Docker容器
Docker-Compose 入门到实战详尽笔记

使用过 Docker 的小伙伴们都知道,启动 Docker 时一般会附带很多的启动参数,如 -v 指定挂载目录,-p 指定端口等等。除此之外,很多时候我们的业务系统中一般都会有几个 Docker 组合运行,容器间网络通信,容器的启动顺序等有明确的要求。基于这些问题,Docker-Compose 技术诞生。
本文将从基础到实战举例,共计7个小节,前面5小节讲解基础,后面2个小节则时以实战为主,详细讲解 Docker-Compose 的使用。主要讲解如下内容:
- Docker-Compose 和 Docker 的联系
- 安装 Docker-Compose
- YAML 语法概述
- Docker-Compose 语法总结
- Docker-Compose 常用命令
- 实战演练一:Docker-Compose 部署伪分布式的 Elasticsearch
- 实战演练二:Docker-Compose 部署 Kafka(Zookeeper)
如果基础好一点的同学,可以直接跳到第6章开始学习实战环节,有问题再倒回来查看基础。
阅读并实践本篇文章内容,大致需要30分钟左右。
Docker-Compose 和 Docker 的联系
相信你们在使用 Docker 时都遇到过以下两个场景:
- Docker 启动要指定参数,例如 -p 指定端口,-v 挂载目录等,当下次启动时,由于参数太多,忘记启动参数。
- 多个 Docker 容器启动时有依赖关系,不确定启动的先后顺序。
而 Docker-Compose 的出现就是为了解决上述两个问题,通过编写 yaml 文件定义 Docker 启动参数和编排容器。
安装 Docker-Compose
Docker-Compose 支持目前主流平台的安装,如图:
参考连接:https://docs.docker.com/compose/install/
小伙伴们根据自己的情况安装对应的版本即可,我这里以 Ubuntu 16.04 环境作为演示,也可以按照官网所述的安装步骤,也可以直接一句命令即可(当然前提时已经安装 Docker ):
apt install docker-compose
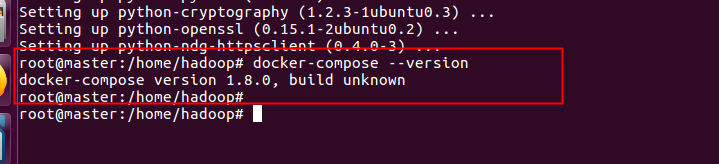
安装完毕后 docker-compose --version 查看版本
每次输入 docker-compose 这个命令确实比较长,我这里教搭建一个给 docker-compose 取别名的方式,操作如下:
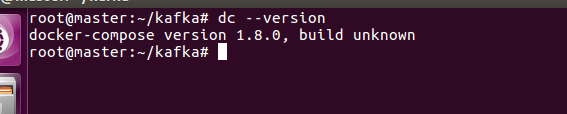
vi ~/.bashrc alias dc='docker-compose' source ~/.bashrc
上述操作的原理就是在系统的环境变量里面为某个指令添加别名,执行完上述三条命令,docker-compose 使用 dc 就可以调用了,如图:
YAML 语法概述
Docker-Compose 容器编排的主要利用到 YAML 语法。学习 YAML 语法可以和 JSON 类比学习,例如 JSON 中有对象、数组等,利用 YAML 语法均可以表示出来。详细的内容推荐看 阮一峰的 《YAML 语言教程》
Docker-Compose 语法总结
