Java教程
Triple 协议支持 Java 异常回传的设计与实现

作者:Apache Dubbo Contributor 陈景明
背景
在一些业务场景, 往往需要自定义异常来满足特定的业务, 主流用法是在catch里抛出异常, 例如:
public void deal() {
try{
//doSomething
...
} catch(IGreeterException e) {
...
throw e;
}
}
或者通过ExceptionBuilder,把相关的异常对象返回给consumer:
provider.send(new ExceptionBuilders.IGreeterExceptionBuilder()
.setDescription('异常描述信息');
在抛出异常后, 通过捕获和instanceof来判断特定的异常, 然后做相应的业务处理,例如:
try {
greeterProxy.echo(REQUEST_MSG);
} catch (IGreeterException e) {
//做相应的处理
...
}
在 Dubbo 2.x 版本,可以通过上述方法来捕获 Provider 端的异常。而随着云原生时代的到来, Dubbo 也开启了 3.0 的里程碑。
Dubbo 3.0 的一个很重要的目标就是全面拥抱云原生,在 3.0 的许多特性中,很重要的一个改动就是支持新的一代Rpc协议Triple。
Triple 协议基于 HTTP 2.0 进行构建,对网关的穿透性强,兼容 gRPC,提供 Request Response、Request Streaming、Response Streaming、Bi-directional Streaming 等通信模型;从 Triple 协议开始,Dubbo 还支持基于 IDL 的服务定义。
