TensorFlow教程
C++与深度学习1——如何用C++读取训练好的tensorflow模型权重参数(超级详细!)

近年来,深度学习模型的落地愈发重要。本文以在边缘设备部署深度学习网络为目标,讲述如何用C++从hdf5格式的keras模型文件中读取到权重参数。
一、环境
win11
visual studio 2022
二、在vs中配置hdf5的环境
配置过程可以参考
https://blog.csdn.net/yx123919804/article/details/103767979
写的非常详细,我按照这个配置的可以用。
三、hdf5模型文件分析
我们可以通过HDF5的官网了解到很多信息。HDF5数据模型,也称为HDF5抽象(或逻辑)数据模型,其两个主要object是groups和datasets。
3.1 groups
每个GHD5文件都包含一个root group,这个group可以包含其它的group。HDF5的group结构类似于树,以下图为例,root group下包含两个group:Viz和SimOut,Viz 组下是与 SimOut 组共享的各种图像和表格。 SimOut 组包含一个 3 维数组、一个 2 维数组和另一个 HDF5 文件中一个 2 维数组的链接。使用group和group member在许多方面类似于在 UNIX 中使用目录和文件。与 UNIX 目录和文件一样,HDF5 文件中的对象通常通过给出它们的完整(或绝对)路径名来描述。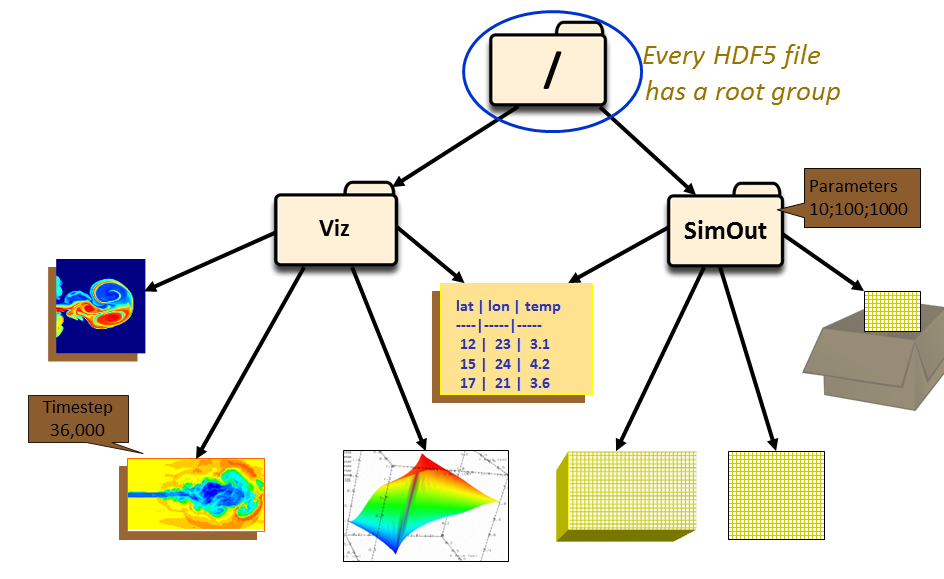
3.2 datasets
每一个dataset包含两部分的数据,Metadata和Data。其中Metadata包含Data相关的信息,而Data则包含数据本身。不过这些都不重要,想要详细了解的朋友可以移步这里。
最直观来看,我们可以下载hdfview将HDF5模型直观化显示如下:模型文件名为pool_model1_10carrier_tf2_channel1.h5,蓝色框中的部分即为group,红色框即为dataset,我们要的权重数据其实就在dataset里面。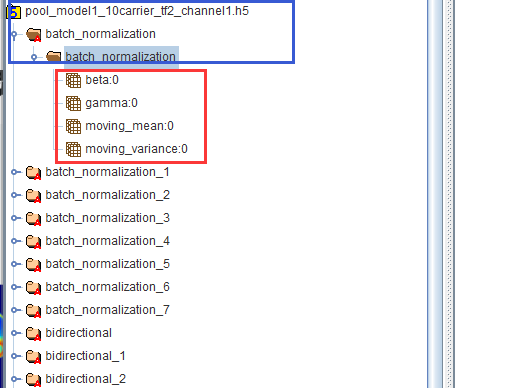
3.3 HDF5库函数的使用
我们最关心的是如果使用HDF5库函数读取keras模型的参数,一般来说,处理HDF5对象的流程是:
- 打开对象
- 访问对象
- 关闭对象
关于hdf5库函数如何使用,可以参考这个网址:
https://portal.hdfgroup.org/display/HDF5/Examples+in+the+Source+Code
在网页的案例中,我们找到C++部分,由于本文只需要读取hdf5文件,因此我们可以参考红框中圈出的cpp文件。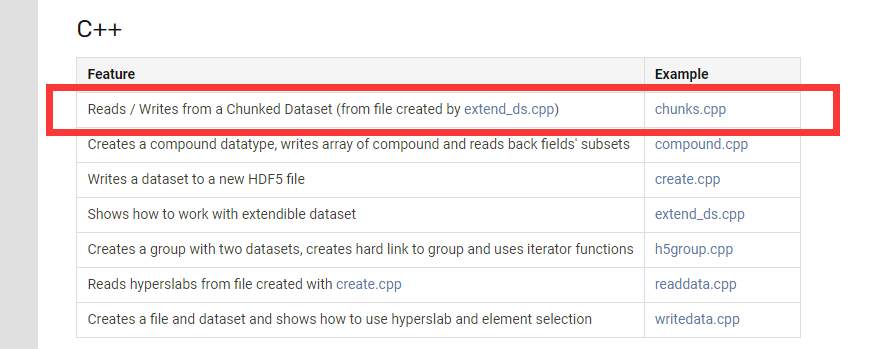
四、有关HDF5库的一些使用方法
这里主要参考了这一篇博客,当然也可以去官网查看每个函数的用法,不过直接看别人的博客可以让我们快速把hdf5库函数用起来。
1、添加工程所需的头文件和库文件
#include <stdint.h> #include <hdf5.h> #include <H5Cpp.h> #include <iostream> using namespace H5; using namespace std; #ifdef _DEBUG #pragma comment(lib, "hdf5_D.lib") #pragma comment(lib, "hdf5_cpp_D.lib") #else #pragma comment(lib, "hdf5.lib") #pragma comment(lib, "hdf5_cpp.lib") #endif /* 来自博客:https://blog.csdn.net/yx123919804/article/details/103772079?