前面的铺垫打好之后,这一章我们开始学习 Docker-Compose 语法,如果熟悉 Docker 语法的小伙伴,这一章将会学得很快。Docker-Compose 主要目的就是用作容器的编排,编排容器用的是 YAML 语法,编排文件内容都写在 docker-compose.yml 文件中。下面我们根据 Docker-Compose 的编排常用的语法依次做讲解,部分不常用的就小伙伴们根据自己的实际需求去官方网站查询即可,Docker 支持的操作,Docker-Compose 是肯定支持的。
version
每个 docker-compose.yml 文件第一个字段就是 version,version 字段是表明使用那个版本的 Compose ,Compose 有如下的版本,目前的最新版是 3.7,此外还有1、2、2.x、3.x,不同版本的 compose 支持了不同的 Docker 版本。
compose 与 Docker 的版本对应关系表:
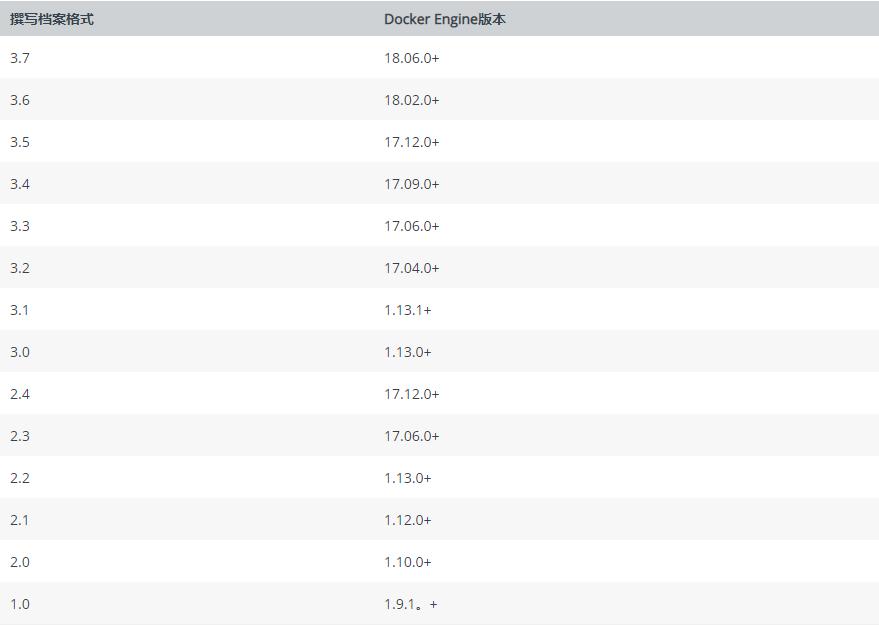
除了表中显示的Compose文件格式版本外,Compose本身也处于发布计划中,如Compose版本中所示,但是文件格式版本不一定会随每个版本而增加。例如,Compose文件格式3.0最初是在Compose版本1.10.0中引入的,并在随后的版本中逐渐版本化。
语法结构如下:
version: "2"
version: "3.7" #可以简写为 version: "3"
image
services:
web:
image: hello-world
在 services 标签下的第二级标签是 web,这个名字是用户自己自定义,它就是服务名称。
image 则是指定服务的镜像名称或镜像 ID。如果镜像在本地不存在,Compose 将会尝试拉取这个镜像。
build
服务除了可以基于指定的镜像,还可以基于一份 Dockerfile,在使用 up 启动之时执行构建任务,这个构建标签就是 build,它可以指定 Dockerfile 所在文件夹的路径。Compose 将会利用它自动构建这个镜像,然后使用这个镜像启动服务容器。
build: /path/to/build/dir
也可以是相对路径,只要上下文确定就可以读取到 Dockerfile
build: ./dir
设定上下文根目录,然后以该目录为准指定 Dockerfile
build: context: ../ dockerfile: path/of/Dockerfile
注意 build 都是一个目录,如果你要指定 Dockerfile 文件需要在 build 标签的子级标签中使用 dockerfile 标签指定,如上面的例子。
如果你同时指定了 image 和 build 两个标签,那么 Compose 会构建镜像并且把镜像命名为 image 后面的那个名字。
build: ./dir image: webapp:tag
既然可以在 docker-compose.yml 中定义构建任务,那么一定少不了 arg 这个标签,就像 Dockerfile 中的 ARG 指令,它可以在构建过程中指定环境变量,但是在构建成功后取消,在 docker-compose.yml 文件中也支持这样的写法:
build:
context: .
args:
buildno: 1
password: secret
下面这种写法也是支持的,一般来说下面的写法更适合阅读。
build:
context: .
