Go教程
掌握PageRank算法核心!你离Google优化高手只差一步!

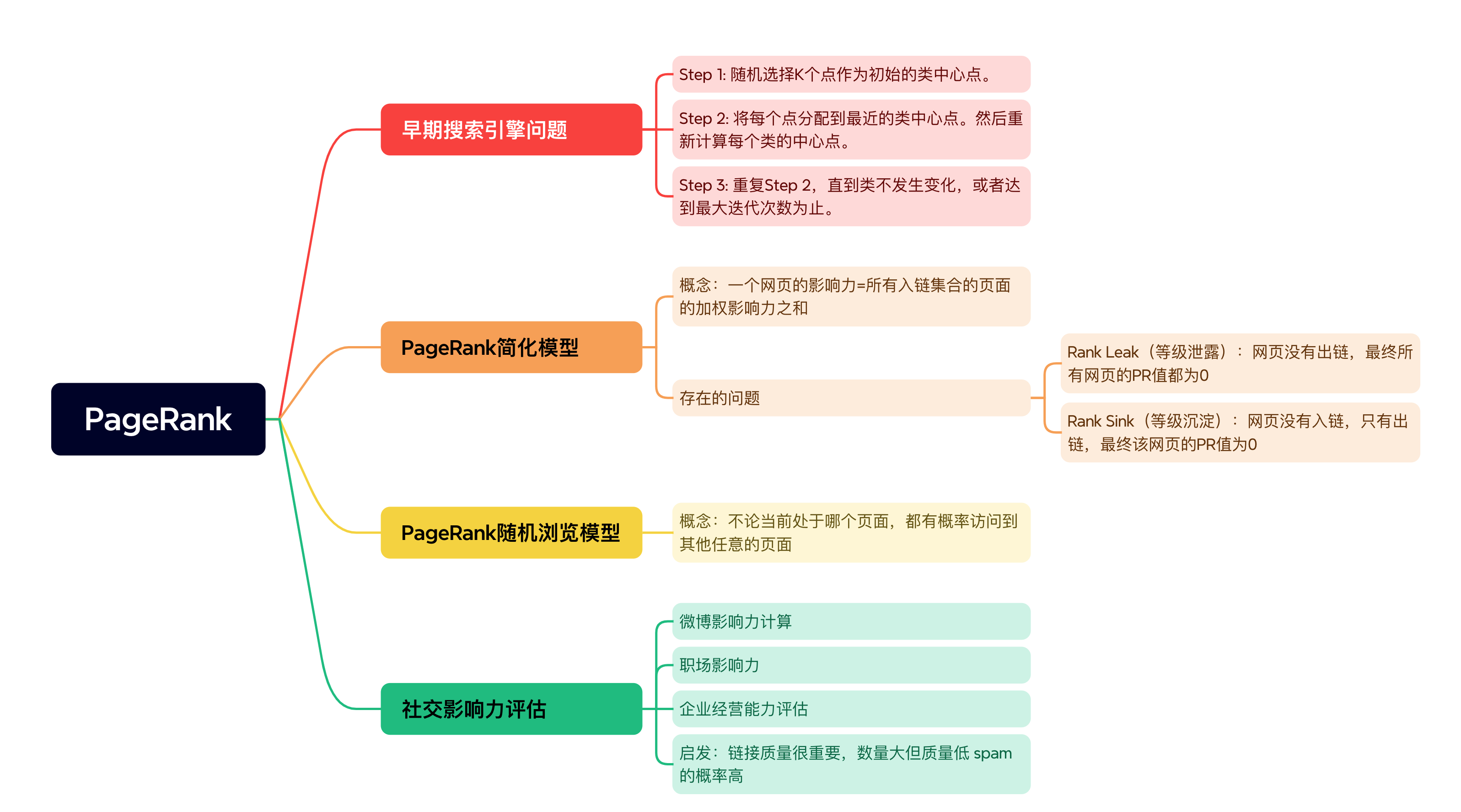
0 前言
98年前的搜索引擎体验不好:
-
返回结果质量不高:搜索结果不考虑网页质量,而通过时间顺序检索
-
易被钻空:搜索引擎基于检索词检索,页面中检索词出现的频次越高,匹配度越高,这样就会出现网页作弊的情况。有些网页为了增加搜索引擎的排名,故意增加某个检索词频率
当时Google拉里·佩奇提出PageRank算法,找到优质网页,这样Google的排序结果不仅能找到用户想要的内容,而且还会从众多网页中筛选出权重高的呈现给用户。
Google的两位创始人都是斯坦福大学的博士生,他们提出PageRank算法受到论文影响力因子的评价启发。当一篇论文被引用的次数越多,证明这篇论文的影响力越大。正是这个想法解决了当时网页检索质量不高的问题。
1 PageRank的简化模型
1.1 PageRank计算过程
4个网页A、B、C、D之间链接信息:

出链:链接出去的链接
入链:链接进来的链接。
图中A有2个入链,3个出链。
一个网页的影响力=所有入链集合的页面的加权影响力之和:
PR(u)=∑v∈BuPR(v)L(v)
PR(u) = \sum_{v \in B_u} \frac{PR(v)}{L(v)}
PR(u)=v∈Bu∑L(v)PR(v)
u为待评估的页面,B_uB\_{u}B_u 为页面u的入链集合。针对入链集合中的任意页面v,它能给u带来的影响力是其自身的影响力PR(v)除以v页面的出链数量,即页面v把影响力PR(v)平均分配给了它的出链,这样统计所有能给u带来链接的页面v,得到的总和就是网页u的影响力,即为PR(u)。
出链会给被链接的页面赋予影响力,统计一个网页链出去的数量,也就是统计这个网页的跳转概率。
例中:
- A有三个出链到B、C、D。用户访问A时,就有跳转到B、C或D可能,跳转概率均1/3
- B有两个出链,链接到了A和D上,跳转概率为1/2
可得A、B、C、D四个网页的转移矩阵M:
M=[01/2101/3001/21/3001/21/31/200]
M =
\begin{bmatrix}