采用 Triple 协议的用户可以在 provider 端生成用户定义的异常信息,记录异常产生的堆栈,triple 协议可保证将用户在客户端获取到异常的message。
Triple 的回传异常会在 AbstractInvoker 的 waitForResultIfSync中把异常信息堆栈统一封装成 RpcException,所有来自 Provider 端的异常都会被封装成 RpcException 类型并抛出,这会导致用户无法根据特定的异常类型捕获来自 Provider 的异常,只能通过捕获 RpcException 异常来返回信息,且 Provider 携带的异常 message 也无法回传,只能获取打印的堆栈信息:
try {
greeterProxy.echo(REQUEST_MSG);
} catch (RpcException e) {
e.printStackTrace();
}
自定义异常信息在社区中的呼声也比较高,因此本次改动将支持自定义异常的功能, 使得服务端能抛出自定义异常后被客户端捕获到。
Dubbo异常处理简介
我们从Consumer的角度看一下一次Triple协议 Unary请求的大致流程:
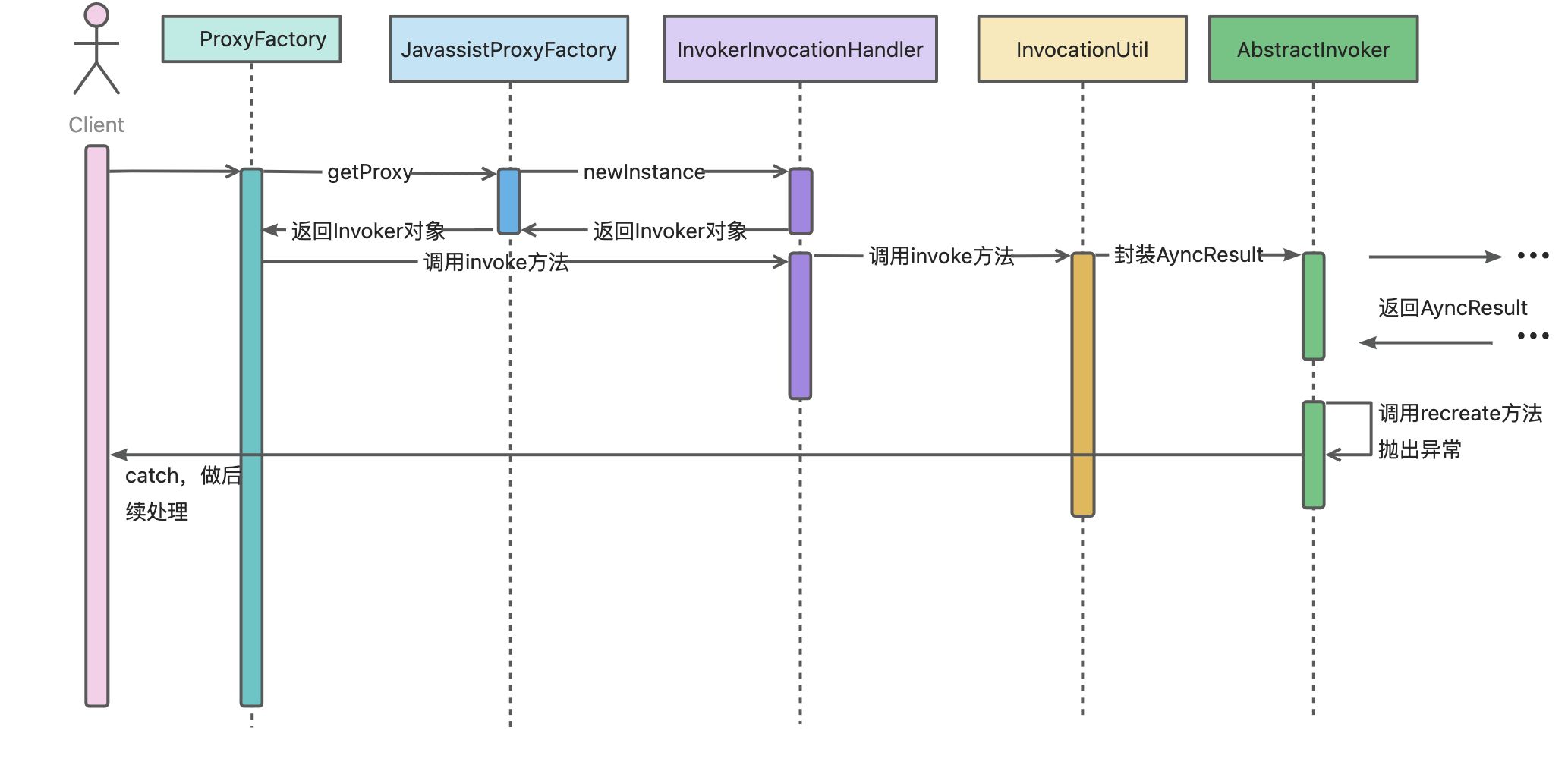
Dubbo Consumer 从 Spring 容器中获取 bean 时获取到的是一个代理接口,在调用接口的方法时会通过代理类远程调用接口并返回结果。
Dubbo提供的代理工厂类是 ProxyFactory,通过 SPI 机制默认实现的是 JavassistProxyFactory,JavassistProxyFactory 创建了一个继承自 AbstractProxyInvoker 类的匿名对象,并重写了抽象方法 doInvoke。重写后的 doInvoke 只是将调用请求转发给了 Wrapper 类的 invokeMethod 方法,并生成 invokeMethod 方法代码和其他一些方法代码。
