人工智能学习
Lora升级!ReLoRa!最新论文 High-Rank Training Through Low-Rank Updates


摘要
尽管通过扩展导致具有数千亿参数的大型网络在统治和效率方面表现突出,但训练过参数化模型的必要性仍然难以理解,且替代方法不一定能使训练高性能模型的成本降低。在本文中,我们探索了低秩训练技术作为训练大型神经网络的替代方法。我们引入了一种名为 ReLoRA 的新方法,该方法利用低秩更新来训练高秩网络。我们将 ReLoRA 应用于预训练最多达 350M 参数的变换器语言模型,并展示了与常规神经网络训练相当的性能。此外,我们观察到 ReLoRA 的效率随着模型大小的增加而提高,使其成为训练多十亿参数网络的有效方法。我们的研究发现揭示了低秩训练技术的潜力及其对扩展规律的影响。代码已在 GitHub 上提供。
1 引言
在过去的十年中,机器学习领域一直被训练越来越多参数化的网络或采取“叠加更多层”的方法所主导。大型网络的定义已经从具有1亿个参数的模型演变到数百亿个参数,这使得与训练这样的网络相关的计算成本对大多数研究团队来说变得过于昂贵。尽管如此,与训练样本相比,需要训练数量级更多的参数的模型的必要性在理论上仍然理解不足。
例如更有效的计算扩展最优化、检索增强模型、以及通过更长时间训练较小模型的简单方法等替代扩展方法,都提供了新的权衡。然而,它们并没有让我们更接近理解为什么我们需要过参数化的模型,也很少使这些模型的训练民主化。例如,训练RETRO需要一套复杂的训练设置和基础设施,能够快速搜索数万亿的标记,而训练LLaMA-6B仍然需要数百个GPU。
相比之下,像零冗余优化器、16位训练、8位推断和参数有效微调(PEFT)等方法在使大型模型更易访问方面发挥了关键作用。具体来说,PEFT方法使得在消费者硬件上微调十亿规模的语言或扩散模型成为可能。这引发了一个问题:这些方法是否也能惠及预训练?
一方面,预训练正是允许对网络进行微小修改以使其适应新任务的步骤。Aghajanyan等人已经证明,预训练网络越多,学习任务所需的更改的秩就越小。另一方面,多项研究已经证明了语言和视觉模型提取和利用的特征的简单性,以及它们的低固有维度。例如,变换器中的注意力模式通常呈现小秩,这已经被成功用于开发更高效的注意力变体。此外,训练过程中也并不需要过参数化。彩票票据假说从经验上证明,在初始化(或训练早期)时,存在子网络 - 获胜票据,当单独训练时可以达到整个网络的性能。
