Java教程
TiFlash 源码阅读(四)TiFlash DDL 模块设计及实现分析

TiFlash 是 TiDB 的分析引擎,是 TiDB HTAP 形态的关键组件。TiFlash 源码阅读系列文章将从源码层面介绍 TiFlash 的内部实现。在上一期源码阅读中,我们介绍了 TiFlash 的存储引擎,本文将介绍 TiFlash DDL 模块的相关内容,包括 DDL 模块的设计思路, 以及具体代码实现的方式。
本文基于写作时最新的 TiFlash v6.1.0 设计及源码进行分析。随着时间推移,新版本中部分设计可能会发生变更,使得本文部分内容失效,请读者注意甄别。TiFlash v6.1.0 的代码可在 TiFlash 的 git repo 中切换到 v6.1.0 tag 进行查看。
Overview
本章节,我们会先对 DDL 模块做一个 overview 的介绍,介绍 DDL 在 TiFlash 中相关的场景,以及 TiFlash 中 DDL 模块整体的设计思想。
这边的 DDL 模块指的是对应负责处理 add column, drop column, drop table recover table 等这一系列 DDL 语句的模块,也是负责跟各数据库和表的 schema 信息打交道的模块。
DDL 模块在 TiFlash 中的相关场景
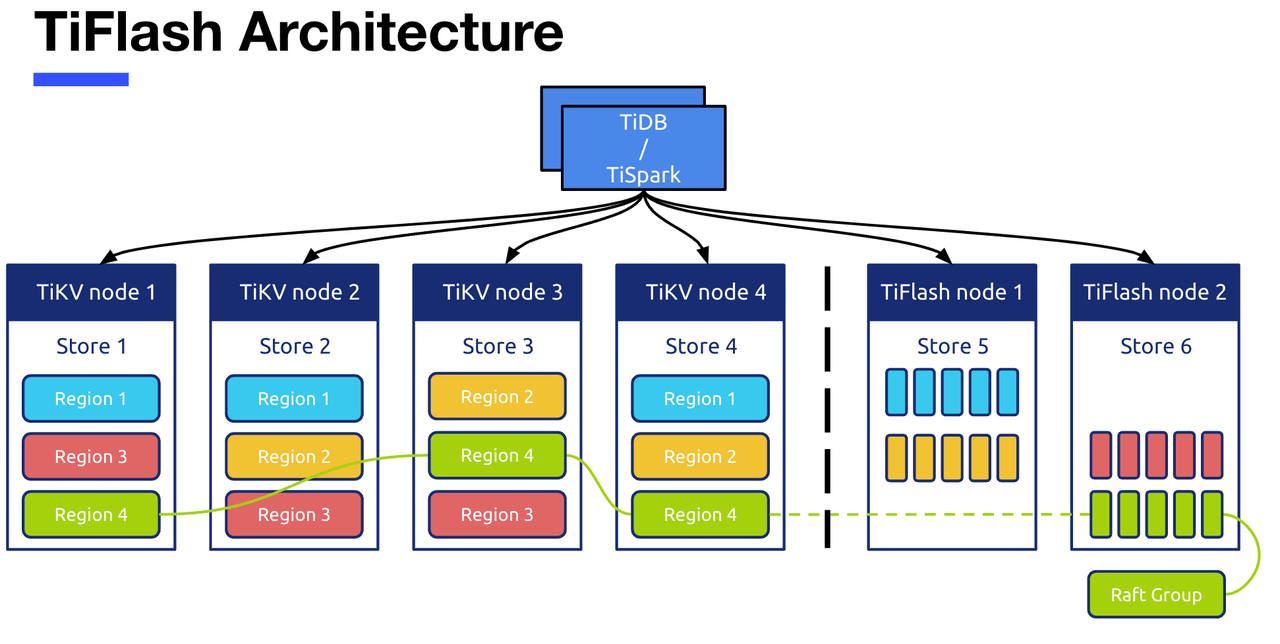
图一 是 TiFlash 的架构示意图,上方是 TiDB/TiSpark 的计算层节点,虚线的左边是四个 TiKV 的节点,右边就是两个 TiFlash 节点。这张图体现的是TiFlash 一个重要的设计理念:通过利用 Raft 的共识算法,TiFlash 会作为 Raft 的 Learner 节点加入 Raft group 来进行数据的异步复制。Raft Group 指的是 TiKV 中由多个 region 副本组成的 raft leader 以及 raft follower 组成的 group。从 TiKV 同步到 TiFlash 的数据,在 TiFlash 中同样是按照 region 划分的,但是在内部会通过列存的方式来存到 TiFlash 的列式存储引擎中。
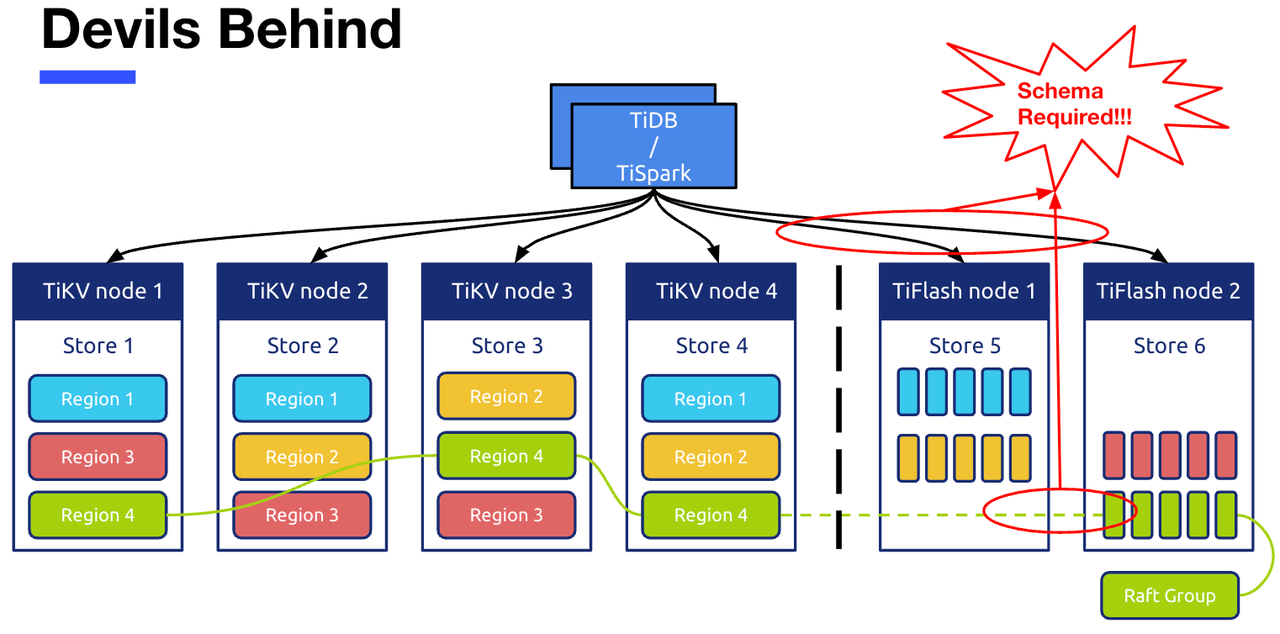
图二是一个概览的架构设计,掩盖了许多细节部分。其中图中这两个红圈对应的部分,就是本文要讨论的主角 DDL模块。
下方的红圈是关于 TiFlash 的写操作。TiFlash 节点是以 learner 角色加入到了 TiKV 中一个个 region 对应的 raft group 中,通过 raft leader 不断发送 raft log 或者 raft snapshot 来给 learner 节点同步数据。 但是因为 TiKV 中数据都是行存的格式,而我们 TiFlash 中需要的数据则是列存的格式,所以 TiFlash 节点在接收到 TiKV 发送过来的这个行存格式的数据以后,需要把他进行一个行转列的转换,转换成需要的列存的格式。而这个转换,就需要依赖对应表的 schema 信息来完成。同样,上方的红圈指的是在 TiDB/TiSpark 来 TiFlash 中读取数据的过程,这个读数据的过程同样也是依赖 schema 来进行参与解析的。因此,TiFlash 的读写操作都是需要强依赖 schema 的,schema 在 TiFlash 中亦是有重要的作用的。
DDL 模块整体设计思想
在具体了解 TiFlash DDL 模块的整体设计思想之前,我们先来了解一下 DDL 模块在 TiDB 和 TiKV 中的对应情况,因为 TiFlash 接收到的 schema 的变更信息亦是从 TiKV 节点发送的。
TiDB 中 DDL 模块基本情况
