C/C++教程
Kafka成长记1:从HelloWorld开始研究Kafka Producer源码原理


成长记不会介绍太多一些kafka的基础知识,如果有需要的话,之后会有专门的《小白起步营》。成长记的默认大家对kafka的一些概念是熟知的、默认也是会基本Kafka的部署的。当然为了照顾一些小白,第一次涉及的知识我会简单介绍和解释的,熟悉的人就当回顾吧。简单的事情重复做有时也是好事。
Kafka成长记会直接从三个方面开始探索,Producer、Broker、Comsumer。过程中,根据场景会使用之前ZK和JDK成长记介绍源码分析方法。话不多说,让我们直接开始第一节的内容吧!
我们之前研究ZK主要是使用的场景法,找到一些核心入口开始分析的。研究Kafka的源码时候,我们也可以参考之前的方法。不过这次我们不直接从Broker服务端节点入手,先从Producer开始入手研究。会用到一些新的分析源码的思想和方法。
要想分析Kafka Producer的源码原理,首先肯定得有一个入口或者下手的地方。很多人使用Kafka肯定都是从一个Demo开始的。自己部署一台Kafka,之后发送下消息,之后在自己消费一条消息。
KafkaProducerHelloWorld
所以我们就从最简单的一个Kafka Producer的Demo开始,从一个KafkaProducerHelloWorld例子开始Kafka源码原理的探索。
HelloWorld的代码如下:
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
/**
* @author fanmao
*/
public class KafkaProducerHelloWorld {
public static void main(String[] args) throws Exception {
//配置Kafka的一些参数
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.30.1:9092");
// 创建一个Producer实例
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 封装一条消息
ProducerRecord<String, String> record = new ProducerRecord<>(
"test-topic", "test-key", "test-value");
// 同步方式发送消息,会阻塞在这里,直到发送完成
// producer.send(record).get();
// 异步方式发送消息,不阻塞,设置一个监听回调函数即可
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception == null) {
System.out.println("消息发送成功");
} else {
System.out.println("消息发送异常");
}
}
});
Thread.sleep(5 * 1000);
// 退出producer
producer.close();
}
}
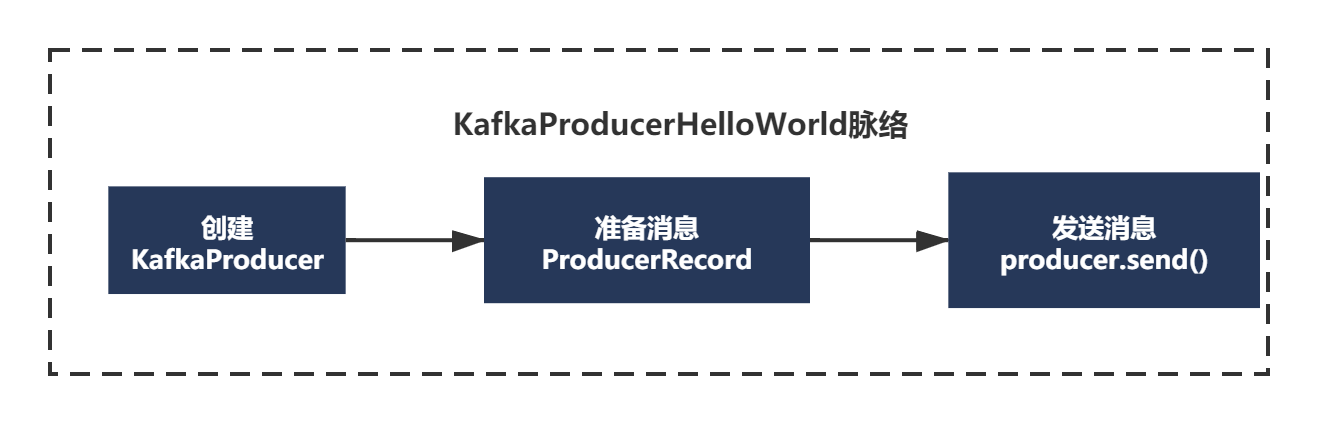
上面的代码例子,虽然非常简单,但是也有自己的脉络。
1)创建KafkaProducer
2)准备消息ProducerRecord
3)发送消息producer.send()
简单画个图:
这里多说一点,我之前在Zookeeper成长记5提到过源码版本的选择和看源码的方式,这里我就不重复说了。直接将选择后的结果告诉大家,我选择的是kafka-0.10.0.1版本。
所以客户端使用的依赖的GAV(Group-ArtifactId-Version) 是 org.apache.kafka-kafka-clients-0.10.0.1。POM如下所示:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.mfm.learn</groupId> <artifactId>learn-kafka</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>learn-kafka</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.10.0.1</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.72</version> </dependency> </dependencies> <build> </build> </project>
KafkaProducer的创建
上面KafkaProducerHelloWorld脉络既然主要分了三步,那我们一步一步来看,首先就是KafkaProducer的创建。我们来一起看看它初始化什么东西?