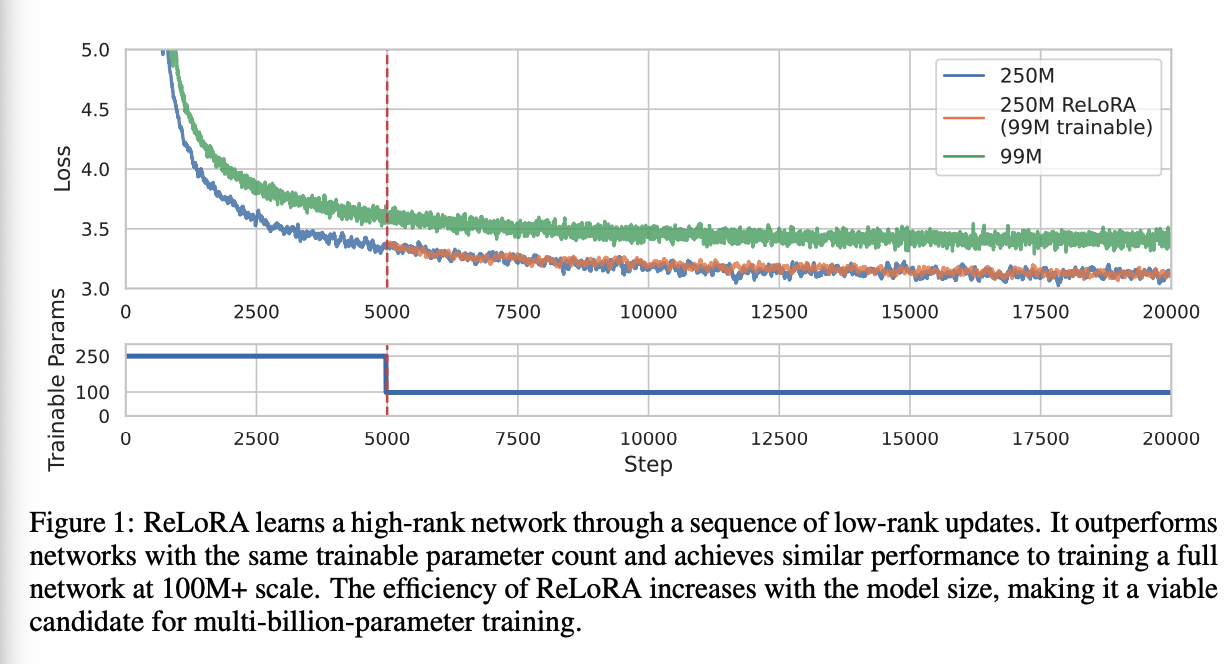
在本研究中,我们专注于低秩训练技术,并介绍了ReLoRA,它使用低秩更新来训练高秩网络。我们凭经验证明ReLoRA执行高秩更新,并实现与常规神经网络训练相似的性能。ReLoRA的组成部分包括神经网络的初始完全秩训练(类似于Frankle等人),LoRA训练,重新开始,锯齿状学习速率计划,以及部分优化器重置。我们对ReLoRA在高达350M参数的变换器语言模型上的效果进行评估。我们选择专注于自回归语言建模,因为这种方法在神经网络的大多数应用中已经展示了其通用性。最后,我们观察到ReLoRA的效率随着模型大小的增加而增加,使其成为有效训练多十亿参数网络的可行选择。
本研究中的每个实验均未使用超过8个GPU天的计算。
2 相关工作
缩放与效率 过参数化与神经网络的可训练性和泛化之间的关系已经得到了广泛的研究,但仍然是一个谜。此外,缩放法则展示了网络大小与其在各种模态之间的性能之间存在简单而强烈的幂律依赖关系。这一发现不仅支持过参数化,而且还鼓励对非常消耗资源的神经网络进行训练。然而,彩票假设表明原则上可以最小化过参数化。具体来说,它表明在训练初期存在可以训练以达到整个网络性能的子网络(中奖彩票)。
参数高效微调 Aghajanyan等人发现预训练减少了网络的变化量或其固有维数,以通过微调学习新任务。即,更大的网络或在更多数据上预训练的网络在学习新任务时需要较小的修改,就其范围的秩而言。这解释了参数高效微调方法的成功,并且还激发了像LoRA和Compacter这样的低秩微调方法的发展。
低秩神经网络训练 在CNN压缩、正则化和高效训练的背景下已经探讨了训练低秩表示。然而,这些方法中的大多数要么特定于CNN,要么不具备良好的可扩展性,要么没有在具有数亿参数的大型转换器上进行评估,而这些转换器可以从高效训练中大大受益。虽然转换器已被证明具有低秩的内部维数和表示,但Bhojanapalli等人的研究表明,在多头注意力中关键和查询投影的低秩限制了转换器的性能。我们自己的实验(第3节)也表明,与完整秩基线和ReLoRA相比,低秩转换器的性能明显较差。
3 方法
让我们从重新审视线性代数101开始。特别是,我们对两个矩阵之和的秩感兴趣:
rank(A + B) ≤ rank(A) + rank(B)。(1)
对和的秩的这个界限是紧的:对于矩阵A,有rank(A) < dim(A),存在B,使得rank(B) < dim(B),并且矩阵之和的秩高于A或B。我们想要利用这个属性来制造一种灵活的参数高效的训练方法。我们从LoRA开始,它是一种基于低秩更新思想的参数高效微调方法。LoRA可以应用于任何通过W ∈ R^m×n参数化的线性操作。具体来说,LoRA将权重更新δW分解为低秩乘积WAWB,如方程2所示,其中s ∈ R是通常等于1/r的固定缩放因子。
δW = sWAWB
WA ∈ R^in×r
, WB ∈ R^r×out(2)
在实践中,LoRA通常是通过添加新的可训练参数WA和WB来实现的,这些参数可以在训练后合并回原始参数。因此,即使方程1允许在训练时间P_t δWt内的总更新具有高于任何单个矩阵的更高的秩,LoRA实现也受到秩r = maxWA,WB rank(WAWB)的限制。
如果我们可以重新启动LoRA,即在训练期间合并WA和WB并重置这些矩阵的值,我们可以增加更新的总秩。多次这样做将整个神经网络更新带到
∆W = ΣT1_t=0 δWt + ΣT2_t=T1 δWt + · · · + ΣTN_t=TN−1 δWt = sW1_AW1_B + sW2_AW2_B + · · · + sWN_AWN_B(3)
其中,总和是独立的,意味着rank(Wi_AWi_B) + rank(Wj_AWj_B) ≥ r。然而,在实践中实现重新启动并不是微不足道的,需要对优化过程进行一些修改。天真的实现会导致模型在重新启动后立即发散。与仅依赖于当前优化时间步的梯度值的普通随机梯度下降不同,Adam更新主要由之前步骤累积的梯度的第一和第二时刻指导。在实践中,梯度矩滑参数β1和β2通常非常高,即0.9 - 0.999。假设在重新初始化边界W1_A和相应的梯度矩mA和vA处是全秩的®。那么,在合并和重新初始化后,继续使用W2_A的旧梯度矩将引导它沿着W1_A的相同方向,并优化相同的子空间。
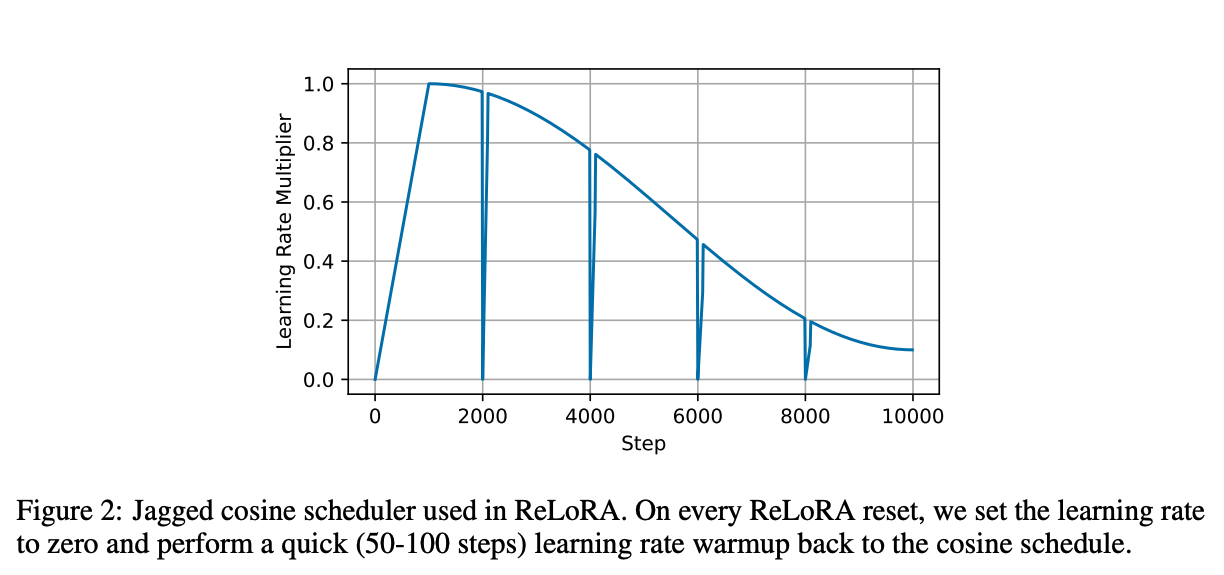
为了解决这个问题,我们提出了ReLoRA。ReLoRA在合并和重新初始化期间对优化器状态进行部分重置,并将学习率设置为0,并随后进行热启动。具体来说,我们将99%的低幅度优化器状态值设置为零,并使用锯齿状余弦学习率计划(图2)。我们的消融研究(表3)表明,这两项修改都是提高LoRA性能的必要条件。
