C/C++教程
Kafka成长记6:Producer如何将消息放入到内存缓冲区(上)


之前我们分析了Producer的配置解析、组件分析、拉取元数据、消息的初步序列化方式、消息的路由策略。如下图:
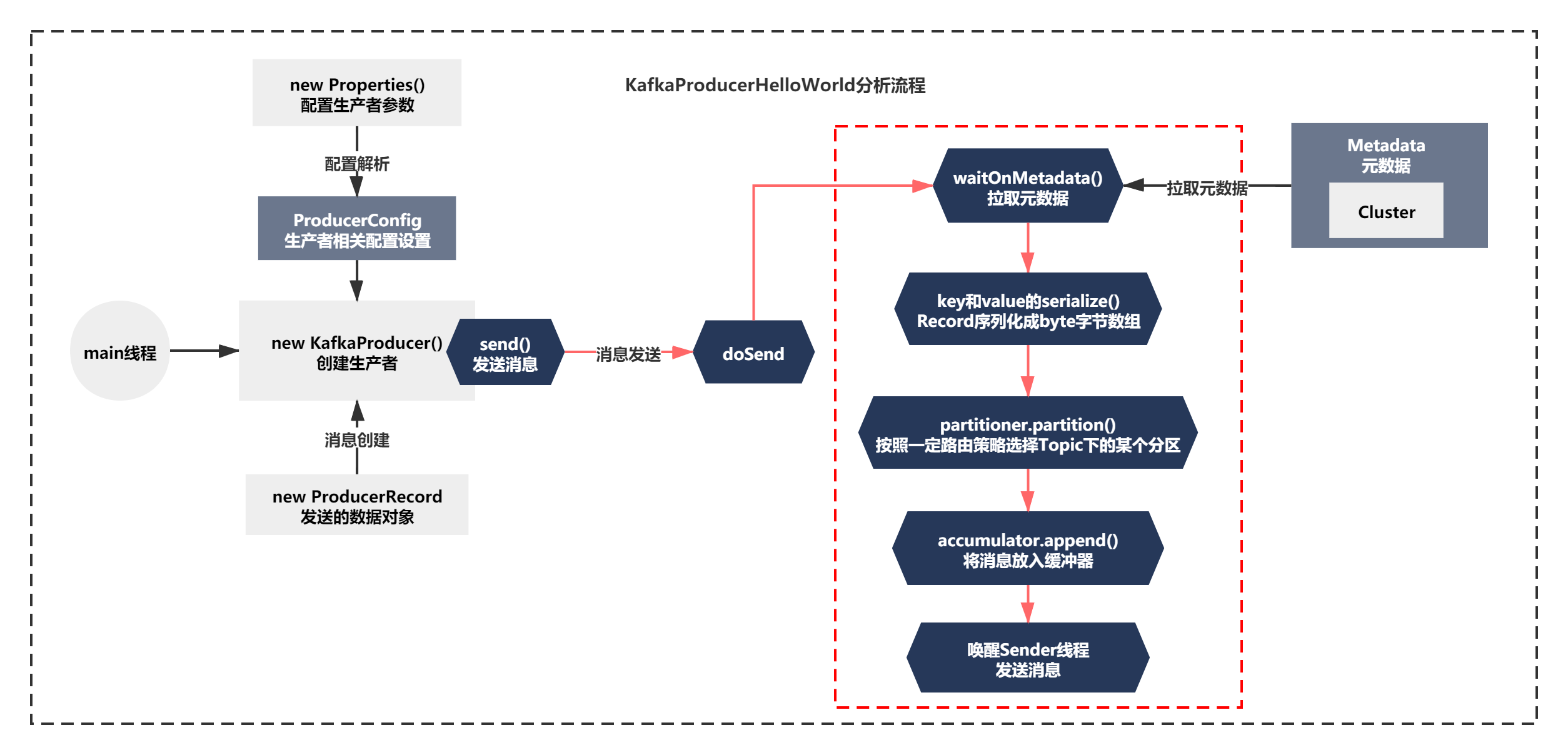
这一节我们继续分析发送消息的内存缓冲器原理—RecordAccumulator.append()。
如何将消息放入内存缓冲器的?
