Java教程
理想汽车 HTAP 读流量优化指南

“没有任何一种数据库是银弹,业务场景的适配和降本增效永远是最重要的。” 数据库的性能优化能够帮助企业最大限度地利用系统资源,提高业务支撑能力和用户体验。本文为 TiDB 性能调优专题的第一篇,在这个专题中,我们将邀请更多 TiDBer 从实际的业务场景出发,分享 TiDB 优化的最佳实践。
作者介绍
郑赫扬(艺名:潜龙),理想汽车 DBA。负责公司分布式数据库的技术探索和业务场景落地,热爱开源。就职于金融、互联网教育、电商、新能源汽车等领域。
理想汽车作为豪华智能电动车品牌,以 “创造移动的家,创造幸福的家” 为使命。随着电动汽车业务的不断发展,公司业务既有 OLTP 也有 OLAP 的需求,因此需要一款 HTAP 数据库帮助公司实现实时业务决策。在 TUG 企业行 —— 走进 58 同城活动中,来自理想汽车的郑赫扬老师为大家介绍了理想汽车 HTAP 读流量在物理环境、业务环境、SQL 优化、热点问题、流量环境、版本及架构等方面的优化方案。以下为演讲实录。
理想汽车选择 TiDB 的理由
1)一栈式 HTAP:简化企业技术栈
TiDB 可以在一份数据源上同时支撑理想汽车 OLTP 和 OLAP 需求,不但能很好地支持实时数据落地存储,也能提供一体化的分析能力。另外,TiDB 也可以集成常见的大数据计算技术框架,比如 Spark、Flink 等等,可以使用其构建离线或者实时的数据仓库体系。2)解决 MySQL 传统拆库拆表问题
随着数据量的激增,单机数据库存不下怎么办?传统关系型数据库再扩展性问题,如果业务上已经用了 MySQL,那只能去做分库分表,或者利用中间件去转化,业务层要把代码改个遍。而 TiDB 与 MySQL 完全兼容,MySQL 应用无需修改便可直接运行。支持包括传统 RDBMS 和 NoSQL 的特性,可以随着数据增长而无缝水平扩展,只需要通过增加更多的机器来满足业务增长需求。3)简约但不简单的扩缩容
在经历产品更新的演进中,TiDB 4.0 和 5.0 版本基本上可以通过一些操作控制来灵活便捷地扩缩容,例如通过增加节点来线性扩展计算能力,存储节点同样可以根据存储需求不断进行扩容增加存储。在进行节点缩容时,对线上服务的影响也几乎无感知。4)完善的生态工具
目前理想汽车正在使用 DM(TiDB Data Migration)、TiCDC、TiSpark 等工具,在实际操作中也很强烈的感受到 TiDB 生态工具非常全面,这些生态工具还在不停地演进发展中,我们也在和官方小伙伴一起探索。5)丰富的场景支持
TiDB 在理想汽车的业务场景包括 OLAP 和 OLTP 两个维度。OLAP 包括离线数仓,实时数仓、DMP 平台(包括日常的决策调度、财务调度、报表等);OLTP 类的商业前端、算法训练(包括线上派单、交付、信息上报)等等。6)良好的社区环境
社区一直是培养 TiDB 不断发展的优渥土壤,在日常维护中一旦出现故障和难点,官方的技术人员就会马上处理,这也给理想汽车很大的信心把 TiDB 引入更多业务场景中使用。HTAP 读流量如何优化?