这里问大家一个问题,这种构造方法的源码原理,一般分析的结果用什么方法会比较好?
没错,组件图或者源码脉络图分析最容易理解了。我们只需要有个大致印象就行。方法有了,一般又会用什么思想呢?连蒙带猜、看看注释,猜测组件的作用,是不是?
好了让我们来试试吧!
new KafkaProducer的代码如下:
/**
* A producer is instantiated by providing a set of key-value pairs as configuration. Valid configuration strings
* are documented <a href="http://kafka.apache.org/documentation.html#producerconfigs">here</a>.
* @param properties The producer configs
*/
public KafkaProducer(Properties properties) {
this(new ProducerConfig(properties), null, null);
}
构造函数中调用了一个重载的构造函数,我们不着急往下看,先看下注释。大体可以知道,这个构造函数,入参是可以通过Properties设置一些参数,之后肯定是讲这个参数转换成了ProducerConfig对象进行封装,肯定有一定的转换方法。你还记得Zookeeper成长记中是不是也有类似的操作,封装了一个QuorumPeerConfig对象。其实分析多了很多源码,你就逐渐有经验了,更好的能驾轻就熟的分析任何一个源码原理了。这才是我想要让大家学会的,而不是它如何解析,封装成配置对象的。
我们接着分析,那么接下里就是两条路了,看下重载的构造方法或者是 ProducerConfig是如何解析的。如下:
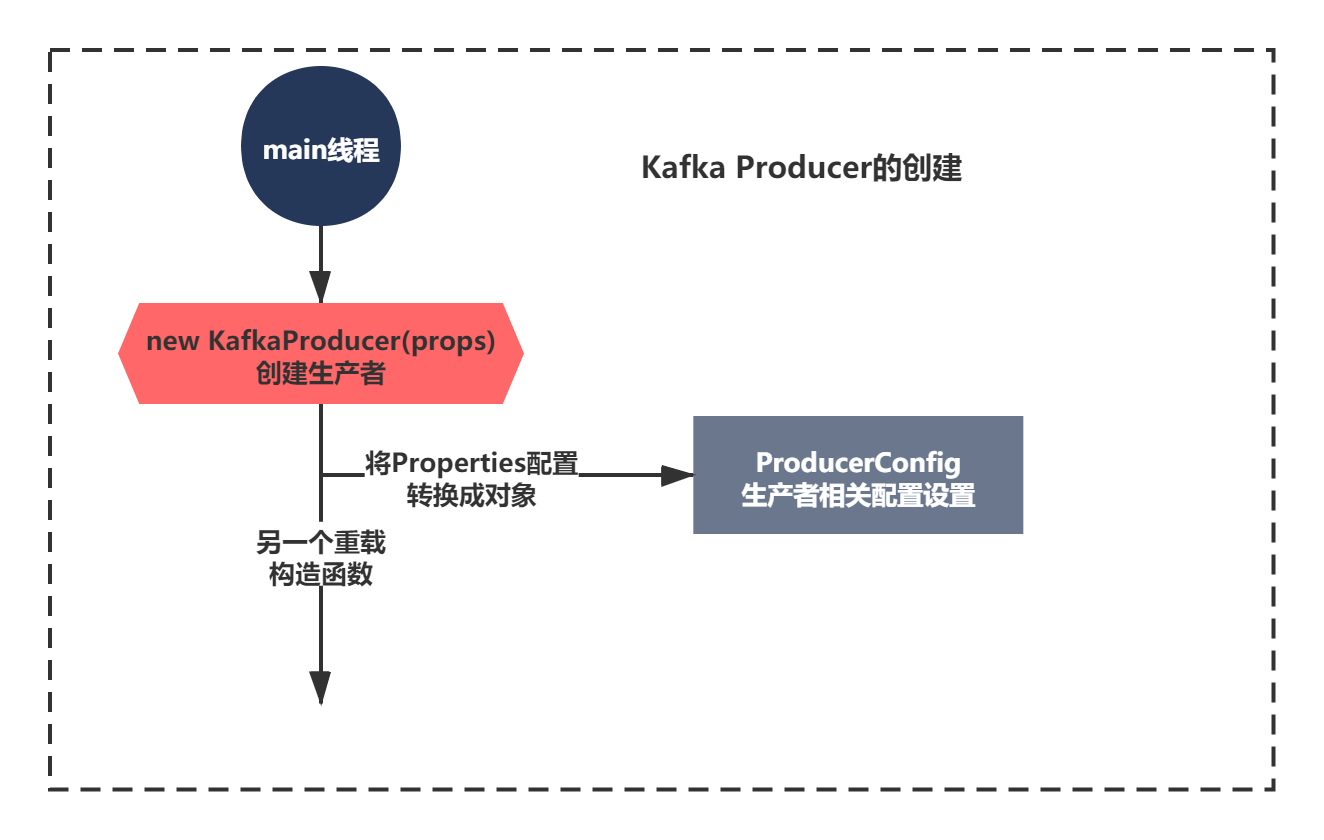
Kafka Producer 生产者的配置如何解析的?
