Java教程
如何配置 SLO

前言
无论是对外提供 IaaS PaaS SaaS 的云公司,还是提供信息技术服务的乙方公司,亦或是金融 制造等各行各业的数据中心、运维部门,我们的一个非常重要的合同承诺或考核评估指标就是:SLA(即:Service-Level Agreement 服务等级协议)。
而真正落地实现 SLA 的精确测量,最广为人知的就是 Google 的 SRE 理论。
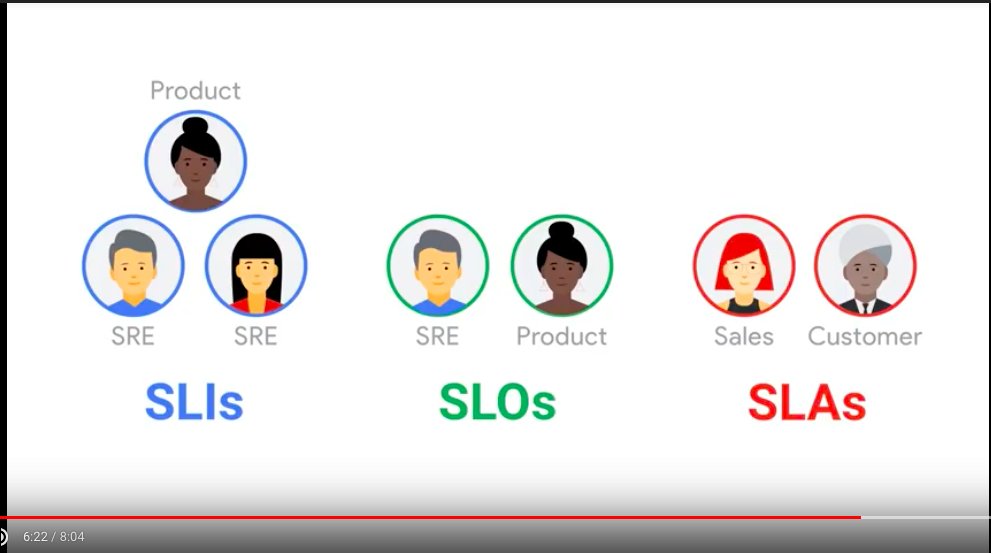
Google SRE SLO & SLA
在 Google,会明确区分 SLO 和服务等级协议 (SLA)。SLA 通常涉及向服务用户承诺,即服务可用性 SLO 应在特定时间段内达到特定级别。如果不这样做,就会导致某种惩罚。这可能是客户为该期间支付的服务订阅费的部分退款,或者免费添加的额外订阅时间。SLO 不达标会伤害到服务团队,因此他们将努力留在 SLO 内。如果您要向客户收取费用,则可能需要 SLA。
SLA 中的可用性 SLO 通常比内部可用性 SLO 更宽松。这可以用可用性数字表示:例如,一个月内可用性 SLO 为 99.9%,内部可用性 SLO 为 99.95%。或者,SLA 可能仅指定构成内部 SLO 的指标的子集。
如果 SLA 中的 SLO 与内部 SLO 不同(几乎总是如此),则监控必须显式测量 SLO 达标情况。您希望能够查看系统在 SLA 日程期间的可用性,并快速查看它是否似乎有脱离 SLO 的危险。
您还需要对合规性进行精确测量,通常来自 Metrics、Tracing、Logging 分析。由于我们对付费客户有一组额外的义务(如 SLA 中所述),因此我们需要将从他们那里收到的查询与其他查询分开进行度量。这是建立 SLA 的另一个好处 — 这是确定流量优先级的明确方法。
定义 SLA 的可用性 SLO 时,请注意将哪些查询视为合法查询。例如,如果客户因为发布了其移动客户端的错误版本而超出配额,则可以考虑从 SLA 中排除所有"超出配额"的响应代码。
SLI
SLI 是经过仔细定义的测量指标,它根据不同系统特点确定要测量什么。
常见的 SLI 有:
- 性能
- 响应时间 (latency)
- 吞吐量 (throughput)
- 请求量 (qps)
- 实效性 (freshness)
- 可用性
- 运行时间 (uptime)
- 故障时间/频率
- 可靠性
- 质量
- 准确性 (accuracy)
- 正确性 (correctness)
- 完整性 (completeness)
- 覆盖率 (coverage)
- 相关性 (relevance)
- 内部指标
- 队列长度 (queue length)
- 内存占用 (RAM usage)
- 因素人
- 响应时间 (time to response)
- 修复时间 (time to fix)
- 修复率 (fraction fixed)
SLO
**SLO(服务等级目标)**指定了服务所提供功能的一种期望状态,服务提供者用它来指定系统的预期状态。SLO 里不会提到,如果目标达不到会怎么样。
SLO 是用 SLI 来描述的,一般描述为:
比如以下SLO:
- 每分钟平均 qps > 100 k/s
- 99% 访问延迟 < 500ms
- 99% 每分钟带宽 > 200MB/s
设置 SLO 时的目标依赖于系统的不同状态(conditions),根据不同状态设置不同的SLO:
总 SLO = service1.SLO1 weight1 + service2.SLO2 weight2 + …
为什么要有 SLO,设置 SLO 的好处是什么呢?
