele[20];//电话
stu* next;//不能提前使用
}stu;
2.2 结构体变量的创建与初始化
在学习完结构体声明之后,我们就可以使用结构体创建变量和初始化变量。
typedef struct student
{
int age;//年龄
char sex[8];//性别
int weight;//体重
char tele[20];//电话
}stu;
struct people
{
int num;//序号
struct student s;//学生
};
int main()
{
struct student s = { 20,"nan",50,"1233455" };//创建变量并初始化
//struct student s;
//s= { 20,"nan",50,"1233455" };错误
stu t = { 18,"nan",45,"123444" };
struct people p = { 1,{20,"nan",50,"1233455"} };
//嵌套结构体的初始化
return 0;
}
- 结构体只能在创建变量时候初始化,不能先初始化,然后赋值
2.3 访问结构体成员
(1) 直接访问
结构体成员的直接访问是通过点操作符(.)访问的。点操作符接受两个操作数。如下所⽰:
struct Point
{
int x;
int y;
};
int main()
{
struct Point p = { 1,2 };
printf("x: %d y: %d\n", p.x, p.y);
return 0;
}
输出结果:
x:1 y:2
(2) 间接访问
除了通过(.)操作符直接访问,我们也可以通过结构体地址,利用(->)操作符间接访问。
#include <stdio.h>
struct Point
{
int x;
int y;
};
int main()
{
struct Point p = { 3, 4 };
struct Point* ptr = &p;//结构体指针
ptr->x = 1;
ptr->y = 2;
printf("x = %d y = %d\n", ptr->x, ptr->y);
return 0;
}
输出结果:
x=1 y=2
3. 结构体内存对齐
3.1 内存对齐规则
在熟悉了结构体的基本应用之后,下面我们要深入讨论的就是结构体大小,那么结构体大小又该如何计算呢?首先让我们看一下下面这段代码。
struct example
{
int num;
char a;
float b;
int p;
}s;
int main()
{
size_t sz = sizeof(s);
printf("大小为%zd\n", sz);
return 0;
}
输出结果:

- 如果直接计算int,float类型4个字节,char类型一个字节,应该为13字节,而结果为16,所以C语言并不是直接分配大小的。
C语言分配结构体内存时,遵循的是内存对齐规则,那什么是内存对齐规则呢?
内存对齐规则:
- 结构体的第⼀个成员对⻬到和结构体变量起始位置偏移量为0的地址处
- 其他成员变量要对⻬到某个数字(对⻬数)的整数倍的地址处。
- 对⻬数=编译器默认的⼀个对⻬数与该成员变量⼤⼩的较⼩值。(VS 中默认的值为 8 ,Linux中gcc没有默认对齐数,对⻬数就是成员⾃⾝的⼤⼩)
- 结构体总⼤⼩为最⼤对⻬数(结构体中每个成员变量都有⼀个对⻬数,所有对⻬数中最⼤的)的整数倍。
- 如果嵌套了结构体的情况,嵌套的结构体成员对⻬到⾃⼰的成员中最⼤对⻬数的整数倍处,结构体的整体⼤⼩就是所有最⼤对⻬数(含嵌套结构体中成员的对⻬数)的整数倍。
3.2 宏——offsetof
- 头文件:#include <stddef.h>
- 声明:offsetof(type, member-designator)
- type – 这是一个 class 类型,其中,member-designator 是一个有效的成员指示器。
- member-designator – 这是一个 class 类型的成员指示器。
- 作用:计算结构体成员相对于起始位置的偏移量
- 返回值:该宏返回类型为 size_t 的值,表示 type 中成员的偏移量。
代码示例:
#include<stddef.h>
struct S1
{
char c1;
int i;
char c2;
};
int main()
{
printf("%zd\n", offsetof(struct S1, c1));
printf("%zd\n", offsetof(struct S1, i));
printf("%zd\n", offsetof(struct S1, c2));
return 0;
}
输出结果:

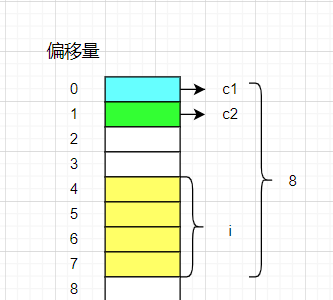
示意图:

- c1是一个char类型占一个字节,根据内存对齐第一条规则,放在偏移量为0处。
- i是int类型占四个字节,根据内存对齐第二,三规则,默认对齐数是4,对齐至4的整数倍,中间浪费三个字节,偏移量为4.
- c2也是char类型占一个字节,默认对齐数是1的整数倍,偏移量为8。
3.2 实例应用
(1) 实例一
struct S1
{
char c1;
char c2;
int i;
};
int main()
{
printf("大小为%zd\n", sizeof(struct S1));//输出什么?
return 0;
}
输出结果:
大小为8
解析:
- c1放在偏移量为0的位置,大小为一个字节。
- c2的默认对齐数为1,放在1的整数倍处,大小为一个字节。
- i的默认对齐数为4放在4的整数倍处,浪费2个字节,大小为4个字节、
- 最大对齐数为4,结构体大小为4的整数倍,现在大小为8刚好满足,所以这个结构体大小为8.
(2) 实例二
struct S2
{
double i;
char c1;
char c3;
};
int main()
{
printf("大小为%zd\n", sizeof(struct S2));//输出什么?
return 0;
}
输出结果:
大小为16
解析:

- i放在偏移量为0处,大小为8。
- c1放在默认对齐数为1放在1的整数倍处,大小为一个字节。
- c2的默认对齐数为1,放在1的整数倍处,大小为一个字节。
- 最大默认对齐数为8,结构体大小为8的整数倍,现在大小为10所以浪费6个字节,大小为16。
(3) 实例三
struct S2
{
double i;
char c1;
char c3;
};
struct S3
{
struct S2 s;
int d;
char c3;
};
int main()
{
printf("大小为%zd\n", sizeof(struct S3));//输出什么?
return 0;
}
输出结果:
大小为24
解析:

- 结构体S2的大小为16,放在偏移量为0的位置。
- d的默认对齐数为4,放在4的整数倍16的位置,大小为4。
- c3的默认对齐数为1,放在1的整数倍20的位置,大小为1。
- 最大对齐数为8,结构体大小为8的整数倍,大小为24。
4. 位段
4.1 什么是位段
有些数据在存储时并不需要占用一个完整的字节,只需要占用一个或几个二进制位即可,所以C 语言有一种特别的数据结构名为位段,允许我们按位对成员进行定义,指定其占用的位数,单位为比特位(bit)。一般是用来节约内存,与结构体有两个不同:
- 位段的成员必须是 int、unsigned int 或signed int ,char等整型。到了 C99,_Bool 也被支持了。
- 位段的成员名后边有⼀个冒号和⼀个数字。
比如:
struct A
{
int _a : 2;//为a分配2个比特位
int _b : 3;//为b分配3个比特位
int _c : 4;//为c分配4个比特位
int _d : 5;//为d分配5个比特位
};
- 位段的⼏个成员可能共有同⼀个字节,这样有些成员的起始位置并不是某个字节的起始位置,那么这些位置处是没有地址的。内存中每个字节分配⼀个地址,⼀个字节内部的bit位是没有地址的。所以不能对位段的成员使⽤&操作符,这样就不能使⽤scanf直接给位段的成员输⼊值,只能是先输⼊放在⼀个变量中,然后赋值给位段的成员。
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
int main()
{
struct A sa = { 0 };
scanf("%d", &sa._b); //这是错误的
//正确的⽰范
int b = 0;
scanf("%d", &b);
sa._b = b;
return 0;
}
4.2 位段的内存分配
- 位段的空间上是按照需要以4个字节( int )或者1个字节( char )的⽅式来开辟的。
- 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使⽤位段。
如下所示,下面这个位段会占用多少内存空间?
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
int main()
{
printf("大小为%zd\n", sizeof(struct A));//输出什么?
return 0;
}

- 2+5+10+30=47,而八个字节64个比特位,事实证明位段节约空间的能力有限的。
那么位段的分配到底是怎么样的呢?
当一个结构体包含两个位段,第二个位段比较大,无法容纳于第一个位段剩余的位时, 是舍弃剩余的位还是利用呢?
我们以下列程序举例:
struct S
{
char a:3;
char b:4;
char c:5;
char d:4;
};
//内存如何分配?
int main()
{
struct S s = {0};
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
return 0;
}
- 假设位段在一个字节内部是从高地址到低地址分配。
- 假设当一个结构体包含两个位段,第二个位段比较大,无法容纳于第一个位段剩余的位时, 是舍弃。
图示:

- 12先转换为二进制01010,因为假设位段在一个字节内部是从高地址到低地址分配,所以从右往左分配,又因为只给a分配了三个比特位,所以只存进010。
- 然后12转换为二进制01100,因为只分配给b四个比特位,所以只存进1100。
- 3转换为二进制为00011,因为分配了c五个比特位,所以存进00011。
- 最后4转换为二进制00100,分配进四个比特位0100。
- 最后只需验证系统存在的数据是否为这样的数据就能验证我们的猜测是否正确了·。
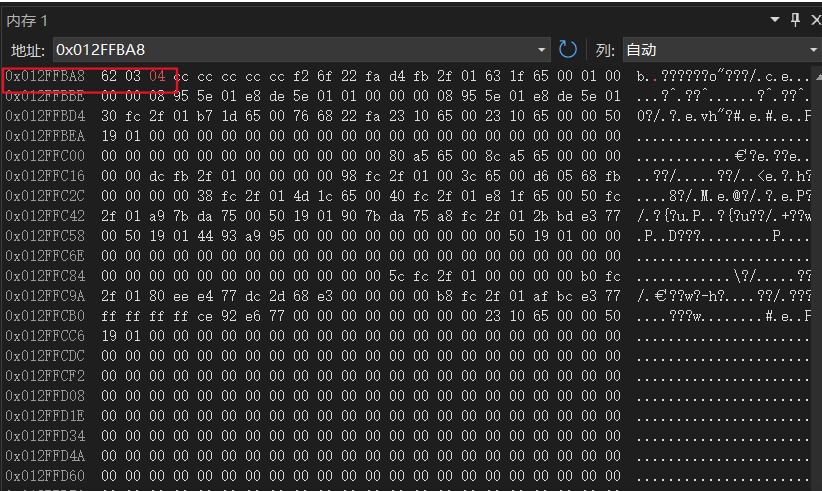
- 通过验证我们可以确定的是在VS2022环境下我们的猜想是正确的。
4.3 位段的缺陷
位段虽然能帮助我们节约内存,但是也有许多缺陷,尤其在跨平台问题上有很大的缺陷。
- int型位段成员会被当成有符号数还是无符号数是不确定的
- 位段中最大位数目是不确定的(在16位机器上int型最大为16,而在32为机器上int型最大为32,如若写成27,那么16位机器就会出问题)
- 位段的成员在内存中到底是从左向右分配,还是从右向左分配尚未定义
- 当一个结构体包含两个位段,第二个位段比较大,无法容纳于第一个位段剩余的位时, 是舍弃剩余的位还是利用,是不确定的。
5. 结构体传参
我们知道函数传参分为两种,一种是直接传参:直接传变量;一种是间接传参:通过传变量地址间接访问。
struct S1
{
int p;
int num;
};
//结构体传参
void print1(struct S1 s)
{
printf("%d\n", s.num);
}
//结构体地址传参
void print2(struct S1* ps)
{
printf("%d\n", ps->num);
}
int main()
{
struct S1 s = { 1,2 };
print1(s); //传整个结构体
print2(&s); //传地址
return 0;
}
那么到底哪种方法好呢?答案自然是传地址更好,因为我们知道传参时形参是实参的临时拷贝,也就是说系统会将参数复制一份,当一个参数的数量极大时会造成不必要的内存分配,而传址调用系统只用分配四个字节或八个字节,大大节约内存。
-
怎么使用nsenter命令进入容器?-icode9专业技术文章分享12-26
-
导入文件提示存在乱码,请确定使用的是UTF-8编码怎么解决?-icode9专业技术文章分享12-26
-
csv文件怎么设置编码?-icode9专业技术文章分享12-26
-
TypeScript基础知识详解12-25
-
安卓NDK 是什么?-icode9专业技术文章分享12-25
-
caddy 可以定义日志到 文件吗?-icode9专业技术文章分享12-25
-
wordfence如何设置密码规则?-icode9专业技术文章分享12-25
-
有哪些方法可以实现 DLL 文件路径的管理?-icode9专业技术文章分享12-25
-
错误信息 "At least one element in the source array could not be cast down to the destination array-icode9专业技术文章分享12-25
-
'flutter' 不是内部或外部命令,也不是可运行的程序 或批处理文件。错误信息提示什么意思?-icode9专业技术文章分享12-25
-
flutter项目 as提示Cannot resolve symbol 'embedding'提示什么意思?-icode9专业技术文章分享12-25
-
怎么切换 Git 项目的远程仓库地址?-icode9专业技术文章分享12-24
-
怎么更改 Git 远程仓库的名称?-icode9专业技术文章分享12-24
-
更改 Git 本地分支关联的远程分支是什么命令?-icode9专业技术文章分享12-24
-
uniapp 连接之后会被立马断开是什么原因?-icode9专业技术文章分享12-24