在doSend中的,拉取元数据、消息的初步序列化方式、消息的路由策略之后就是accumulator.append()。
如下代码所示:(去除了多余的日志和异常处理,截取了核心代码)
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
//拉取元数据、消息的初步序列化方式、消息的路由策略
long waitedOnMetadataMs = waitOnMetadata(record.topic(), this.maxBlockTimeMs);
long remainingWaitMs = Math.max(0, this.maxBlockTimeMs - waitedOnMetadataMs);
byte[] serializedKey = keySerializer.serialize(record.topic(), record.key());
byte[] serializedValue = valueSerializer.serialize(record.topic(), record.value());
int serializedSize = Records.LOG_OVERHEAD + Record.recordSize(serializedKey, serializedValue);
ensureValidRecordSize(serializedSize);
tp = new TopicPartition(record.topic(), partition);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
Callback interceptCallback = this.interceptors == null ?
callback : new InterceptorCallback<>(callback, this.interceptors, tp);
// 将路由结果、初步序列化的消息放入到消息内存缓冲器中
RecordAccumulator.RecordAppendResult result =
accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
this.sender.wakeup();
}
return result.future;
} catch (Exception e) {
throw e;
}
//省略其他各种异常捕获
}
accumulator.append() 它主要是将路由结果、初步序列化的消息放入到消息内存缓冲器中。
分析如何将消息放入内存缓冲器之前,需要回顾下它内部的基本结构。之前组件分析的时候,我们初步分析过RecordAccumulator的大体结构,如下图:
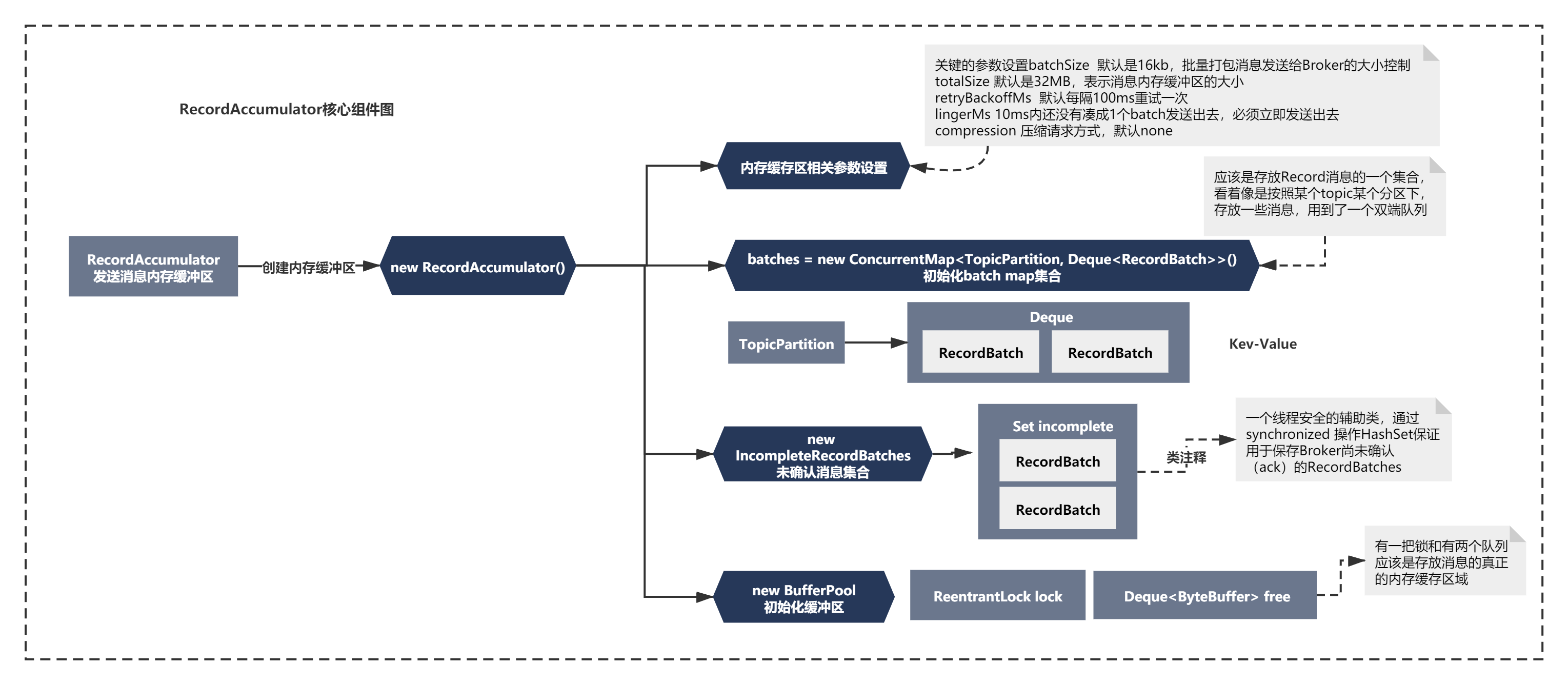
1)设置了一些参数 batchSize、totalSize、retryBackoffMs、lingerMs、compression等
2)初始化了一些数据结构,比如batches是一个 new CopyOnWriteMap<>()
3)初始化了BufferPool和IncompleteRecordBatches
回顾了RecordAccumulator这个组件之后,我们就来看看到底如何将消息放入内存缓冲器的数据结构中的。
