人工智能学习
自编码器AE全方位探析:构建、训练、推理与多平台部署

本文深入探讨了自编码器(AE)的核心概念、类型、应用场景及实战演示。通过理论分析和实践结合,我们详细解释了自动编码器的工作原理和数学基础,并通过具体代码示例展示了从模型构建、训练到多平台推理部署的全过程。
一、自编码器简介
自编码器的定义
自编码器(Autoencoder, AE)是一种数据的压缩算法,其中压缩和解压缩函数是数据相关的、有损的、从样本中自动学习的。自编码器通常用于学习高效的编码,在神经网络的形式下,自编码器可以用于降维和特征学习。
自编码器的历史发展
- 1980年代初期:自动编码器的早期研究
- 1990年代:使用反向传播训练自动编码器
- 2000年代:深度学习时代下的自动编码器研究,例如堆叠自动编码器
- 最近的进展:自动编码器在生成模型、异常检测等方向的新应用
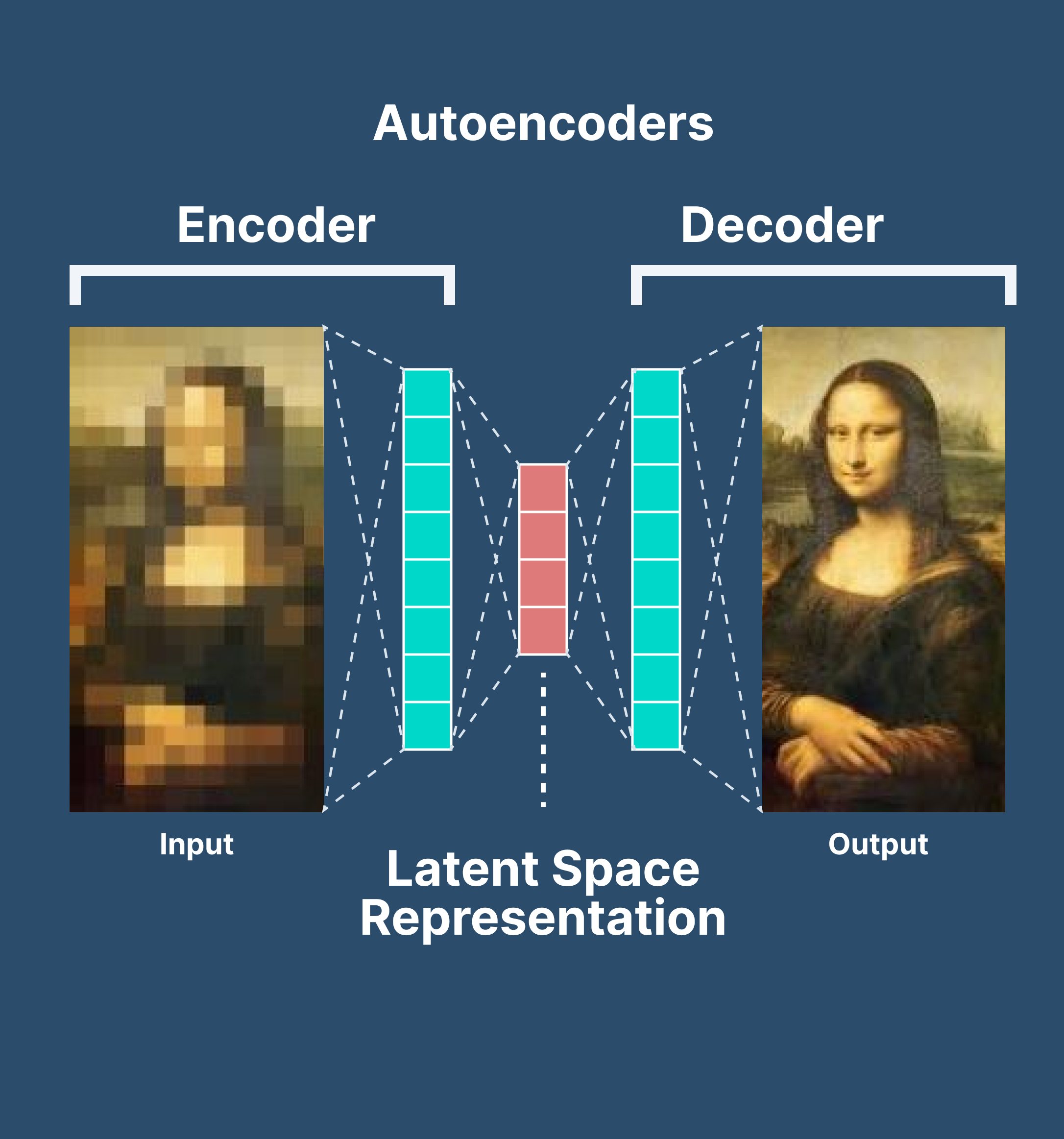
自编码器的工作原理
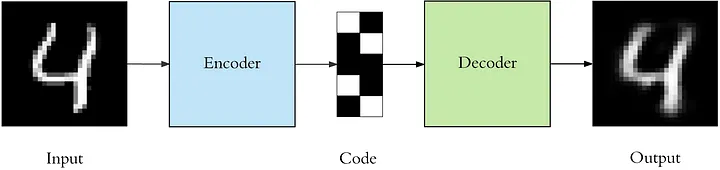
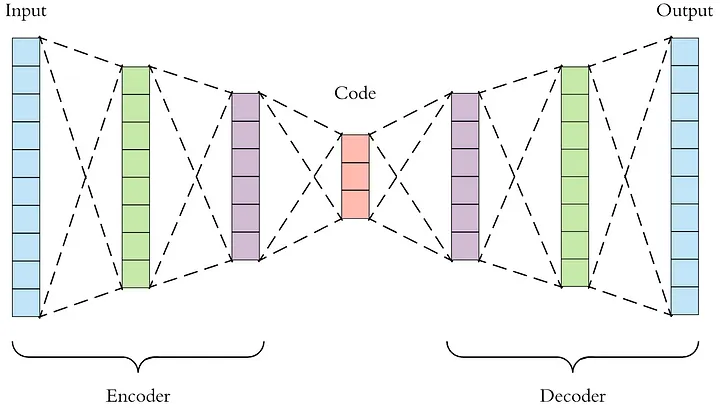
自编码器由两个主要部分组成:编码器和解码器。
-
编码器:编码器部分将输入数据压缩成一个潜在空间表示。它通常由一个神经网络组成,并通过减小数据维度来学习数据的压缩表示。
-
解码器:解码器部分则试图从潜在空间表示重构原始数据。与编码器相似,解码器也由一个神经网络组成,但是它工作的方式与编码器相反。
-
训练过程:通过最小化重构损失(例如均方误差)来训练自动编码器。
-
应用领域:自动编码器可以用于降维、特征学习、生成新的与训练数据相似的样本等。
二、自动编码器的类型
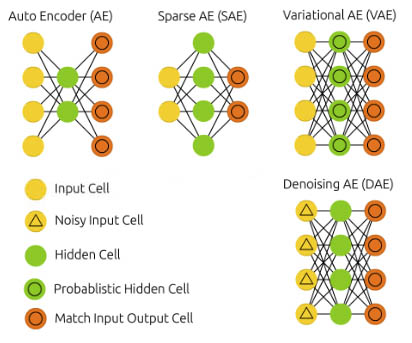
线性自动编码器
- 定义:线性自动编码器是一种利用线性变换进行编码和解码的自动编码器。
- 工作原理:
- 编码器:使用线性函数将输入映射到潜在空间。
- 解码器:使用线性函数将潜在空间映射回原始空间。
