Go教程
【2023年】第38天 Googlenet四个版本的比较

一、Googlenet Abstract
1. Googlenet V1 Abstract
- We propose a deep convolutional neural network architecture codenamed Inception, which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC14).
我们提出了一种代号为 "Inception "的深度卷积神经网络架构,该架构在 2014 年 ImageNet 大规模视觉识别挑战赛(ILSVRC14)中为分类和检测技术树立了新的典范。 - The main hallmark of this architecture is the improved utilization of the computing resources inside the network.
这种架构的主要特点是提高了网络内计算资源的利用率。 - This was achieved by a carefully crafted design that allows for increasing the depth and width of the network while keeping the computational budget constant.
这是通过精心设计实现的,在保持计算预算不变的情况下,可以增加网络的深度和宽度。 - To optimize quality, the architectural decisions were based on the Hebbian principle and the intuition of multi-scale processing.
为了优化质量,架构决策是基于海比原理和多尺度处理的直觉。 - One particular incarnation used in our submission for ILSVRC14 is called GoogLeNet, a 22 layers deep network, the quality of which is assessed in the context of classification and detection.
我们向 ILSVRC14 提交的论文中使用的一个特殊版本名为 GoogLeNet,它是一个 22 层的深度网络,其质量是在分类和检测的背景下评估的。
2. Googlenet V2 Abstract
- Training Deep Neural Networks is complicated by the fact that the distribution of each layer’s inputs changes during training, as the parameters of the previous layers change.
训练深度神经网络非常复杂,因为在训练过程中,随着前几层参数的变化,每一层输入的分布也会发生变化。 - This slows down the training by requiring lower learning rates and careful parameter initialization, and makes it notoriously hard to train models with saturating nonlinearities.
这需要较低的学习率和谨慎的参数初始化,从而减慢了训练速度,并使训练具有饱和非线性特性的模型变得非常困难。 - We refer to this phenomenon as internal covariate shift, and address the problem by normalizing layer inputs.
我们将这种现象称为内部协变量偏移,并通过对图层输入进行归一化处理来解决这一问题。 - Our method draws its strength from making normalization a part of the model architecture and performing the normalization for each training mini-batch.
我们的方法的优势在于将归一化作为模型架构的一部分,并对每个训练小批量进行归一化。 - Batch Normalization allows us to use much higher learning rates and be less careful about initialization.
批量归一化允许我们使用更高的学习率,并且在初始化方面也不那么谨慎。 - It also acts as a regularizer, in some cases eliminating the need for Dropout.
它还能起到正则化的作用,在某些情况下无需使用 Dropout。 - Applied to a state-of-the-art image classification model, Batch Normalization achieves the same accuracy with 14 times fewer training steps, and beats the original model by a significant margin.
将批量归一化应用于最先进的图像分类模型时,训练步骤减少了 14 倍,却达到了相同的准确率,并以显著优势击败了原始模型。 - Using an ensemble of batchnormalized networks, we improve upon the best published result on ImageNet classification: reaching 4.9% top-5 validation error (and 4.8% test error), exceeding the accuracy of human raters.
利用批量归一化网络的集合,我们改进了 ImageNet 分类的最佳公开结果:前五名验证误差为 4.9%(测试误差为 4.8%),超过了人类评分员的准确率。
3. Googlenet V3 Abstract
- Convolutional networks are at the core of most state-of-the-art computer vision solutions for a wide variety of tasks.
卷积网络是最先进的计算机视觉解决方案的核心,适用于各种任务。 - Since 2014 very deep convolutional networks started to become mainstream, yielding substantial gains in various benchmarks.
自 2014 年以来,深度卷积网络开始成为主流,并在各种基准测试中取得了显著提高。 - Although increased model size and computational cost tend to translate to immediate quality gains for most tasks (as long as enough labeled data is provided for training), computational efficiency and low parameter count are still enabling factors for various use cases such as mobile vision and big-data scenarios.