TiDB 的 DDL 模块是借鉴 Google F1 来实现的在分布式场景下,无锁并且在线的 schema 变更。具体的实现可以参考 TiDB 源码阅读系列文章(十七)DDL 源码解析 | PingCAP。TiDB 的 DDL 机制提供了两大特点:
-
DDL 操作会尽可能避免发生 data reorg(data reorg 指的是在表中进行数据的增删改)。
- 图三这个 add column 的例子里面,原表有 a b 两列以及两行数据。当我们进行 add column 这个 DDL 操作时,我们不会在原有两行中给新增的 c 列填上默认值。如果后续有读操作会读到这两行的数据,我们则会在读的结果中给 c 列填上默认值。通过这样的方式,我们来避免在 DDL 操作的时候发生 data reorg。诸如 add column, drop column,以及整数类型的扩列操作,都不需要触发 data reorg 的。

-
但是对于有损变更的 DDL 操作(例如:缩短列长度(后续简称缩列)的操作,可能会导致用户数据截断的 DDL变更),我们不可避免会发生 data reorg。但是在有损变更的场景下,我们也不会在表的原始列上进行数据修改重写的操作,而是通过新增列,在新增列上进行转换,最后删除原列,对新增列更名的方式来完成 DDL 操作。图四这个缩列 (modify column) 的例子中,我们原表中有 a, b 两列 ,此次 DDL 操作需要把 a 列从 int 类型缩成 tiny int 类型。整个 DDL 操作的过程为:
- 先新增一列隐藏列 _col_a_0。
- 把原始 a 列中的数值进行转换写到隐藏列 _col_a_0 上。
- 转换完成后,将原始的 a 列删除,并且将 _col_a_0 列重命名为 a 列。(这边提到的删除 a 列也并非物理上把 a 列的数值删除,是通过修改 meta 信息的方式来实现的)*
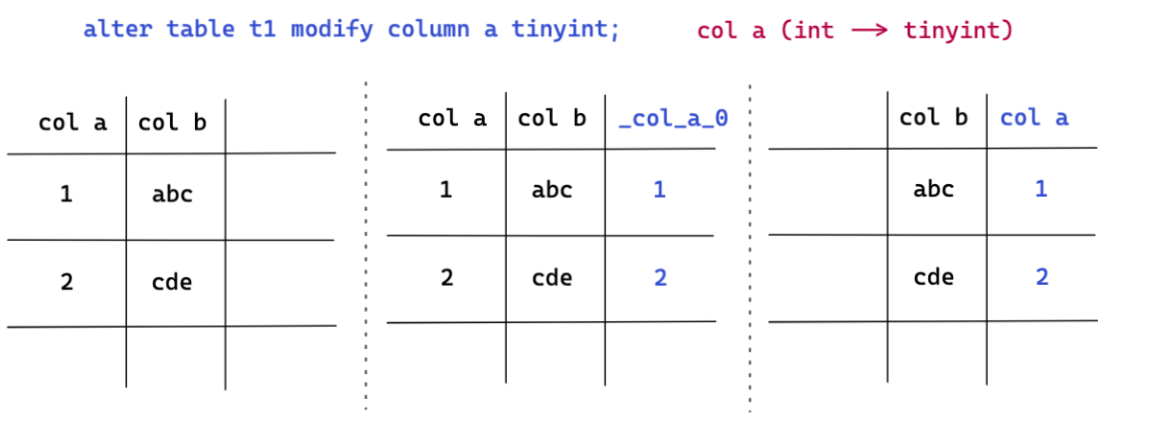
另外对于缩列这个 DDL 操作本身,我们要求缩列过程中不会发生数据的丢失。比如要从 int 缩成 tinyint时,就要求原有列的值都是在 tinyint 范围内的,而不支持出现本身超出 tinyint 的值转换成 tinyint 类型。对于后者的情况,会直接报错 overflow,缩列操作失败。
-
相对数据更新的 schema 永远可以解析旧的数据。这一条结论亦是我们后面 TiFlash DDL 模块依赖的一条重要的保证。这个保证是依赖我们行存数据的格式来实现的。在存数据的时候,我们是将column id 和 column value 一起存储的,而非column name和column value一起存储。另外我们的行存格式可以简化的理解为是一个 column_id → data 的一个 map 方式(实际上我们的行存并非一个 map,而是用二进制编码的方式来存储的,具体可以参考 Proposal: A new storage row format for efficient decoding)。
- 我们可以通过图五这个例子,来更好的理解一下这条特性。左边是一个两列的原表,通过 DDL 操作,我们删除了 a 列,新增了 c 列,转换为右边的 schema 状态。这时,我们需要用新的 schema 信息去解析原有的老数据,根据新 schema 中的每个 column id,我们去老数据中找到每个 column id 对应的值,其中 id_2 可以找到对应的值,但 id_3 并没有找到对应的值,因此,就给 id_3 补上该列的默认值。而对于数据中多个 id_1 对应的值, 就选择直接舍弃。通过这样的方式,我们就正确的解析了原来的数据。

TiKV 中 DDL 模块基本情况
TiKV 这个行存的存储层,本身是没有在节点中保存各个数据表对应的 schema 信息的,因为 TiKV 本身的读写过程都不需要依赖自身提供的 schema 信息。