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
// We keep track of the number of appending thread to make sure we do not miss batches in
// abortIncompleteBatches().
appendsInProgress.incrementAndGet();
try {
// check if we have an in-progress batch
Deque<RecordBatch> dq = getOrCreateDeque(tp);
synchronized (dq) {
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
if (appendResult != null)
return appendResult;
}
// we don't have an in-progress record batch try to allocate a new batch
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
if (appendResult != null) {
// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...
free.deallocate(buffer);
return appendResult;
}
MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize);
RecordBatch batch = new RecordBatch(tp, records, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
return new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true);
}
} finally {
appendsInProgress.decrementAndGet();
}
}
整个方法的脉络,看着逻辑比较多,涉及了很多数据结构,我们一步一步来分析下。第一次看的话,大体你可以梳理如下脉络:
1)getOrCreateDeque 这个方法应该是才创建一个双端队列,队列放的每一个元素不是单条消息Record,而是消息的集合RecordBatch。
2)free.allocate 应该是在分配内存缓冲器中的内存
3)tryAppend 应该是将消息放入内存中
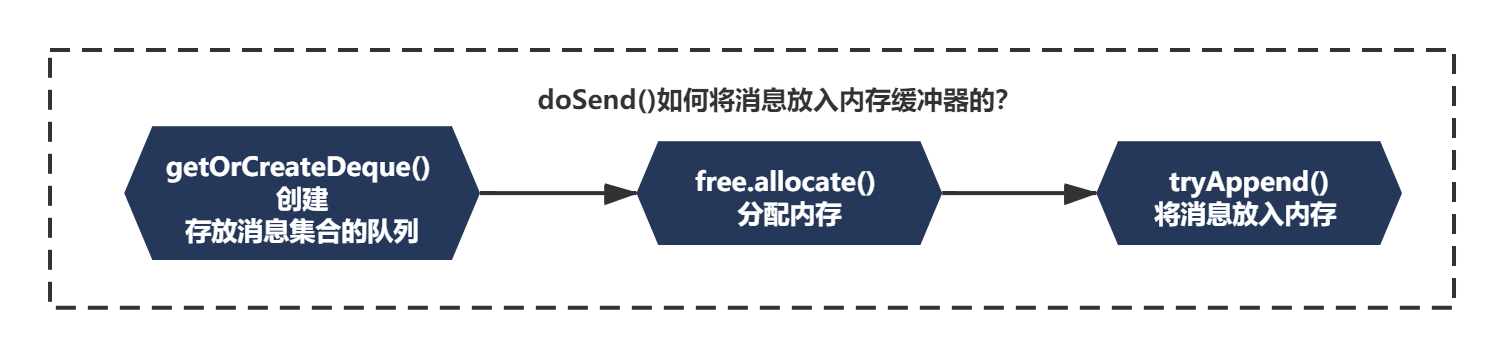
创建存放消息集合的队列
在将消息放入内存缓冲器之前,首先通过getOrCreateDeque 创建的是一个存放消息集合的队列。代码如下:
private final ConcurrentMap<TopicPartition, Deque<RecordBatch>> batches;
public RecordAccumulator(int batchSize,
long totalSize,
CompressionType compression,
long lingerMs,
long retryBackoffMs,
Metrics metrics,
Time time) {
//省略...
