C/C++教程
MapReduce执行流程

数据处理总流程
MapReduce计算框架体现的是一个分治的思想。及将待处理的数据分片在每个数据分片上并行运行相同逻辑的map()函数,然后将每一个数据分片的处理结果汇集到reduce()函数进行规约整理,最后输出结果。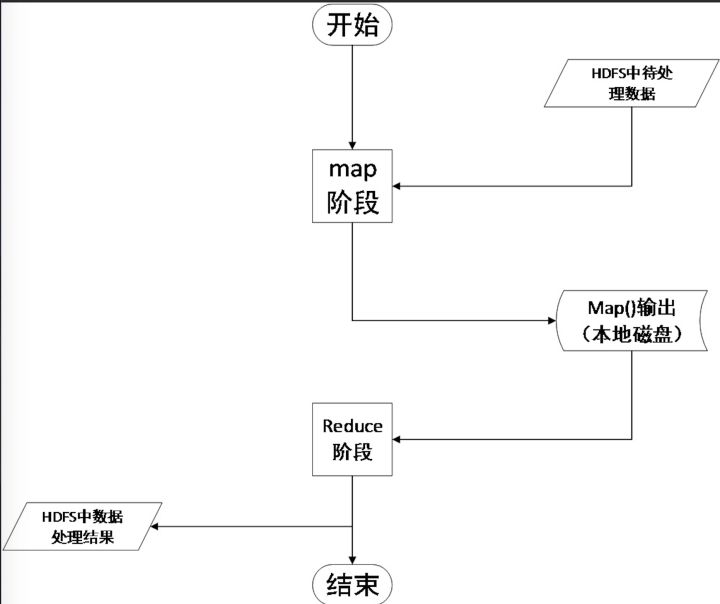
总体上来说MapReduce的处理流程从逻辑上看并不复杂。对于应用Hadoop进行数据分析的开发人员来说,只需实现map()方法和reduce()方法就能完成大部分的工作。正是因为Hadoop逻辑上和开发上都不复杂使它被广泛的应用于各行各业。
Map阶段
Map阶段更为详细的处理过程如图所示: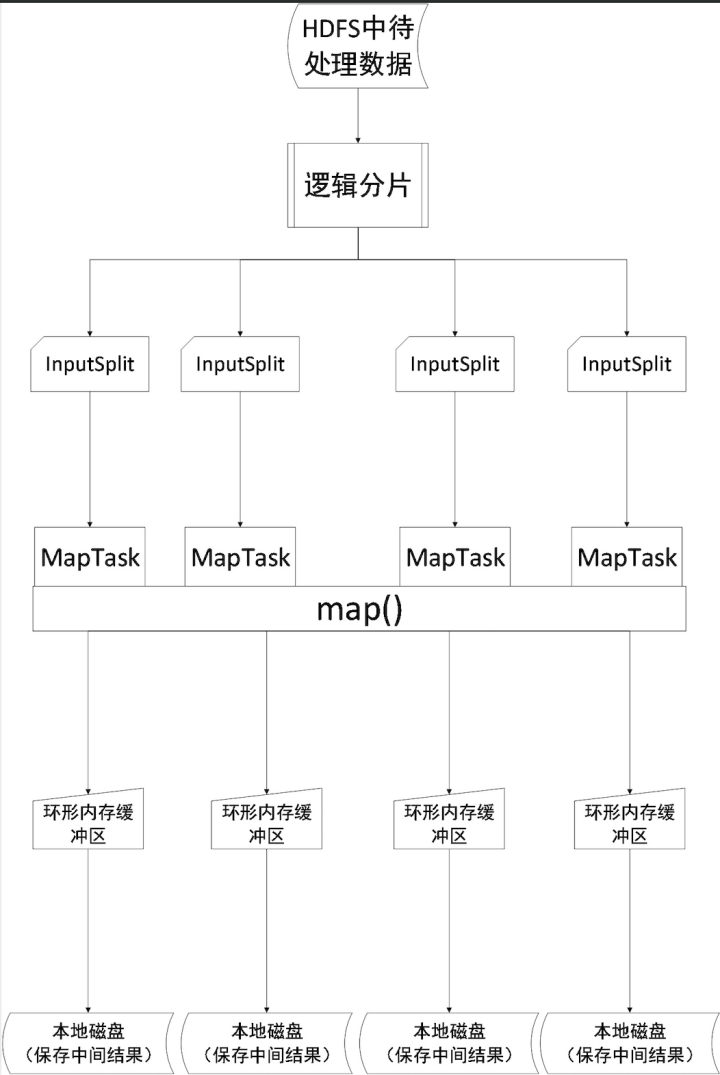
一般情况下用户需要处理分析的数据都在HDFS上。因此,MapReduce计算框架会是使用InputFormat(org.apache.hadoop.mapreduce)的子类将输入数据分片(InputSplit)。分片后的数据将作为MapTask的输入,MapTask会根据map()中的程序逻辑将数据分为K-V键值对。
为了更好的理解数据分片的过程和实现的逻辑,本文以InputFormat的一个子类FileInputFormat为例研究数据分片的过程。
FileInputFormat类将数据分片,然而这里所说的分片并不是将数据物理上分成多个数据块而是逻辑分片。
PS:并不是所有文件都可以分片,比如gzip,snappy压缩的文件就无法分割 .