0 & 1/2 & 1 & 0 \\
1/3 & 0 & 0 & 1/2 \\
1/3 & 0 & 0 & 1/2 \\
1/3 & 1/2 & 0 & 0
\end{bmatrix}
M=⎣⎢⎢⎡01/31/31/31/2001/2100001/21/20⎦⎥⎥⎤
设A、B、C、D初始影响力相同:
W0=[1/41/41/41/4]
W_0 = \begin{bmatrix}
1/4 \\
1/4 \\
1/4 \\
1/4
\end{bmatrix}
W0=⎣⎢⎢⎡1/41/41/41/4⎦⎥⎥⎤
第一次转移后,各页面影响力
w1
w_{1}
w1
变为:
$$
W_1 = M W_0 =
\begin{bmatrix}
0 & 1/2 & 1 & 0 \
1/3 & 0 & 0 & 1/2 \
1/3 & 0 & 0 & 1/2 \
1/3 & 1/2 & 0 & 0
\end{bmatrix}
\begin{bmatrix}
1/4 \
1/4 \
1/4 \
1/4
\end{bmatrix}
\begin{bmatrix}
9/24 \
5/24 \
5/24 \
5/24
\end{bmatrix}
KaTeX parse error: Expected 'EOF', got '再' at position 2:
再̲用转移矩阵乘以得到$w\_{2…
w_{n}
$$
影响力不再发生变化,可收敛到(0.3333,0.2222,0.2222,0.2222),即对应A、B、C、D四个页面最终平衡状态下的影响力。
可见A页面相比于其他页面来说权重更大,也就是PR值更高。而B、C、D页面的PR值相等。
至此,模拟了一个简化PageRank计算过程,实际面临
1.2 问题
等级泄露(Rank Leak)
如一个网页没有出链,就像黑洞,吸收其他网页的影响力而不释放,最终导致其他网页PR值为0

对此,可把没有出链的节点,先从图中去掉,等计算完所有节点PR值,再加上该节点计算。但导致新的等级泄露的节点的产生,工作量还是很大。
等级沉没(Rank Sink)
如果一个网页只有出链,没有入链,计算的过程迭代下来,会导致这个网页的PR值为0(也就是不存在公式中的V)。

能否同时解决等级泄露和等级沉没?