this.batches = new CopyOnWriteMap<>();
//省略...
}
/**
* Get the deque for the given topic-partition, creating it if necessary.
*/
private Deque<RecordBatch> getOrCreateDeque(TopicPartition tp) {
Deque<RecordBatch> d = this.batches.get(tp);
if (d != null)
return d;
d = new ArrayDeque<>();
Deque<RecordBatch> previous = this.batches.putIfAbsent(tp, d);
if (previous == null)
return d;
else
return previous;
}
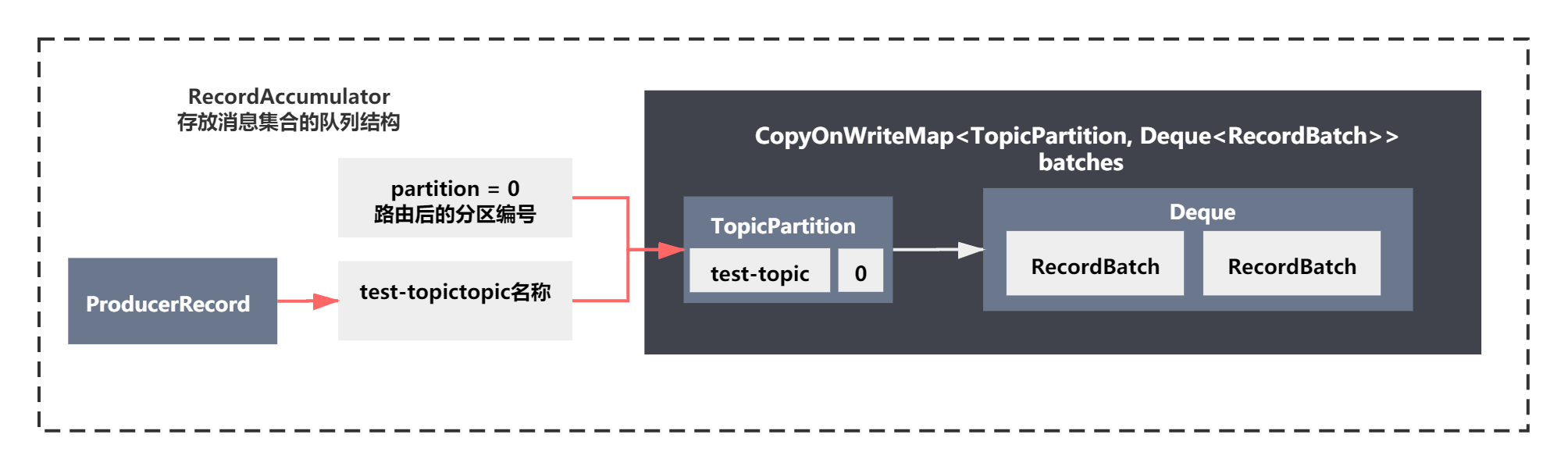
这个创建的内存结构可以看到,是**一个变量 batches,它是一个CopyOnWriteMap。**这个数据结构之前我们组件图初步分析过。再结合这段代码,不难理解它的脉络:
这个map主要根据Topic分区信息作为key,value是一个队列核心数据结构是RecordBatch,由于是第一次给某个topic分区发送的消息,value为空,需要初始化队列,否则说明曾经给这个topic的分区发送给数据,value非空,直接返回之前的队列。
由于我们这里是第一次向test-topic发送消息,所以可以得到下图的数据结构:
之后执行了一段加锁逻辑,之前提到,tryAppend应该是将消息放入内存中。但是由于队列是刚创建的,deque.peekLast();肯定是空,所以这段加锁的代码不会执行。
synchronized (dq) {
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
if (appendResult != null)
return appendResult;
}
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Callback callback, Deque<RecordBatch> deque){
RecordBatch last = deque.peekLast();
if (last != null) {
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, callback, time.milliseconds());
if (future == null)
last.records.close();
else
return new RecordAppendResult(future, deque.size() > 1 || last.records.isFull(), false);
}
return null;
}