这一节,我们就先来看看ProducerConfig是如何解析配置文件的。new ProducerConfig()的代码如下:
/*
* NOTE: DO NOT CHANGE EITHER CONFIG STRINGS OR THEIR JAVA VARIABLE NAMES AS THESE ARE PART OF THE PUBLIC API AND
* CHANGE WILL BREAK USER CODE.
* 注意:请勿更改任何配置字符串或它们的JAVA变量名,因为它们是公共API的一部分,更改将破坏用户代码。
*/
private static final ConfigDef CONFIG;
ProducerConfig(Map<?, ?> props) {
super(CONFIG, props);
}
这个构造函数的脉络,调用了一个super,竟然有一个父类。看起来比Zookeeper的配置解析封装的多一些,不是简单的一个QuorumPeerConfig。
而且有一个静态变量 ConfigDef CONFIG。你肯定想知道它是个什么东西。
我们可以看下ConfigDef这个类的源码脉络,看看能不能看出来什么:
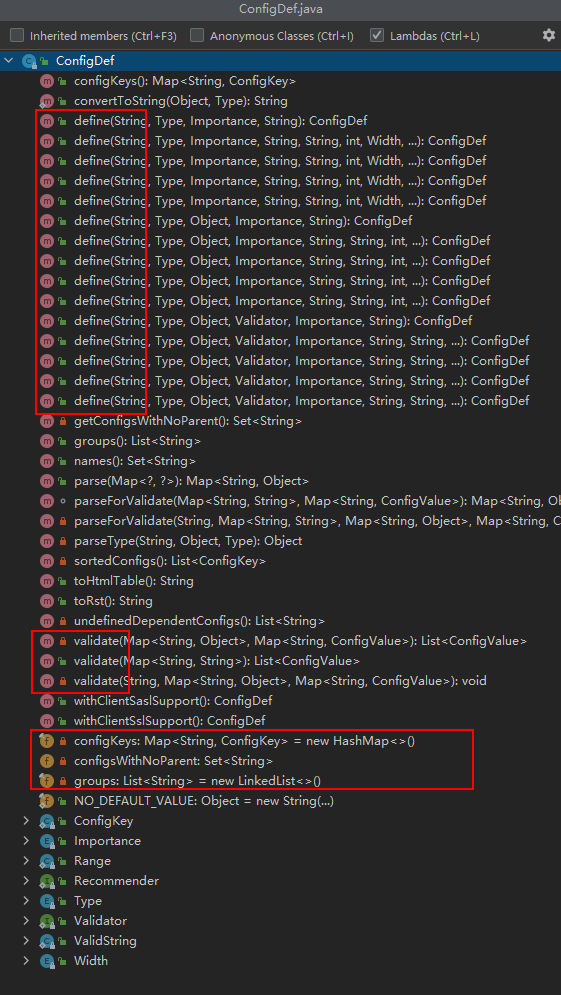
看着就是有一堆define方法、validate方法。关键几个变量,比如一个Map configKeys啥的。好像感觉是放key-value配置的
比如key=bootstrap.servers , value192.168.30.:9092的。
实在猜不到,我们可以再看看ConfigDef这个类的注释。
/**
/**
* This class is used for specifying the set of expected configurations. For each configuration, you can specify
* the name, the type, the default value, the documentation, the group information, the order in the group,
* the width of the configuration value and the name suitable for display in the UI.
* 此类用于指定期望的配置集。对于每种配置,您可以指定名称,类型,默认值,文档,组信息,组中的顺序,配置值的宽度和适合在UI中显示的名称。
*
* You can provide special validation logic used for single configuration validation by overriding {@link Validator}.
* 您可以通过覆盖{@link Validator}来提供用于单个配置验证的特殊验证逻辑。
*
* Moreover, you can specify the dependents of a configuration. The valid values and visibility of a configuration
* may change according to the values of other configurations. You can override {@link Recommender} to get valid
* values and set visibility of a configuration given the current configuration values.
* 此外,您可以指定配置的从属。配置的有效值和可见性可能会根据其他配置的值而改变。您可以覆盖{@link Recommender}来获得有效值,
* 并在给定当前配置值的情况下设置配置的可见性。
* 省略其他...
* This class can be used standalone or in combination with {@link AbstractConfig} which provides some additional
* functionality for accessing configs.