args:
- buildno=1
- password=secret
与 ENV 不同的是,ARG 是允许空值的,这样构建过程可以向它们赋值。。例如:
args: - buildno - password
注意:YAML 的布尔值(true, false, yes, no, on, off)必须要使用引号引起来(单引号、双引号均可),否则会当成字符串解析。
command
使用 command 可以覆盖容器启动后默认执行的命令。
command: echo 'hello world'
也可以写成类似 Dockerfile 中的格式:
command: ['echo','hello world']
container_name
前面说过 Compose 的容器名称格式是:<项目名称><服务名称><序号>
虽然可以自定义项目名称、服务名称,但是如果你想完全控制容器的命名,可以使用这个标签指定:
container_name: app
这样容器的名字就指定为 app 了。
depends_on
在使用 Compose 时,最大的好处就是少打启动命令,但是一般项目容器启动的顺序是有要求的,如果直接从上到下启动容器,必然会因为容器依赖问题而启动失败。
例如在没启动数据库容器的时候启动了应用容器,这时候应用容器会因为找不到数据库而退出,为了避免这种情况我们需要加入一个标签,就是 depends_on,这个标签解决了容器的依赖、启动先后的问题。
例如下面容器会先启动 redis 和 db 两个服务,最后才启动 web 服务:
version: '2'
services:
web:
build: .
depends_on:
- db
- redis
redis:
image: redis
db:
image: postgres
注意的是,默认情况下使用 docker-compose up web 这样的方式启动 web 服务时,也会启动 redis 和 db 两个服务,因为在配置文件中定义了依赖关系。
dns
和 --dns 参数一样用途,格式如下:
dns: 8.8.8.8
也可以是一个列表:
dns: - 8.8.8.8 - 9.9.9.9
此外 dns_search 的配置也类似:
dns_search: example.com dns_search: - dc1.example.com - dc2.example.com
tmpfs
挂载临时目录到容器内部,与 run 的参数一样效果:
tmpfs: /run tmpfs: - /run - /tmp
entrypoint
在 Dockerfile 中有一个指令叫做 ENTRYPOINT 指令,用于指定接入点,ENTRYPOINT 配置容器启动时的执行命令,如果 Dockerfile 中如果存在多个 ENTRYPOINT 指令,仅最后一个生效。(不会被忽略,一定会被执行,即使运行 docker run 时指定了其他命令)。
在 docker-compose.yml 中可以定义接入点,覆盖 Dockerfile 中的定义:
entrypoint: /code/entrypoint.sh
env_file
还记得前面提到的 .env 文件吧,这个文件可以设置 Compose 的变量。而在 docker-compose.yml 中可以定义一个专门存放变量的文件。
如果通过 docker-compose -f FILE 指定了配置文件,则 env_file 中路径会使用配置文件路径。
如果有变量名称与 environment 指令冲突,则以后者为准。格式如下:
env_file: .env
或者根据 docker-compose.yml 设置多个:
env_file: - ./common.env - ./apps/web.env - /opt/secrets.env
注意的是这里所说的环境变量是对宿主机的 Compose 而言的,如果在配置文件中有 build 操作,这些变量并不会进入构建过程中,如果要在构建中使用变量还是首选前面刚讲的 arg 标签。
environment
与上面的 env_file 标签完全不同,反而和 arg 有几分类似,这个标签的作用是设置镜像变量,它可以保存变量到镜像里面,也就是说启动的容器也会包含这些变量设置,这是与 arg 最大的不同。
一般 arg 标签的变量仅用在构建过程中。而 environment 和 Dockerfile 中的 ENV 指令一样会把变量一直保存在镜像、容器中,类似 docker run -e 的效果。
environment: RACK_ENV: development SHOW: 'true' SESSION_SECRET: environment: - RACK_ENV=development - SHOW=true - SESSION_SECRET
expose
这个标签与Dockerfile中的EXPOSE指令一样,用于指定暴露的端口,但是只是作为一种参考,实际上docker-compose.yml的端口映射还得ports这样的标签。
expose: - "3000" - "8000"
external_links
