云计算
揭秘 Fluss 架构组件

这是 Fluss 系列的第四篇文章了,我们先回顾一下前面三篇文章主要说了哪些内容。
- Fluss 部署,带领大家部署Fluss 环境,体验一下 Fluss 的功能
- Fluss 整合数据湖的操作,体验Fluss 与数据湖的结合
- 讲解了 Fluss、Kafka、Paimon 之间的区别和联系
前面三篇文章可以让大家上手玩起来 Fluss 这个框架,并说明了它与 Kafka、Paimon 数据湖的关系,接下来的文章
就深入 Fluss 细节来说一下它的实现原理了,今天给大家带来的是 Fluss 架构方法的知识。
Fluss 架构
Fluss 集群由两个主要进程组成:CoordinatorServer 和 TabletServer。
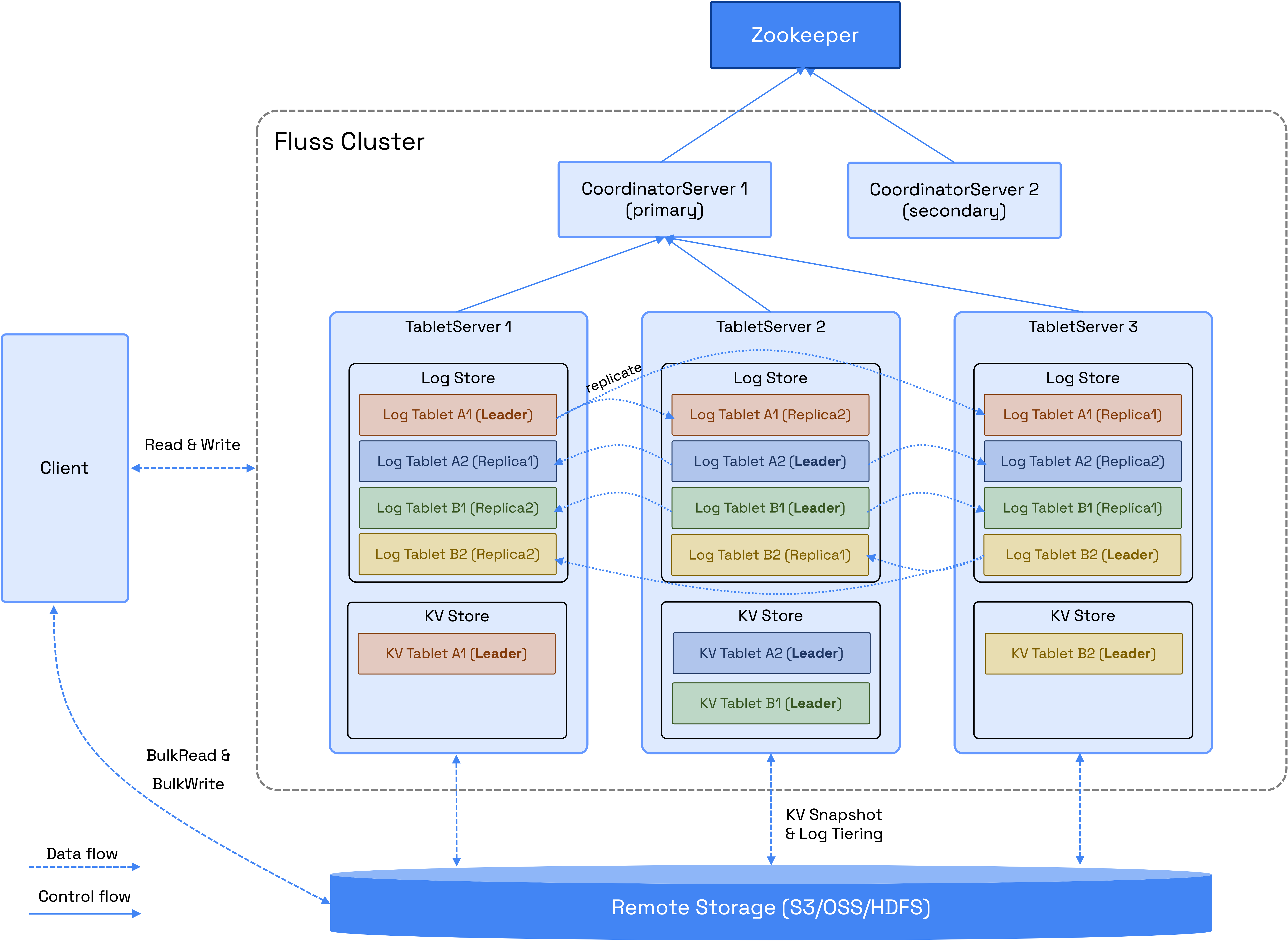
从上面的图片看 Fluss 是一个典型的主从架构,有Client、CoordinatorServer 、TabletServer等进程,我第一眼看到这个架构感觉就有点熟悉,这分区多副本和 Kafka 架构非常像。
下面我通过一条数据的生命周期的小故事给大家描述 Fluss 架构中这些服务组件的主要功能和工作流程。
1. 小数据的诞生(Client:我是从哪里来的?)
一个风和日丽的早晨,小数据“订单 1001”诞生了。它的妈妈是个电商用户小明,爸爸是一条代码(API)。小明通过 Fluss 的 App(Client)下了一单,内容如下:
订单号:1001,金额:4999 元,状态:待发货,时间:2024-12-25 09:00:00
在被创建的瞬间,小数据便穿过了网络,奔向 Fluss 的大门。它的梦想是被记录、管理、查询,甚至有朝一日成为运营分析的明星数据!
2. 走进总部大脑(CoordinatorServer:一个靠谱的“人生规划师”)
