Java教程
Java利用余弦相似度测量文本相似度

本文主要是介绍Java利用余弦相似度测量文本相似度,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
余弦相似度
余弦相似度是用于度量两个向量之间的夹角的余弦值,它可以用于比较文本、用户偏好等多个领域。
余弦相似度是一种测量两个向量之间相似性的方法。它的基本思想是:
- 如果两个向量在相同的方向上都有较大的分量,或者在相反的方向上有较小的分量,则它们的余弦相似性分数将接近1(完全相似)
- 如果一个向量在某个方向上有较大的分量,而另一个向量在该方向上的分量很小,则它们的余弦相似性分数将接近-1(完全不相似)
- 如果两个向量在所有方向上的分量都大致相同,则它们的余弦相似性分数将接近0(没有相似性)。
对于文本,我们可以将每个文本表示为一个向量,其中每个维度对应一个单词,该向量的每个值表示该单词在文本中出现的频率。然后,我们可以使用余弦相似性来测量这两个文本向量的相似性。
余弦相似度的计算公式如下: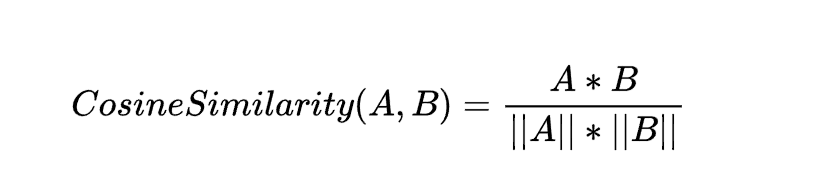
Java计算文本余弦相似度
示例代码1
import java.util.HashSet;
import java.util.Map;
import java.util.Set;
import java.util.stream.Collectors;
import java.util.stream.Stream;
/**
* @ClassName TextSimilarity
* @Desc 使用Java8借助余弦相似性测度测量文本相似度
* 余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度将向量根据坐标值,绘制到向量空间中,如最常见的二维空间。
* @Author diandian
**/
public class TextSimilarity {
/**
* 测量文本相似度
* 1. 首先,从两个字符串提取单词。
* 2.个字符串中的每个单词,计算出现频率。这里所说的“出现频率”是指单词在
* 每个句子中出现的次数。设A为单词向量,表示它们在第一个字符串出现的频率, B也是单词向量,表示它们在第二个字符串中出现的频率。
* 3.通过删除重复项,找出每个字符串的特有单词。
* 4.找出两个字符串都有的单词。
* 5.余弦相似度公式的分子是向量A与B的点积。
* 6.公式的分母是向量A与B大小的算术积。
* 请注意,两个句子的余弦相似度分数介于-1(表示正好相反)到1(表示完全一样)之间,0分表示去相关。
* @param s1
* @param s2
* @return
*/
public double calculateCosine(String s1, String s2){
//使用正则表达式与Java8的并行功能对给定的字符串进行切分,得到单词的两个字符串流
Stream<String> stream1 = Stream.of(s1.toLowerCase().split("\\W+")).parallel();
Stream<String> stream2 = Stream.of(s2.toLowerCase().split("\\W+")).parallel();
//计算每个字符串中每个单词出现的频率,存入map
Map<String, Long> wordFreq1 = stream1
.collect(Collectors.groupingBy(String::toString,Collectors.counting()));
Map<String, Long> wordFreq2 = stream2
.collect(Collectors.groupingBy(String::toString,Collectors.counting()));
//对于每个句子的单词列表,删除其中的重复项,仅仅保留唯一的单词
Set<String> wordSet1 = wordFreq1.keySet();
Set<String> wordSet2 = wordFreq2.keySet();
//将两个字符串中共有的单词创建列表,用于计算上面两个Map的点积
Set<String> intersection = new HashSet<String>(wordSet1);
intersection.retainAll(wordSet2);
//计算余弦公式的分子,它是两个Map的点积
double numerator = 0;
for (String common: intersection){
numerator += wordFreq1.get(common) * wordFreq2.get(common);
}
//用于保存向量大小的值
double param1 = 0, param2 = 0;
//计算第一个向量的大小
for(String w1: wordSet1){
param1 += Math.pow(wordFreq1.get(w1), 2);
}
param1 = Math.sqrt(param1);
//计算第二个向量的大小
for(String w2: wordSet2){
param2 += Math.pow(wordFreq2.get(w2), 2);
}
param2 = Math.sqrt(param2);
//两个向量大小的乘积,就是余弦相似度的分母
double denominator = param1 * param2;
//计算出两个字符串的余弦相似度
double cosineSimilarity = numerator/denominator;
return cosineSimilarity;
}
public static void main(String[] args){
TextSimilarity cos = new TextSimilarity();
System.out.println(cos.calculateCosine("To be, or not to be: that is the question.", "Frailty, thy name is woman!"));