但是到这里你会发现代码一个明显的特点,使用了synchronized加锁和线程安全的内存结构CopyOnWriteMap,这些都是明显线程安全的控制。
为什么呢?因为同一个Producer可以使用多线程进行发送消息,必然要考虑线程安全的很多东西。
为什么选用CopyOnWriteMap,而不用ConcurrentHashMap呢?你可以思考下。(这里给个提示,JDK成长记提到过,CopyOnWriteMap它的底层是写时复制,适合读多写少的场景)
synchronized加锁代码块使用了,分段加锁,并没有暴力的在方法上加synchronized。这也是一个使用亮点。
写在结尾的话
到这里,你会发现在中间件会大量的见到并发包下的组件的使用,工作中你用到可能都是凤毛麟角,这些组件的使用是我们研究中间件源码值得学习的一点。
你一定要多思考为什么,不要停留在是什么,怎么用上,这个思想需要刻意训练,希望你可以慢慢养成。
好了,今天的内容就到这里,之前有同学反馈,每一节的只是太过于干了,实实在在的干货!看起来有时候会比较费劲,所以之后的章节尽量会避免上万字的大章节,会控制在6000字左右。
另外,除了成长记外,我偶尔也会分享我自己的故事和行业中遇见的事情,希望大家从我的经历中可以有另一番成长和收获,比如我是如何学习和提升技术的?我是如何画图的?我如何做技术分享的等等。
-
安卓NDK 是什么?-icode9专业技术文章分享12-25
-
caddy 可以定义日志到 文件吗?-icode9专业技术文章分享12-25
-
wordfence如何设置密码规则?-icode9专业技术文章分享12-25
-
有哪些方法可以实现 DLL 文件路径的管理?-icode9专业技术文章分享12-25
-
错误信息 "At least one element in the source array could not be cast down to the destination array-icode9专业技术文章分享12-25
-
'flutter' 不是内部或外部命令,也不是可运行的程序 或批处理文件。错误信息提示什么意思?-icode9专业技术文章分享12-25
-
flutter项目 as提示Cannot resolve symbol 'embedding'提示什么意思?-icode9专业技术文章分享12-25
-
怎么切换 Git 项目的远程仓库地址?-icode9专业技术文章分享12-24
-
怎么更改 Git 远程仓库的名称?-icode9专业技术文章分享12-24
-
更改 Git 本地分支关联的远程分支是什么命令?-icode9专业技术文章分享12-24
-
uniapp 连接之后会被立马断开是什么原因?-icode9专业技术文章分享12-24
-
cdn 路径可以指定规则映射吗?-icode9专业技术文章分享12-24
-
CAP:Serverless?+AI?让应用开发更简单12-24
-
新能源车企如何通过CRM工具优化客户关系管理,增强客户忠诚度与品牌影响力12-23
-
原创tauri2.1+vite6.0+rust+arco客户端os平台系统|tauri2+rust桌面os管理12-23