在使用Docker过程中,我们会有许多单独使用docker run启动的容器,为了使 Compose 能够连接这些不在 docker-compose.yml 中定义的容器,我们需要一个特殊的标签,就是external_links,它可以让 Compose 项目里面的容器连接到那些项目配置外部的容器(前提是外部容器中必须至少有一个容器是连接到与项目内的服务的同一个网络里面)。
格式如下:
external_links: - redis_1 - project_db_1:mysql - project_db_1:postgresql
extra_hosts
添加主机名的标签,就是往/etc/hosts文件中添加一些记录,与Docker client的–add-host类似:
extra_hosts: - "somehost:162.242.195.82" - "otherhost:50.31.209.229"
启动之后查看容器内部hosts:
162.242.195.82 somehost 50.31.209.229 otherhost
labels
向容器添加元数据,和 Dockerfile 的 LABEL 指令一个意思,类似于代码注释,这个就是对 Compose 做一个陈述,格式如下:
labels: com.example.description: "Accounting webapp" com.example.department: "Finance" com.example.label-with-empty-value: "" labels: - "com.example.description=Accounting webapp" - "com.example.department=Finance" - "com.example.label-with-empty-value"
links
前面提到的参数 depends_on 解决的是启动顺序问题,这个标签解决的是容器连接问题,与 Docker client的–link 一样效果,会连接到其它服务中的容器。
links: - db - db:database - redis
ports
映射端口的标签。
使用 HOST:CONTAINER 格式或者只是指定容器的端口,宿主机会随机映射端口。
ports: - "3000" - "8000:8000" - "49100:22" - "127.0.0.1:8001:8001"
注意:当使用 HOST:CONTAINER 格式来映射端口时,如果你使用的容器端口小于60你可能会得到错误得结果,因为YAML将会解析xx:yy这种数字格式为60进制。所以建议采用字符串格式。
volumes
挂载一个目录或者一个已存在的数据卷容器,可以直接使用 [HOST:CONTAINER] 这样的格式,或者使用 [HOST:CONTAINER:ro] 这样的格式,后者对于容器来说,数据卷是只读的,这样可以有效保护宿主机的文件系统。
Compose的数据卷指定路径可以是相对路径,使用 . 或者 … 来指定相对目录。
数据卷的格式可以是下面多种形式:
volumes: # 只是指定一个路径,Docker 会自动在创建一个数据卷(这个路径是容器内部的)。 - /var/lib/mysql # 使用绝对路径挂载数据卷 - /opt/data:/var/lib/mysql # 以 Compose 配置文件为中心的相对路径作为数据卷挂载到容器。 - ./cache:/tmp/cache # 使用用户的相对路径(~/ 表示的目录是 /home/<用户目录>/ 或者 /root/)。 - ~/configs:/etc/configs/:ro # 已经存在的命名的数据卷。 - datavolume:/var/lib/mysql
network_mode
网络模式,与Docker client的–net参数类似,只是相对多了一个service:[service name] 的格式。
例如:
network_mode: "bridge" network_mode: "host" network_mode: "none" network_mode: "service:[service name]" network_mode: "container:[container name/id]"
可以指定使用服务或者容器的网络,这几种网络模式有很大的区别,有空的话都可以去了解一下,默认是 bridge,即桥接模式。
networks
加入指定网络,格式如下:
services:
some-service:
networks:
- some-network
- other-network
关于这个标签还有一个特别的子标签aliases,这是一个用来设置服务别名的标签,例如:
services:
some-service:
networks:
some-network:
aliases:
- alias1
- alias3
other-network:
aliases:
- alias2
相同的服务可以在不同的网络有不同的别名。
Docker-Compose 常用命令
这一章我们来继续学习有关 Docker-Compose 的执行命令,Docker-Compose 总体来看和 Docker 命令很类似,具体有哪些命令,我们可以通过 docker-compose -h 查看,如图:
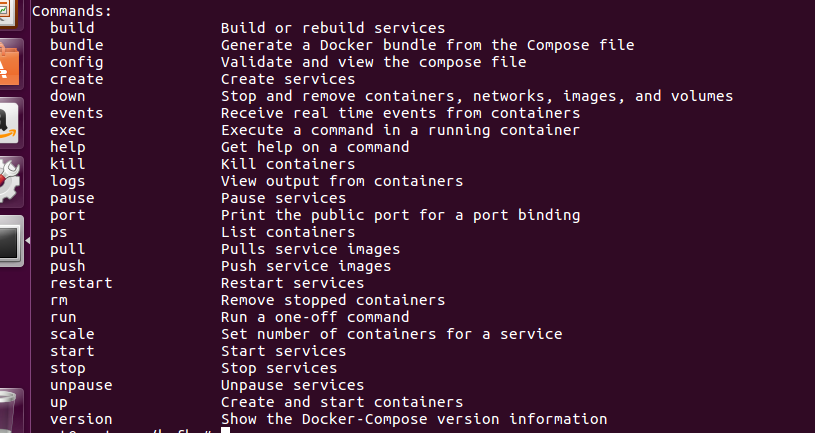
下面我来依次对常用的做说明,并做适当的举例辅助理解。
