Go教程
golang泛型实现--双hash表

一、写在前面
现代编程语言一般都提供了hash表的容器, 比如c++的std::hash_map, golang的map底层都使用了hash table, 是什么魔法让hash table在编程中占有一席之地,下面的内容会慢慢揭晓这个答案。
二、hash表的组成
在聊hash表的实现,先问一个问题。对于数组的访问可以使用索引,array[0], 就可以取得0索引的值, 取值的效率是O(1), 如果对于字符串类型如果也能实现类似的访问, 那不是很完美,先字符串转数字, 再变成array[0]取值,那效率也是O(1)。
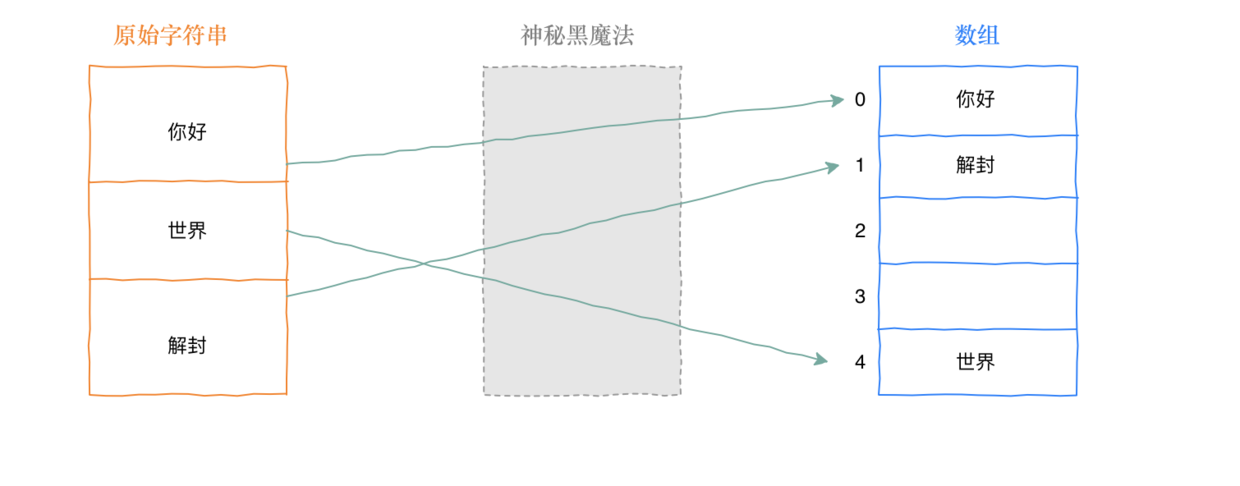
上图中神秘黑魔法就是hash函数,那么hash函数这么牛逼,有没有什么问题? hash函数最大的问题就是hash冲突,如下图, 面对不同的字符串对映射到同一个槽位。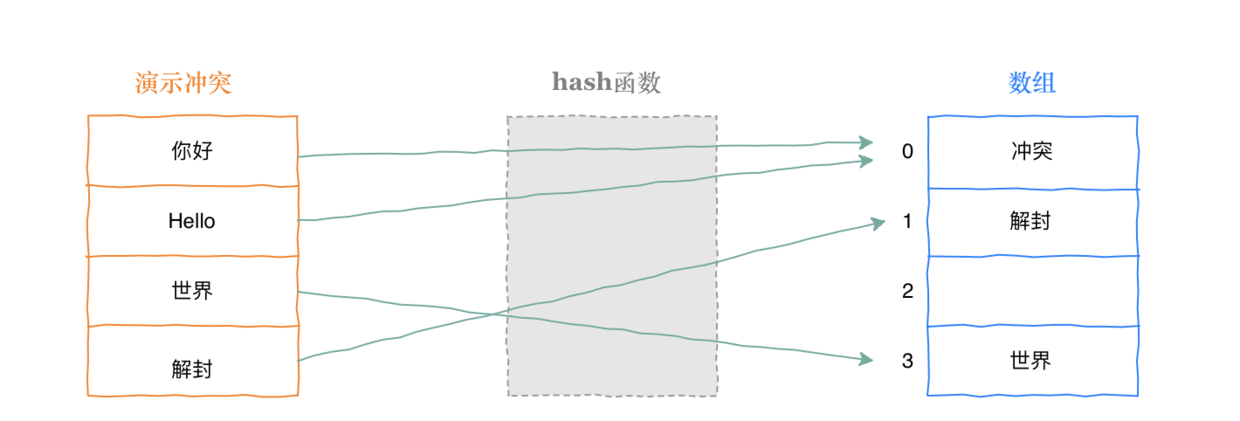
在工程实践中, 一般使用挂链的方式, 就是每个hash table里面的槽位都是链表,冲突之后就是把新节点加到链表的表尾。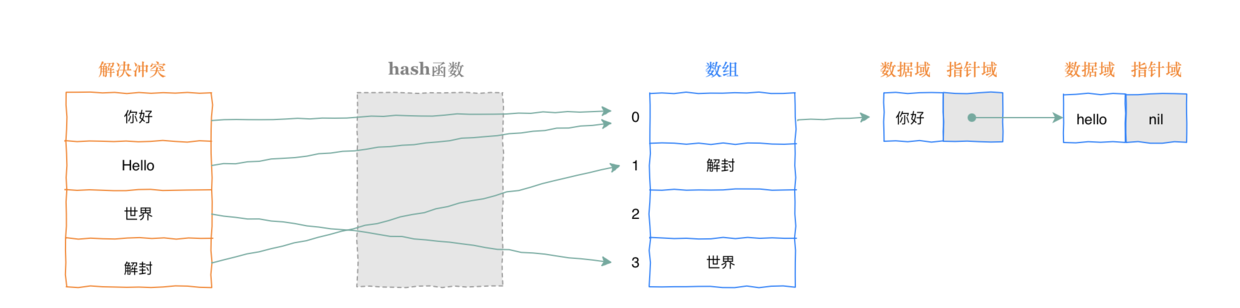
三、redis是如何实现双hash表的
3.1 冲突挂链的效率优化
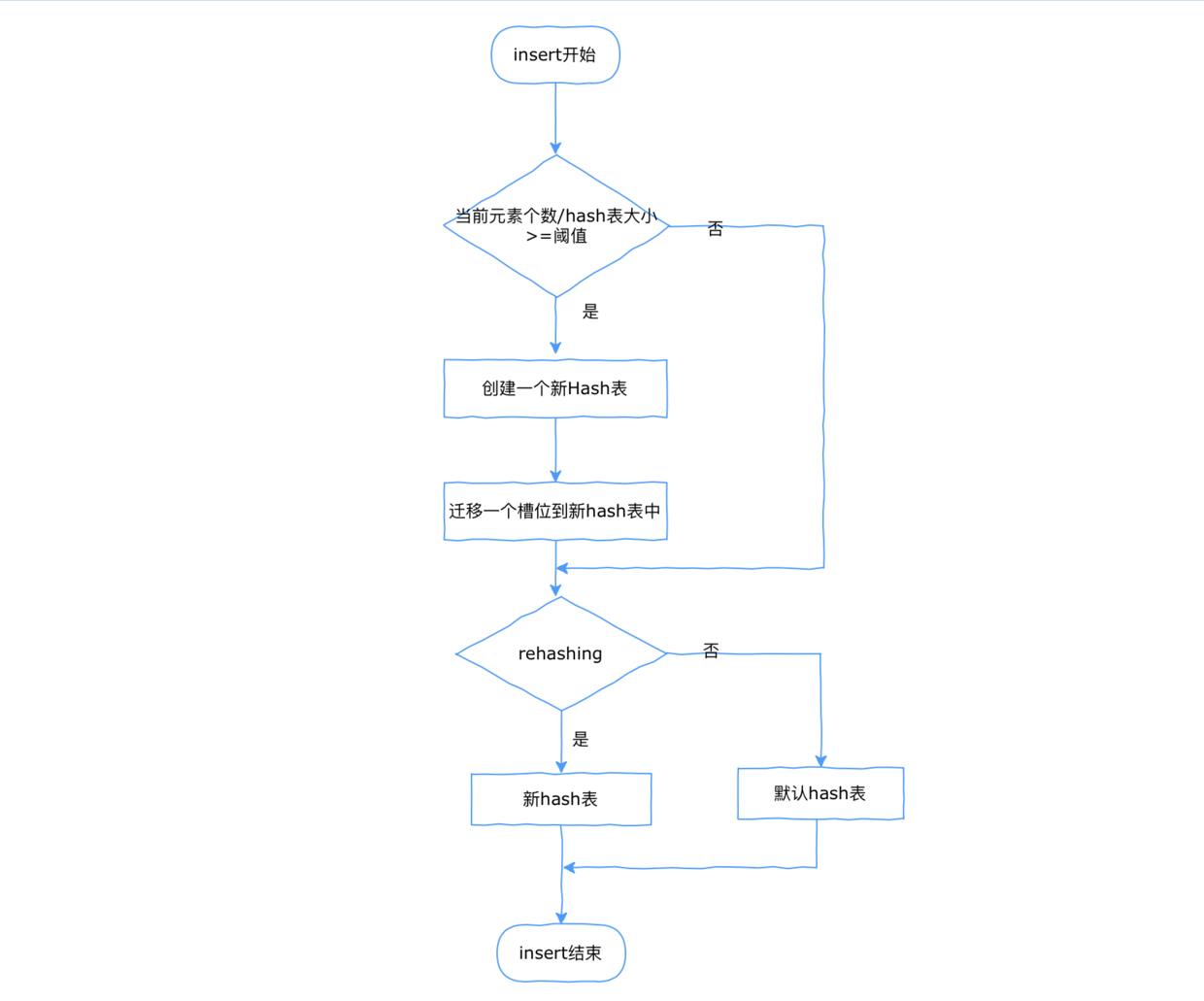
在一般hash table的实现中,聊到了使用挂链表的方式解决hash冲突。那有一个问题,随着数据越来越多, 冲突的概率也是越来越大。一个槽位里面挂1000个节点,还有啥效率可言。既然冲突不可避免, 那当槽位里面挂的节点超过一定比例, 就扩容一个新的hash table, 这个新旧同时存在的状态定为rehashing,更大的hash table,可以让冲突槽位的链表长度降低,从而提升效率。假如这个点可行, 后面无非是工程问题。
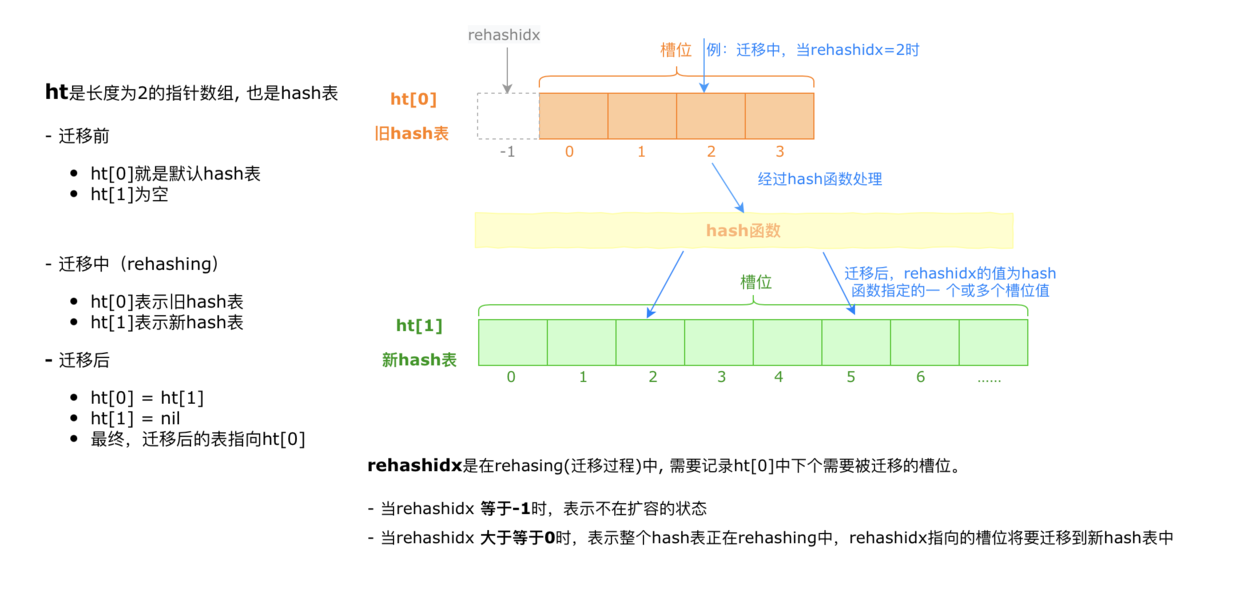
3.2 扩容流程
上面已经想到用双hash表的方式提升数据扩容之后的访问效率,那现在讨论insert流程,访问的过程是先访问旧的hash table,然后再访问新的hash table,删除同理。
注意:
这里面有个优化点, 为了尽量避免rehashing对业务造成影响,需要平均操作的影响,每次get delete set操作,都迁移一些数据到新hash表中,这也是redis hashtable里面的实现。