System.out.println(cos.calculateCosine("The lady doth protest too much, methinks.", "Frailty, thy name is woman!"));
System.out.println(cos.calculateCosine("hello world", "hello world"));
System.out.println(cos.calculateCosine("我是中国人", "中国人"));
}
}
注意:暂时不支持对中文进行相似度计算
示例代码2
pom.xml文件引入依赖:
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-math3 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.6.1</version>
</dependency>
import org.apache.commons.math3.linear.ArrayRealVector;
import org.apache.commons.math3.linear.RealVector;
/**
* @ClassName: CosineSimilarity1
* @desc: TODO 使用apache.commons.math3包计算余弦相似度
* @author: diandian
*/
public class CosineSimilarity {
public static void main(String[] args) {
//May you have infinite faith in your preciousness when you lost your way. Love what your love, do what you do and listen to your heart.
//愿你在迷茫时,坚信你的珍贵,爱你所爱,行你所行,听从你心
//String text1 = "May you have infinite faith in your preciousness when you lost your way. Love what your love, do what you do and listen to your heart.";
//String text2 = "May you have infinite faith in your preciousness when you lost your way. Love what your love, do what you do and listen to your heart. May you be young forever.";
String text1 = "愿你在迷茫时,坚信你的珍贵,爱你所爱,行你所行,听从你心";
String text2 = "愿你在迷茫时,坚信你的珍贵,爱你所爱,行你所行,听从你心; 无问西东;";
RealVector vector1 = getWordFrequencyVector(text1);
RealVector vector2 = getWordFrequencyVector(text2);
double cosineSimilarity = calculateCosineSimilarity(vector1, vector2);
System.out.println("Cosine Similarity: " + cosineSimilarity);
}
// 将文本转换为词频向量
private static RealVector getWordFrequencyVector(String text) {
String[] words = text.toLowerCase().split("\\s+");
int dimension = 1000; // 根据实际情况设置向量维度
double[] vectorData = new double[dimension];
for (String word : words) {
// 这里简化处理,将每个单词的哈希值映射到向量的维度上
int hash = Math.abs(word.hashCode()) % dimension;
vectorData[hash] += 1; // 或者可以使用 TF-IDF 等更复杂的权重
}
return new ArrayRealVector(vectorData);
}
// 计算余弦相似性
private static double calculateCosineSimilarity(RealVector vector1, RealVector vector2) {
double dotProduct = vector1.dotProduct(vector2);
double magnitude1 = vector1.getNorm();
double magnitude2 = vector2.getNorm();
if (magnitude1 == 0 || magnitude2 == 0) {
return 0; // 避免除以零
}
return dotProduct / (magnitude1 * magnitude2);
}
}
注意:暂时不支持对中文进行相似度计算
示例代码3
为了支持计算中文文本的余弦相似度计算,我们需要对中文文本进行预处理和分词,然后将文本表示为特征向量。可以使用分词工具,比如结巴分词(jieba),引入依赖:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.6.1</version>
</dependency>
<dependency>
<groupId>com.huaban</groupId>
<artifactId>jieba-analysis</artifactId>