数据逻辑分片的核心方法是getSplits():
public List<InputSplit> getSplits(JobContext job) throws IOException {
。。。。。。
List<InputSplit> splits = new ArrayList<InputSplit>();
List<FileStatus> files = listStatus(job);
for (FileStatus file: files) {
Path path = file.getPath();
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
if (isSplitable(job, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
。。。。。。
return splits;
}
其流程图如下所示: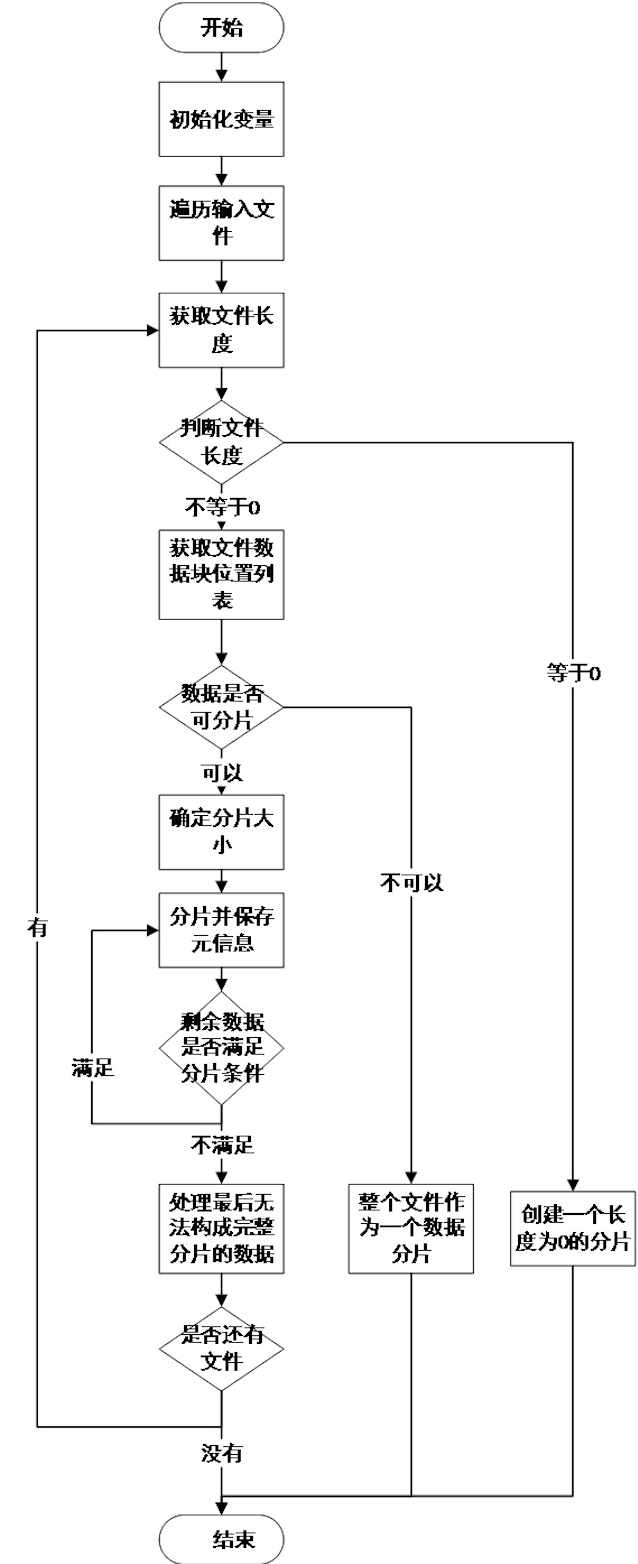
getSplits()中的BlockLocation类保存待处理文件的数据块信息,它包含了数据块所在DataNode的hostname,带有缓存副本的数据块所在的节点的hostname,访问数据块所在DataNode的IP:端口号,在拓扑网络中的绝对路径名,数据块在整个数据文件中的偏移量,数据块长度,是否是坏块。getSplits()会依据这些信息创建一个FileSplit完成一个逻辑分片,然后将所有的逻辑分片信息保存到List中。List中的InputSplit包含四个内容,文件的路径,文件开始的位置,文件结束的位置,数据块所在的host。
除了getSplits()方法另一比较重要的算法是computeSplitSize()方法,它负责确定数据分片的大小,数据分片的大小对程序的性能会有一定的影响,最好将数据分片的大小设置的和HDFS中数据分片的大小一致。确定分片大小的算法是:
Math.max(minSize, Math.min(maxSize, blockSize)) set mapred.max.split.size=256000000;2.x版本默认约是128M,我们集群配置的是256M set mapred.min.split.size=10000000;2.x版本默认是约10M,我们集群配置的是1 blockSize 在hdfs-site.xml参数dfs.block.size中配置,我们集群设置的是默认的是134217728=128M set mapred.map.tasks 对map task数量仅仅是参考的作用,我们集群默认的是2 对应的是set mapred.reduce.tasks,我们集群默认的是-1 reducer数量可能起作用的 hive.exec.reducers.bytes.per.reducer=256000000 hive.exec.reducers.max=1009 min( hive.exec.reducers.max ,总输入数据量/hive.exec.reducers.bytes.per.reducer)