来个流程图说明下。
3.3 收缩流程
收缩流程可以在hash table内部做,也可以在外部做。
hash table一般实现是指针数据,假如对一个hash table存入100w元素,再删除掉。
说明:
不支持内部自动收缩的hash table,一般会浪费7.6MB的空间(64位机器) 8 * 1000000 / 1024/1024.0 = 7.62890625,这里的8是64位机器一个指针的字节数,除以一个1024单位是KB,再除以一个1024就是MB。浪费空间也不大,现代手机都动不动8GB以上RAM。
如果还是极在意这个点,可以提供一个收缩函数给外部调用。
四、核心代码
如下为golang移值redis双hash表的核心代码,供参考。
// 元素
type entry[K comparable, V any] struct {
key K
val V
next *entry[K, V]
}
type config struct {
hashFunc func(str string) uint64
cap int
}
// hash 表头
type HashMap[K comparable, V any] struct {
// 大多数情况, table[0]里就存在hash表元素的数据
// 大小一尘不变hash随着数据的增强效率会降低, rhashmap的实现是超过某阈值时
// table[1] 会先放新申请的hash表元素, 当table[0]都移动到table[1]时, table[1]赋值给table[0], 完成一次hash扩容
// 移动的操作都分摊到Get, Set, Delete操作中, 每次移动一个槽位, 或者跳运100个空桶(TODO修改代码, 需要修改这边的注释)
table [2][]*entry[K, V] //hash table
used [2]uint64 // 记录每个table里面存在的元素个数
sizeExp [2]int8 //记录exp
rehashidx int // rehashid目前的槽位
keySize int //key的长度
config
isKeyStr bool //是string类型的key, 或者不是
init bool
}
// 返回索引值和entry
func (h *HashMap[K, V]) findIndexAndEntry(key K) (i uint64, e *entry[K, V], err error) {