- 对于客户而言,是可预期的服务质量,可以简化客户端的系统设计
- 对于服务提供者而言
- 可预期的服务质量
- 更好的取舍成本/收益
- 更好的风险控制(当资源受限的时候)
- 故障时更快的反应,采取正确措施
SLA
SLA = SLO + 后果
小结
- SLI:服务等级指标,经过仔细定义的测量指标
- SLO:服务等级目标,
总 SLO = service1.SLO1 weight1 + service2.SLO2 weight2 + … - SLA: 服务等级协议,
SLA = SLO + 后果
如何配置 SLO
公有云常见 SLO
常见于通过 处理请求的服务或 API 提供的服务(如:对象存储 或 API 网关)
- 错误率 (error rate) 计算的是服务返回给用户的 error 总数
- 如果错误率大于X%(如 0.5%),就算是服务 down了,开始计算 downtime
- 如果错误率持续超过 Y (如 5)分钟,这个downtime就会被计算在内
- 间断性的小于 Y 分钟的downtime是不被计算在内的。
前端 Web 或 APP
前端用户体验 Apdex 目标
如果有前端 js 探针监控,或拨测监控,那么可以用前端用户体验 Apdex 作为 SLO。
Apdex 定义了一个性能标准,将应用程序用户分为三个组:
- 满意、
- 可容忍(一般)
- 沮丧(不满意)。
例如,作为前端应用程序的 SLO,您可以指定希望 90% 的用户 Apdex 都是 满意 。
如,My WebApp Apdex 公式如下:
100% * (apps.web.actionCount.category:filter(eq(Apdex category,SATISFIED)):splitBy("My WebApp")) / (apps.web.actionCount.category:splitBy("My WebApp"))
前端 APP 无崩溃(Crash)用户率目标
衡量手机 App (iOS 和 Android) 的可用性和可靠性的最重要指标之一是 无崩溃用户率。指的是没有崩溃的情况下打开并使用移动 APP 的用户百分比。
因此,公式示例如下:
apps.other.crashFreeUsersRate.os:splitBy("My mobile app")
拨测可用性目标
拨测可用性 SLO 表示拨测处于可用状态下的时间百分比,或者,成功拨测占执行的总测试数的百分比。
因此,公式示例为:
(synthetic.browser.availability.location.total:splitBy("My WebApp"))
后端应用 或 Service
基本的 SLO - 调用成功率目标
成功率 = 成功的请求调用次数 / 总的请求调用次数
如:My service 的 成功率:
100% * (service.requestCount.successCount:splitBy("My service"))/(service.requestCount.totalCount:splitBy("My service"))
那么,如果 My service 的关键 API 或请求需要计量,就可能是下面的公式:
(100%)*(service.keyRequest.successCount:splitBy(type("SERVICE_API") AND entityId("POST /login")))/(service.keyRequest.totalCount:splitBy(type("SERVICE_API") AND entityId("POST /login")))
ℹ️ 提示:
成功的请求最简单的一种方式是:http 状态码为 2xx 或 3xx 的请求即视为成功。
还有一种,请求执行过程中没有抛出错误(日志或异常)的请求视为成功。
服务性能目标
重点在于性能。
服务性能 SLO 表示 「fast」 服务调用占服务调用总数的百分比,其中 「fast」使用自定义条件定义。例如:
- fast:0 - 3s 内完成服务调用()
- normal:3 - 5s 内完成服务调用
- slow:5s 以上完成服务调用或超时
ℹ️ 提示:
当然,上边的 3s 也不应该是拍脑袋想的,而应该是例如基于过去一个月系统正常运行时 99% 百分位数的响应时间。
公式示例为:
(service:fastRequests:splitBy("My WebApp")) / (service:totalRequests:splitBy("My WebApp"))
后端数据库
数据库可用性或读可用性目标
错误率:是在给定的一小时间隔内,DB 的失败 SQL 执行次数除以总 SQL 执行次数。