- 与PCA的关系:可以证明线性自动编码器与主成分分析(PCA)在某些条件下等价。
深度自动编码器
- 定义:深度自动编码器由多个隐藏层组成,允许捕捉数据的更复杂结构。
- 工作原理:
- 多层结构:使用多个非线性隐藏层来表示更复杂的函数。
- 非线性映射:通过非线性激活函数提取输入数据的高阶特征。
稀疏自动编码器
- 定义:稀疏自动编码器是在自动编码器的损失函数中加入稀疏性约束的自动编码器。
- 工作原理:
- 稀疏约束:通过L1正则化或KL散度等方法强制许多编码单元为零。
- 特征选择:稀疏约束有助于选择重要的特征,从而实现降维。
变分自动编码器
- 定义:变分自动编码器(VAE)是一种统计生成模型,旨在通过学习数据的潜在分布来生成新的样本。
- 工作原理:
- 潜在变量模型:通过变分推断方法估计潜在变量的后验分布。
- 生成新样本:从估计的潜在分布中采样,然后通过解码器生成新样本。
三、自编码器的应用场景
数据降维
- 定义:数据降维是减小数据维度的过程,以便更有效地分析和可视化。
- 工作原理:自动编码器通过捕捉数据中的主要特征,并将其映射到较低维度的空间,实现降维。
- 应用示例:在可视化复杂数据集时,例如文本或图像集合。
异常检测
- 定义:异常检测是识别不符合预期模式的数据点的过程。
- 工作原理:自动编码器能够学习数据的正常分布,然后用于识别不符合这一分布的异常样本。
- 应用示例:在工业设备监测中,用于发现可能的故障和异常行为。
特征学习
- 定义:特征学习是从原始数据中自动学习出有效特征的过程。
- 工作原理:自动编码器能够通过深度神经网络提取更抽象和有用的特征。
- 应用示例:在计算机视觉中,用于提取图像的关键特征。
生成模型
- 定义:生成模型是用于生成与训练数据相似的新数据的模型。
- 工作原理:特定类型的自动编码器,例如变分自动编码器,可以用来生成新的样本。
- 应用示例:在艺术创作和药物设计中生成新的设计和结构。
数据去噪
- 定义:数据去噪是从带噪声的数据中恢复出原始信号的过程。
- 工作原理:自动编码器可以被训练为识别和移除输入数据中的噪声。
- 应用示例:在医学图像处理中,用于清除图像中的不必要噪声。