if err := h.expand(); err != nil {
return 0, nil, err
}
hashCode := h.calHash(key)
idx := uint64(0)
for table := 0; table < 2; table++ {
idx = hashCode & sizeMask(h.sizeExp[table])
head := h.table[table][idx]
for head != nil {
if key == head.key {
return idx, head, nil
}
head = head.next
}
if !h.isRehashing() {
break
}
}
return idx, nil, nil
}
// 设置, 这里可以看下insert的流程
func (h *HashMap[K, V]) Set(k K, v V) error {
h.lazyinit()
if h.isRehashing() {
h.rehash(1)
}
index, e, err := h.findIndexAndEntry(k)
if err != nil {
return err
}
idx := 0
if h.isRehashing() {
//如果在rehasing过程中, 如果这个key是第一次存入到hash table, 优先写入到新hash table中
idx = 1
}
// element存在, 这里是替换
if e != nil {
//e.key = k
e.val = v
return nil
}
e = &entry[K, V]{key: k, val: v}
e.next = h.table[idx][index]
h.table[idx][index] = e
h.used[idx]++
return nil
}
五、性能压测
如下为性能压测数据:
- 读取速度比标准库快一倍
- 写入速度较标准库每次慢0.018ns
goos: darwin goarch: amd64 pkg: github.com/guonaihong/gstl/rhashmap cpu: Intel(R) Core(TM) i7-1068NG7 CPU @ 2.30GHz BenchmarkGet-8 1000000000 0.4066 ns/op BenchmarkGetStd-8 1000000000 0.8333 ns/op PASS ok github.com/guonaihong/gstl/rhashmap 130.007s. 