* 此类可以单独使用,也可以与{@link AbstractConfig}结合使用,从而提供一些附加功能访问配置的功能。
*/
通过上面的话,你应该就不难看出它的功能了。简单的说就是封装了key-value的配置,可以设置和校验key-value,可以单独使用用于访问配置
知道了这个静态变量的作用后,你点击到ProducerConfig的super,进入父类的构造函数:
public AbstractConfig(ConfigDef definition, Map<?, ?> originals, boolean doLog) {
/* check that all the keys are really strings */
for (Object key : originals.keySet())
if (!(key instanceof String))
throw new ConfigException(key.toString(), originals.get(key), "Key must be a string.");
this.originals = (Map<String, ?>) originals;
this.values = definition.parse(this.originals);
this.used = Collections.synchronizedSet(new HashSet<String>());
if (doLog)
logAll();
}
上面的代码核心脉络就一句话definition.parse(this.originals); 也就是执行了ConfigDef的parrse方法。
到这里,你想都不用想,这个方法就是转换 Properties为ProducerConfig配置的方法了。如下图所示:
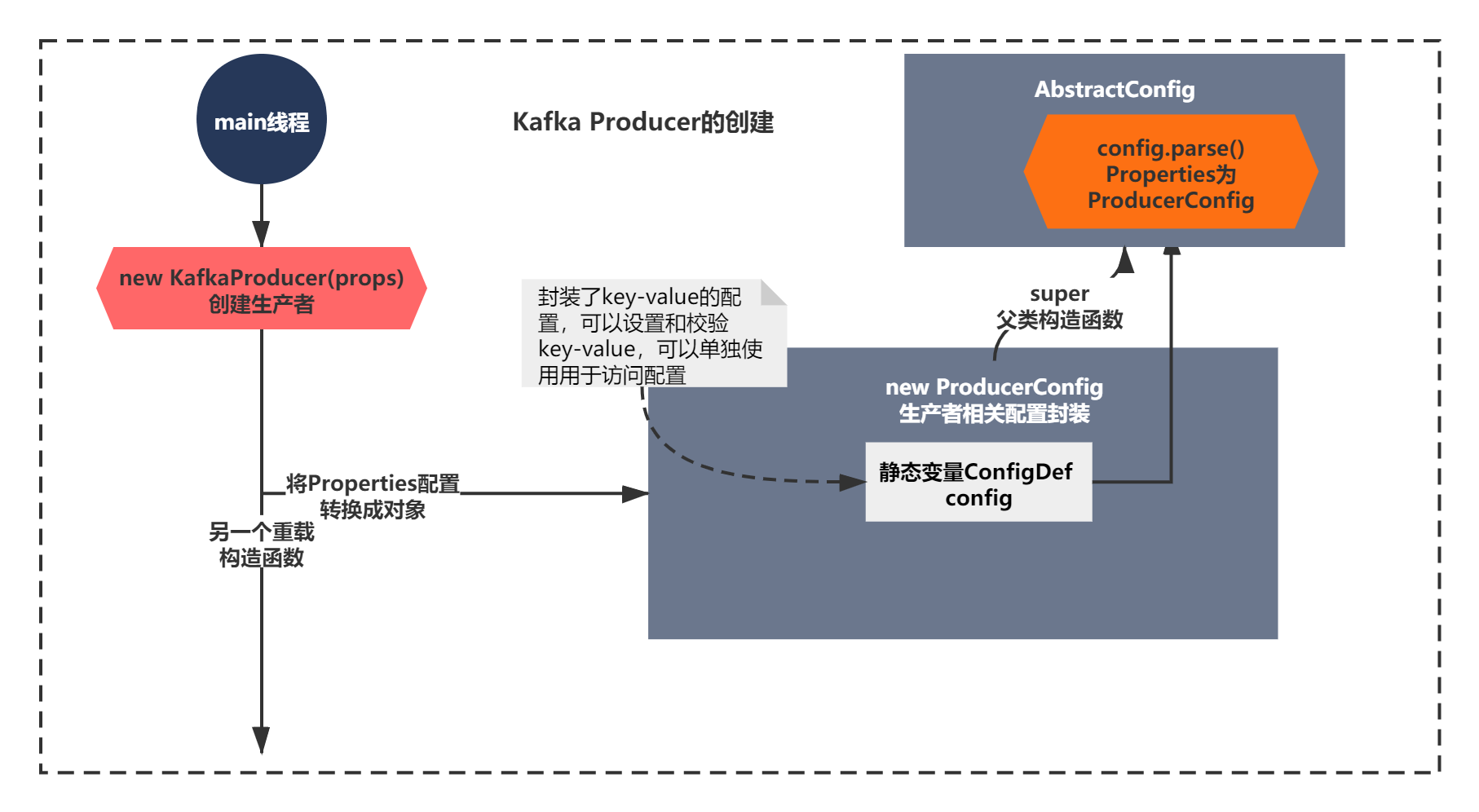
那么接下来简单看下parse方法吧,代码如下:
private final Map<String, ConfigKey> configKeys = new HashMap<>();
public Map<String, Object> parse(Map<?, ?> props) {
// Check all configurations are defined
List<String> undefinedConfigKeys = undefinedDependentConfigs();
if (!undefinedConfigKeys.isEmpty()) {
String joined = Utils.join(undefinedConfigKeys, ",");
throw new ConfigException("Some configurations in are referred in the dependents, but not defined: " + joined);
}
// parse all known keys
Map<String, Object> values = new HashMap<>();
for (ConfigKey key : configKeys.values()) {
Object value;
// props map contains setting - assign ConfigKey value
if (props.containsKey(key.name)) {
value = parseType(key.name, props.get(key.name), key.type);