虽然对于大多数任务来说,模型规模和计算成本的增加往往会带来直接的质量提升(只要提供足够的标注数据用于训练),但计算效率和低参数数量仍然是移动视觉和大数据场景等各种使用案例的有利因素。 - Here we are exploring ways to scale up networks in ways that aim at utilizing the added computation as efficiently as possible by suitably factorized convolutions and aggressive regularization.
在这里,我们正在探索扩展网络的方法,目的是通过适当的因式卷积和积极的正则化,尽可能高效地利用增加的计算量。 - We benchmark our methods on the ILSVRC 2012 classification challenge validation set demonstrate substantial gains over the state of the art: 21.2% top-1 and 5.6% top-5 error for single frame evaluation using a network with a computational cost of 5 billion multiply-adds per inference and with using less than 25 million parameters.
- 我们在 ILSVRC 2012 分类挑战验证集上对我们的方法进行了基准测试,结果表明我们的方法比目前的技术水平有了大幅提高:使用计算成本为每次推理 50 亿次乘法加法的网络和使用不到 2500 万个参数的情况下,单帧评估的前 1 名错误率为 21.2%,前 5 名错误率为 5.6%。
- With an ensemble of 4 models and multi-crop evaluation, we report 3.5% top-5 error and 17.3% top-1 error.
通过 4 个模型的集合和多作物评估,我们发现前 5 名的误差率为 3.5%,前 1 名的误差率为 17.3%。
4. Googlenet V4 Abstract
- Very deep convolutional networks have been central to the largest advances in image recognition performance in recent years.
深度卷积网络是近年来图像识别性能最大进步的核心。 - One example is the Inception architecture that has been shown to achieve very good performance at relatively low computational cost.
其中一个例子是 Inception 架构,该架构已被证明能以相对较低的计算成本实现非常出色的性能。 - Recently, the introduction of residual connections in conjunction with a more traditional architecture has yielded state-of-the-art performance in the 2015 ILSVRC challenge; its performance was similar to the latest generation Inception-v3 network.
最近,在 2015 年 ILSVRC 挑战赛中,残差连接与更传统的架构相结合,产生了最先进的性能;其性能与最新一代 Inception-v3 网络相似。 - This raises the question of whether there are any benefit in combining the Inception architecture with residual connections.
这就提出了一个问题:将 Inception 架构与残差连接相结合是否有任何好处。 - Here we give clear empirical evidence that training with residual connections accelerates the training of Inception networks significantly.
在这里,我们给出了明确的经验证据,证明使用残差连接进行训练能显著加快 Inception 网络的训练速度。 - There is also some evidence of residual Inception networks outperforming similarly expensive Inception networks without residual connections by a thin margin.
还有一些证据表明,有残余连接的初始网络比没有残余连接的类似昂贵无参差初始网络的性能要好得多。 - We also present several new streamlined architectures for both residual and non-residual Inception networks.
我们还为残差和非残差 Inception 网络提出了几种新的精简架构。 - These variations improve the single-frame recognition performance on the ILSVRC 2012 classification task significantly.
这些变化大大提高了 ILSVRC 2012 分类任务的单帧识别性能。 - We further demonstrate how proper activation scaling stabilizes the training of very wide residual Inception networks.
我们还进一步展示了适当的激活比例如何稳定非常宽的残差 Inception 网络的训练。 - With an ensemble of three residual and one Inception-v4, we achieve 3.08% top-5 error on the test set of the ImageNet classification (CLS) challenge.
