Go教程
golang泛型实现——双向循环链表

本文主要是介绍golang泛型实现——双向循环链表,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
一、写在前面
标准库的双向循环链表实现是基于interface{}的,性能一般。为了提升性能,本文基于泛型语法实现一个比标准库更快的链表写法(主要包括双向循环链表的插入和删除的核心操作)。
二、什么是链表
链表用于存储逻辑关系为 “一对一” 的数据,与数组不一样,不要求存储地址是连续的。
三、链表的分类
-
链表根据指针的指向分为 单向链表 和 双向链表 。
- 单向链表:通常使用Next指针
type Node[T any] struct { next *Node[T] Element T }- 双向链表:通常使用Next、Prev两个指针.
type Node[T any] struct { next *Node[T] prev *Node[T] Element T } -
链表根据是否循环, 又分为
- 单向循环链表
- 双向循环链表
- 单向链表
- 双向链表
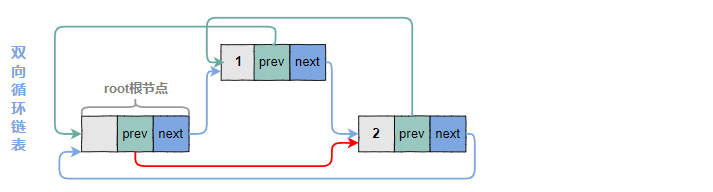
四、双向循环链表的实现
下面主要介绍在工程上用得比较多的双向循环链表(将双向链表的头结点和尾结点链接起来构成循环的链表)的实现。
4.1 双向循环链表的表头定义和初始化函数
循环链表和普通的双向链表最大的区别是初始化的时候root.prev和root.next要指向root节点自己。
说明:
这是一个递归定义,可以试着打印
root.prev,root.prev.prev或者root.next,root.next.next的地址看看。
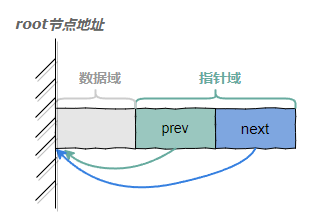
// 每个Node节点, 包含前向和后向两个指针和数据域
type Node[T any] struct {
next *Node[T]
prev *Node[T]
Element T
}
// 返回一个双向循环链表
func New[T any]() *LinkedList[T] {
return new(LinkedList[T]).Init()
}
// 指向自己, 组成一个环
func (l *LinkedList[T]) Init() *LinkedList[T] {
l.root.next = &l.root
l.root.prev = &l.root
l.length = 0
return l
}
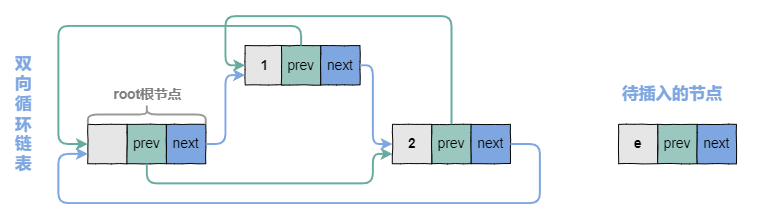
4.2 插入节点的图示
在root节点,如何指向最后一个元素呢? 就是root.prev,下图展示双向循环链表插入节点的过程。
e是待插入节点at是完成插入动作之后e节点前面的一个节点
// at e at.next
// at <- e
// e -> at.next
// at -> e
// e <- at.next
func (l *LinkedList[T]) insert(at, e *Node[T]) {
e.prev = at
e.next = at.next
e.next.prev = e
at.next = e
l.length++
}
4.2.1 插入节点之前的状态
4.2.2 修改e节点的prev指针
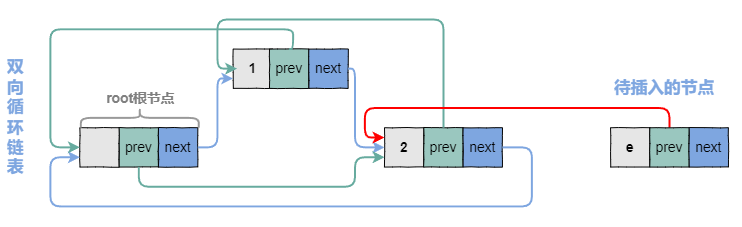
4.2.3 修改e节点的next指针
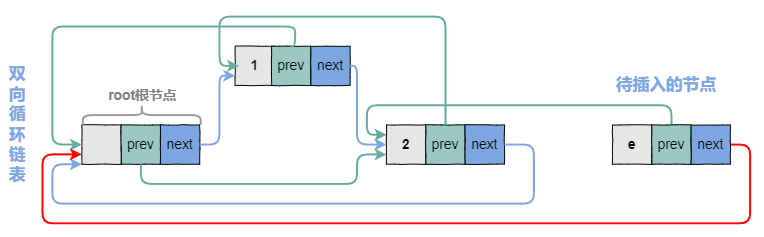
4.2.4 修改e.next.prev指针
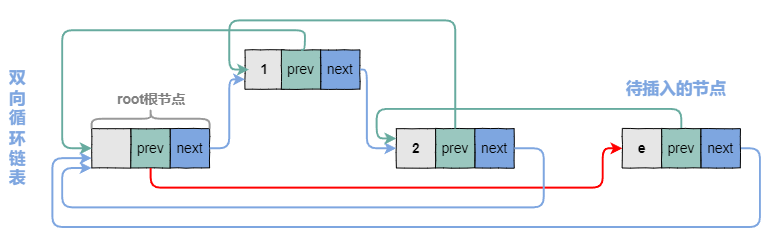
4.2.5 修改at指针的next指针
即,修改2元素的next指针。
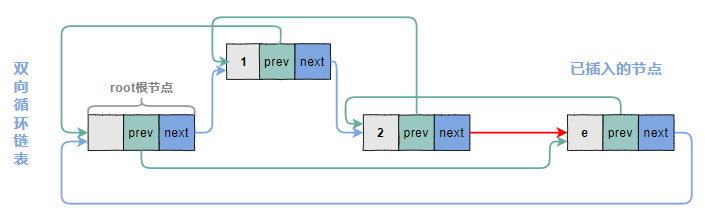
4.3 删除节点的图示