docker-compose up -d nginx 构建建启动nignx容器 docker-compose exec nginx bash 登录到nginx容器中 docker-compose down 删除所有nginx容器,镜像 docker-compose ps 显示所有容器 docker-compose restart nginx 重新启动nginx容器 docker-compose run --no-deps --rm php-fpm php -v 在php-fpm中不启动关联容器,并容器执行php -v 执行完成后删除容器 docker-compose build nginx 构建镜像 docker-compose build --no-cache nginx 不带缓存的构建 docker-compose logs nginx 查看nginx的日志 docker-compose logs -f nginx 查看nginx的实时日志 docker-compose config -q 验证(docker-compose.yml)文件配置,当配置正确时,不输出任何内容,当文件配置错误,输出错误信息。 docker-compose events --json nginx 以json的形式输出nginx的docker日志 docker-compose pause nginx 暂停nignx容器 docker-compose unpause nginx 恢复ningx容器 docker-compose rm nginx 删除容器(删除前必须关闭容器) docker-compose stop nginx 停止nignx容器 docker-compose start nginx 启动nignx容
到这里基础环境我们已经学习完毕,下面我开始进入紧张刺激的实战环节,小伙伴也可以在学完基础章节后,只看实战的标题,试着自己去写写,然后和我的对照这看。
实战演练一:Docker-Compose 部署伪分布式的 Elasticsearch
Elasticsearch 是一个开源、高扩展的分布式全文检索引擎,可以近乎实时的存储、检索数据。而且扩展性很好,条件允许下可以扩展到上百台服务器,处理 PB 级别的数据,已经广泛应用于业务系统及大数据项目中。通过 Docker-Compose 搭建的目的是我们可以快速搭建一个伪分布式的 Elasticsearch 集群,这样做的目的是为了学习方便同时也阔以用于小型系统的生产环境,从而不用为了搭建环境而浪费时间。
Elastisearch 官网 Docker-Compose 安装说明:https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html
下面的 docker-compose 文件来自于 Elasticsearch 官网推荐,为了运行更方便,我提前将 Elasticsearch 镜像下载到阿里云镜像。详细的解释以注释的方式在文件中表示。
version: '2'
services:
# 服务名称,这里启动了三个,分别是es01,es02,es03
es01:
#将官方地址替换为了我的阿里云地址,这样下载速度会更快
image: registry.cn-hangzhou.aliyuncs.com/chand/elasticsearch:7.10.1
#指定容器的名称
container_name: es01
environment:
# 配置es相关的环境变量
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
#ulimit设置限制的时候会设置两条线soft和hard线,当资源到达了soft线那么只是告警,如果达到了hard线那么内核就强制限制了。
ulimits:
memlock:
soft: -1
hard: -1
#数据挂载到本地目录
volumes:
- data01:/usr/share/elasticsearch/data
#指定暴露的端口
ports:
- 9200:9200
#指定网路
networks:
- elastic
#es02、es03与上述的es01配置几乎一致,后面就不赘述了
es02:
image: registry.cn-hangzhou.aliyuncs.com/chand/elasticsearch:7.10.1
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
networks:
- elastic
es03:
image: registry.cn-hangzhou.aliyuncs.com/chand/elasticsearch:7.10.1
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge
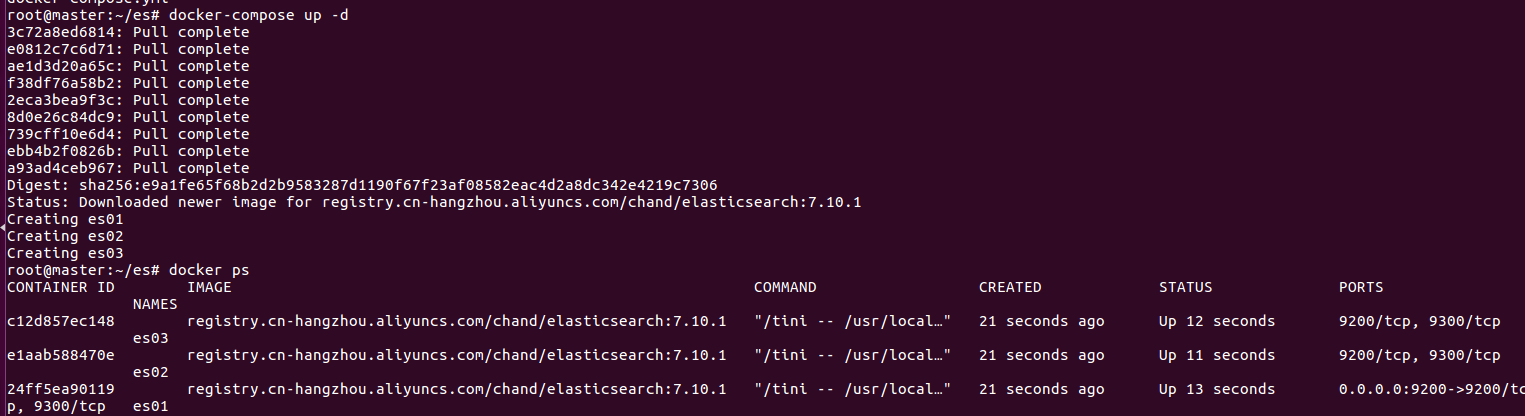
配置好上述命令后,我们来执行命令 docker-compose up -d 启动 Compose,docker-compose ps 查看启动状态,如图:
ip:9200/_cluster/health?pretty浏览器查看是否启动集群成功,我本地 ip 是 192.168.10.107,访问地址:http://192.168.10.107:9200/_cluster/health?pretty,结果如图:
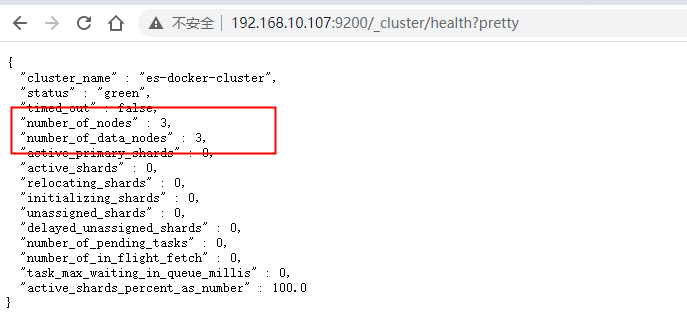
可以看到成功启动了集群,至此我们的第一实战演示完毕。我这里在运行时候由于内存不足报错了异常信息如下:
[max virtual memory areas vm.max_map_count [65530\] is too low, increase to at least [262144]](https://www.cnblogs.com/yidiandhappy/p/7714489.html)
解决方案:
sysctl -w vm.max_map_count=262144
为了防止重启后失效,修改虚拟机配置文件 vi /etc/sysctl.conf,在最后一行添加如下内容:
vm.max_map_count=262144
实战演练二:Docker-Compose 部署 Kafka(Zookeeper)
紧接着我们来到第二个实战演示,这个也是小伙伴们在日常工作会遇到的场景,搭建 Kafka。搭建 kafka 比较麻烦一点的是因为 Kafka 高度依赖 Zookeeper。下面我们来看一下通过 Docker-Compose 如何解决,详细说明在文件中以注解的形式表示。
version: '2'
services:
zookeeper:
#拉取 zookeeper镜像,更换为阿里云镜像源,提升拉取速度
image: registry.cn-hangzhou.aliyuncs.com/chand/zookeeper
#暴露映射的端口
ports:
- "2181:2181"
#指定zookeeper的容器名称
container_name: "zookeeper"
#自动重启,即使主机重启也会重启容器
restart: always
kafka:
#拉取 kafka 镜像,更换为阿里云镜像源,提升拉取速度
image: registry.cn-hangzhou.aliyuncs.com/chand/kafka:2.12-2.3.0
#指定kafka容器名称
container_name: "kafka"
#指定端口
ports:
- "9092:9092"
#设置相关kafka的配置
environment:
- TZ=CST-8
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
# 非必须,设置自动创建 topic
- KAFKA_AUTO_CREATE_TOPICS_ENABLE=true
# 修为自己本机实际的IP地址
- KAFKA_ADVERTISED_HOST_NAME=192.168.10.107
- KAFKA_ADVERTISED_PORT=9092
# 修改为自己实际的IP地址
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.10.107
- KAFKA_LISTENERS=PLAINTEXT://:9092
# 非必须,设置对内存
- KAFKA_HEAP_OPTS=-Xmx1G -Xms1G
# 非必须,设置保存7天数据,为默认值
- KAFKA_LOG_RETENTION_HOURS=1
volumes:
# 将 kafka 的数据文件映射出来
- /home/kafka:/kafka
- /var/run/docker.sock:/var/run/docker.sock
#自动重启,即使主机重启也会重启容器
restart: always
执行命令 dc up -d 启动服务,dc ps查看服务的启动状态。

启动完毕后,我们来验证是否成功部署 kafka,我这里通过 Java 调用 kafka 接口,演示创建主题和遍历主题,以测试 kafka 是否联通为目的。
AdminClientTest
package cn.czyfwpla.kafka.examples.admin;
import java.util.concurrent.ExecutionException;
/**
* @author mxq
* 调用kafka admin api 代码示例
*/
public class AdminClientTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
AdminExampleApi adminExampleApi = new AdminExampleApi();
adminExampleApi.listTopics();
adminExampleApi.createTopic("mxq-test");
adminExampleApi.listTopics();
}
}
AdminExampleApi
package cn.czyfwpla.kafka.examples.admin;
import cn.czyfwpla.kafka.examples.KafkaConstant;
import org.apache.kafka.clients.admin.*;
import org.apache.kafka.common.KafkaFuture;
import java.util.*;