在 ImageNet 分类(CLS)挑战赛的测试集上,我们利用由三个残差和一个 Inception-v4 组成的集合,取得了 3.08% 的前五名错误率。
二、Googlenet版本之间的比较
1. 模型结构
-
GoogLeNet与以前的卷积神经网络相比,除了在深度上进行了延申,还对网络的宽度进行了拓展。
-
GoogLeNet的整个网络由许多块状子网络堆叠而成,这个子网络构成了inception结构,inception v1在同一层中采用不同的卷积核,并对卷积核结果进行合并。
-
inception v2组合不同卷积核的堆叠形式,并对卷积结果进行合并。
-
inception v3则在inception v2基础上进行深度组合的尝试。
-
inception v4结构与前面的版本相比更加复杂,子网络中嵌套这子网络。

-
通过设计一个稀疏网络结构,也能产生稠密的数据,既能增加神经网络的表现,又能保证计算资源的使用效率。
-
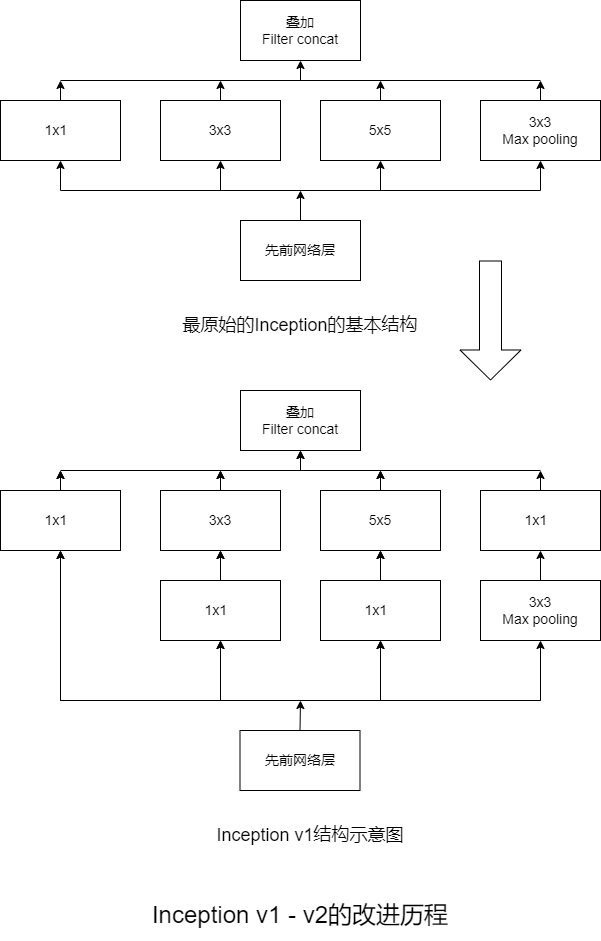
谷歌提出的最原始的Inception的基本结构,该结构将CNN中常用的卷积(1x1,3x3,5x5)、池化操作(3x3)堆叠在一起(卷积、池化后的尺寸相同,将通道相加),一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。
-
然后Inception原始版本的所有卷积核都在上一层的输出上,5x5的卷积核所需要的卷积核所需要的计算量太大,导致特征图的厚度很大,为了避免这种情况发生,在3x3卷积前、5x5卷积前、最大池化后分别加上了1x1的卷积核,以起到减小特征图厚度的作用,这也就形成了Inception v1的网络结构。
-
大尺寸的卷积核可以带来更大的感受野,但也意味着会产生更多的参数,比如5x5卷积核的参数有25个,3x3的卷积核的参数有9个,前者大约是后者的2.78倍。
-
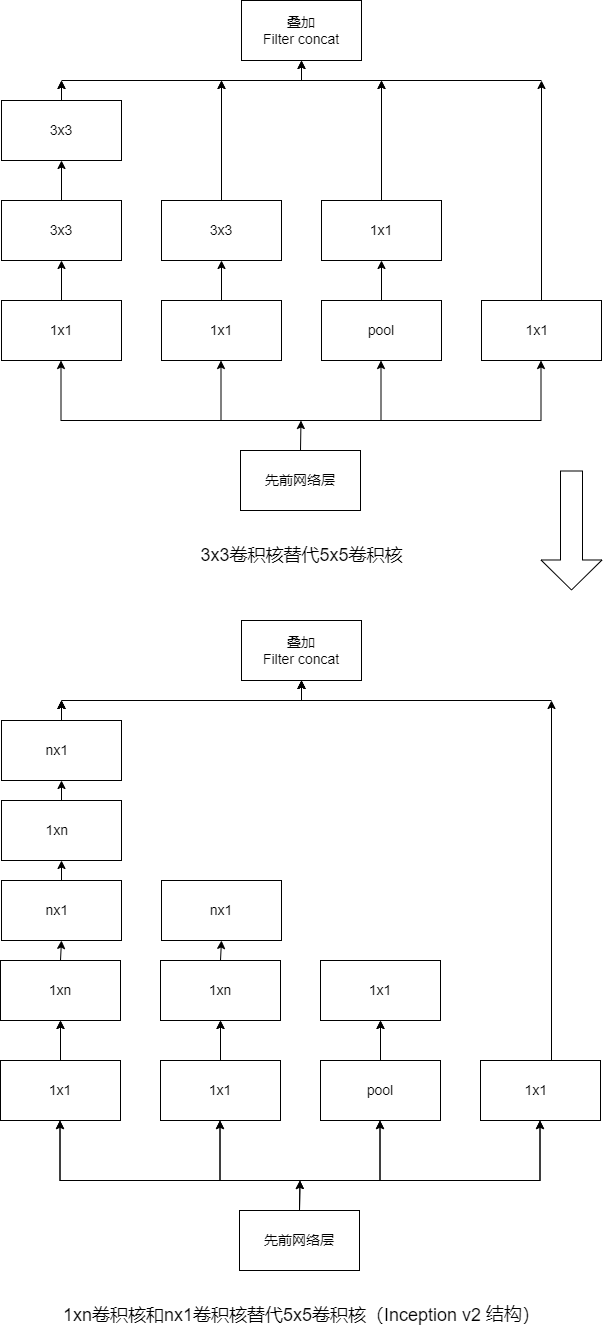
因此,GoogLeNet团队提出了可以用2个连续的3x3卷积层组成的小网络来代替单个的5x5的卷积层,即在保持感受野范围的同时又减小了参数两。
-
那么这种替代方案会不会造成表达能力的下降吗?大量实验表明,这种替代方案并不会造成表达能力的下降,所以大卷积核完全可以由一系列的3x3的卷积核替代。
-
那么,能不能再分的更小一点呢?GoogLeNet团队又考虑了nx1的卷积核,使用1xn卷积核和nx1卷积核代替5x5卷积核,即为Inception v2。
-