// props map doesn't contain setting, the key is required because no default value specified - its an error
} else if (key.defaultValue == NO_DEFAULT_VALUE) {
throw new ConfigException("Missing required configuration \"" + key.name + "\" which has no default value.");
} else {
// otherwise assign setting its default value
value = key.defaultValue;
}
if (key.validator != null) {
key.validator.ensureValid(key.name, value);
}
values.put(key.name, value);
}
return values;
}
这段代码直接看上去有点懵,没关系,还是直接看的核心脉络。
核心脉络是一个for循环,主要遍历了Map<String, ConfigKey> configKey这个map,核心逻辑如下:
1)首先通过parseType确认value的类型, 之后根据ConfigKey定义的配置名称,也就是key
2)最后将准备好的key-value配置,放入Map<String, Object> values中返回给了AbstractConfig
这里我们就知道了最终我们配置的Producer参数,**就会放入到AbstractConfig的一个Map<String,Object>中,而且Object说明配置的value是区分整数、字符串之类的。**比如
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.30.:9092");
就会如下图所示:
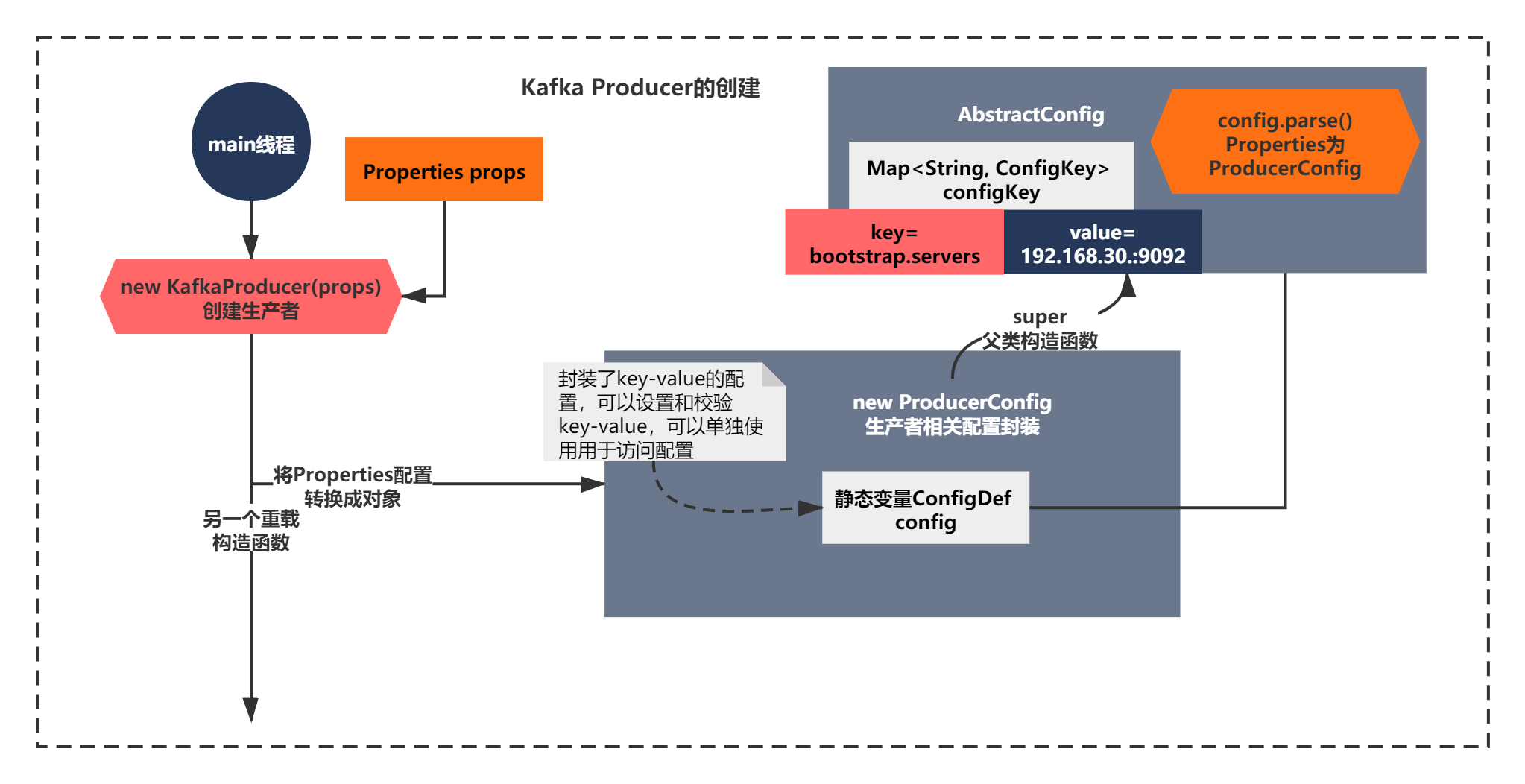
其实就是解析的Properties的整个过程了。你会发现其实也没有多复杂,就是稍微比Zookeeper封装的复杂点。
不过如果你细心的话,这里就有一个问题了, 上面parase方法的for循环,循环的Map<String, ConfigKey> configKey 是什么时候初始化的呢?
我们可以倒回去看看。
private static final ConfigDef CONFIG;
ProducerConfig(Map<?, ?> props) {
super(CONFIG, props);
}
还记得调用父类方法前,这个ConfigDef是子类传递给父类的。这个变量又是一个静态的,要想初始化,肯定是有一段静态初始化代码在ProducerConfig中的。你可以找到如下的代码:
/** <code>retries</code> */
public static final String RETRIES_CONFIG = "retries";
private static final String RETRIES_DOC = "Setting a value greater than zero will cause the client to resend any record whose send fails with a potentially transient error."
+ " Note that this retry is no different than if the client resent the record upon receiving the error."