代码生成完毕后,通过 Javassist 生成 Class 对象,最后再通过反射创建 Wrapper 实例,随后通过 InvokerInvocationHandler -> InvocationUtil -> AbstractInvoker -> 具体实现类发送请求到Provider端。
Provider 进行相应的业务处理后返回相应的结果给 Consumer 端,来自 Provider 端的结果会被封装成 AsyncResult ,在 AbstractInvoker 的具体实现类里,接受到来自 Provider 的响应之后会调用 appResponse 到 recreate 方法,若 appResponse 里包含异常,
则会抛出给用户,大体流程如下:
上述的异常处理相关环节是在 Consumer 端,在 Provider 端则是由org.apache.dubbo.rpc.filter.ExceptionFilter 进行处理,它是一系列责任链 Filter 中的一环,专门用来处理异常。
Dubbo 在 Provider 端的异常会在封装进 appResponse 中。下面的流程图揭示了 ExceptionFilter 源码的异常处理流程:
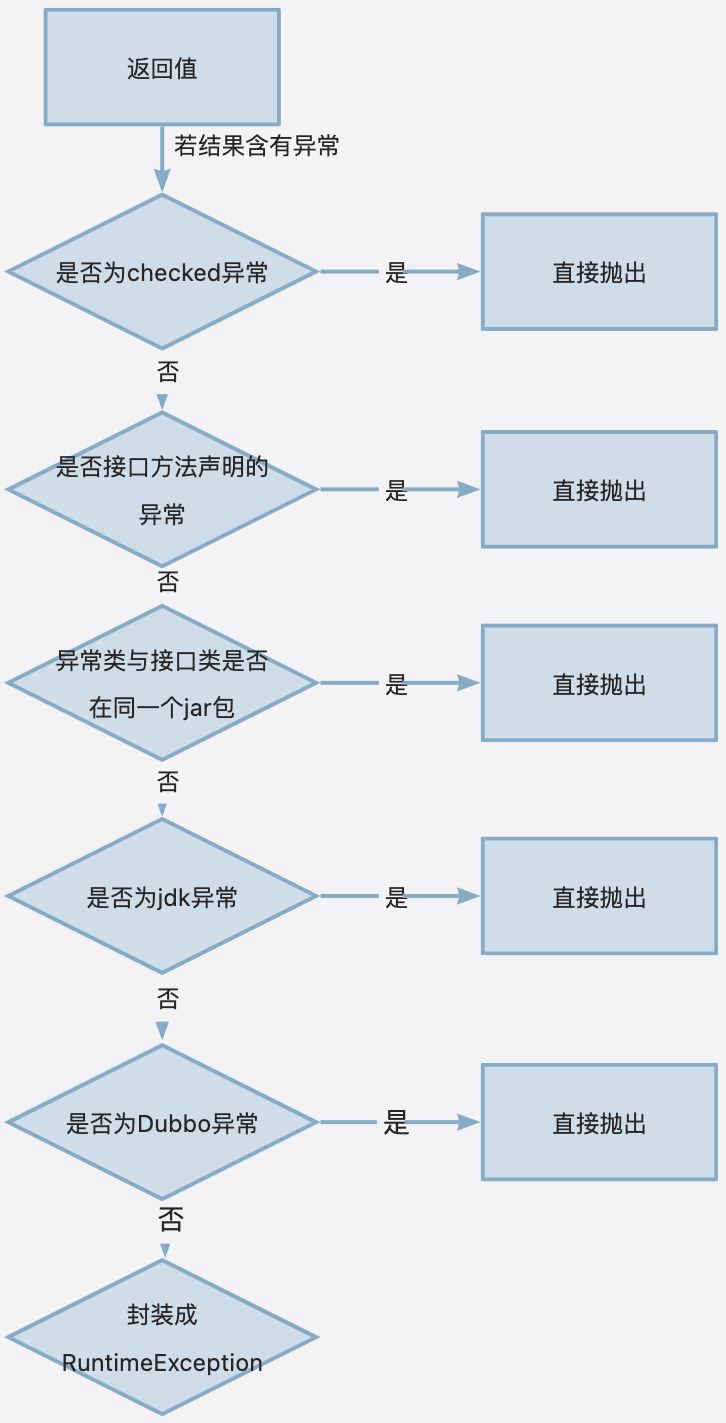
而当 appResponse 回到了 Consumer 端,会在 InvocationUtil 里调用 AppResponse 的 recreate 方法抛出异常,
最终可以在 Consumer 端捕获:
public Object recreate() throws Throwable {
if (exception != null) {
try {
Object stackTrace = exception.getStackTrace();
if (stackTrace == null) {