删除某个节点,是把这个节点的前面一个节点和后面一个节点搭上关系。
令n为待删除节点
// 删除这个元素
// n.prev n n.next
// n.prev --> n.next
// n.prev <-- n.next
func (l *LinkedList[T]) remove(n *Node[T]) {
n.prev.next = n.next
n.next.prev = n.prev
n.prev = nil
n.next = nil
l.length--
}
4.3.1 删除节点之前的状态
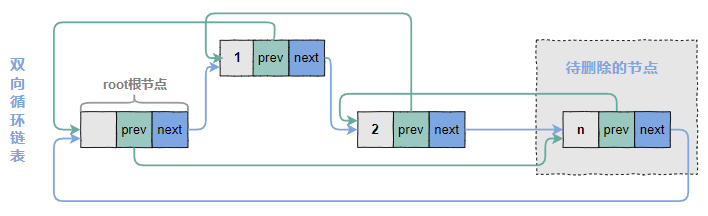
4.3.2 修改n节点的前一个节点的next指针
即,n.prev.next = n.next
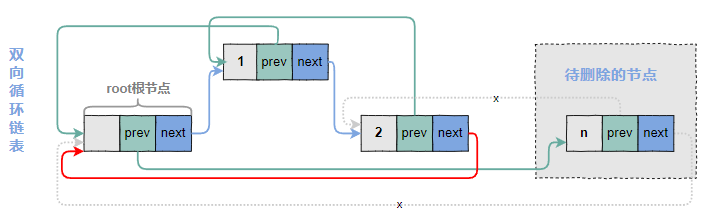
4.3.3 修改n节点的后一个节点的prev指针
即,下图为删除节点之后的状态。
五、性能压测
stdlib是目前标准库内置的双向循环链表, gstl是本文中提到的双向循环链表实现。benchmark逻辑是对两种链表的尾部节点添加数据,其中本文实现链表(gstl)性能相比标准库快一倍有余。
goos: darwin goarch: amd64 pkg: github.com/guonaihong/gstl/linkedlist cpu: Intel(R) Core(TM) i7-1068NG7 CPU @ 2.30GHz Benchmark_ListAdd_Stdlib-8 5918479 190.0 ns/op Benchmark_ListAdd_gstl-8 15942064 83.15 ns/op PASS ok github.com/guonaihong/gstl/linkedlist 3.157s
六、完整的源代码
双向循环链表的操作除了上文提到的插入、删除外,还有表与表的合并、 分割、获取某个index的值等等,实现时可以先在纸上画图,再写代码。如果还有疑问可以参考如下链接中的源码:https://github.com/guonaihong/gstl/tree/master/linkedlist
这篇关于golang泛型实现——双向循环链表的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
您可能喜欢
-
go-zero 框架的 RPC 服务 启动start和停止 底层是怎么实现的?-icode9专业技术文章分享12-20
-
Go-Zero 框架的 RPC 服务启动和停止的基本机制和过程是怎么实现的?-icode9专业技术文章分享12-19
-
怎么在golang中使用gRPC测试mock数据?-icode9专业技术文章分享12-18
-
掌握PageRank算法核心!你离Google优化高手只差一步!12-15
-
GORM 中的标签 gorm:"index"是什么?-icode9专业技术文章分享12-15
-
怎么在 Go 语言中获取 Open vSwitch (OVS) 的桥接信息(Bridge)?-icode9专业技术文章分享12-11
-
怎么用Go 语言的库来与 Open vSwitch 进行交互?-icode9专业技术文章分享12-11
-
怎么在 go-zero 项目中发送阿里云短信?-icode9专业技术文章分享12-11
-
怎么使用阿里云 Go SDK (alibaba-cloud-sdk-go) 发送短信?-icode9专业技术文章分享12-11
-
搭建个人博客网站之一、使用hugo创建个人博客网站12-10
-
MongoDB入门:新手快速上手指南12-04
-
goland 编辑器超过线的插件有哪些?-icode9专业技术文章分享11-29
-
go.mod的文件内容是什么?-icode9专业技术文章分享11-26
-
MongoDB身份认证机制揭秘!11-23
-
MongoDB教程:从入门到实践详解11-20
栏目导航