Inception v3最重要的一个改进是分解操作,将7x7分解成两个一维的卷积,分别是1x7卷积和7x1卷积,3x3也一样,分解为1x3卷积核3x1卷积,这样既可以加速计算,又可以将1个卷积拆成2个卷积,增加了网络的深度核网络的非线性(每增加一层都要进行Relu操作)。
-
Inception v4研究了Inception模块与残差连接的结合,Inception v4主要利用残差连接(Residual Connection)来改进Inception v3 结构。
2. 模型特性
GoogLeNet的模型特性:
(1)采用不同的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合。
(2)卷积核大小之所以采用1、3和5,主要是为了方便对地。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了。
(3)网络越到后面,特征越抽象,而且每个特征所涉及的感受野也会更大,因此随着层数的增加,3
x3和5x5卷积的比例也要增加。但是,使用5x5的卷积核仍然会带来巨大的计算量。为此,GoogLeNet也采用
1x1的卷积核来进行降维。
二、归一化
- 在训练数据之前,对训练数据集进行标准化和归一化处理,可以加快模型的收敛速度,而且更加重要的是在一定程度上缓解了深层网络中梯度弥散的问题,从而使训练深层网络模型更加的容易。
1. 归一化的含义
- 归一化的具体作用是归纳统一样本的统计分布性,归一化在[0, 1]之间是统计的概率分布,归一化在[-1, 1]之间是统计的坐标分布。
- 为了建模或者计算的方便,首先要保持度量单位的同一性,在深度学习中,当所有的样本的输入信号都为正值时,与第一隐含层神经元相连的权重只能同时增加或者减小,从而导致学习速度很慢。为了避免这种情况发生并方便后面数据的处理,加快网络学习速度,可以对输入信号进行归一化,使所有样本的输入信号均值接近与0或与其方差相比很小。
- 神经网络中的sigmoid激活函数取值在0-1之间,网络最后一个节点的输出也是如此。
2. 归一化和标准化的联系与区别
(1)两者的联系:
- 他们都能取消由于量纲不同引起的误差,都是一种线性变化,都是对向量按照比例压缩再进行平移。
(2)两者的区别:
- 归一化是将样本的特征值转换到同一量纲下,把数据映射到[0, 1]或[-1, 1]区间内,仅由变量的极值决定,区间缩放是归一化的一种。
- 标准化是将样本依照特征矩阵的列处理数据,通过求z-score的方法,将其转化为标准正态分布,使其和整体样本分布相关,每个样本点都能对标准化产生影响。
3. 为什么要归一化或标准化?