重申一下,ReLoRA是一种受LoRA启发的低秩训练方法,通过重新启动来增加更新的有效秩,使用部分优化器重置和锯齿调度器来稳定训练和热启动。所有这些都使ReLoRA能够通过一次仅训练一小部分参数实现与全秩训练相当的性能,特别是在大型变换器网络中。ReLoRA在算法1中描述。
提高计算效率 与其他低秩训练技术不同,ReLoRA通过保持原始网络的冻结权重并添加新的可训练参数来遵循LoRA方法。乍一看,这似乎在计算上是低效的;然而,冻结和可训练参数之间的区别在参数高效微调中起到了关键作用。
这些方法通过减小梯度和优化器状态的大小,显著提高了训练时间和内存效率。值得注意的是,Adam状态消耗的内存是模型权重的两倍。此外,对于大型网络,通常的做法是以32位精度保持梯度累积缓冲区,从而增加了梯度的内存消耗的重要开销。
通过大幅减少可训练参数的数量,ReLoRA使得能够使用更大的批次大小,最大化硬件效率。此外,它还减少了分布式设置中的带宽要求,这通常是大规模训练的限制因素。
此外,由于冻结参数在重新启动之间没有被更新,所以它们可以保持在低精度量化格式中,进一步减少它们的内存和计算影响。
这一额外的优化有助于整体提高ReLoRA在内存利用和计算资源方面的效率,并在规模上增加。

4 实验
为了评估ReLoRA的有效性,我们将其应用于使用各种模型大小:60M、130M、250M和350M,在C4数据集上训练变换器语言模型。语言建模已被证明是机器学习的基本任务,它能够实现文本和图像分类、翻译、编程、上下文学习、逐步推理等许多其他新兴能力。鉴于其重要性,本文的目的仅关注语言建模。
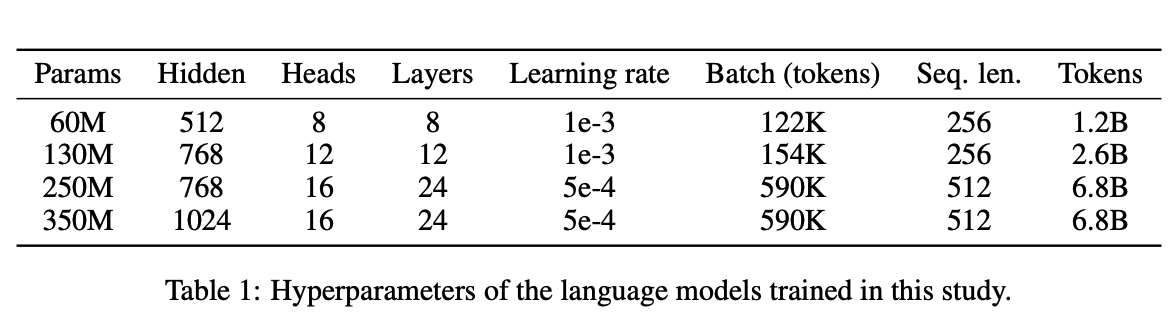
架构和训练超参数 我们的架构基于变换器,并与LLaMA非常相似。具体来说,我们使用预归一化、RMSNorm、SwiGLU激活、全连接隐藏状态大小,以及旋转嵌入。对于所有LoRA和ReLoRA实验,我们使用秩r = 128,因为我们的初步实验显示它具有最佳的困惑度/内存权衡。所有超参数均在表1中呈现。
我们对所有浮点操作使用bfloat16,并使用Flash注意力进行有效的注意力计算。与LLaMA中使用float32进行softmax计算的注意力相比,这增加了50-100%的训练吞吐量,而没有任何训练稳定性问题。