比标准库快一倍. goos: darwin goarch: amd64 pkg: github.com/guonaihong/gstl/rhashmap cpu: Intel(R) Core(TM) i7-1068NG7 CPU @ 2.30GHz BenchmarkSet-8 1000000000 0.1690 ns/op BenchmarkSetStd-8 1000000000 0.1470 ns/op PASS ok github.com/guonaihong/gstl/rhashmap 3.970s 五百万数据的Get操作时间
六、完整代码
如果对其余部分也感兴趣, 可以查看如下网址, 包含Get、 Set、 Delete完整的实现。
https://github.com/guonaihong/gstl/tree/master/rhashmap
-
go-zero 框架的 RPC 服务 启动start和停止 底层是怎么实现的?-icode9专业技术文章分享12-20
-
Go-Zero 框架的 RPC 服务启动和停止的基本机制和过程是怎么实现的?-icode9专业技术文章分享12-19
-
怎么在golang中使用gRPC测试mock数据?-icode9专业技术文章分享12-18
-
掌握PageRank算法核心!你离Google优化高手只差一步!12-15
-
GORM 中的标签 gorm:"index"是什么?-icode9专业技术文章分享12-15
-
怎么在 Go 语言中获取 Open vSwitch (OVS) 的桥接信息(Bridge)?-icode9专业技术文章分享12-11
-
怎么用Go 语言的库来与 Open vSwitch 进行交互?-icode9专业技术文章分享12-11
-
怎么在 go-zero 项目中发送阿里云短信?-icode9专业技术文章分享12-11
-
怎么使用阿里云 Go SDK (alibaba-cloud-sdk-go) 发送短信?-icode9专业技术文章分享12-11
-
搭建个人博客网站之一、使用hugo创建个人博客网站12-10
-
MongoDB入门:新手快速上手指南12-04
-
goland 编辑器超过线的插件有哪些?-icode9专业技术文章分享11-29
-
go.mod的文件内容是什么?-icode9专业技术文章分享11-26
-
MongoDB身份认证机制揭秘!11-23
-
MongoDB教程:从入门到实践详解11-20