其中,minSize是配置文件中设置的分片最小值,minSize则为最大值,blockSize为HDFS中数据块的大小。
完成逻辑分片后,FileInputFormat的各个子类向MapTask映射k-v键值对(如TextInputFormat)。FileInputFormat的子类是对数据分片中的数据进行处理。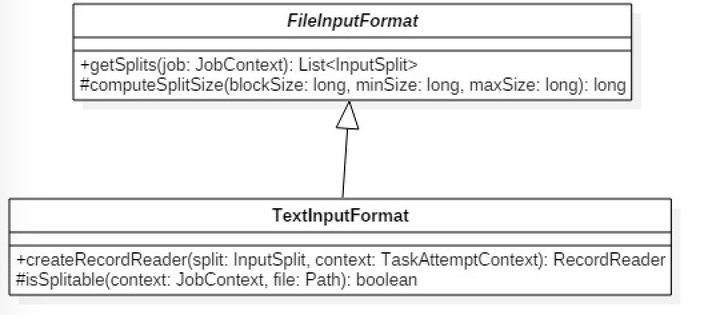
TextInputFormat中createRecorderReader()将InputSplit解析为k-v传给mapTask,该方法中用到了LineRecordReader它继承自RecordReader。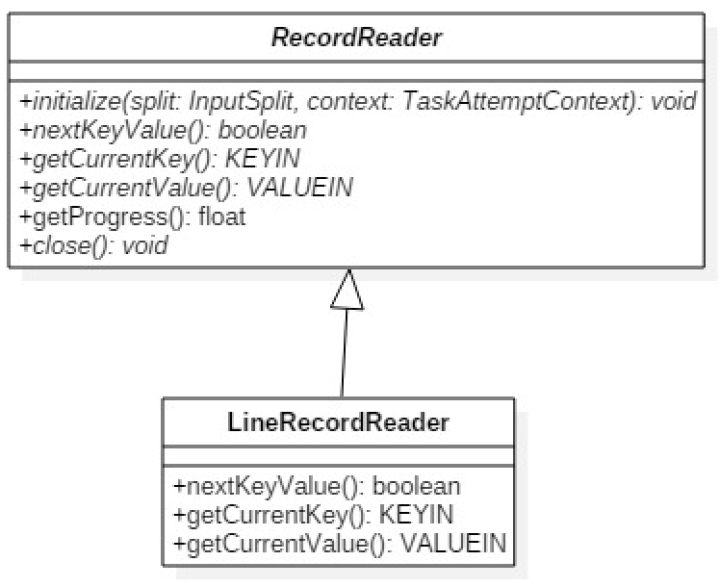
MapTask最终是通过调用nextKeyValue()方法来遍历分片中的数据并且将行数以及每一行的的数据分别作为key和value传递给map()方法。map()方法按照开发工程师编写的逻辑对输入的key和value进行处理后会组成新的k-v对然后写出到一个内存缓冲区中。
每个MapTask都有一个内存缓冲区,对缓冲区读写是典型的生产者消费者模式。这里内存缓冲区的结构设计对MapTask的IO效率有着直接的影响。Hadoop采用了环形内存缓冲区,当缓冲区数据量达到阈值消费者线程SpillThread开始将数据写出,于此同时充当生产者的writer()函数依然可以将处理完的数据写入到缓冲区中。生产者和消费者之间的同步是通过可重入互斥锁spillLock来完成的。
在写磁盘之前,线程会对缓冲区内的数据进行分区,以决定各个数据会传输到哪个Reduce中。而在每个分区中会按key进行排序(如果此时有个Combiner则它会在排序后的输出上运行一次,以压缩传输的数据)
mapred-site.xml 文件中 mapreduce.task.io .sort.mb=300M mapreduce.map.sort.spill.percent 配置的默认只0.8

用户可以通过继承Partitiner类并且实现getPartitioner()方法,从而定制自己的分区规则。默认的分区规则是通过key的hashCode来完成分区的。
环形缓冲区在达到溢写的阈值后,溢写到磁盘(每次溢写都会新建一个溢写文件)最后合并溢写文件,形成一个分区有序的中间结果。另外可以对中间结果进行压缩,以减少传输的数据量。
Reduce阶段
Reduce阶段更为详细的流程如下图所示: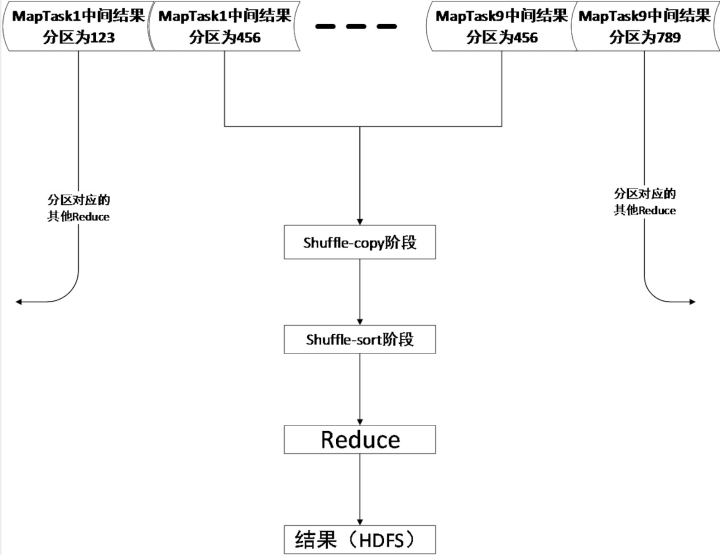
ReduceTask对数据进行规约的第一步就是从MapTask的输出磁盘上将数据拉取过来。这个过程重点分析shuffle类和Fetcher类。Shuffle类如下图所示: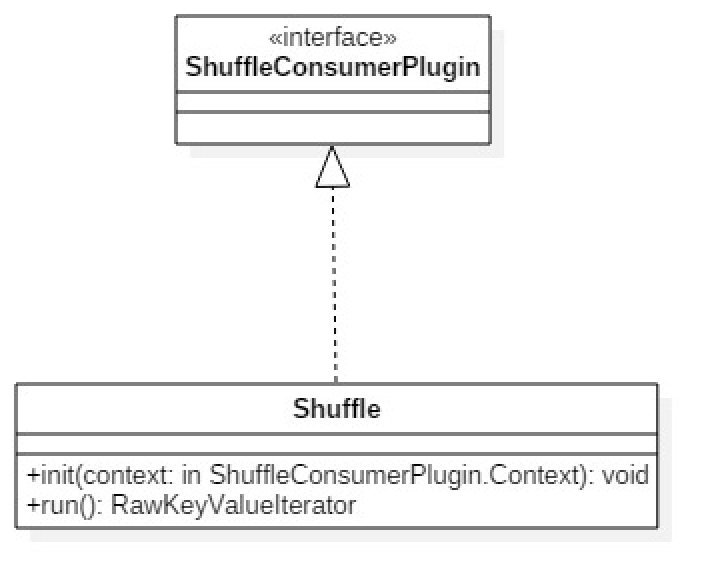
Shuffle类中的init()方法负责初始化Shuffle阶段需要的上下文,并且在Shuffle的最后阶段调用归并排序方法。Shuffle类的核心方法为run()方法。
public RawKeyValueIterator run() throws IOException, InterruptedException {