- TiKV 的写操作本身是不需要 shcema ,因为写入 TiKV 的数据是上层已经完成转换的行存的格式的数据(也就是 kv 中的 v)。
- 对于 TiKV 的读操作
- 如果读操作只需要直接把 kv 读出,则也不需要 schema 信息。
- 如果是需要在 TiKV 中的 coprocesser 上处理一些 TiDB 下发给 TiKV 承担的下推计算任务的时候,TiKV 会需要 schema 的信息。但是这个 schema 信息,会在 TiDB 发送来的请求中包含,所以 TiKV 可以是直接拿 TiDB 发送的请求中的 schema 信息来进行数据的解析,以及做一些异常处理(如果解析失败的话)。因此 TiKV 这一类读操作也不会需要自身提供 schema 相关的信息。
TiFlash 中 DDL 模块设计思想
TiFlash 中 DDL 模块的设计思想主要包含了以下三点:
- TiFlash 节点上会保存自己的 schema copy。一部分是因为 TiFlash 对 schema 具有强依赖性,需要 schema 来帮助解析行转列的数据以及需要读取的数据。另一方面也因为 TiFlash 是基于 Clickhouse 实现的,所以很多设计也是在 Clickhouse 原有的设计上进行演进的,Clickhouse 本身设计中就是保持了一份 schema copy。
- 对于 TiFlash 节点上保存的 schema copy,我们选择通过定期从 TiKV 中拉取最新的 schema(本质其实是拿到 TiDB 中最新的 schema 信息)来进行更新,因为不断持续地更新 schema 的开销是非常大的,所以我们是选择了定期更新。
- 读写操作,会依赖节点上的 schema copy 来进行解析。如果节点上的 schema copy 不满足当下读写的需求,我们会去拉最新的schema信息,来保证schema 比数据新,这样就可以正确成功解析了(这个就是前面提到的 TiDB DDL 机制提供的保证)。具体读写时对 schema copy 的需求,会在后面的部分具体给大家介绍。
DDL Core Process
本章节中,我们将介绍 TiFlash DDL 模块核心的工作流程。
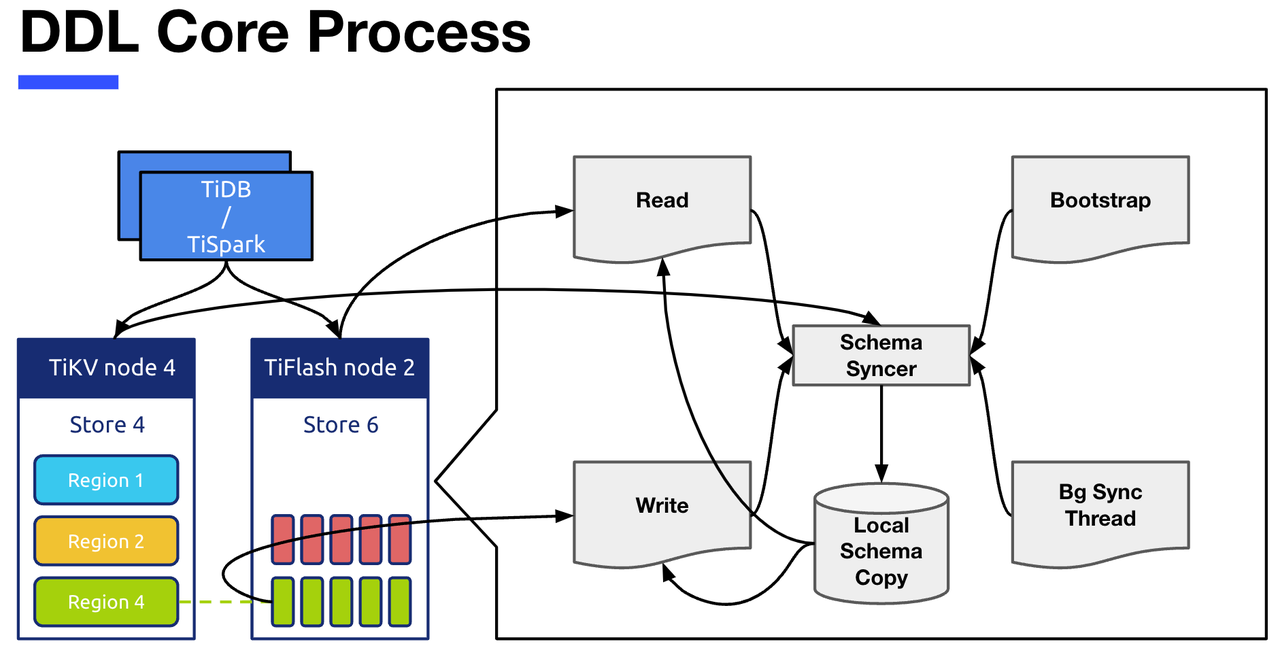
图六左边是各个节点的一个缩略展示,右边放大显示了TiFlash 中跟 DDL 相关的核心流程,分别为:
- Local Schema Copy 指的是 TiFlash 节点上存的 schema copy 的信息。
- Schema Syncer 模块负责从 TiKV 拉取 最新的 Schema 信息,依此来更新 Local Schema Copy。
- Bootstrap 指的是 TiFlash Server 启动的时候,会直接调用一次 Schema Syncer,获得目前所有的 schema 信息。
- Background Sync Thread 是负责定期调用 Schema Syncer 来更新 Local Schema Copy 模块。
- Read 和 Write 两个模块就是 TiFlash 中的读写操作,读写操作都会去依赖 Local Schema Copy,也会在有需要的时候来调用 Schema Syncer 进行更新。
下面我们就逐一来看每个部分是怎么实现的。
Local Schema Copy
TiFlash 中 schema 信息最主要的是跟各个数据表相关的信息。在 TiFlash 的存储层中,每一个物理的表,都会对应一个 StorageDeltaMerge 的实例对象,在这个对象中有两个变量,是负责来存储跟schema 相关的信息的。
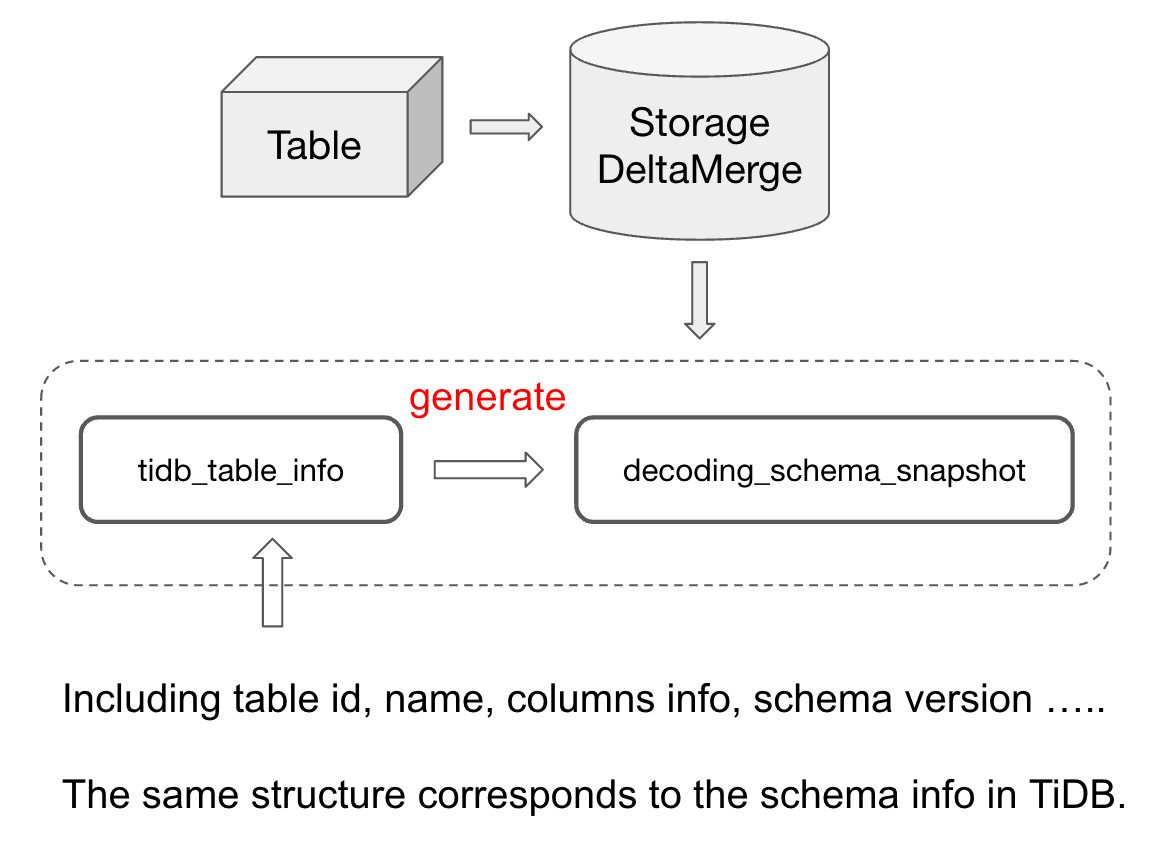