我们大部分模型在8个RTX 4090上训练了一天或更短的时间。由于计算限制,我们训练的模型要比LLaMA小得多,最大的模型拥有350M个参数,与BERT Large相同。我们根据Chinchilla缩放定律为所有模型选择预训练令牌的数量,除了最大的一个,我们为其训练了6.8B个令牌,而9.5B个令牌是Chinchilla最优的。
ReLoRA和基线设置 在我们的低秩训练实验中,ReLoRA替换了所有注意力和全连接网络参数,同时保持嵌入全秩。RMSNorm参数化保持不变。由于ReLoRA封装的模型比全秩训练具有更少的可训练参数,因此我们包括了一个控制基线,即具有与ReLoRA相同数量可训练参数的全秩变换器。
我们从全秩训练的5,000次更新步骤的检查点开始初始化ReLoRA,并在此后的每5,000步重置一次,总共3次。每次重置后,基于大小修剪99%的优化器状态,并在接下来的100次迭代中预热损失。ReLoRA参数按照LoRA的最佳实践重新初始化,A矩阵使用Kaiming初始化,B矩阵使用零。如果不使用重新启动,B矩阵也使用Kaiming初始化以避免梯度对称性问题。
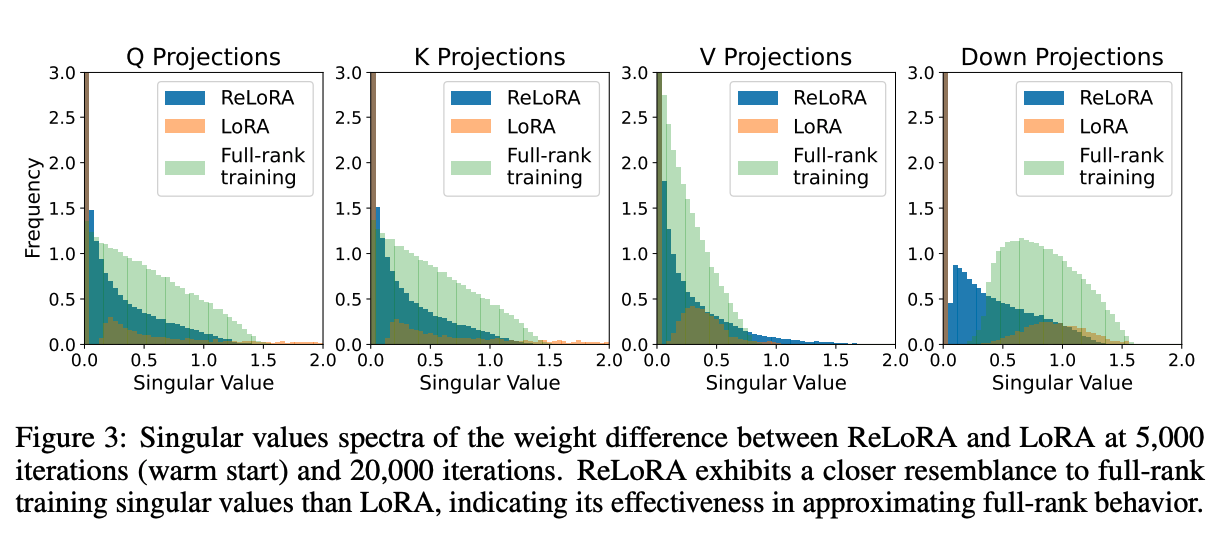
5 结果
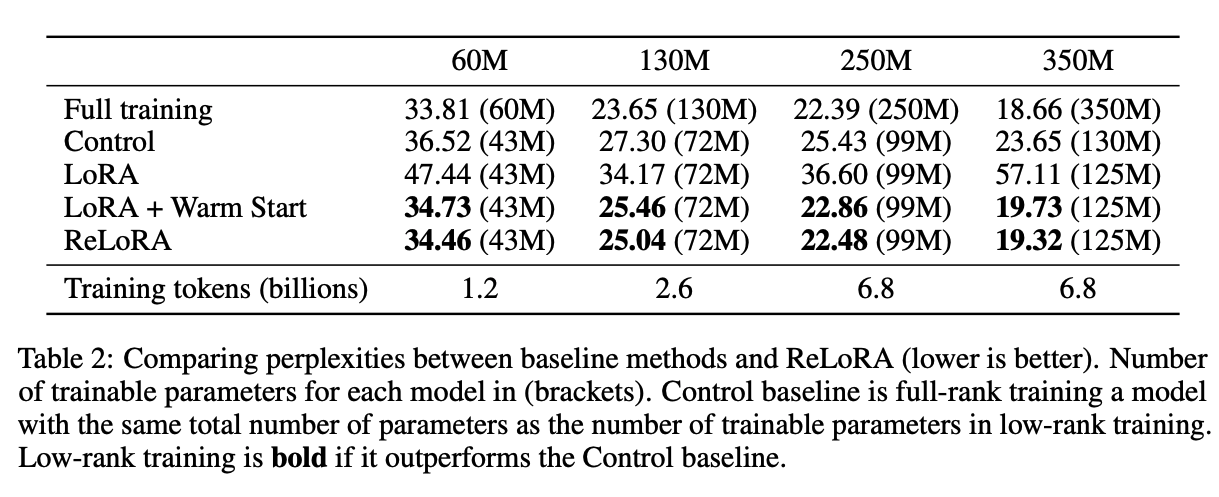
参数高效的预训练 我们的主要结果在表2中展示。ReLoRA显著优于低秩LoRA训练,展示了我们所提出修改的有效性(在第3节中剖析)。此外,ReLoRA的表现与全秩训练相似,且随着网络大小的增加,性能差距逐渐减小。
通过低秩更新进行高秩训练 为了确定ReLoRA是否执行比LoRA更高的秩更新,我们绘制了ReLoRA、LoRA和全秩训练的热启动权重与最终权重之间差异的奇异值谱图。图3描绘了LoRA和ReLoRA在WQ、WK、WV和Wdown的奇异值之间的显著定性差异。
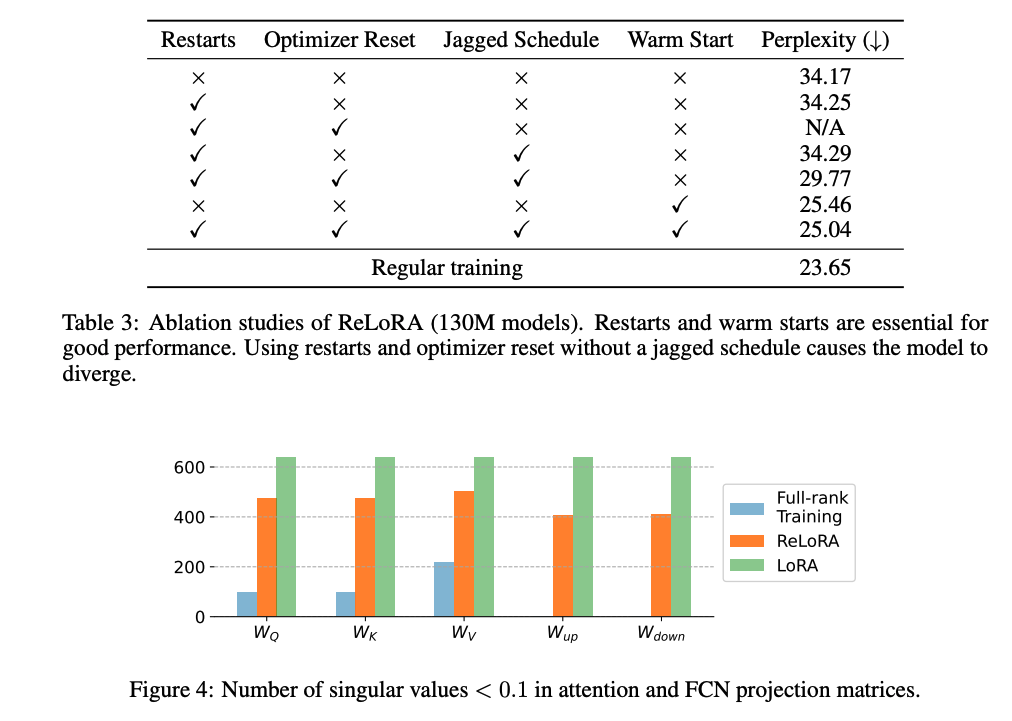
虽然LoRA的大部分奇异值为零(图4),且有显著数量的异常高值超过1.5,但ReLoRA在0.1和1.0之间呈现更高的分布质量,让人联想到全秩训练。这一观察强调了高秩更新的重要性,并展示了ReLoRA的定性功效,其通过执行多个低秩更新实现高秩更新。
5.1 剖析研究