1)物理环境优化
 理想汽车目前把 TiDB 和 PD 集群的配置从原来的 16 核 32G 升级成了 32 核 128G。对于 TiDB 来说,支持 AP 类的大 SQL 可能要跑 7 - 8G 左右的内存,对内存的需求更高。为了解决 PD 的算力问题,我们会预估一下数仓的数据级,预估之后我们会再调大,例如一个单点的话,一个 PD 在 50 万以上可能有调度问题。所以我们可以调大 Region,来横向避免 Region 数量过多的情况。TiKV 刚开始使用的是 32C32G 2T 的百度云 SSD,现在和 TiFlash 一样全部采用 32 核 64G 的 4T NVMe 物理盘,这两个升级都是为了更好地统筹计算资源。
理想汽车目前把 TiDB 和 PD 集群的配置从原来的 16 核 32G 升级成了 32 核 128G。对于 TiDB 来说,支持 AP 类的大 SQL 可能要跑 7 - 8G 左右的内存,对内存的需求更高。为了解决 PD 的算力问题,我们会预估一下数仓的数据级,预估之后我们会再调大,例如一个单点的话,一个 PD 在 50 万以上可能有调度问题。所以我们可以调大 Region,来横向避免 Region 数量过多的情况。TiKV 刚开始使用的是 32C32G 2T 的百度云 SSD,现在和 TiFlash 一样全部采用 32 核 64G 的 4T NVMe 物理盘,这两个升级都是为了更好地统筹计算资源。2)业务环境优化
目前在理想汽车主要的 TiDB 集群都由 DM 同步上游的 MySQL,针对 DM 集群管理做了大量优化。做完之后,就是现在所有的上游 MySQL 主要库在 TiDB 里面都会有副本,因此 TiDB 就具备了 MySQL 从库 + 业务主库 + DMP 平台结果库的功能。
关键业务库表 DDL 变更和业务变更
- 上游 MySQL DDL 变更是否允许都会做一个规范,防止同步任务中断。
- 新业务完整的测试环境支持。
- 上游 MySQL 刷业务数据会有大量写流量,DM-sync 线程扩容。刷数据之前大家需要提前自动化,调整到高峰以应对流量冲击,因为下游有很多重要的业务,数据延迟的话会很有影响。
分类开发规范:
OLTP 开发规范:目前理想汽车的单个事务 SQL 结果集大小不能超过 20MB 结果集 50W 以下,或者 TiDB 计算节点内存小于 120MB,因为 TiDB 要对结果集做一个处理,可能最大扩大至 6 倍。
OLAP 开发规范:
复杂 SQL 大表走 TiFlash (一般 2KW),小表走 TiKV。