exception.setStackTrace(new StackTraceElement[0]);
}
} catch (Exception e) {
// ignore
}
throw exception;
}
return result;
}
Triple 通信原理
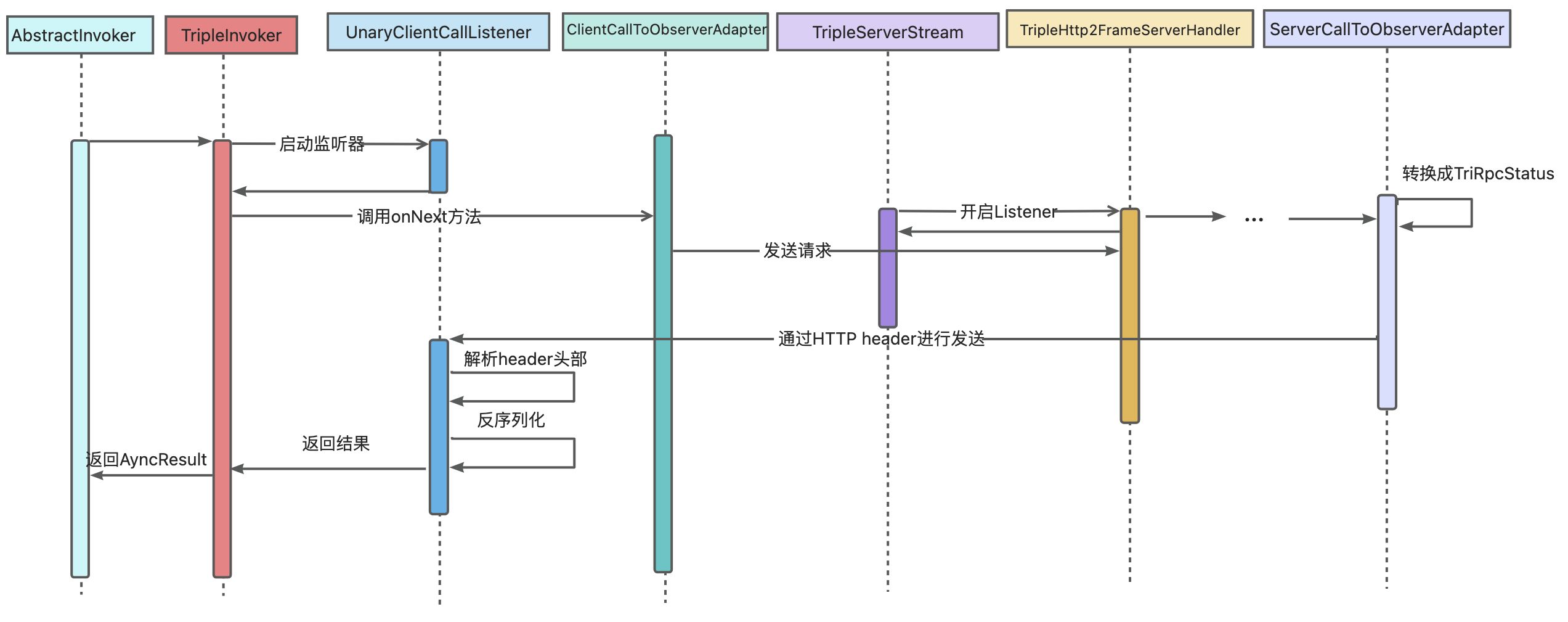
在上一节中,我们已经介绍了 Dubbo 在 Consumer 端大致发送数据的流程,可以看到最终依靠的是 AbstractInvoker 的实现类来发送数据。在 Triple 协议中,AbstractInvoker 的具体实现类是 TripleInvoker ,TripleInvoker 在发送前会启动监听器,监听来自 Provider 端的响应结果,并调用 ClientCallToObserverAdapter 的 onNext 方法发送消息,最终会在底层封装成 Netty 请求发送数据。
在正式的请求发起前,TripleServer 会注册 TripleHttp2FrameServerHandler,它继承自 Netty 的 ChannelDuplexHandler,其作用是会在 channelRead 方法中不断读取 Header 和 Data 信息并解析,经过层层调用,会在 AbstractServerCall 的 onMessage 方法里把来自 consumer 的信息流进行反序列化,并最终由交由 ServerCallToObserverAdapter 的 invoke 方法进行处理。
在 invoke 方法中,根据 consumer 请求的数据调用服务端相应的方法,并异步等待结果;若服务端抛出异常,则调用 onError 方法进行处理,否则,调用 onReturn 方法返回正常的结果,大致代码逻辑如下:
public void invoke() {
...