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166123206116782246444170%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=166123206116782246444170&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~pc_rank_34-1-103772079-null-null.142^v42^pc_rank_34,185^v2^control&utm_term=C%2B%2B%E8%AF%BB%E5%8F%96hdf5%E6%A8%A1%E5%9E%8B&spm=1018.2226.3001.4187 */
2、打开文件
// 用只读方式打开文件, 用完后记得要调用 file.close() 关闭释放资源
H5File file("文件路径, 你需要自己修改, 文件名包括.扩展名", H5F_ACC_RDONLY);
3、如何查看某个group中的内容
// Opens an object within a group or a file, i.e., root group. hid_t getObjId(const char* name, const PropList& plist = PropList::DEFAULT) const; hid_t getObjId(const H5std_string& name, const PropList& plist = PropList::DEFAULT) const;
H5File类中的 getObjId函数能够获取指定group下的内容并返回句柄,接下来我们可以利用该句柄定义group类对象,借助group类来对指定的group下的内容进行操作。
// 用只读方式打开文件, 用完后记得要调用 file.close() 关闭释放资源
H5File file("文件路径, 你需要自己修改, 文件名包括.扩展名", H5F_ACC_RDONLY);
// 打开 Root Group, 用完后记得要调用 rg.close() 关闭释放资源
Group rg(file.getObjId("/"));
// 取得 Group 中 Object 的数量
const hsize_t objs = rg.getNumObjs();
for (hsize_t i = 0; i < objs; i++)
{
// 用 Index 为参数获取 Object 名字
const H5std_string name = rg.getObjnameByIdx(i);
cout << "Obj_name_" << i + 1 << ": " << name.c_str() << endl;
}
rg.close();
file.close();
cout << endl << endl;
system("pause");
/*
这段代码参考博客:https://blog.csdn.net/yx123919804/article/details/103772079
*/
上面的代码能够获取模型中神经网络各层的名称如下,和hdfview看到的结果是一致的。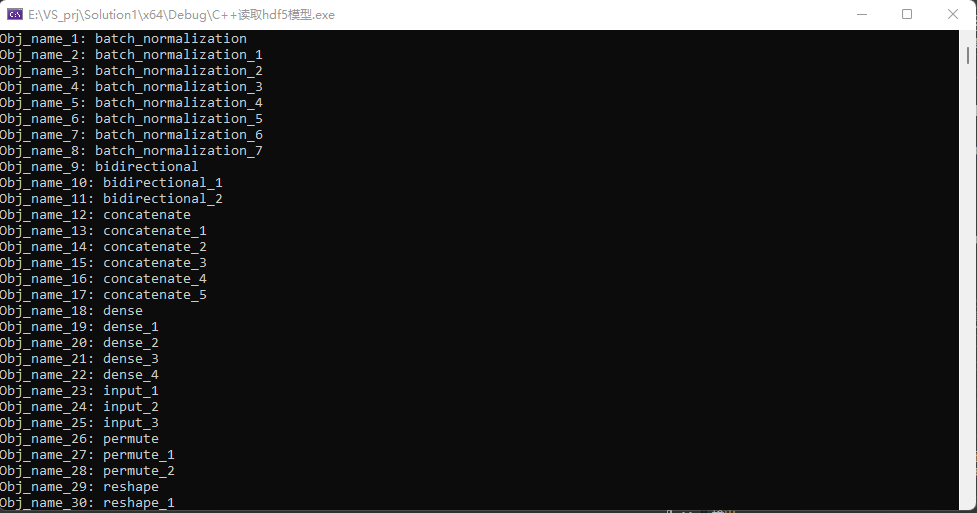
4、读取指定dataset中的数据
//打开文件和指定的数据集
H5File file("pool_model1_10carrier_tf2_channel1.h5", H5F_ACC_RDONLY);
DataSet dset(rg.getObjId("/batch_normalization/batch_normalization/beta:0"));