小数据“订单 1001”刚一到达 Fluss,就立刻被送到了 CoordinatorServer(总部控制中心),它可是 Fluss 的大脑!CoordinatorServer 一看到小数据,立刻开始规划它的未来,像极了一个靠谱的职业规划师:
- 元数据登记:CoordinatorServer 先给小数据发了个“身份证”,记录了它的订单号、金额、状态和时间。
- 分配节点:CoordinatorServer 仔细分析了一下,“东区分拣中心(TabletServer)”距离小明最近,于是决定把小数据送过去。
- 资源平衡:东区最近有点忙,但 CoordinatorServer 坚信可以处理好这个订单,偶尔也会平衡任务给其他中心。
规划好这一切后,CoordinatorServer 给小数据指了条明路:“去吧,到东区分拣中心报道!”
3. 踏上分拣之旅(TabletServer:我在哪里存活?)
小数据一路风尘仆仆,终于来到了 东区分拣中心(TabletServer)。这里是 Fluss 的数据加工厂,专门负责记录、存储和查询小数据。
东区分拣中心一看到小数据,马上给它安排了两份档案:
-
LogStore(日志部门):
LogStore 是个勤劳的“打工人”,专门记录小数据的每一步人生足迹:[时间:2024-12-25 09:00:00] 创建订单:订单号 1001,状态:待发货
小数据兴奋极了:“我的人生从这里被记录下来啦!”
-
KvStore(仓库):
KvStore 是分拣中心的“仓库管理员”,专门保存小数据的状态和内容,以备后续查询。KvStore 给小数据安排了个“货架”:货架位置:东区仓库 001,数据状态:待发货
“好耶!”小数据开心地在自己的货架上安顿下来。
4. 人生中的更新(LogStore + KvStore:我的状态变了!)
就在 9:30,小数据的人生迎来了第一个重要的“更新”。妈妈小明得到了快递信息:“您的订单已发货!”