try {
//调用invoke方法请求服务
final Result response = invoker.invoke(invocation);
//异步等待结果
response.whenCompleteWithContext((r, t) -> {
//若异常不为空
if (t != null) {
//调用方法过程出现异常,调用onError方法处理
responseObserver.onError(t);
return;
}
if (response.hasException()) {
//调用onReturn方法处理业务异常
onReturn(response.getException());
return;
}
...
//正常返回结果
onReturn(r.getValue());
});
}
...
}
大体流程如下:
实现版本
了解了上述原理,我们就可以进行相应的改造了,能让 consumer 端捕获异常的关键在于把异常对象以及异常信息序列化后再发送给consumer端。常见的序列化协议很多,例如 Dubbo/HSF 默认的 hessian2 序列化;还有使用广泛的 JSON 序列化;以及 gRPC 原生支持的 protobuf(PB) 序列化等等。Triple协议因为兼容grpc的原因,默认采用 Protobuf 进行序列化。上述提到的这三种典型的序列化方案作用类似,但在实现和开发中略有不同。PB 不可由序列化后的字节流直接生成内存对象,而 Hessian 和 JSON 都是可以的。后两者反序列化的过程不依赖“二方包”,其序列化和反序列化的代码由 proto 文件相同,只要客户端和服务端用相同的 proto 文件进行通信,就可以构造出通信双方可解析的结构。
单一的 protobuf 无法序列化异常信息,因此我们采用 Wrapper + PB 的形式进行序列化异常信息,抽象出一个 TripleExceptionWrapperUtils 用于序列化异常,并在 trailer 中采用 TripleExceptionWrapperUtils 序列化异常,大致代码流程如下:
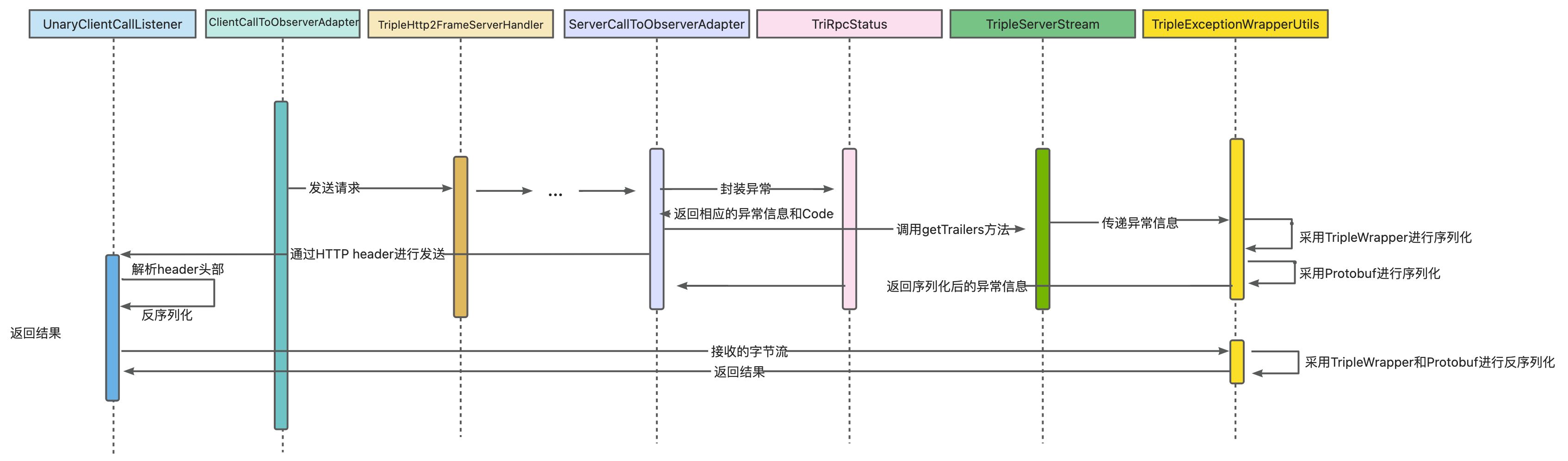
上面的实现方案看似非常合理,已经能把 Provider 端的异常对象和信息回传,并在 Consumer 端进行捕获。但仔细想想还是有问题的:通常在 HTTP2 为基础的通信协议里会对 header 大小做一定的限制,太大的header size 会导致性能退化严重,为了保证性能,往往以 HTTP2 为基础的协议在建立连接的时候是要协商最大 header size 的,超过后会发送失败。对于 Triple 协议来说,在设计之初就是基于 HTTP 2.0,能无缝兼容 Grpc,而 Grpc header 头部只有 8KB 大小,异常对象大小可能超过限制,从而丢失异常信息;且多一个 header 携带序列化的异常信息意味着用户能加的 header 数量会减少,挤占了其他 header 所能占用的空间。
经过讨论,考虑将异常信息放置在 Body,将序列化后的异常从 trailer 挪至 body,采用 TripleWrapper + protobuf 进行序列化,把相关的异常信息序列化后回传。
社区围绕这个问题进行了一系列的争论,读者也可尝试先思考一下:
1.在 body 中携带回传的异常信息,其对应HTTP header状态码该设置为多少?
2.基于 http2 构建的协议,按照主流的 grpc 实现方案,相关的错误信息放在 trailer,理论上不存在body,上层协议也需要保持语义一致性,若此时在payload回传异常对象,且grpc并没有支持在Body回传序列化对象的功能, 会不会破坏Http和grpc协议的语义?从这个角度出发,异常信息更应该放在trailer里。
3.作为开源社区,不能一味满足用户的需求,非标准化的用法注定是会被淘汰的,应该尽量避免更改 Protobuf的语义,是否在Wrapper层去支持序列化异常就能满足需求?