tidb_table_info这个变量存的是 table 中各种 schema 信息,包括 table id,table name,columns infos,schema version等等。并且tidb_table_info的存储结构跟 TiDB / TiKV 中存储 table schema 的结构是完全一致的。decoding_schema_snapshot则是根据tidb_table_info以及StorageDeltaMerge中的一些信息生成的一个对象。decoding_schema_snapshot是为了优化写入过程中行转列的性能而提出的。因为我们在做行转列转换的时候,如果依赖tidb_table_info获取对应需要的 schema 信息,需要做一系列的转换操作来进行适配。考虑到 schema 本身也不会频繁更新,为了避免每次行转列解析都需要重复做这些操作,我们就用decoding_schema_snapshot这个变量来保存转换好的结果,并且在行转列过程中依赖decoding_schema_snapshot来进行解析。
Schema Syncer
Schema Syncer 这个模块是由 TiDBSchemaSyncer 这个类来负责的。它通过 RPC 去 TiKV 中获取最新的 schema 的更新内容。对于获取到的 schema diffs,会找到每个 schema diff 对应的 table,在 table 对应的 StorageDeltaMerge 对象中来更新 schema 信息以及对应存储层相关的内容。
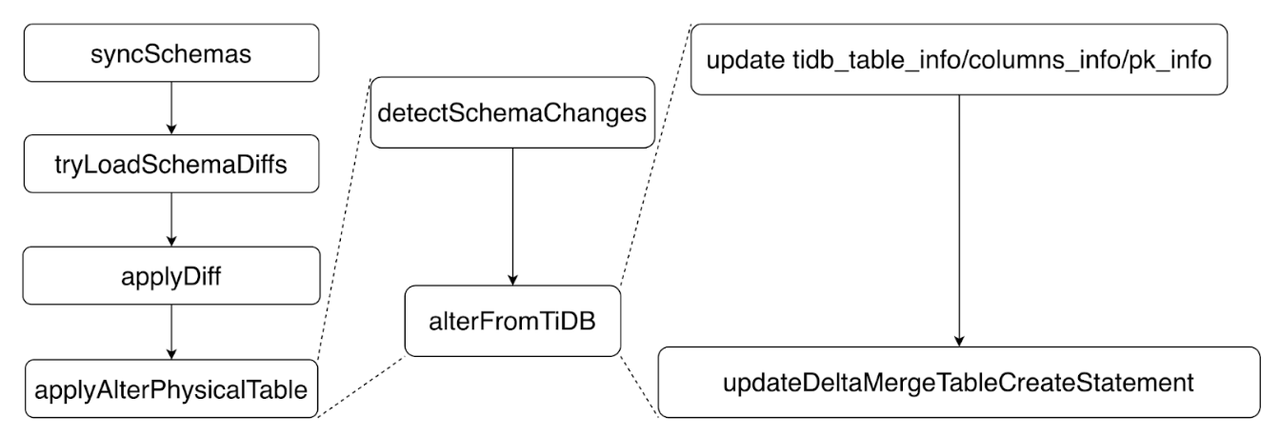
整个过程是通过 TiDBSchemaSyncer 函数 syncSchema来实现的,具体的过程可以参考图八:
- 通过
tryLoadSchemaDiffs, TiKV 中拿到这一轮新的 schema 变更信息。 - 随后遍历所有的 diffs 来一个个进行
applyDiff。 - 对每个 diff,我们会找到他对应的 table,进行
applyAlterPhysicalTable。 - 在这其中,我们会 detect 到这轮更新中,跟这个表相关的所有 schema 变更,然后调用
StorageDeltaMerge::alterFromTiDB来对这张表对应的StorageDeltaMerge对象进行变更。 - 具体变更中,我们会修改
tidb_table_info, 相关的 columns 和主键的信息。 - 另外我们还会更新这张表的建表语句,因为表本身发生了变化,所以他的建表语句也需要对应改变,这样后续做 recover 等操作的时候才能正确工作。
在整个 syncSchema 的过程中,我们是不会更新 decoding_schema_snapshot的。decoding_schema_snapshot采用的是采用的是懒惰更新的方式,只有在具体的数据要发生写入操作了,需要调用到 decoding_schema_snapshot,它才会去检测自己目前是不是最新的 schema 对应的状态,如果不是,就会根据最新的 tidb_table_info 相关的信息来更新。也是通过这样的方式,我们可以减少很多不必要的转换。比如如果一张表频繁发生了很多 schema change,但是没有做任何的写操作, 那么就可以避免 tidb_table_info到 decoding_schema_snapshot 之间的诸多计算转换操作。
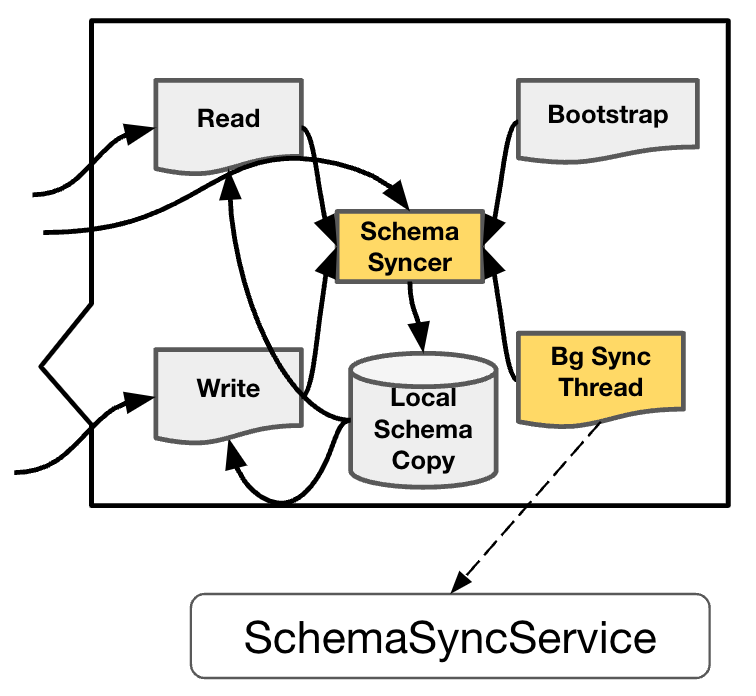