。。。。。。
// Start the map-output fetcher threads
Boolean isLocal = localMapFiles != null;
final int numFetchers = isLocal ? 1 :
jobConf.getint(MRJobConfig.SHUFFLE_PARALLEL_COPIES, 5);
Fetcher<K,V>[] fetchers = new Fetcher[numFetchers];
if (isLocal) {
fetchers[0] = new LocalFetcher<K, V>(jobConf, reduceId, scheduler,
merger, reporter, metrics, this, reduceTask.getShuffleSecret(),
localMapFiles);
fetchers[0].start();
} else {
for (int i=0; i < numFetchers; ++i) {
fetchers[i] = new Fetcher<K,V>(jobConf, reduceId, scheduler, merger,
reporter, metrics, this,reduceTask.getShuffleSecret());
fetchers[i].start();
}
}
。。。。。。
eventFetcher.shutDown();
for (Fetcher<K,V> fetcher : fetchers) {
fetcher.shutDown();
}
scheduler.close();
copyPhase.complete();
// copy is already complete
taskStatus.setPhase(TaskStatus.Phase.SORT);
reduceTask.statusUpdate(umbilical);
RawKeyValueIterator kvIter = null;
。。。。。。
return kvIter;
}
在run()方法中它是通过启动fetcher线程来拉取数据的。首先需要判断将要拉取的数据是否具有本地性,如果数据在本地则直接传入文件的地址否则创建fetcher线程来从其他节点远程拉取数据。Fetcher类类图如下: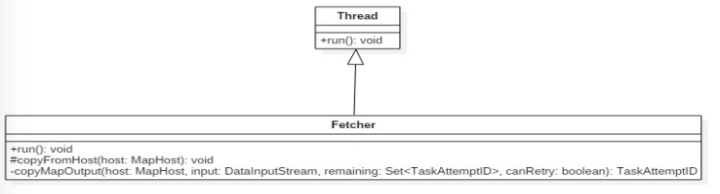
Fetcher继承自Thread类因此它重写了run()方法并且调用了copyFromHost()方法。copyFromHost()方法首先获取指定host上运行完成的MapTaskID然后循环的从Map段读取数据直到所有的数据都读取完成。
protected void copyFromHost(MapHost host) throws IOException {
。。。。。。
List<TaskAttemptID> maps = scheduler.getMapsForHost(host);
。。。。。。
while (!remaining.isEmpty() && failedTasks == null) {