- 应用层面需要统一量纲,因为样本数据的评价标准不一样,需要对其量纲化,统一评价标准。
- 在使用梯度下降的方法求解最优化问题时,归一化或标准化后可以加快梯度下降的求解速度,即提升模型的收敛速度。
- 应用归一化可以避免神经元饱和,当神经元的激活在接近0或1时会饱和,在这些区域,梯度几乎为0。这样,在反向传播的过程中,局部梯度就会接近0,此时应用归一化可以有效的减少梯度消失。
- 避免输出数据中小的数值被吞食,也避免太大的数值引发数值问题。
4. 归一化有哪些类型
- 线性归一化:
线性归一化适用于数值比较集中的情况。缺点是如果max(x) 和 min(x) 不稳定,容易使归一化结果不稳定,后续使用效果也不稳定。 - 标准差标准化:
标准差标准化是让经过处理的数据符合标准正态分布,即均值为0,标准差为1。 - 非线性归一化:
非线性归一化经常用在数据分化比较大的场景,有些数值很大,有些很小。通过数学函数,将原始值进行映射,这些方法包括log、指数、正切等。
5. 局部响应归一化
- 局部响应归一化(Local Response Normalization,LRN)是一种提高深度学习准确度的技术方法。
- LRN一般是在激活、池化函数之后使用的一种处理方法。
- 在AlexNet中提出了LRN层,对局部神经元的活动创建竞争机制,使其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
6. 局部响应归一化原理
局部响应归一化原理是仿造生物学上活跃的神经元对相邻神经元的抑制现象(侧抑制)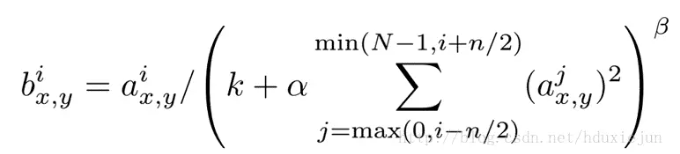
其中:
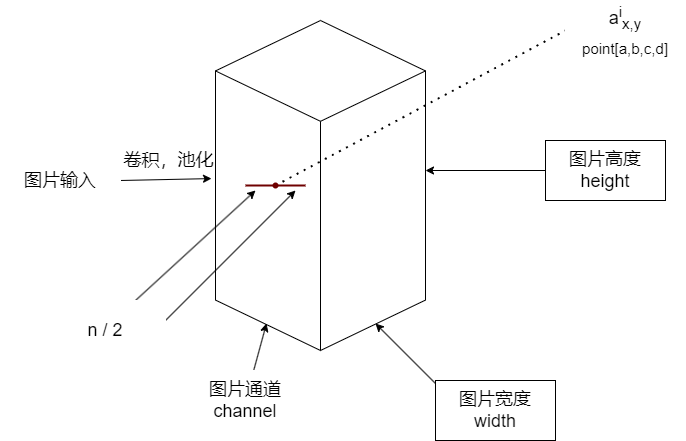
- a 表示卷积层后的输出结果,是一个四维数组 [batch, height, width, channel]。batch代表批次数,height代表图片高度,width代表图片宽度,channel代表通道数。可以理解为一批图片中的某一张图片经过卷积操作后输出的神经元个数,或者理解为处理后的图片深度。
- aix,y表示在这个输出结构中的一个位置[a, b, c, d],可以理解为某一张图中的某一个通道下的某个高度和某个宽度位置的点,即第a张图的第d个通道下的高度为b、宽度为c的点。
- N表示通道数量
- A、n/2、k分别代表input、depth_radius、bias。参数k、n、a、β都是超参数,一般设置k=2, n=5, a=e-4, β=0.75。
- ∑叠加的方向沿着通道方向,即每个点值的平方和是沿着a中的第三维通道方向的,也就是一个点同方向的前面n/2个通道(最小为第0个通道) 和后n/2个通道(最大为第d-1个通道)的点的平方和(共n+1个点)。
7. 什么是批归一化?