对于周围涉及到调用 Schema Syncer 的模块,Read,Write,BootStrap 这三个模块都是直接的调用 TiDBSchemaSyncer::syncSchema。而 Background Sync Thread 则是通过 SchemaSyncService 来负责,在 TiFlash Server 启动的最开始阶段,把 syncSchema 这个函数塞到 background thread pool里面去,保持大概每隔10s调用一次,来实现定期更新。
Schema on Data Write
我们先来了解一下,写的过程本身需要处理的情况。我们有一个要写入的行格式的数据,需要把他每一列内容进行解析处理,写入列存引擎中。另外我们节点中有 local schema copy 来帮助解析。但是,这行要写入的数据和我们的 schema copy 在时间上的先后顺序是不确定的。因为我们的数据是通过 raft log / raft snapshot 的形式发送过来的,是一个异步的过程。schema copy 则是定期来进行更新的,也可以看作是一个异步的过程,所以对应的 schema 版本和 这行写入的数据 在 TiDB 上发生的先后顺序我们是不知道的。写操作就是要在这样的场景下,正确的解析数据进行写入。
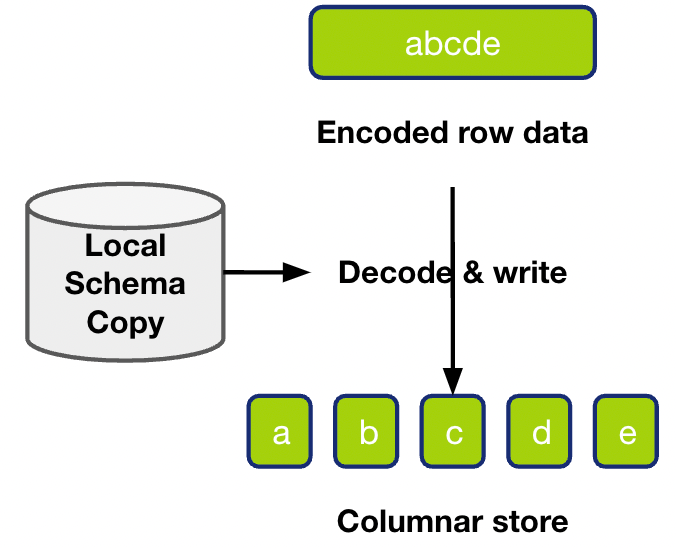
对于这样的场景,会有个非常直接的处理思路:我们可以在做行转列解析前,先拉取最新的 schema,从而保证我们的 schema 一定比要写入的数据更新,这样一定是可以成功解析的。但是一方面 schema 不是频繁变更的,另外每次写都要拉取 schema 是非常大的开销,所以我们写操作最终选择的做法是,我们先直接用现有的 schema copy 来解析这行数据,如果解析成功了就结束,解析失败了,我们再去拉取最新的 schema 来重新解析。
在做第一轮解析时,除了正确解析完成以外,我们还可能遇到以下三种情况:
- 第一种情况 Unknown Column, 即待写入的数据比 schema 多了一列 e。发生这种情况的可能有下面两种可能。
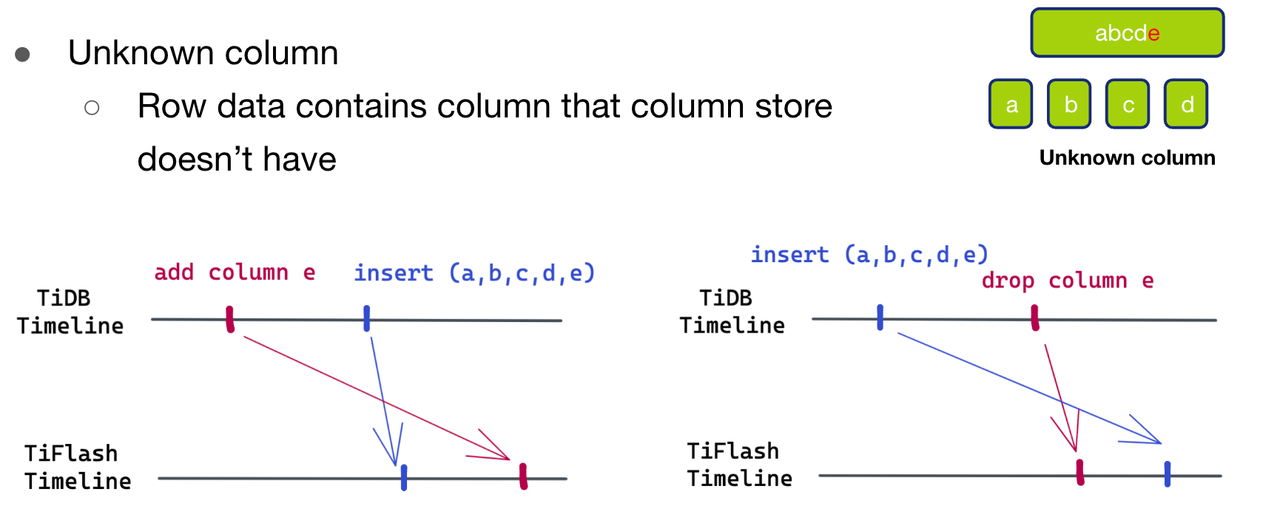
- 第一种可能,如图十一(左)所示,待写入的数据比 schema 新。在 TiDB 的时间线上,先新增了一列 e,随后再插入了 (a,b,c,d,e) 这行数据。但是插入的数据先到到了 TiFlash ,add column e 的 schema 变更还没到 TiFlash 侧,所以就出现了数据比 schema 多一列的情况。
- 第二种可能,如图十一(右)所示,待写入的数据比 schema 旧。在 TiDB 的时间线上,先插入了这行数据 (a,b,c,d,e),然后 drop column e。但是 drop column e 的 schema 变更先到达 TiFlash 侧, 插入的数据后到达,也会出现了数据比 schema 多一列的情况。
在这种情况下,我们也没有办法判断到底属于上述是哪一种情况,也没有一个共用的方法能处理,所以就只能返回解析失败,去触发拉取最新的 schema 进行第二轮解析。
- 第二种情况 Missing Column,即待写入的数据比 schema 少了一列 e。同样,也有两种产生的可能性。
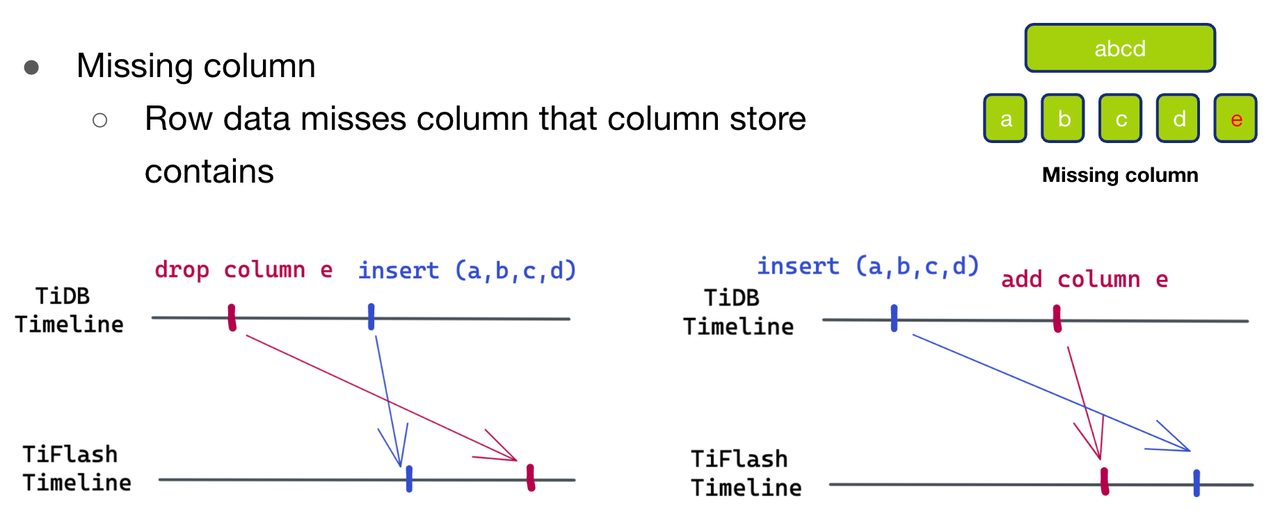
- 第一种可能,如图十二(左)所示,待写入的数据比 schema 新。在 TiDB 时间线上,先 drop column e,再插入数据(a,b,c,d)。
- 第二种可能,如图十二(右)所示,待写入的数据比 schema 旧。 在 TiDB 时间线上,先插入了数据 (a,b,c,d),然后再插入了 e 列。
同样我们这时候也没有办法判断是属于哪种情况,按照前面的做法,我们还是应该解析失败返回重新拉取在解析了。但是在这种情况下,如果多出来的 e 列 是有默认值的或者是支持填 NULL 的,我们可以直接给 e 列填上默认值或者 NULL 来返回解析成功。我们分别看一下在两种可能性下,我们这种填默认值或者 NULL 的处理会有什么样的影响。