//获取指定数据集的文件空间,方便后续获取其维度
DataSpace filespace = dataset.getSpace();
//获取其维度
int rank = filespace.getSimpleExtentNdims();
//获取每一维度的大小,并用数组存储
hsize_t* dims = new hsize_t[rank];
const int ndims = dsp.getSimpleExtentDims(dims);
// 输出各维度的大小
for (int i = 0; i < rank; i++){
cout << "Dimension_" << i + 1 << " = " << dims[i] << endl;
}
delete[]dims;
dims = nullptr;
//获取dataset的数据类型
DataType dt = dset.getDataType();
const H5T_class_t t = dt.getClass();
//利用数组存储当前dataset
const hsize_t data_size = dset.getInMemDataSize() / sizeof(float);
float* buf = new float[data_size];
// 读出数据到 buf 中
dset.read(buf, dt);
for (int i = 0; i < data_size; i++){
cout << buf[i] << endl;
}
delete[]buf;
buf = nullptr;
dt.close();
dsp.close();
dset.close();
rg.close();
file.close();
cout << endl << endl;
/*
这段代码参考博客:https://blog.csdn.net/yx123919804/article/details/103772079
*/
五、程序编写
5.1 实现的功能
由于前面我们完成了利用HDF5函数库读取指定dataset中的数据,接下来我们对函数进行封装,实现一次性存储我们需要的所有layer的权重数据。
函数实现的功能:
输入:想要读取的网络层名,这里用vector储存
输出:读取到的权重数据。这里考虑到不同的layer其包含的参数名称也不一样,例如bn层有beta、gamma、moving_mean、moving_variance这些参数,dense层含有bias、kernel这些参数,因此采用unordered_map<string, vector>的形式,用键值对的方式存储。不管是什么层,统一存放在vector中,后续根据层的名称再对参数进行划分取用。
5.2 函数的编写
我们整理一下代码思路:
1、打开hdf5模型
2、遍历我们指定的layer名称,获取其objectID,判断该object是group还是dataset,若为object则到3,若为dataset则到4。
3、继续往深层遍历直到dataset
4、从dataset读取数据存入vector,回到2直到指定的layer全部遍历完
但其实通过hdfview查看hdf模型我们可以看到,root group下包含所有以layer名称命名的group,但是这些group下还会有其它group,这也为我们找到dataset带来了麻烦。从下图中,我们发现bidirectional层下的dataset比较麻烦,需要同时保存lstm_cell_2和lstm_cell_1下的dataset。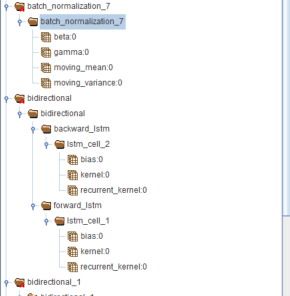