读错误率:是在给定的一小时间隔内,DB 的失败查询 SQL 执行次数除以总 SQL 执行次数。
公式示例为:
可用性 % = 100% - Average DB Error Rate
或:
读可用性 % = 100% - Average DB Read Error Rate
吞吐量目标
-
吞吐量失败的请求:是指请求尚未超过给定 DB 吞吐量,却被 DB 吞吐量限制,导致错误码
-
吞吐量错误率:是在给定的一小时间隔内,给定 DB 的吞吐量失败请求总数除以总请求数。
那么,公式示例为:
吞吐量目标% = 100% -平均吞吐量错误率
一致性目标
SLI 为:
一致性违规率:是指在给定的 DB 中,在给定的一小时间隔内,对所选的一致性级别(按总请求数划分)执行一致性保证时无法发送的成功请求。
延迟目标
- P99 延迟:计算出的一段时间内的测试 SQL (如
select 1 from dual) 执行时间的 99% 百分位响应时间。 - 延迟时间和:是指在应用程序提交的 SQL 成功请求导致 P99 延迟大于或等于 10ms 的一个小时间隔的总数。
那么,示例公式为:
延迟目标% = 100% - 总的延迟时间和的次数 / (DB 总使用时间/1H)
如:过去 1 个月,总的延迟时间和的次数为 50 次,分母为:30 * 24 / 1 = 720
那么:延迟目标% = 100% - 50 / 720 ≈ 93%
MQ 类
消息成功率目标
就是成功的消息除以 MQ 接收的总消息。
公式示例为:
(100)*((mq.rabbitmq.queue.requests.successful:splitBy("payment"))/mq.rabbitmq.queue.requests.incoming:splitBy("payment")))
Host 类
UPTIME 目标
例如,每小时正常运行时间百分比 = 100% - 单个 Host 实例处于不可用状态的总时间(没有超过多长时间才算不可用一说)百分比
不可用的定义可以是:
- 该 Host 实例没有网络连接
- 该 Host 实例 无法执行读写 IO,且 IO 在队列中挂起。即 IO hang。
K8S 类
K8S 类是一类综合系统,需要考虑如下目标
- API Server 成功率目标
- 计算目标
- 存储目标
- 网络目标
- …
存储类
可用性(Availability)目标
大致也是类似上边的可用性目标。
数据持久性(Durability)目标
这个通常非常高,比如:99.999999999%
可以简单粗暴认为:只要有数据丢失的情况,就是没达到目标。
典型案例就是腾讯的那次。
网络类
可用性目标
以 NAT 网关为例:
单实例服务不可用分钟数: 当某一分钟内,NAT 网关实例出方向所有数据包都被 NAT 网关丢弃时,则视为该分钟内该 NAT 网关实例服务不可用。在一个服务周期内 NAT 网关实例不可用分钟数之和即服务不可用分钟数。
总结
可以根据不同的层次、组件设定不同的 SLO。
SLO 的监测是需要监控工具的支持。
常用的 SLO 包括:
- 可用性(Availability)目标
- 成功率(Success Rate)目标
- 延迟 (Latency) 目标
- 运行时间 (Uptime) 目标
- 数据持久性(Durability)目标
EOF
三人行, 必有我师; 知识共享, 天下为公. 本文由东风微鸣技术博客 EWhisper.cn 编写.
-
cursor试用出现:Too many free trial accounts used on this machine 的解决方法01-11
-
百万架构师第十四课:源码分析:Spring 源码分析:深入分析IOC那些鲜为人知的细节|JavaGuide01-11
-
不得不了解的高效AI办公工具API01-11
-
2025 蛇年,J 人直播带货内容审核团队必备的办公软件有哪 6 款?01-10
-
高效运营背后的支柱:文档管理优化指南01-10
-
年末压力山大?试试优化你的文档管理01-10
-
跨部门协作中的进度追踪重要性解析01-10
-
总结 JavaScript 中的变体函数调用方式01-10
-
HR团队如何通过数据驱动提升管理效率?6个策略01-10
-
WBS实战指南:如何一步步构建高效项目管理框架?01-10
-
实现精准执行:团队协作新方法01-10
-
如何使用工具提升活动策划团队的工作效率?几个必备工具推荐01-10
-
WiX 标签使用介绍:打造专业安装程序的利器01-10
-
服装跨境电商SOP模板:优化运营效率的实战指南01-10
-
单行键盘:用 Java 解决键盘输入时间问题01-10