第一种可能的情况下,因为我们已经 drop 了 column e,所以后续所有的读操作都不会读到 column e 的操作,所以其实给 e 列填任何值,都不会影响正确性。而对于第二种可能的情况,本身 (a,b,c,d) 这行数据就是缺失 e 的值的,需要在读的时候给这行数据填 e 的默认值 或者 NULL 的,所以在这个情况下,我直接先给这行数据的 column e 填了默认值或者 NULL,也是完全可以正常工作的。所以这两种情况下,我们给 e 列填默认值或者 NULL 都是可以正确工作的,因此我们就不需要返回解析失败了。但是如果多出的 e 列并不支持填默认值或者 NULL,那就只能返回解析失败,去触发拉取最新的 schema 进行第二轮解析。
- 第三种情况 Overflow Column,即我们待写入的数据中有一列数值大于了我们 schema 中这一列的数据范围的。
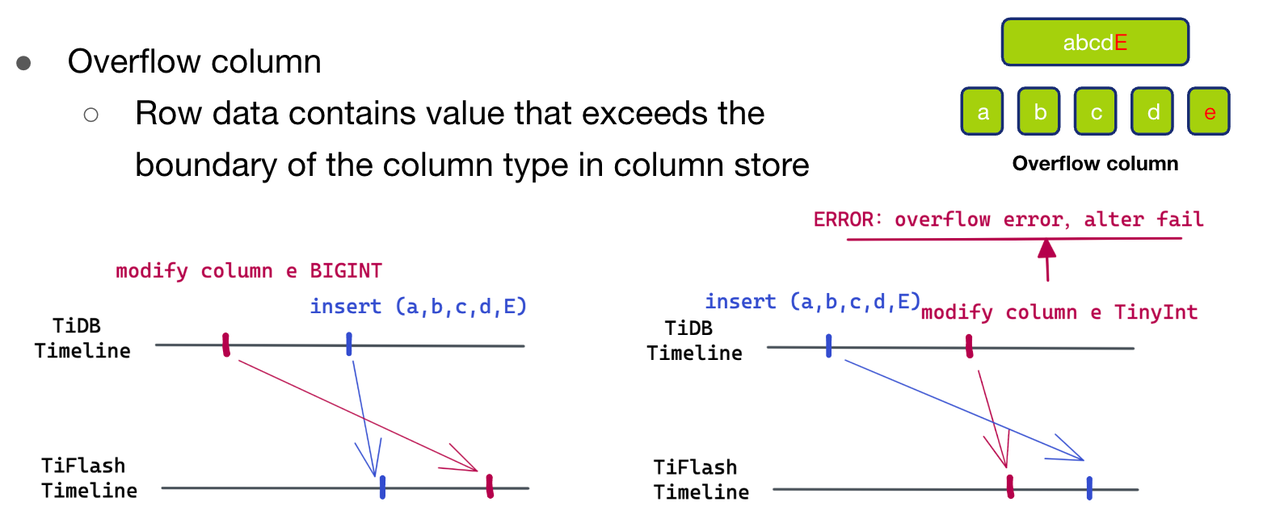
对于这种情况,只有图十三(左)这种情况,即先进行了扩列的操作,然后插入了新的数据,但是数据先于 schema 到达了 TiFlash。我们可以看一下图十三(右)来理解为什么不可能是先插入数据再触发缩列的情况。如果我们先插入了数据(a,b,c,d,E),然后对 e 列做了缩列操作,将 e 列从 int 类型缩成 tinyint 类型。而因为插入的这个 E 超过了 tinyint 的范围,所以这个 DDL 操作会报 overflow 的错误的,操作失败,因此无法导致 overflow column 这种现象。
因此出现 overflow的场景,只可能是图十三(左)的这种情况。但是因为 schema change 还没有到达 TiFlash,我们并不知道新的列具体的数据范围是怎么样的,所以没有办法把这个 overflow 的值 E 写入 TiFlash 存储引擎,所以我们也只能返回解析失败,去触发拉取最新的 schema 进行第二轮解析。
了解完再第一次解析的时候可能会遇到的三种异常情况,我们再来了解一下在第一次解析失败下,重新拉取最新的 schema 以后,再进行第二轮解析下会出现的情况。同样的,除了在第二轮正常的完成解析以外,我们还可能遇到前面的三种情况,但不一样的是,在第二轮解析时,可以保证我们的 schema 比待写入的数据更新了。

- 第一种情况 Unknown Column。因为 schema 比 待写入的数据新,所以我们可以肯定是因为在这行数据后,又发生了 drop column e 的操作,但是这个 schema change 先到达了 TiFlash 侧,所以导致了 Unknown Column 的场景。因此我们只需要直接把 e 列数据直接删除即可。
- 第二种情况 Missing Column。这种情况则是由于在这行数据后进行了 add column e 的操作造成的,因此我们直接给多余的列填上默认值即可。
- 第三种情况 Overflow Column。因为目前我们的 schema 已经比待写入的数据新了,所以再次出现 overflow column 的情况,一定是发生了异常,因此我们直接抛出异常。
以上就是写数据过程的整体的思路,如果想了解具体的代码细节,可以搜索一下 writeRegionDataToStorage 这个函数。另外我们的行转列的过程是依赖 RegionBlockReader 这个类来实现的,这个类依赖的 schema 信息就是我们前面提到的 decoding_schema_snapshot。在行转列的过程中,RegionBlockReader 在拿 decoding_schema_snapshot 的时候会先检查 decoding_schema_snapshot 是否跟最新的 tidb_table_info 版本是对齐的,如果没对齐,就会触发 decoding_schema_snapshot 的更新,具体逻辑可以参考 getSchemaSnapshotAndBlockForDecoding 这个函数。