半监督学习
- 定义:半监督学习使用标记和未标记的数据来构建预测模型。
- 工作原理:自动编码器可以用于利用未标记的数据提取有用的特征,进而增强分类或回归模型。
- 应用示例:在语音识别或自然语言处理中,利用大量未标记的数据进行训练。
四、自编码器的实战演示
4.1 环境准备
环境准备是所有机器学习项目的起点。在进行自动编码器的实战演示之前,确保你的计算环境满足以下要求:
操作系统
- 推荐使用Linux或macOS,Windows也可支持。
- 版本要求不特别严格,但推荐使用最近几年的稳定版本。
Python环境
- 使用Python 3.6或更高版本。
- 建议使用虚拟环境管理工具,例如
virtualenv或conda来隔离项目环境。
安装深度学习框架
- 使用PyTorch作为深度学习框架。
- 安装命令:
pip install torch torchvision - GPU支持(如果可用):确保CUDA版本与PyTorch兼容。
依赖库安装
- Numpy:用于数值计算,命令
pip install numpy。 - Matplotlib:用于可视化,命令
pip install matplotlib。 - Scikit-learn:用于数据预处理和评估,命令
pip install scikit-learn。
数据集准备
- 根据实战项目的需要,预先下载和准备相关数据集。
- 确保数据集的格式和质量符合实验要求。
开发工具
- 推荐使用Jupyter Notebook或者VS Code等现代开发环境,便于代码编写和结果展示。
硬件要求
- 至少4GB的RAM。
- 如果进行大型训练,建议使用支持CUDA的NVIDIA显卡。
4.2 构建自编码器模型
4.2.1 设计模型架构
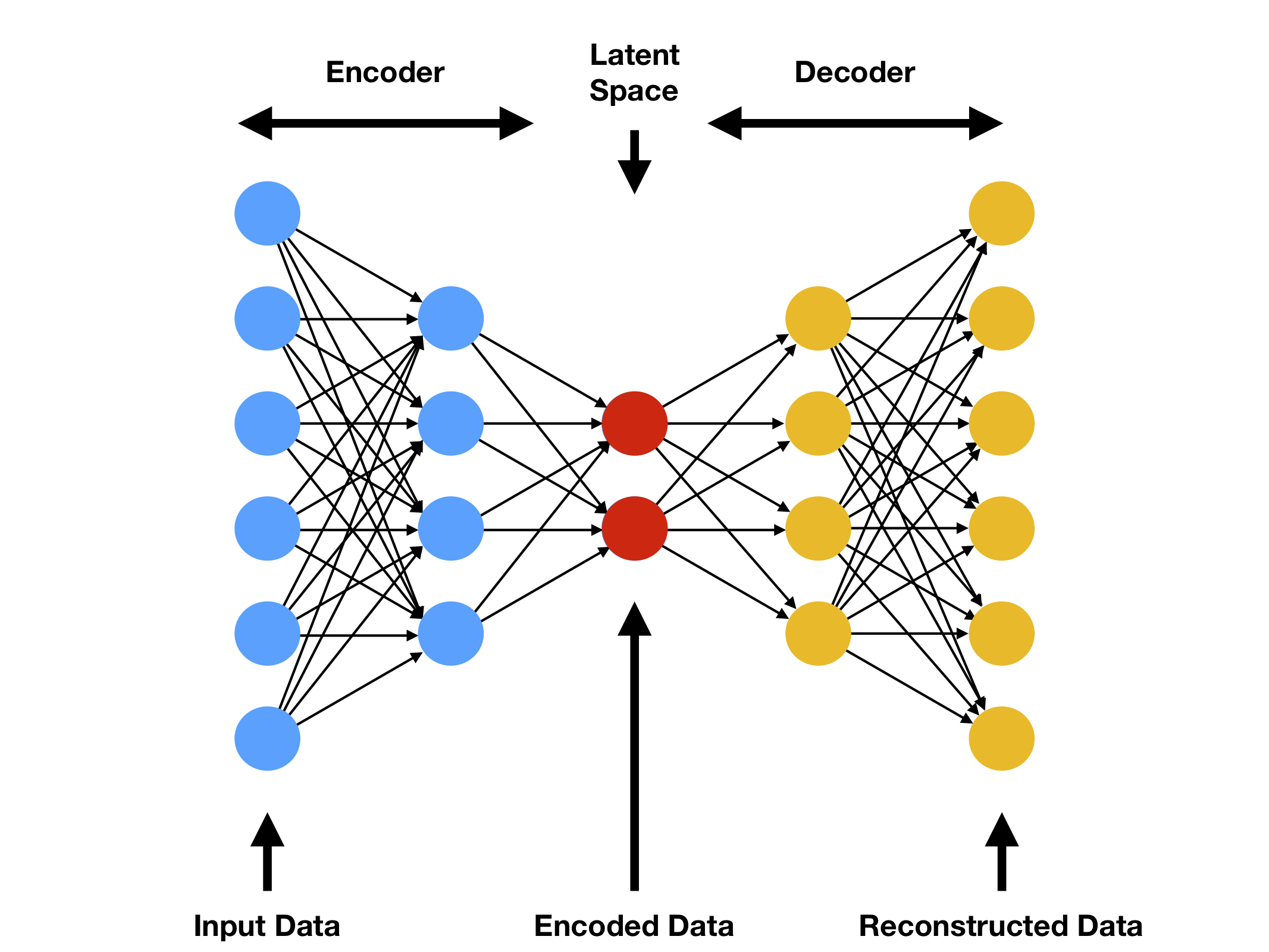
首先,我们需要设计自动编码器的架构,确定编码器和解码器的层数、大小和激活函数。
- 编码器:通常包括几个全连接层或卷积层,用于将输入数据映射到隐藏表示。
- 解码器:使用与编码器相反的结构,将隐藏表示映射回原始数据的维度。