- 以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理。
- 虽然我们对输入数据进行了归一化处理,但只是输入数据经过σ = (Wx + b) 这样的矩阵乘法以及非线性的运算之后,其数据分布很可能被改变,而随着深度网络的多层运算,数据分布的变化将越来越大。
- 如果我们能够在网络的中间也进行归一化处理,是否对网络的训练起到改进的作用呢?我想答案是肯定的!
- 这种在神经网络中间层也进行了归一化处理,使训练效果更好的方法,就是批归一化(Batch Normalization,BN)
8.批归一化的优点
- 减少了对人为选择参数的依赖。在某些情况下可以取消DroPout方法和L2正则项参数,或者采用更小的L2正则项约束参数。
- 减少了对学习率的要求。使用批归一化后可以使用初始很大的学习率或选择较小的学习率,算法也能够快速训练收敛。
- 可以不再使用局部响应归一化,批归一化本身就是归一化网络。
- 破坏原有的数据分布,在一定程度上缓解过拟合,防止每一批训练中某一个样本经常被挑选到,有助于提高精度。
- 减少梯度消失,加快收敛速度,提高训练精度。
9. 批归一化算法流程
输入:上一层输出结果X = x1x2, … , xm,学习参数 γ 和 β。
(1)计算上一层输出数据的均值:
μ β = 1/m ∑ mi=1(xi)
其中,m是此次训练样本的Batch的大小。
(2)计算上一层输出数据的标准差:
σ2 β = 1/m ∑ mi=1(xi - μβ)2
(3)进行归一化处理
xi = (xi + μβ) / √ (μ2 β + ξ)
其中ξ是为了避免分母为0而加进去的接近于0的很小的值。
(4)重构,对经过上面归一化处理得到的数据进行重构,得到
y i = γ x i + β
其中γ和β都是可学习参数。
- 上述是批归一化训练时的过程,但是当投入使用时,往往只输入一个样本,没有均值,标准差。
- 此外,均值是从计算所有批次均值的平均值得到的,标准差根据每个批次的标准差无偏估计得到的。
10. 批归一化和组归一化的比较
- 批归一化(Batch Normalization,BN),可以让各种网络并行训练。但是批量维度进行归一化会带来一些问题,比如批量统计估算不准确导致当批量变小时,批归一化的误差会迅速增加。
- 在训练大型网络和将特征转移到计算机视觉任务中(包括检测,分割和视频),内存消耗限制了只能使用小批量的批归一化。
- 组归一化(Group Normalization,GN),组归一化将通道分成组,并在每组内计算归一化的均值和方差。组归一化的计算和批量大小无关,并且其准确度在各种批量大小下都很稳定。
- 在ImageNet上训练的ResNet-50上,组归一化使用批量大小为2时的错误率比批归一化的错误率第10.6%;当使用典型的批量时,组归一化和批归一化相当,并且优于其他归一化变体。而且组归一化可以自然的从预训练迁移到微调。在进行COCO中的目标检测和分割以及Kinetic中的视频分类的比赛中,组归一化可以胜过其他竞争对手,表明组归一化可以在各种任务中有效地取代强大的批归一化。
11.权重归一化和批归一化的比较
- 权重归一化(weight Normalization,WN)和批归一化(Batch Normalization,BN)都属于参数重写(Reparameterization)的方法,只是采用的方式不同。
- 权重归一化是网络权重W进行归一化;批归一化是对网络的某一层输入数据进行归一化。
权重归一化与批归一化相比有三点优势:
(1)权重归一化通过重写深度学习网络的权重W的方式来加速深度学习网络参数收敛,没有引入mini-batch的依赖,适用于RNN(LSTM)的网络。批归一化不能直接用于RNN进行归一化操作,原因在于:
- RNN处理的队列是变长的。
- RNN基于时间状态计算,如果直接使用批归一化处理,需要保存每个时间状态下mini-batch的均值和方差,效率低且占内存较多。