我们对ReLoRA的四个关键组件:重启、锯齿状调度、优化器重置和温暖启动进行剖析研究,使用130M大小的模型。结果展示在表3中。在本节中,我们将重点关注和分析这些组件的某些组合。
LoRA ReLoRA,没有上述组件,本质上等同于通过LoRA参数化训练低秩网络。这种方法产生了极高的困惑度,表明简单的矩阵分解与全秩训练有显著不同的训练动态。
添加重启和优化器重置 ReLoRA,没有锯齿状调度和优化器重置,表现与LoRA相似,因为旧的优化器状态将新初始化的参数强制进入与先前权重相同的子空间,限制了模型的容量。然而,用ReLoRA进行天真的优化器重置会导致模型发散。锯齿状调度有助于稳定训练,并对混合物产生积极影响。在我们的初步实验中,我们还观察到,部分优化器重置和锯齿状调度器的组合允许更快的预热,低至50步,而不是从头开始初始化优化器时所需的数百步。
温暖启动 温暖启动显示了最显著的改进,使困惑度降低了近10点。为了调查预热后训练是否有助于损失,我们测量了预热网络的困惑度,等于27.03。它优于所有低秩方法,除了我们最终的ReLoRA配方,但仍然显示出与最终网络的显著差异。这展示了早期训练的重要性,类似于彩票假说与倒带的概念。
6 结论
在本文中,我们研究了大型变换器语言模型的低秩训练技术。我们首先检查了简单低秩矩阵分解(LoRA)方法的局限性,并观察到它在有效训练高性能变换器模型方面存在困难。为解决这个问题,我们提出了一种名为ReLoRA的新方法,它利用秩的和性质通过多个低秩更新来训练高秩网络。与彩票假说和倒带相似,ReLoRA在转变为ReLoRA之前采用全秩训练的温暖启动。此外,ReLoRA引入了合并和重新初始化(重启)策略、锯齿状学习速率调度器和部分优化器重置,这些共同增强了ReLoRA的效率,并使其更接近全秩训练,特别是在大型网络中。随着网络大小的增加,ReLoRA的效率提高,使其成为多十亿规模训练的可行候选方案。
我们坚信,低秩训练方法的发展对于提高训练大型语言模型和一般神经网络的效率具有很大的潜力。此外,低秩训练还有潜力为深度学习理论的进步提供有价值的见解,有助于我们通过梯度下降理解神经网络的可训练性以及在过参数化体系中的卓越泛化能力。
7 局限性和未来工作