结果集最大值小于 7KW 或者 TiDB 计算结果内存小于 8G。
不断探索 TiDB 的 OLAP 性能边界。
DM 优化:
DDL 的问题是不支持变更,假如下游读流量业务受到影响,例如公司上游挂了很多个 MySQL,你希望做 MySQL 同步关联,你只要同步在一个 TiDB 集群里面,你也可以做一个小的数仓,调整方法,首先调整 TiDB 支持 DDL 变更。 再来看下 AP 类型的 SQL 实时数仓,最大内存是 8G,总共少了 7700 万的数据,执行时间是381 秒,是用 TiFlash 跑的。因为有的报表类或者是定时任务实时性不高,所以分类的话,还是 OK 的。我们现在好多类似的 SQL 在这么跑,TiFlash 5.0.2 集群版本,对于我们来说还可以,业务上比较稳定。
再来看下 AP 类型的 SQL 实时数仓,最大内存是 8G,总共少了 7700 万的数据,执行时间是381 秒,是用 TiFlash 跑的。因为有的报表类或者是定时任务实时性不高,所以分类的话,还是 OK 的。我们现在好多类似的 SQL 在这么跑,TiFlash 5.0.2 集群版本,对于我们来说还可以,业务上比较稳定。
3)SQL优化
首先得定一下规则
SQL 索引:
- OLTP 类:决定查询速度,所有 SQL 必须走索引
- OLAP 类:根据表的数量级和 SQL 复杂度
tidb_ddl_reorg_batch_size = 128
tidb_ddl_reorg_worker_cnt = 2
tidb_ddl_reorg_priority = PRIORITY_LOW
tidb_ddl_reorg_batch_size = 1024
tidb_ddl_reorg_worker_cnt = 16
tidb_ddl_reorg_priority = PRIORITY_HIGH
SQL 执行计划:
读表算子 TiDB 和 MySQL 不一样。MySQL 的话是 Type、Reader 之类的,但是 TiDB 是有分成算子再往下去读像 TableReader,点查大于索引覆盖,相当于 MySQL 的索引覆盖,相当于 TiDB 普通索引。读表算子优劣:PointGet/BatchPointGet>IndexReader(MySQL覆盖索引)> IndexLookupReader(普通索引)> TableReader。对于 TP 类型 SQL 来说尽可能消除 TableReader 读表算子或者减少结果集。
SQL 错误索引与统计信息:
TiDB 统计信息和表格健康度会直接影响你的索引,通常就不走了,所以你的业务突然就变慢了,只能说越来越小了。对于理想汽车来说,看表的健康度只要是大于 80% 的话,正确索引的概率基本上是可以保证的。表中至少 1000 行数据
默认 1 分钟无 DML
modify_count > tidb_auto_analyze_ratio参数(默认 0.5,设置成 0.8)
tidb_build_stats_concurrency(默认 4,资源充足可以调大)
tidb_distsql_scan_concurrency(默认 15,AP 30,TP 10)
tidb_index_serial_scan_concurrency(默认 1,TP 不调,AP 调成 4)
 解决方法:(1) 设置自动 analyze 时间 -tidb_auto_analyze_start_time(这里是 UTC 时间,如果是默认值00:00 + 0000,则早上 8 点开始执行)。所以建议设置时间为业务低峰 -8 小时,比如凌晨执行(16:00 + 0000),结束 tidb_auto_analyze_end_time 设置(23:59 + 0000)。(2) 如果仍然不准确,可以适当入侵绑定 SQL 计划或者强制走索引。
解决方法:(1) 设置自动 analyze 时间 -tidb_auto_analyze_start_time(这里是 UTC 时间,如果是默认值00:00 + 0000,则早上 8 点开始执行)。所以建议设置时间为业务低峰 -8 小时,比如凌晨执行(16:00 + 0000),结束 tidb_auto_analyze_end_time 设置(23:59 + 0000)。(2) 如果仍然不准确,可以适当入侵绑定 SQL 计划或者强制走索引。CREATE [GLOBAL | SESSION] BINDING FOR BindableStmt USING BindableStmt;
show stats_meta where table_name='xxx'
show stats_healthy where table_name='xxx'
show STATS_HISTOGRAMS where table_name='xxx' analyze table xxx;

SQL 逻辑优化
TiFlash 函数下推,大家一定要看一下,因为 TiFlash 不是所有的函数都下推。假如你走 TiFlash 数据量很大,又没有函数下推,代表你会在 TiDB 里面计算,这个过程可能就会比较耗时。建议对准官方的支持列表,(下图为部分截取)按照下推列表去规范 SQL。