+ " Allowing retries without setting <code>" + MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION + "</code> to 1 will potentially change the"
+ " ordering of records because if two batches are sent to a single partition, and the first fails and is retried but the second"
+ " succeeds, then the records in the second batch may appear first.";
static {
CONFIG = new ConfigDef()
.define(BOOTSTRAP_SERVERS_CONFIG, Type.LIST, Importance.HIGH, CommonClientConfigs.BOOSTRAP_SERVERS_DOC)
.define(BUFFER_MEMORY_CONFIG, Type.LONG, 32 * 1024 * 1024L, atLeast(0L), Importance.HIGH, BUFFER_MEMORY_DOC)
.define(RETRIES_CONFIG, Type.INT, 0, between(0, Integer.MAX_VALUE), Importance.HIGH, RETRIES_DOC)
.define(ACKS_CONFIG,
Type.STRING,
"1",
in("all", "-1", "0", "1"),
Importance.HIGH,
ACKS_DOC)
.define(COMPRESSION_TYPE_CONFIG, Type.STRING, "none", Importance.HIGH, COMPRESSION_TYPE_DOC)
.define(BATCH_SIZE_CONFIG, Type.INT, 16384, atLeast(0), Importance.MEDIUM, BATCH_SIZE_DOC)
.define(TIMEOUT_CONFIG, Type.INT, 30 * 1000, atLeast(0), Importance.MEDIUM, TIMEOUT_DOC)
.define(LINGER_MS_CONFIG, Type.LONG, 0, atLeast(0L), Importance.MEDIUM, LINGER_MS_DOC)
.define(CLIENT_ID_CONFIG, Type.STRING, "", Importance.MEDIUM, CommonClientConfigs.CLIENT_ID_DOC)
.define(SEND_BUFFER_CONFIG, Type.INT, 128 * 1024, atLeast(0), Importance.MEDIUM,
// 省略其他define
.withClientSslSupport()
.withClientSaslSupport();
}
这个静态方法的其实就是调用了define方法,初始化了Producer各个配置名称、默认值还有文档说明。最终封装成一个map,value是ConfigKey,初始化了ConfigDef。
private final Map<String, ConfigKey> configKeys = new HashMap<>();
public static class ConfigKey {