不过我们也可以发现,hdf5模型的结构和树类似,根节点即为root group,根节点的子节点即为以layer名称命名的group。我们将从layer名称命名的group开始单独划分出一个子树,其实读取权重参数的过程就是读取叶子节点的过程,示意图如下,可以采用层序遍历的方式读取dataset。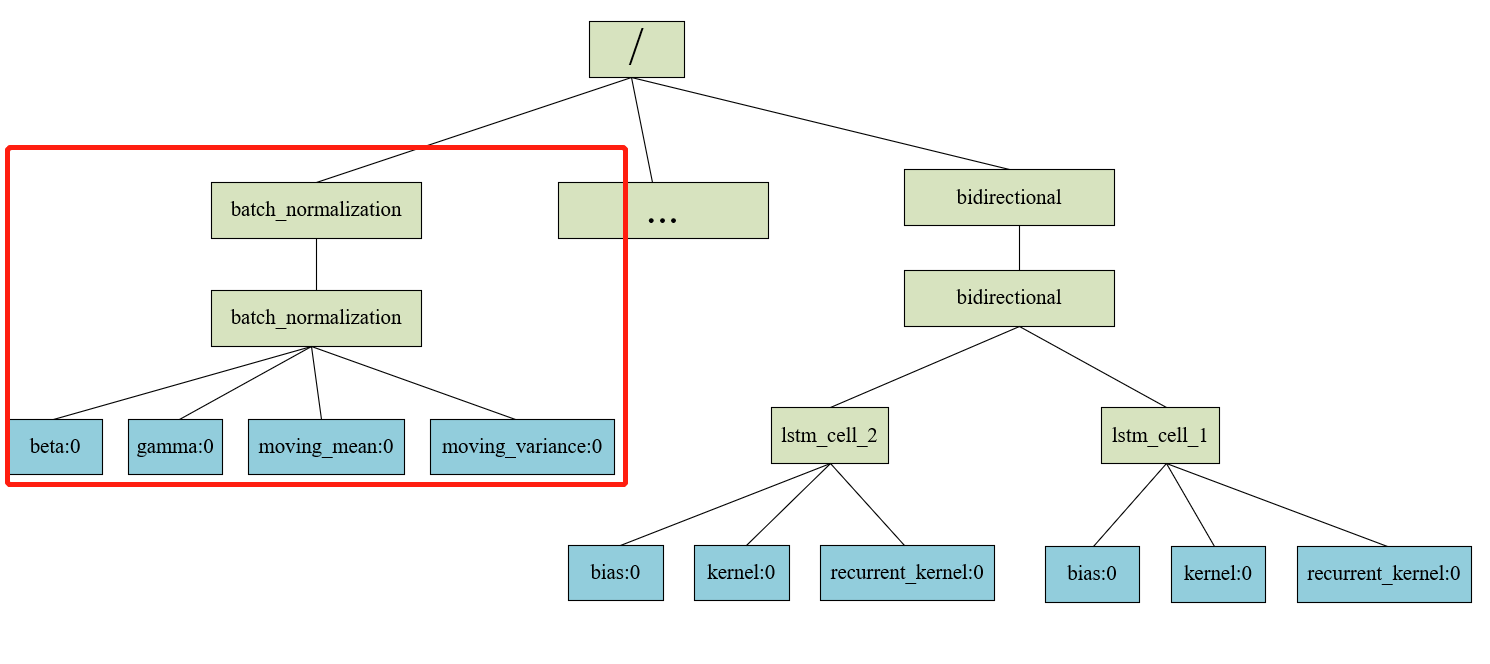
5.3 代码
现在就可以敲击代码了
/*
功能:获取指定层的权重参数
参数:
filename 读取的hdf5文件
layers_name 指定的layer名称列表
model_data 读取的layer权重参数
*/
bool GetLayerWeights(const string& filename, vector<string>& layers_name, unordered_map<string, vector<float>>& model_data) {
// 用只读方式打开文件, 用完后记得要调用 file.close() 关闭释放资源
H5File file(filename, H5F_ACC_RDONLY);
//遍历所有的layer
for (int i = 0; i < layers_name.size(); i++) {
//拼接指定的object路径
string group_string = "";
group_string = "/" + layers_name[i];
hid_t root_id = file.getObjId(group_string);//相当于每个layer分支的根节点
//层序遍历读取参数
GetFloorWeights_QUEUE(layers_name[i], group_string, file, root_id, model_data);
}
file.close();
return true;
}
//层序遍历得到叶子节点(dataset)
void GetFloorWeights_QUEUE(const string& layer_name, const string& root_str, const H5File& file, const hid_t& root_id, unordered_map<string, vector<float>>& model_data) {
queue<pair<hid_t,string>> que; //为了方便后续操作,这里将objectID以及其路径一起存储在队列中
que.push({root_id,root_str});
while (!que.empty()) {
int que_size = que.size();
for (int i = 0; i < que_size; i++) {
pair<hid_t, string> cur_node = que.front();
hid_t cur_id = cur_node.first;
string cur_str = cur_node.second;
que.pop();
H5I_type_t obj_type = H5Iget_type(cur_id);
//如果是group,就把其下所有的内容都入队列
if (obj_type == H5I_GROUP) {
//获取该group下object的数量
Group rg(cur_id);
const hsize_t objs = rg.getNumObjs();
//将group下的所有object全部入队列
for (hsize_t j = 0; j < objs; j++) {
const H5std_string name = rg.getObjnameByIdx(j);
string tmp_str = cur_str + "/" + name;
hid_t tmp_id = file.getObjId(tmp_str);