(2)批归一化基于一个mini-batch的数据计算均值和方差,而不是基于整个训练集来做,相当于进行梯度计算时引入了噪声。因此,批归一化不适用于对噪声敏感的强化学习、生成模型等使用。相反,权重归一化通过标量g和向量v对权重W进行重写,因此权重归一化可以比批归一化引入更少的噪声。
(3)权重归一化不需要额外的存储空间来保存mini-batch的均值和方差,正向和反向传播实现时额外的计算开销也更小。
(4)但是权重归一化不具有批归一化把网络每一层的输出固定在一个变化范围内的能力,因此采用权重归一化时需要注意参数初始化策略的选择。
12. 批归一化的适用范围
- 在CNN中,批归一化应作用在非线性映射之前。在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试使用批归一化来解决。另外,在一般使用情况下也可以加入批归一化来加快训练速度,提高模型精度。
- 批归一化化比较适用于每个mini-batch比较大,数据分布比较近的场景。另外,由于批归一化化需要在运行过程中统计每个mini-batch的一阶统计量和二阶统计量,因此不适用于动态网络结构和RNN网络。
13. BN,LN,IN,GN的对比
- 主流归一化方法有批归一化化(Batch Normalization,BN)、层次归一化(Layer Normalization,LN)、实例归一化(Instance Normalization,IN)、组归一化(Group Normalization,GN)。
- 深度网络中的数据维度一般是[N, C, H, W] 或 [N, H, W, C],N是Batch Size,H/W是特征图的高/宽,C是特征图的通道数,压缩H/W至一个维度。压缩H/W至一个维度。
- BN:对批次方向做归一化,归一化维度为[N, H, W]。
- LN:在通道方向上做归一化,归一化的维度为[C, H, W],主要对RNN作用比较明显。
- IN:在一个图像像素内做归一化,归一化的维度为[H, W],主要用于风格化迁移。
- GN:将通道方向分组,然后在每一个组内做归一化,先将特征的维度由[N, C, H, W]变换为[N, G, C//G, H, W],归一化的维度为[C//G, H, W]。
还有一种归一化方式,可切摸归一化(Switchable Norm,SN),是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用的方法。
-
MongoDB资料:新手入门完全指南12-24
-
go-zero 框架的 RPC 服务 启动start和停止 底层是怎么实现的?-icode9专业技术文章分享12-20
-
Go-Zero 框架的 RPC 服务启动和停止的基本机制和过程是怎么实现的?-icode9专业技术文章分享12-19
-
怎么在golang中使用gRPC测试mock数据?-icode9专业技术文章分享12-18
-
掌握PageRank算法核心!你离Google优化高手只差一步!12-15
-
GORM 中的标签 gorm:"index"是什么?-icode9专业技术文章分享12-15
-
怎么在 Go 语言中获取 Open vSwitch (OVS) 的桥接信息(Bridge)?-icode9专业技术文章分享12-11
-
怎么用Go 语言的库来与 Open vSwitch 进行交互?-icode9专业技术文章分享12-11
-
怎么在 go-zero 项目中发送阿里云短信?-icode9专业技术文章分享12-11
-
怎么使用阿里云 Go SDK (alibaba-cloud-sdk-go) 发送短信?-icode9专业技术文章分享12-11
-
搭建个人博客网站之一、使用hugo创建个人博客网站12-10
-
MongoDB入门:新手快速上手指南12-04
-
goland 编辑器超过线的插件有哪些?-icode9专业技术文章分享11-29
-
go.mod的文件内容是什么?-icode9专业技术文章分享11-26
-
MongoDB身份认证机制揭秘!11-23