public final String name;
public final Type type;
public final String documentation;
public final Object defaultValue;
public final Validator validator;
public final Importance importance;
public final String group;
public final int orderInGroup;
public final Width width;
public final String displayName;
public final List<String> dependents;
public final Recommender recommender;
}
这个过程虽然没什么,但是重点就来了,默认值。也就说KafkaProducer的配置,默认值都是在这里初始化的。如果你想知道Producer的默认值,就可以看这里了。
这些参数之前公众号的《Kafka入门系列》中都有详细的介绍,我这里介绍了估计你也记不住。之后我们分析源码的时候你在慢慢理解吧。下面我摘录了一些核心配置,供大家回忆下:
Producer核心参数:
metadata.max.age.ms 默认每隔5分钟 会刷新下元数据
max.request.size 每个请求的最大大小(1mb)
buffer.memory 缓冲区的内存大小(32mb)
max.block.ms 缓冲区填满之后或元数据拉取最大阻塞时间(60s)
request.timeout.ms 请求超时时间(30s)
batch.size 每个batch的大小默认(16kb)
linger.ms 默认为0,不延迟发送。
可以配置为10ms,10ms内还没有凑成1个batch发送出去,必须立即发送出去
…
小结
好了今天我们就先分析到这里,下一节我们继续分析Producer 的创建,通过组件图和流程图的方式看看配置解析之后,执行的重载构造函数又做了那些事情呢?
-
【机器学习(二)】分类和回归任务-决策树(Decision Tree,DT)算法-Sentosa_DSML社区版11-25
-
增量更新怎么做?-icode9专业技术文章分享11-23
-
压缩包加密方案有哪些?-icode9专业技术文章分享11-23
-
用shell怎么写一个开机时自动同步远程仓库的代码?-icode9专业技术文章分享11-23
-
webman可以同步自己的仓库吗?-icode9专业技术文章分享11-23
-
在 Webman 中怎么判断是否有某命令进程正在运行?-icode9专业技术文章分享11-23
-
如何重置new Swiper?-icode9专业技术文章分享11-23
-
oss直传有什么好处?-icode9专业技术文章分享11-23
-
如何将oss直传封装成一个组件在其他页面调用时都可以使用?-icode9专业技术文章分享11-23
-
怎么使用laravel 11在代码里获取路由列表?-icode9专业技术文章分享11-23
-
怎么实现ansible playbook 备份代码中命名包含时间戳功能?-icode9专业技术文章分享11-22
-
ansible 的archive 参数是什么意思?-icode9专业技术文章分享11-22
-
ansible 中怎么只用archive 排除某个目录?-icode9专业技术文章分享11-22
-
exclude_path参数是什么作用?-icode9专业技术文章分享11-22
-
微信开放平台第三方平台什么时候调用数据预拉取和数据周期性更新接口?-icode9专业技术文章分享11-22