超越350M的扩展 由于计算资源有限,我们的实验仅限于训练多达350M参数的语言模型。然而,ReLoRA已经在此规模上展示了有希望的结果。不过,我们预计其真正的潜力将在1B+参数区域实现。此外,虽然350M模型胜过控制基线,但并未继续缩小ReLoRA和全秩训练之间的差距的趋势。我们将这一现象归因于次优的超参数选择,这需要进一步研究。
此外,在60-350M的实验中,尽管ReLoRA显著减少了可训练参数的数量,但我们并未观察到对这种大小的网络在内存和计算方面的实质改进。为了评估我们当前实现在更大规模上的效率,我们训练了1.3B参数的模型进行少量迭代,以估计ReLoRA的内存和计算改进。在这个规模下,我们观察到30%的内存消耗减少和52%的训练吞吐量增加。我们期望在更大的网络中观察到相对全训练基线的更大改进,因为ReLoRA的可训练参数数量(与LoRA类似)相较于冻结参数的数量增加得要慢得多。ReLoRA的实现可以通过有效利用ReLoRA层的梯度检查点、自定义反向函数和将冻结模型权重转换为int8或int4量化格式[14]来进一步改进。
与其他低秩训练方法的比较 早期的工作已经探索了许多低秩训练方法与其他模型架构的组合[44,49,55]。我们的工作与这些早期努力有两个方面的不同。首先,我们提出的方法通过低秩训练执行高秩更新。其次,我们的工作展示了在具有100M+参数的大规模变换器语言模型中,低秩训练方法的竞争力。
-
实战:30 行代码做一个网页端的 AI 聊天助手11-20
-
5分钟搞懂大模型的重复惩罚后处理11-18
-
基于Ollama和pgai的个人知识助手项目:用Postgres和向量扩展打造智能数据库11-18
-
我用同一个提示测试了4款AI工具,看看谁设计的界面更棒11-15
-
深度学习面试的时候,如何回答1x1卷积的作用11-15
-
检索增强生成即服务:开发者的得力新帮手11-15
-
技术与传统:人工智能时代的最后一袭纱丽11-15
-
未结构化数据不仅仅是给嵌入用的:利用隐藏结构提升检索性能11-15
-
Emotion项目实战:新手入门教程11-15
-
7 个开源库助你构建增强检索生成(RAG)、代理和 AI 搜索11-15
-
Vertex AI上下文缓存与Gemini模型详解11-15
-
用可视化评估你的检索增强生成系统:RAG系统的评估与分析11-15
-
强化学习:教智能代理操作发电厂的方法11-15
-
质量工程师眼中的检索增强生成(RAG)解析11-15
-
让我们聊一聊算法和社会媒体那些事儿11-15