4.2.2 编写代码
以下是使用PyTorch实现自动编码器模型的示例代码:
import torch.nn as nn
class Autoencoder(nn.Module):
def __init__(self, input_dim, encoding_dim):
super(Autoencoder, self).__init__()
# 编码器部分
self.encoder = nn.Sequential(
nn.Linear(input_dim, encoding_dim * 2),
nn.ReLU(),
nn.Linear(encoding_dim * 2, encoding_dim),
nn.ReLU()
)
# 解码器部分
self.decoder = nn.Sequential(
nn.Linear(encoding_dim, encoding_dim * 2),
nn.ReLU(),
nn.Linear(encoding_dim * 2, input_dim),
nn.Sigmoid() # 输出范围为0-1
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
上述代码定义了一个简单的全连接自动编码器。
input_dim是输入数据的维度。encoding_dim是隐藏表示的维度。- 我们使用ReLU激活函数,并在解码器的输出端使用Sigmoid激活,确保输出范围在0到1之间。
4.2.3 模型训练
对于模型训练,我们通常使用MSE损失,并选择适合的优化器,例如Adam。
from torch.optim import Adam # 实例化模型 autoencoder = Autoencoder(input_dim=784, encoding_dim=64) # 定义损失和优化器 criterion = nn.MSELoss() optimizer = Adam(autoencoder.parameters(), lr=0.001) # 训练代码(循环、前向传播、反向传播等) # ...