<version>1.0.2</version>
</dependency>
import com.huaban.analysis.jieba.JiebaSegmenter;
import com.huaban.analysis.jieba.*;
import org.apache.commons.math3.linear.ArrayRealVector;
import org.apache.commons.math3.linear.RealVector;
import java.util.ArrayList;
import java.util.List;
/**
* @ClassName: ChineseCosineSimilarity
* @desc: TODO 中文余弦相似度计算
*在Java中,要计算给定的两个中文字符串的余弦相似度,首先需要进行中文文本的预处理和分词,然后将文本表示为特征向量。
* 可以使用分词工具,比如结巴分词(jieba),然后使用向量空间模型(Vector Space Model)来表示文本。
* @author: diandian
*/
public class ChineseCosineSimilarity {
public static void main(String[] args) {
// 两个中文字符串
String text1 = "愿你在迷茫时,坚信你的珍贵,爱你所爱,行你所行,听从你心";
String text2 = "愿你在迷茫时,坚信你的珍贵,爱你所爱,行你所行,听从你心; 无问西东;";
// 提取分词结果
List<String> words1 = segmentChineseText(text1);
List<String> words2 = segmentChineseText(text2);
// 计算余弦相似度
double similarity = calculateCosineSimilarity(words1, words2);
System.out.println("余弦相似度: " + similarity);
}
// 中文文本分词
private static List<String> segmentChineseText(String text) {
// 中文分词器
JiebaSegmenter segmenter = new JiebaSegmenter();
List<SegToken> segTokens = segmenter.process(text, JiebaSegmenter.SegMode.SEARCH);
// 提取分词结果
List<String> words = new ArrayList<>();
for (SegToken segToken : segTokens) {
words.add(segToken.word);
}
return words;
}
/**
* 计算余弦相似度
* @param words1
* @param words2
* @return
*/
private static double calculateCosineSimilarity(List<String> words1, List<String> words2) {
// 合并两个文本的分词结果,获取词汇表
List<String> vocabulary = new ArrayList<>(words1);
vocabulary.addAll(words2);
// 创建两个文本的词频向量
RealVector vector1 = createVector(words1, vocabulary);
RealVector vector2 = createVector(words2, vocabulary);
// 计算余弦相似度
return vector1.cosine(vector2);
}
/**
* 获取中文文本的特征向量
* @param words
* @param vocabulary
* @return
*/
private static RealVector createVector(List<String> words, List<String> vocabulary) {
// 初始化词频向量
double[] vectorData = new double[vocabulary.size()];
// 遍历词汇表,统计词频
for (int i = 0; i < vocabulary.size(); i++) {
String term = vocabulary.get(i);
int frequency = 0;
// 统计词频
for (String word : words) {
if (word.equals(term)) {
frequency++;
}
}
vectorData[i] = frequency;
}
return new ArrayRealVector(vectorData);
}
}
上面只是给出的示例代码,在实际应用中,请根据需要自行修改,后续还会分享其他,请诸君多多支持!
这篇关于Java利用余弦相似度测量文本相似度的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
您可能喜欢
-
初学者必备:订单系统资料详解与实操教程12-25
-
内网穿透资料入门教程12-24
-
微服务资料入门指南12-24
-
微信支付系统资料入门教程12-24
-
微信支付资料详解:新手入门指南12-24
-
Hbase资料:新手入门教程12-24
-
Java部署资料12-24
-
Java订单系统资料:新手入门教程12-24
-
Java分布式资料入门教程12-24
-
Java监控系统资料详解与入门教程12-24
-
Java就业项目资料:新手入门必备教程12-24
-
Java全端资料入门教程12-24
-
Java日志系统资料详解:新手入门指南12-24
-
Java微服务系统资料:入门与初级应用指南12-24
-
Java小程序资料:入门教程与实战技巧12-24
栏目导航