Schema on Data Read
和写不太一样的是,在开始内部的读流程之前,我们需要先校验 schema version。我们上层发送的请求中,会带有 schema version 信息(Query_Version)。读请求校验需要满足的要求则是,待读的表本地的 schema 信息和读请求里面的 schema version 对应的信息保持一致的。
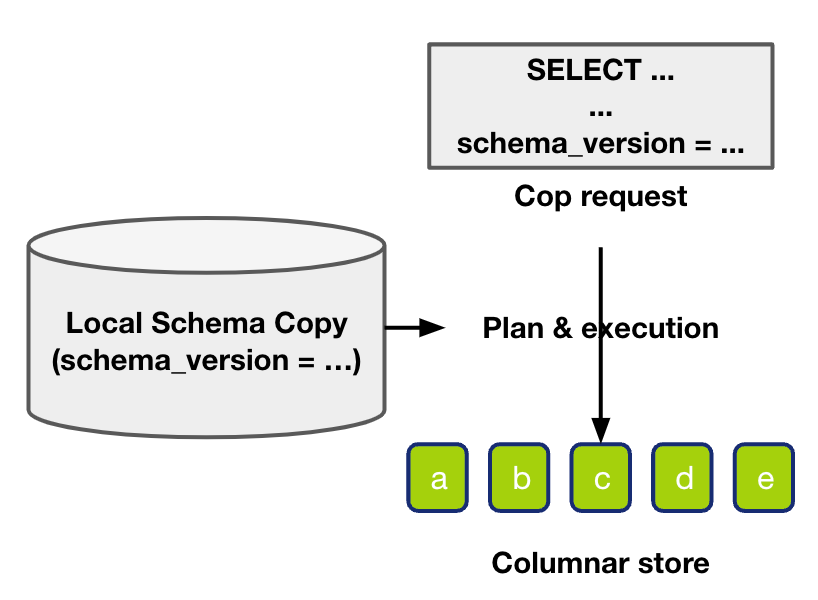
TiFlash 负责拉取 schema 的 TiDBSchemaSyncer 会记录整体的 schema version,我们这边称它为Local_Version。因此读操作的要求即 Query_Version = Local_Version。如果 Query_Version 大于 Local_Version,我们会认为本地 schema 版本落后了,因此触发 sync schema ,拉取最新的 schema,再重新进行校验。如果 Query_Version 小于 Local_Version,我们就会认为 query 的 schema 版本太老,因此会拒绝读请求,让上层节点更新 schema version 后重新发送请求。
在这种设定下,如果我们有个表在非常频繁的发生 DDL 操作,那么他的 schema version 就会不断更新。因此如果此时又需要对这个表进行读操作,就很容易出现读操作一直在 Query_Version > Local_Version 和 Query_Version < Local_Version 两种状态下交替来回的状况。比如一开始读请求的 schema version 更大,触发 TiFlash sync schema,更新 local schema copy。更新后本地的 schema version 就比读请求新,因此触发拒绝读请求。读请求更新 schema version 后,我们又发现读请求的 schema version 比 本地 schema copy 更新了,周而复始 … 对于这种情况,我们目前是没有做特殊处理的。我们会认为这种情况是非常非常罕见的,或者说不会发生的,所以如果不幸发生了这样的特殊情况,那只能等待他们达到一个平衡状态,顺利开始读操作。
前面我们提到读操作要求 Query_Version 和 Local_Version 完全相等,因此非常容易出现出现不相等的情况,从而造成诸多重新发起查询或者重新拉取 schema 的情况。为了减少发生此种情况的次数,我们做了一个小的优化。
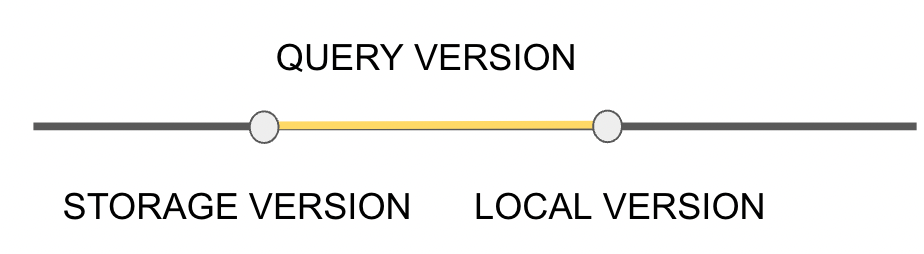
我们除了 TiFlash 整体有 schema version外,每张表也有自己的 schema version,我们称为 Storage_Version,并且我们的 Storage_Version 永远小于等于 Local_Version 的, 因为只有在最新的schema 变更的时候,确实修改了这张表,Storage_Version 才会恰好等于 Local_Version, 其他情况下,Storage_Version 都是小于 Local_Version 的。因此在 [Storage_Version, Local_Version] 这个区间中,我们这张表的 schema 信息是没有发生任何变化的。也就是 Query_Version只要在[Storage_Version, Local_Version] 这个区间内,读请求要求的这张表的 schema 信息和我们目前的 schema 版本就是完全一致的。所以我们就可以把 Query_Version < Local_Version 这个限定放松到 Query_Version < Storage_Version。在 Query_Version < Storage_Version 时,才需要更新读请求的 schema 信息。