4.2.4 模型评估和可视化
模型训练后,可以通过对比原始输入和解码输出来评估其性能。可以使用matplotlib进行可视化。
4.3 训练自编码器
训练自动编码器是一个迭代的过程,需要正确地组织数据、设置合适的损失函数和优化器,并通过多次迭代优化模型的权重。以下是详细步骤:
4.3.1 数据准备
准备适合训练的数据集。通常,自动编码器的训练数据不需要标签,因为目标是重构输入。
- 数据加载:使用PyTorch的DataLoader来批量加载数据。
- 预处理:根据需要进行标准化、归一化等预处理。
4.3.2 设置损失函数和优化器
通常,自动编码器使用均方误差(MSE)作为损失函数,以测量重构误差。优化器如Adam通常是一个不错的选择。
criterion = nn.MSELoss() optimizer = torch.optim.Adam(autoencoder.parameters(), lr=0.001)
4.3.3 训练循环
以下是标准的训练循环,其中包括前向传播、损失计算、反向传播和权重更新。
# 设定训练周期
epochs = 50
for epoch in range(epochs):
for data in dataloader:
# 获取输入数据
inputs, _ = data
# 清零梯度
optimizer.zero_grad()
# 前向传播
outputs = autoencoder(inputs)
# 计算损失
loss = criterion(outputs, inputs)
# 反向传播
loss.backward()
# 更新权重
optimizer.step()
# 打印训练进度
print(f"Epoch [{epoch + 1}/{epochs}], Loss: {loss.item():.4f}")
4.3.4 验证和测试
在训练过程中或训练结束后,对自动编码器的性能进行验证和测试。
- 使用单独的验证集评估模型在未见数据上的性能。
- 可以通过可视化原始图像和重构图像来定性评估模型。
4.3.5 模型保存
保存训练好的模型,以便以后使用或进一步优化。
torch.save(autoencoder.state_dict(), 'autoencoder_model.pth')
4.4 模型推理用于生成环境
部署自动编码器到生成环境是一个复杂的任务,涉及模型的加载、预处理、推理以及后处理等步骤。以下是一些核心环节的指南:
4.4.1 模型加载
首先,需要从保存的文件中加载训练好的模型。假设模型已保存在’autoencoder_model.pth’中,加载的代码如下:
model = Autoencoder(input_dim=784, encoding_dim=64)
model.load_state_dict(torch.load('autoencoder_model.pth'))
model.eval() # 将模型设置为评估模式
4.4.2 数据预处理
在生成环境中,输入数据可能来自不同的源,并且可能需要进行预处理以满足模型的输入要求。
- 加载数据:从文件、数据库或网络服务加载数据。
- 转换数据:例如,将图像转换为模型所需的维度和类型。
4.4.3 模型推理
使用处理过的输入数据对模型进行推理,并获取重构的输出。
with torch.no_grad(): # 不需要计算梯度
outputs = model(inputs)
4.4.4 结果后处理和展示
根据具体应用,可能需要将模型的输出进行进一步的处理和展示。
- 转换输出:将输出转换为适当的格式或维度。
- 展示结果:通过Web服务、图表或其他方式展示结果。
4.4.5 集成到Web服务
在许多情况下,可能需要将自动编码器集成到Web服务中,以便通过API进行访问。这可能涉及以下步骤:
- 构建API:使用诸如Flask或Django的框架构建API。
- 封装模型:将推理代码封装为可以通过HTTP调用的函数。
- 处理请求和响应:解析来自客户端的请求,格式化模型的响应。
4.4.6 性能优化和扩展
在生成环境中,模型的性能和可扩展性可能是关键问题。
- 优化推理速度:可能涉及模型量化、硬件加速等。