try {
failedTasks = copyMapOutput(host, input, remaining, fetchRetryEnabled);
}
catch (IOException e) {
。。。。。
}
}
}
读取数据是在copyMapOutput()方法中完成的,方法中用到了ShufferHeader类它实现了Writable接口从而可以完成序列化与反序列化的工作,它调用readFields()方法从数据流中读取数据。
mapreduce.task.io .sort.factor =25
读取数据过程中需要注意的是,如果中间结果小则复制到内存缓冲区中否则复制到本地磁盘中。当内存缓冲区达到大小阈值或者文件数阈值则溢写到本地磁盘,与此同时后台线程会不停的合并溢写文件形成大的有序的文件。
在Shuffle-copy阶段进行的同时Shuffle-Sort也在处理数据,这个阶段就是针对内存中的数据和磁盘上的数据进行归并排序。
复制完所有的map输出做循环归并排序合并数据。举个例子更加好理解,若合并因子为10,50个输出文件,则合并5次,最后剩下5个文件不符合合并条件,则将这5个文件交给Reduce处理。
Reduce阶段会接收到已经排完序的k-v对,然后对k-v对进行逻辑处理最后输出结果k-v对到HDFS中.
-
安卓NDK 是什么?-icode9专业技术文章分享12-25
-
caddy 可以定义日志到 文件吗?-icode9专业技术文章分享12-25
-
wordfence如何设置密码规则?-icode9专业技术文章分享12-25
-
有哪些方法可以实现 DLL 文件路径的管理?-icode9专业技术文章分享12-25
-
错误信息 "At least one element in the source array could not be cast down to the destination array-icode9专业技术文章分享12-25
-
'flutter' 不是内部或外部命令,也不是可运行的程序 或批处理文件。错误信息提示什么意思?-icode9专业技术文章分享12-25
-
flutter项目 as提示Cannot resolve symbol 'embedding'提示什么意思?-icode9专业技术文章分享12-25
-
怎么切换 Git 项目的远程仓库地址?-icode9专业技术文章分享12-24
-
怎么更改 Git 远程仓库的名称?-icode9专业技术文章分享12-24
-
更改 Git 本地分支关联的远程分支是什么命令?-icode9专业技术文章分享12-24
-
uniapp 连接之后会被立马断开是什么原因?-icode9专业技术文章分享12-24
-
cdn 路径可以指定规则映射吗?-icode9专业技术文章分享12-24
-
CAP:Serverless?+AI?让应用开发更简单12-24
-
新能源车企如何通过CRM工具优化客户关系管理,增强客户忠诚度与品牌影响力12-23
-
原创tauri2.1+vite6.0+rust+arco客户端os平台系统|tauri2+rust桌面os管理12-23