4)热点问题优化
业务报慢 SQL,监控看单个节点 Coprocessor CPU(Coprocessor 是 TiKV 中读取 数据并计算的模块)异常飙升。(v3.0.14 未开启 Unified read pool,面板指标 TiKV - Details -> Thread CPU) - 看读热点,可以基于命令行去做一个脚本,比如 pt-ctl,看 hot read 和 hot write。(1) 去看 region 对应的表是哪张,获取热点的单个 region。(2) 4.0 以上 dashboard 热力图。(3) TiDB_HOT_REGIONS 表中记载了是那张表,有多少个字节。
- 看读热点,可以基于命令行去做一个脚本,比如 pt-ctl,看 hot read 和 hot write。(1) 去看 region 对应的表是哪张,获取热点的单个 region。(2) 4.0 以上 dashboard 热力图。(3) TiDB_HOT_REGIONS 表中记载了是那张表,有多少个字节。 然后手动 split Region,然后 hot read schedule 进行调度,CPU 使用资源下降,单个读热点 region 就消失了。
然后手动 split Region,然后 hot read schedule 进行调度,CPU 使用资源下降,单个读热点 region 就消失了。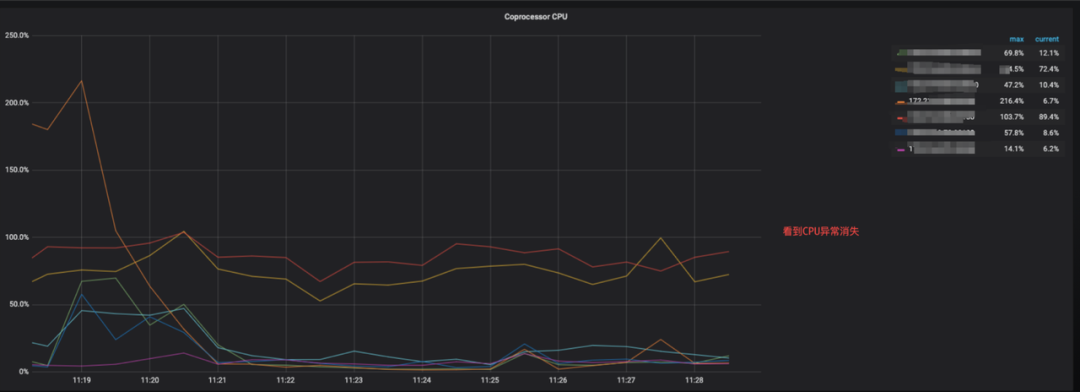
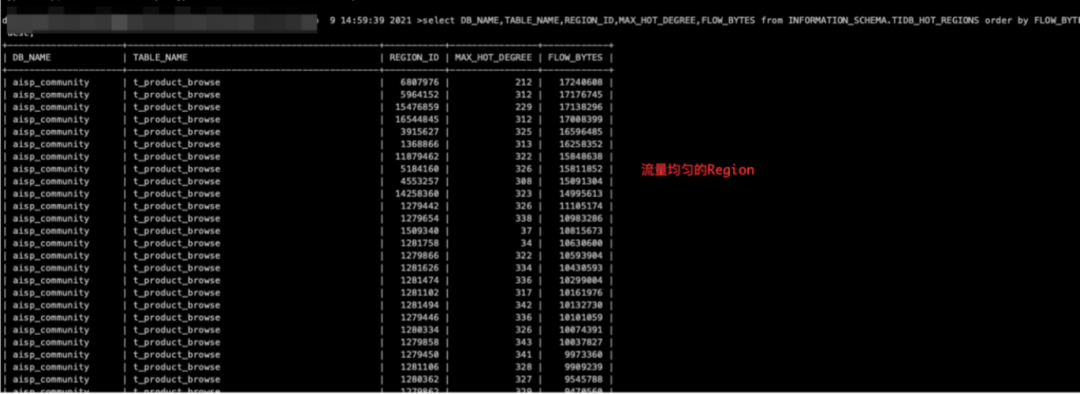 像监控、命令可以看最高的读取热点,每天都可以看,用命令行做一个筛选,找到对应的库表切割,切割完之后或者自动切割都可以,然后再观察。但是这个 Load base split 有的时候也有可能,也可以每天跑一遍检验它的结果。
像监控、命令可以看最高的读取热点,每天都可以看,用命令行做一个筛选,找到对应的库表切割,切割完之后或者自动切割都可以,然后再观察。但是这个 Load base split 有的时候也有可能,也可以每天跑一遍检验它的结果。
5)流量环境优化
第一,强制 SQL 里面走一些执行计划,执行内容可以限定一个参数,比如说 10 秒,或者内存 20M。我们针对线上 TP 类型是有的,比如下图这个业务的 SQL,就是点击类的报表系统,因为点击类的报表系统由于业务人员选的维度不同,最后的数据量级也不同,你可以设置一个限制,否则可能他点很多次的话,一个大的流量就会把你的集群冲击掉。 Optimizer Hints 熔断:
Optimizer Hints 熔断:执行时间: MAX_EXECUTION_TIME(N)
执行内存: MEMORY_QUOTA(N)
线上 TP SQL
长连接控制: pt-kill 控制杀掉 Sleep 线程或者重启 TiDB-Server(慎用)
执行内存: tidb_mem_quota_query
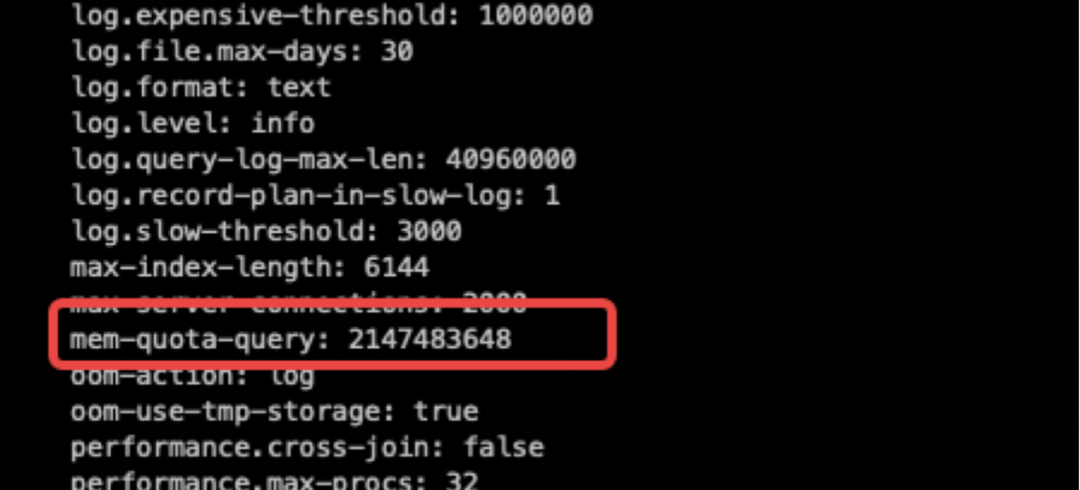 第三,理想汽车 AP 和 TP 读流量是分流的,TP 走的是 TiKV,AP 走的是 TiFlash,线上默认所有库表都加了 TiFlash 副本,有 3000 多个同步任务,大概是 3000 多张表,做一个流量分流。有的时候可能走 TiKV 更快,但是有的时候是一个整体切割,如下图所示,现在是两个流量分流了。
第三,理想汽车 AP 和 TP 读流量是分流的,TP 走的是 TiKV,AP 走的是 TiFlash,线上默认所有库表都加了 TiFlash 副本,有 3000 多个同步任务,大概是 3000 多张表,做一个流量分流。有的时候可能走 TiKV 更快,但是有的时候是一个整体切割,如下图所示,现在是两个流量分流了。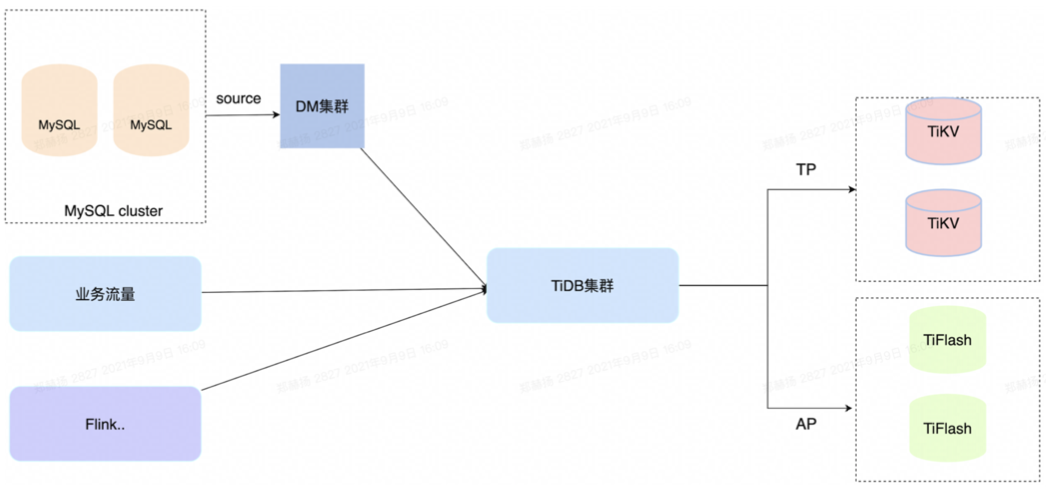
- AP 和 TP 的流量均摊,可以更改执行计划,但是我们用 Hint 更改执行计划,发现对 AP 类型非常不友好,测试的时候可能还会走到 TiKV 上面。SELECT *+ READ_FROM_STORAGE(TIFLASH[test1.t1,test2.t2]) */ t1.a FROM test1.t t1, test2.t t2 WHERE t1.a = t2.a;
- Session 会话控制,需要配合 rollback 回滚参数使用,强行走 TiFlash。set @@session.tidb_isolation_read_engines = "tiflash";
- TiFlash 下面有一个参数一定要设置,就是如果 TiFlash 发生查询错误,业务语句返回 TiKV 查询数据。确保万一 TiFlash 副本不能用了,还有读取数据的机会。set global tidb_allow_fallback_to_tikv='tiflash';
6)版本优化:
5.0 版本因为有 MPP 功能,我们去尝试从轻 AP 类型转到 AP 类型,看是否可以免除业务迁移的麻烦。我们的测试结果拿 2 台 TiFlash 做 MPP 测试作为参考,结果如下:2 台 TiFlash MPP 业务整体提升 35%。