2 PageRank的随机浏览模型
拉里·佩奇提出。他假设:用户不都按跳转链接的方式上网,还可能不论当前处啥页面,都有概率访问其他任意页面,如用户就是要直接输入网址访问其他页面,虽概率小。
所以他定义阻尼因子d,代表用户按跳转链接上网的概率,通常可取固定值0.85,而1-d=0.15则代表了用户不是通过跳转链接的方式来访问网页的,比如直接输入网址。
PR(u)=1−dN+d∑v∈BuPR(v)L(v)
PR(u) = \frac{1-d}{N} + d \sum_{v \in B_u} \frac{PR(v)}{L(v)}
PR(u)=N1−d+dv∈Bu∑L(v)PR(v)
其中N为网页总数,这又可重新迭代网页的权重计算,因加入阻尼因子d,一定程度解决等级泄露和等级沉没。
PageRank随机浏览模型可收敛,即可得一个稳定正常PR值。
3 PageRank在社交影响力评估中的应用
网页之间形成网络-互联网,论文之间也存在相互引用,我们所处环境就是各种网络集。有网络,就有出入链,就有PR权重计算,就可用PageRank。如微博,计算某人影响力。
一个人的微博粉丝数不一定等于其实际影响力。如按PageRank,还要看粉丝质量。如果有很多明星或大V关注,这人影响力一定高。僵尸粉即使再多,影响力不高。
工作场景如脉脉,计算个人在职场的影响力。如果你的工作关系是李开复、江南春,职场影响力一定很高。反之,你是学生,在职场上被链入的关系较少,职场影响力就低。
看一个公司经营能力,也可看这家公司都和啥公司合作。如合作都是世界500强,在行业内一定领导者,客户都是小客户,即使数量多,业内影响力也不一定大。
除非像淘宝,海量中小客户,最后大客户也会上门合作。所以权重高的节点,往往有一些权重同样很高的节点在合作。
4 PageRank启发
算是Google搜索引擎重要的技术之一,在1998年帮助Google获得了搜索引擎的领先优势,现在PageRank已经比原来复杂很多,但思想依然带给启发,如想:
- 自媒体影响力提高,尽量混在大V圈
- 找高职位工作,尽量结识公司高层或认识更多猎头,因为猎头和很多高职位的人员都有链接。
也可帮我们识别链接农场。链接农场指网页为链接而链接,填充一些无用内容。这些页面相互链接或指向某网页,从而想得到更高权重。
5 总结
本文讨论了PageRank算法原理,对简化PageRank模型模拟。针对简化模型中存在的等级泄露和等级沉没这两个问题,PageRank的随机浏览模型引入了阻尼因子d解决。
同样,PageRank有很广的应用领域,在许多网络结构中都有应用,如计算个人微博影响力。社交网络中,链接质量很重要。
本文已收录在Github,关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都架构师,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
- 中央/分销预订系统性能优化
- 活动&券等营销中台建设
- 交易平台及数据中台等架构和开发设计
- 车联网核心平台-物联网连接平台、大数据平台架构设计及优化
- LLM Agent应用开发
- 区块链应用开发
- 大数据开发挖掘经验
- 推荐系统项目
目前主攻市级软件项目设计、构建服务全社会的应用系统。
参考:
- 编程严选网
-
go-zero 框架的 RPC 服务 启动start和停止 底层是怎么实现的?-icode9专业技术文章分享12-20
-
Go-Zero 框架的 RPC 服务启动和停止的基本机制和过程是怎么实现的?-icode9专业技术文章分享12-19
-
怎么在golang中使用gRPC测试mock数据?-icode9专业技术文章分享12-18
-
GORM 中的标签 gorm:"index"是什么?-icode9专业技术文章分享12-15
-
怎么在 Go 语言中获取 Open vSwitch (OVS) 的桥接信息(Bridge)?-icode9专业技术文章分享12-11
-
怎么用Go 语言的库来与 Open vSwitch 进行交互?-icode9专业技术文章分享12-11
-
怎么在 go-zero 项目中发送阿里云短信?-icode9专业技术文章分享12-11
-
怎么使用阿里云 Go SDK (alibaba-cloud-sdk-go) 发送短信?-icode9专业技术文章分享12-11
-
搭建个人博客网站之一、使用hugo创建个人博客网站12-10
-
MongoDB入门:新手快速上手指南12-04
-
goland 编辑器超过线的插件有哪些?-icode9专业技术文章分享11-29
-
go.mod的文件内容是什么?-icode9专业技术文章分享11-26
-
MongoDB身份认证机制揭秘!11-23
-
MongoDB教程:从入门到实践详解11-20
-
执行 Google Ads API 查询后返回的是空数组什么原因?-icode9专业技术文章分享11-17