- 扩展支持:可能需要集群或其他技术来支持多用户并发访问。
4.5 多平台推理部署

在许多实际应用场景中,可能需要将训练好的自动编码器模型部署到不同的平台或设备上。这可能包括云端服务器、边缘设备、移动应用等。使用ONNX(Open Neural Network Exchange)格式可以方便地在不同平台上部署模型。
4.5.1 转换为ONNX格式
首先,需要将训练好的PyTorch模型转换为ONNX格式。这可以使用PyTorch的torch.onnx.export函数实现。
import torch.onnx # 假设model是训练好的模型 input_example = torch.rand(1, 784) # 创建一个输入样例 torch.onnx.export(model, input_example, "autoencoder.onnx")
4.5.2 ONNX模型验证
可以使用ONNX的工具进行模型的验证,确保转换正确。
import onnx
onnx_model = onnx.load("autoencoder.onnx")
onnx.checker.check_model(onnx_model)
4.5.3 在不同平台上部署
有了ONNX格式的模型,就可以使用许多支持ONNX的工具和框架在不同平台上部署。
- 云端部署:使用诸如Azure ML、AWS Sagemaker等云服务部署模型。
- 边缘设备部署:使用ONNX Runtime或其他兼容框架在IoT设备上运行模型。
- 移动设备部署:可使用像ONNX Runtime Mobile这样的工具在iOS和Android设备上部署。
4.5.4 性能调优
部署到特定平台时,可能需要进行性能调优以满足实时或资源受限的需求。
- 量化:通过减少权重和计算的精度降低资源消耗。
- 加速器支持:针对GPU、FPGA等硬件加速器优化模型。
4.5.5 持续监控和更新
部署后的持续监控和定期更新是确保模型在生产环境中稳定运行的关键。
- 监控:监视模型的性能、资源使用和预测质量。
- 更新:根据新数据和反馈定期更新和优化模型。
五、总结
本文详细介绍了自动编码器的理论基础、不同类型、应用场景以及实战部署。以下是主要的实战细节总结:
理论与实践结合
我们不仅深入探讨了自动编码器的工作原理和数学基础,还通过实际代码示例展示了如何构建和训练模型。理论与实践的结合可以增强对自动编码器复杂性的理解,并为实际应用打下坚实基础。
多场景应用
自动编码器的灵活性在许多应用场景中得到了体现,从图像重构到异常检测等。了解这些应用可以启发更广泛和深入的使用。
实战演示
本文的实战演示部分涵盖了从环境准备、模型构建、训练,到生成环境部署和多平台推理的全过程。这些细节反映了模型从实验到生产的整个生命周期,并涉及许多实际问题和解决方案。
多平台推理
通过ONNX等开放标准,我们展示了如何将自动编码器部署到不同平台上。这一部分反映了现代AI模型部署的复杂性和多样性,并提供了一些实用的工具和技巧。
-
实战:30 行代码做一个网页端的 AI 聊天助手11-20
-
5分钟搞懂大模型的重复惩罚后处理11-18
-
基于Ollama和pgai的个人知识助手项目:用Postgres和向量扩展打造智能数据库11-18
-
我用同一个提示测试了4款AI工具,看看谁设计的界面更棒11-15
-
深度学习面试的时候,如何回答1x1卷积的作用11-15
-
检索增强生成即服务:开发者的得力新帮手11-15
-
技术与传统:人工智能时代的最后一袭纱丽11-15
-
未结构化数据不仅仅是给嵌入用的:利用隐藏结构提升检索性能11-15
-
Emotion项目实战:新手入门教程11-15
-
7 个开源库助你构建增强检索生成(RAG)、代理和 AI 搜索11-15
-
Vertex AI上下文缓存与Gemini模型详解11-15
-
用可视化评估你的检索增强生成系统:RAG系统的评估与分析11-15
-
强化学习:教智能代理操作发电厂的方法11-15
-
质量工程师眼中的检索增强生成(RAG)解析11-15
-
让我们聊一聊算法和社会媒体那些事儿11-15