import java.util.concurrent.ExecutionException;
/**
* @author mxq
*/
public class AdminExampleApi {
//创建主题
public void createTopic(String topicName) throws ExecutionException, InterruptedException {
Properties properties = new Properties();
properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, KafkaConstant.KAFKA_HOST);
AdminClient adminClient = AdminClient.create(properties);
//副本数量
Short replaceNum = 1;
NewTopic newTopic = new NewTopic(topicName, 1, replaceNum);
Collection collection = new ArrayList();
collection.add(newTopic);
CreateTopicsResult topics = adminClient.createTopics(collection);
KafkaFuture<Void> all = topics.all();
all.get();
}
//遍历主题
public void listTopics() throws ExecutionException, InterruptedException {
Properties properties = new Properties();
properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, KafkaConstant.KAFKA_HOST);
AdminClient adminClient = AdminClient.create(properties);
ListTopicsResult listTopicsResult = adminClient.listTopics();
KafkaFuture<Set<String>> names = listTopicsResult.names();
Set<String> stringSet = names.get();
Iterator<String> iterator = stringSet.iterator();
//遍历主题的名称
while (iterator.hasNext()){
System.out.println(iterator.next());
}
KafkaFuture<Collection<TopicListing>> listings = listTopicsResult.listings();
Collection<TopicListing> topicListings = listings.get();
//遍历主题、消息类型
for (TopicListing topicListing : topicListings) {
System.out.println(topicListing.toString());
}
}
}
结果:

总结
到这里文章也该结束了,对整个文章做一个总结吧,为什么说已经有很多作者都写了 Docker-Compose ,我这里又来写呢。原因目前市面上的 Docker-Compose 文章主要是讲解理论为主,小伙伴们在学习的时候如果不亲自实践,我觉得学到的东西也仅仅停留在理论,难以在工作中起到帮助作用。我这篇文章前面讲解理论为基础,后面以讲解实战为主。前两个实战在我们学习或搭建小型生产环境时,极大提升效率,第三个实战则是以实际项目发布为背景,四个容器组合发布,让小伙伴们直观感受到 Docker-Compose 给我们带来的便利。实战环境由于我的环境和小伙伴们的环境多少会有一些不同,如果你在运行的时候遇到问题,亦或者是文章有写得不对的地方,欢迎在下方留言指出。
-
Docker部署资料:新手入门教程12-20
-
Docker部署实战:新手入门教程12-19
-
Docker部署教程:新手入门详解12-19
-
云原生周刊:在Docker上部署大语言模型12-09
-
Docker教程:新手快速入门指南12-05
-
Docker项目实战:新手教程与案例解析12-05
-
Docker入门教程:快速掌握基础操作12-04
-
Docker入门教程:轻松搭建你的第一个容器化应用12-04
-
Docker-Compose 入门教程:全面解析基础命令与应用场景12-04
-
Docker入门:新手必读的简单教程12-04
-
基于Kafka、Spark、Airflow、PostgreSQL和Docker的端到端数据工程实战教程12-02
-
云原生周刊:Kubernetes 和 Docker 的对比12-02
-
重启 Docker 容器的命令有哪些?-icode9专业技术文章分享11-30
-
Docker-Compose容器集群化项目实战:新手入门指南11-19
-
Docker镜像仓库项目实战:新手入门教程11-19