在校验结束后,负责读的模块根据我们对应表的 tidb_table_info 去建立 stream 进行读取。Schema 相关的流程,我们可以在 InterpreterSelectQuery.cpp 的 getAndLockStorageWithSchemaVersion 以及 DAGStorageInterpreter.cpp 的 getAndLockStorages 中进行进一步的了解。 InterpreterSelectQuery.cpp 和 DAGStorageInterpreter.cpp 都是来负责对 TiFlash 进行读表的操作,前者是负责 clickhouse client 连接下读取的流程,后者则是 TiDB 支路中读取的流程。
Special Case
最后我们看一个例子,来了解一下 Drop Table 和 Recover Table 相关的情况。
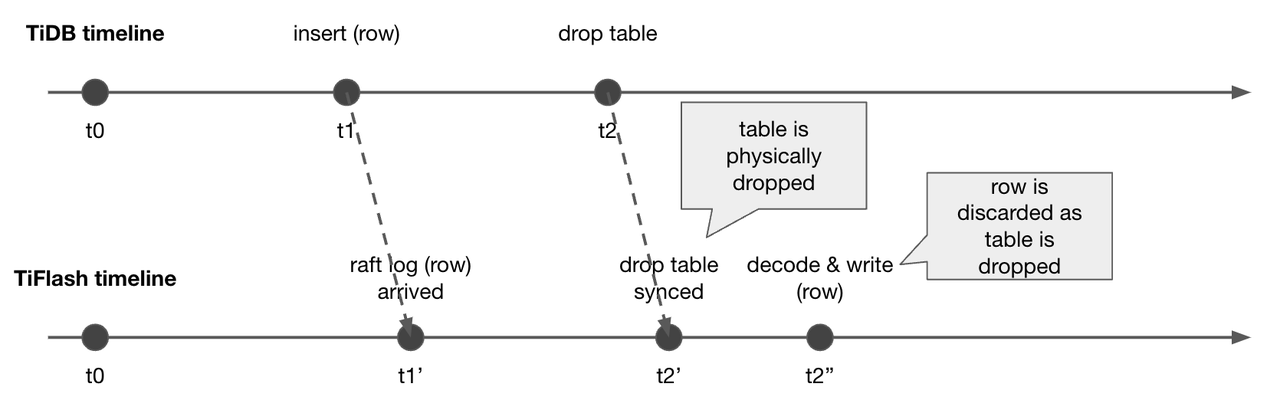
图十六中上方的线是 TiDB 的时间线,下方的线是 TiFlash 的时间线。在 t1 的时候,TiDB 进行了 insert 的操作,然后在 t2 的时候又进行了 drop table 的操作。t1’ 的时候,TiFlash 收到了 insert 这条操作的 raft log,但是还没进行到解析和写入的步骤,然后在 t2’ 的时候,TiFlash 同步到了 drop table 这条 schema DDL 操作,进行了 schema 的更新。等到 t2’’ 的时候,TiFlash 开始 解析前面那条新插入的数据了,但是这时候因为对应的表已经被删除了,所以我们就会扔掉这条数据。到目前为止还没有任何的问题。
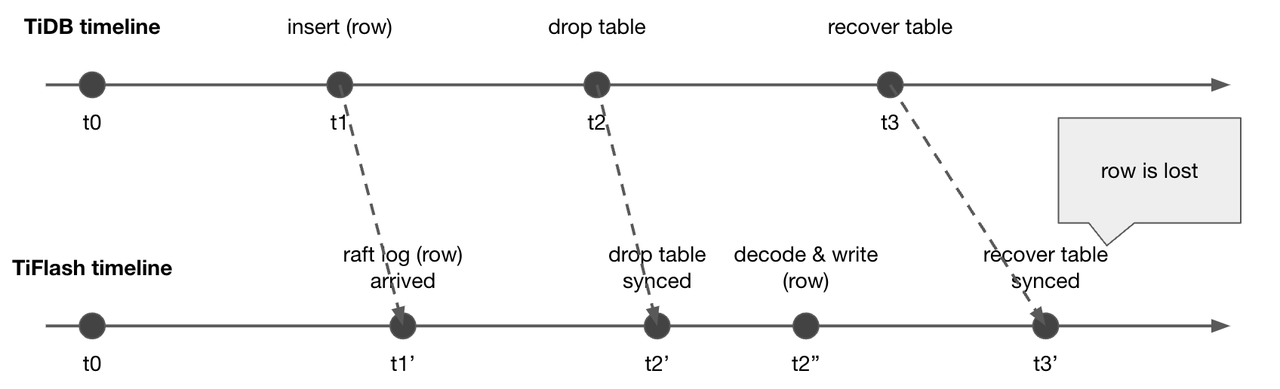
但是如果 t3 的时候我们又进行了 recover 的操作,将这张表恢复了,那最后插入的这条 row 数据就丢失了。数据丢失是我们不能接受的结果。因此 TiFlash 对于 drop table 这类的 DDL,会对这张表设上 tombstone,具体的物理回收延后到做 gc 操作的时候再发生。对于 drop table 后这张表上还存在的写操作,我们会继续进行解析和写入,这样在后续做 recover 的时候,我们也不会发生数据的丢失。
小结
本篇文章主要介绍了 TiFlash 中 DDL 模块的设计思想,具体实现和核心的相关流程。更多的代码阅读内容会在后面的章节中逐步展开,敬请期待。
-
Springboot应用的多环境打包入门11-23
-
Springboot应用的生产发布入门教程11-23
-
Python编程入门指南11-23
-
Java创业入门:从零开始的编程之旅11-23
-
Java创业入门:新手必读的Java编程与创业指南11-23
-
Java对接阿里云智能语音服务入门详解11-23
-
Java对接阿里云智能语音服务入门教程11-23
-
JAVA对接阿里云智能语音服务入门教程11-23
-
Java副业入门:初学者的简单教程11-23
-
JAVA副业入门:初学者的实战指南11-23
-
JAVA项目部署入门:新手必读指南11-23
-
Java项目部署入门:新手必看指南11-23
-
Java项目部署入门:新手必读指南11-23
-
Java项目开发入门:新手必读指南11-23
-
JAVA项目开发入门:从零开始的实用教程11-23