首先回答第二、三个问题:HTTP 协议并没有约定在状态码非 2xx 的时候不能返回 body,返回之后是否读取取决于用户。grpc 采用protobuf进行序列化,所以无法返回 exception;且try catch机制为java独有,其他语言并没有对应的需求,但Grpc暂时不支持的功能并一定是unimplemented,Dubbo的设计目标之一是希望能和主流协议甚至架构进行对齐,但对于用户合理的需求也希望能进行一定程度的修改。且从throw本身的语义出发,throw 的数据不只是一个 error message,序列化的异常信息带有业务属性,根据这个角度,更不应该采用类似trailer的设计。至于单一的Wrapper层,也没办法和grpc进行互通。至于Http header状态码设置为200,因为其返回的异常信息已经带有一定的业务属性,不再是单纯的error,这个设计也与grpc保持一致,未来考虑网关采集可以增加新的triple-status。
更改后的版本只需在异常不为空时返回相关的异常信息,采用 TripleWrapper + Protobuf 进行序列化异常信息,并在consumer端进行解析和反序列化,大体流程如下:
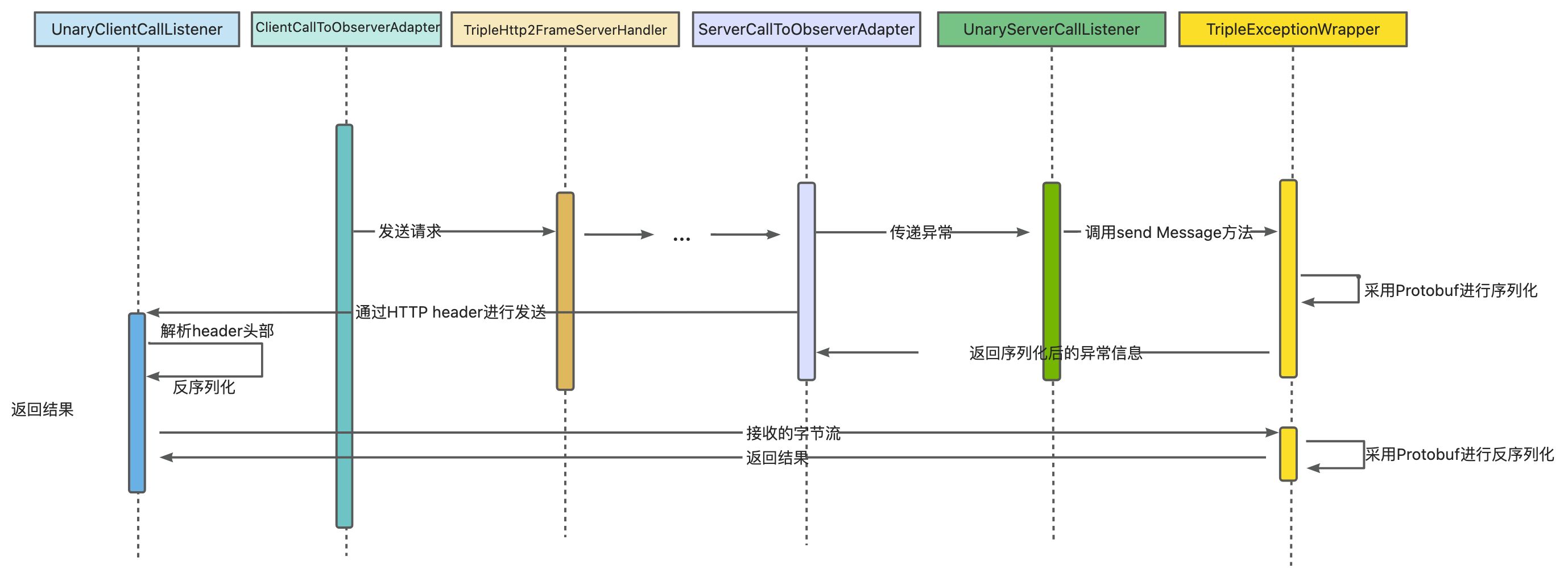
总结
通过对 Dubbo 3.0 新增自定义异常的版本迭代中可以看出,尽管只能新增一个小小的特性,流程下并不复杂,但由于要考虑互通、兼容和协议的设计理念,因此思考和讨论的时间可能比写代码的时间更多。
-
OpenFeign服务间调用学习入门12-27
-
OpenFeign服务间调用学习入门12-27
-
OpenFeign学习入门:轻松掌握微服务通信12-27
-
OpenFeign学习入门:轻松掌握微服务间的HTTP请求12-27
-
JDK17新特性学习入门:简洁教程带你轻松上手12-27
-
JMeter传递token学习入门教程12-27
-
JMeter压测学习入门指南12-27
-
JWT单点登录学习入门指南12-27
-
JWT单点登录原理学习入门12-27
-
JWT单点登录原理学习入门12-27
-
JWT解决方案学习入门:新手必读教程12-27
-
JWT解决方案学习入门:新手必读教程12-27
-
Mybatis持久层框架学习入门12-27
-
史上最全性能调优秘籍:让你的系统飞起来!12-27
-
Mybatis二级缓存学习入门详解12-27