业务 SQL 比较复杂,5.0.2 之后官方做了更多的下推优化。
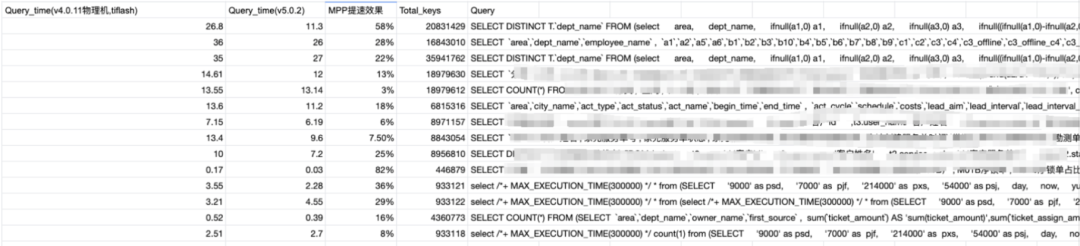 生产环境中,我们用 5 个 TiFlash node 跑,这是前后的流量对比图,整体有 32 秒,后来基本都降到了 1 秒以下。
生产环境中,我们用 5 个 TiFlash node 跑,这是前后的流量对比图,整体有 32 秒,后来基本都降到了 1 秒以下。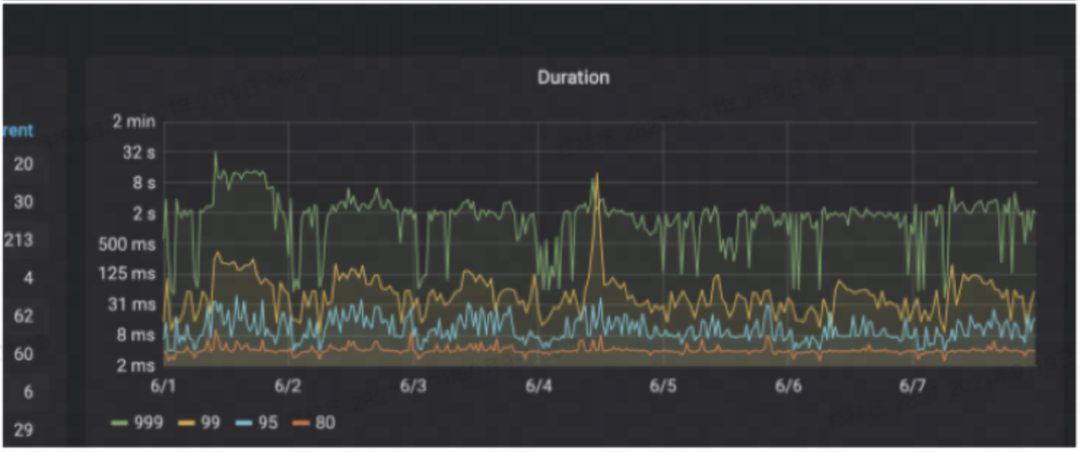
但是这个图很骗人的,大家千万不能相信这个 999,你真正需要优化的,可能就不在这个 999 里面,全在那个 0.01 里面。但是整体优化的效果还是很明显的,包括事务延迟执行 lantency,都降低了很多。整体的响应更具说服力,以下是一天时间内的对比图,大于 30 秒的 SQL 少了 87%,大于 60 秒的 SQL 也降低了 87%,大于 2 分钟的 SQL 同比降低了 99%,同样的流量,5.0.2 对我们整体的优化提升还是非常大的。
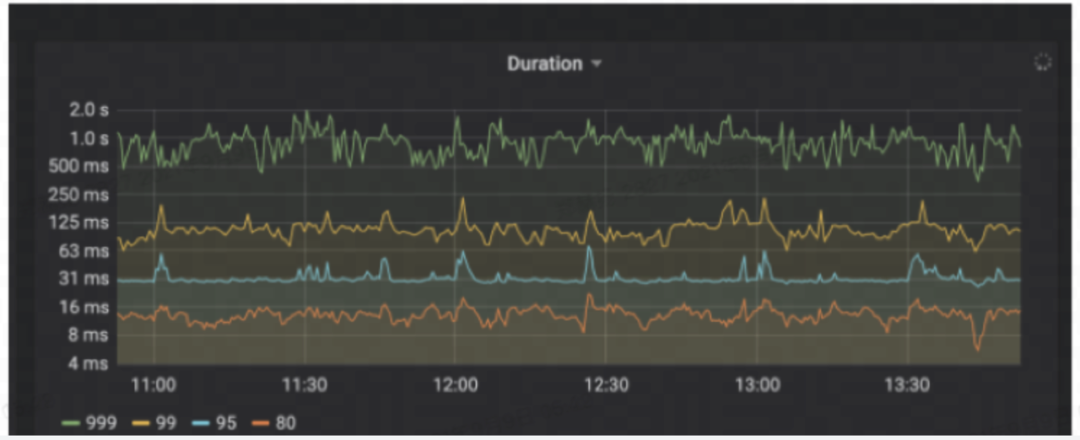
7)架构优化
架构优化的核心思想是用技术架构来转化 SQL 压力,下图是实时数仓的技术架构。上面是 DM 同步 MySQL 的数据源写入到 TiDB,TiDB 做一个 ODS 层之后,再导入到 TiCDC,之后通过分区打入到 Kafka,再分批消费进入 Flink,然后数据回写回 TiDB,提供实时数据和物化视图功能。因为 TiDB 本身不支持物化视图,可以在 Flink 里面解决这个技术难题,打造一个流批一体的实时数仓。
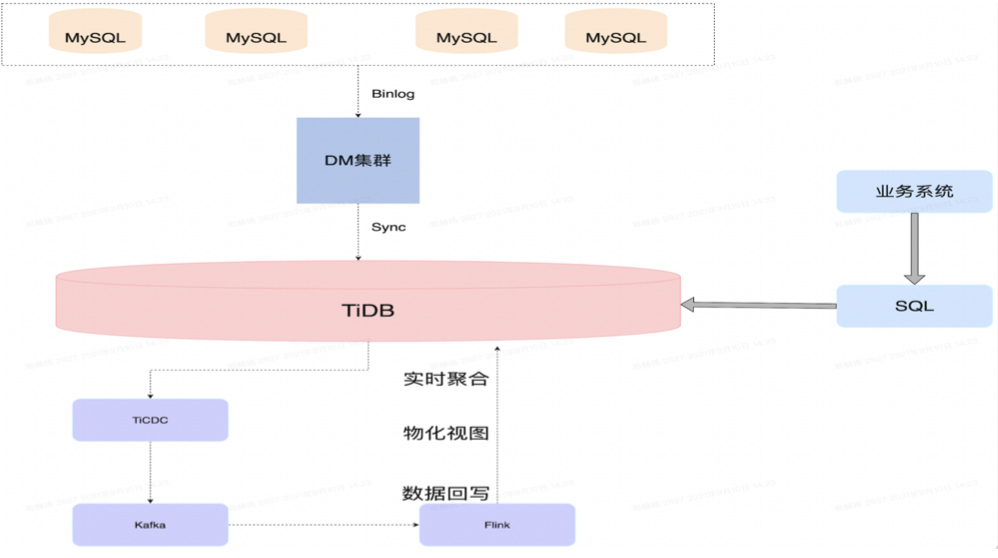 考虑到 OLAP 业务 SQL,我们选择了 TiKV 存储引擎,这个时候在 Flink 做完计算的表再写回 TiDB 的话,有一些 AP 的 SQL 就可以变成 TP 了,像 Table Reader 的算子有的时候可以变成 PointGet 或者是 BatchPointGet(点查或者表查),范围查询就会少很多,这样就在侧面缓解了压力。选择 TiFlash 就可以完成各种维度的聚合操作,实现离线报表和在线统计这些功能。这些都是我们已经实施上线的,但是还有几个使用问题,例如:
考虑到 OLAP 业务 SQL,我们选择了 TiKV 存储引擎,这个时候在 Flink 做完计算的表再写回 TiDB 的话,有一些 AP 的 SQL 就可以变成 TP 了,像 Table Reader 的算子有的时候可以变成 PointGet 或者是 BatchPointGet(点查或者表查),范围查询就会少很多,这样就在侧面缓解了压力。选择 TiFlash 就可以完成各种维度的聚合操作,实现离线报表和在线统计这些功能。这些都是我们已经实施上线的,但是还有几个使用问题,例如:在理想汽车的 DM 场景下,对表做了 rename 后 TiCDC 就无法识别了。因为 TiCDC 默认是以 Table ID 算的,表名一样,但是里面的 Table ID 已经变了,TiCDC 识别不了,就只能重启;
- 新增的 Kafka 分区,流量增大时增加 Kafka 分机,TiCDC 无法识别,也需要重启;
- V4.0.14 版本以前的 TiCDC 稳定性存在问题。
总结
业务发展推动技术革新,目前理想汽车的发展非常快。TiDB 的读流量优化是个全局视角,除了 SQL 本身外,官方提供了非常全面的优化手段,包括引擎、架构、执行计划、参数控制等。大家可以去按照自己的业务发展去做各种不同的尝试。
当然,优化都不能只看表面,TiDB Duration SQL 999 线是最常看的指标,但是也有欺骗性,但有时候最需要优化的是那 0.01%。最后,没有任何一种数据库是银弹,业务场景的适配和降本增效永远是最重要的。TiDB 更像是集百家之长,而不是专精于一技,在解决分库分表的基础上,基本覆盖所有场景和生态支持。理想汽车也希望能和 TiDB 一起走得更远。
-
Mybatis官方生成器资料详解与应用教程11-26
-
Mybatis一级缓存资料详解与实战教程11-26
-
Mybatis一级缓存资料详解:新手快速入门11-26
-
SpringBoot3+JDK17搭建后端资料详尽教程11-26
-
Springboot单体架构搭建资料:新手入门教程11-26
-
Springboot单体架构搭建资料详解与实战教程11-26
-
Springboot框架资料:新手入门教程11-26
-
Springboot企业级开发资料入门教程11-26
-
SpringBoot企业级开发资料详解与实战教程11-26
-
Springboot微服务资料:新手入门全攻略11-26
-
SpringBoot微服务资料入门教程11-26
-
Springboot项目开发资料详解与入门指南11-26
-
SpringBoot项目开发资料详解入门教程11-26
-
SpringBoot应用的生产发布资料详解11-26
-
手写消息中间件:从零开始的指南11-26