que.push({ tmp_id, tmp_str});
}
rg.close();
}
//如果是dataset,说明到达了叶子节点,把dataset写入model_data即可
if (obj_type == H5I_DATASET) {
//打开对应的dataset
string dataset_name = cur_str;
DataSet dset = file.openDataSet(dataset_name);
// 获取Dataset中数据的数据类型
DataType dt = dset.getDataType();
const H5T_class_t t = dt.getClass();
//判定读取的数据类型为float(目前只写了float的逻辑,需要支持多数据类型的话,后续可以直接用函数模板解决)
if (t == H5T_FLOAT) {
// 数据在内存中的字节数除以数据类型得到 buf 的大小
const hsize_t data_size = dset.getInMemDataSize() / sizeof(float);
float* buf = new float[data_size];
// 读出数据到 buf 中
dset.read(buf, dt);
cout<< dataset_name <<":" << endl;
for (int k = 0; k < data_size; k++)
{
cout << buf[k] << endl;
model_data[layer_name].push_back(buf[k]);
}
delete[]buf;
buf = nullptr;
}
dt.close();
dset.close();
}
}
}
return;
}
六、下一节内容
下一节内容就是设计各种layer的类存储我们读取到的权重参数,用于后续的前向推理过程。
-
tensorflow是什么-icode9专业技术文章分享10-30
-
成功地使用本地的 NVIDIA GPU 运行 PyTorch 或 TensorFlow10-15
-
供应链投毒预警 | 恶意Py包仿冒tensorflow AI框架实施后门投毒攻击01-23
-
attributeerror: module 'tensorflow' has no attribute 'placeholder'01-19
-
module 'tensorflow.compat.v2' has no attribute 'internal'01-19
-
【2023年】第33天 Neural Networks and Deep Learning with TensorFlow07-17
-
【2023年】第32天 Boosted Trees with TensorFlow 2.0(随机森林)07-10
-
【2023年】第31天 Logistic Regression with TensorFlow 2.0(用TensorFlow进行逻辑回归)07-09
-
【2023年】第30天 Supervised Learning with TensorFlow 2(用TensorFlow进行监督学习 2)07-01
-
【2023年】第29天 Supervised Learning with TensorFlow 1(用TensorFlow进行监督学习 1)06-18
-
【2023年】第28天 tensorflow的介绍06-17
-
如何在 Windows10 下运行 Tensorflow 的目标检测?05-16
-
关于Tensorflow!目标检测预训练模型的迁移学习05-16
-
我通过 tensorflow 预测了博客的粉丝数05-14
-
从零开始配置深度学习环境:CUDA+Anaconda+Pytorch+TensorFlow04-14