于是,小数据的状态从“待发货”更新为“已发货”。分拣中心马上展开协作:
-
LogStore 记录变更: LogStore 再次记录下小数据的人生足迹:
[时间:2024-12-25 09:30:00] 更新状态:已发货
-
KvStore 更新状态: KvStore 将仓库里的数据替换为最新状态:
货架位置:东区仓库 001,数据状态:已发货
小数据感叹:“原来我的人生是可以改写的!”
5. 跨仓储的挑战(ZooKeeper:保持系统秩序)
东区分拣中心最近有点忙,有些数据开始超载。就在这时,Fluss 的 “通信协调员”(ZooKeeper)站了出来:“不用慌!一切有我协调。”
ZooKeeper 通知总部,将一部分数据任务转移到北区的分拣中心,以确保整个系统的平稳运行。小数据惊叹:“原来我有这么多后备选项!”
6. 历史的归宿(Remote Storage:成为数据档案)
随着时间的推移,越来越多的数据涌入东区分拣中心,小数据意识到它的时代要结束了。
为了让分拣中心有更多存储空间,小数据和它的伙伴们被转移到了 远程云存储(Remote Storage)。这就像是档案馆,它保存了所有历史数据。
“虽然我不再活跃,但我的人生还会被查阅!未来的人们可以分析我。”小数据在档案馆安然入眠。
7. 被召唤的高光时刻(查询 + 分析)
就在小数据以为自己会默默无闻地躺着时,突然,一条查询指令将它唤醒:
SELECT status FROM orders WHERE order_id = 1001;
系统快速检索:
- LogStore 提供了变更日志,追踪它的所有历史记录。
- KvStore 提供了最终的状态。
小数据以它的最新状态“已发货”再次出现在查询结果中:“原来,我一直在被需要!”
到了年底,Fluss 公司还通过批量分析指令:
SELECT SUM(amount) FROM orders WHERE year(order_time) = 2024;
运营团队惊喜地发现,小数据贡献了 4999 元销售额!“我成了分析中的重要一环!”
Fluss 小数据的一生
| 组件 | 在故事中的角色 | 功能 |
|---|---|---|
| Client | 小数据的出生医院 | 负责接收数据的输入。 |
| CoordinatorServer | 职业规划师(总部控制中心) | 负责数据分配、元数据管理、故障恢复。 |
| TabletServer | 分拣中心 | 负责数据的存储和更新,提供高效查询。 |
| LogStore | 日志记录员 | 记录所有数据的变更历史,用于流式处理和追踪。 |
| KvStore | 仓库管理员 | 保存数据的最新状态,支持高效查询和修改。 |
| ZooKeeper | 系统协调员 | 保证整个系统有序运行,处理分配和调度。 |
| Remote Storage | 数据档案馆 | 保存历史数据,减轻分拣中心的压力。 |
专业解释
下面是 Fluss 架构里面这些进程的详细专业解释:
CoordinatorServer
CoordinatorServer 是集群的核心控制和管理组件,主要负责以下任务:
- 元数据管理:维护元数据。
- 节点分配管理:管理 Tablet 的分配和节点列表。
- 权限管理:处理用户和服务权限。
此外,CoordinatorServer 负责以下关键操作:
- 数据再平衡:在节点扩展或缩减时重新分配数据。
- 数据迁移:当节点发生故障时,管理数据迁移和服务节点切换。
- 表管理:创建或删除表,更新桶(Bucket)的数量。
CoordinatorServer 是整个集群的大脑,确保资源高效分配与无缝管理。
TabletServer
TabletServer 负责数据存储、持久化,并直接为用户提供 I/O 服务。它由以下两个关键组件组成:
- LogStore:用于存储日志数据,类似数据库的 binlog(变更日志)。
- KvStore:用于存储表数据,支持更新和删除。
不同表类型对应的行为:
- 主键表(PrimaryKey Table):支持更新操作,使用 KvStore 存储表数据,并使用 LogStore 存储变更日志。
- 日志表(Log Table):仅支持追加写入,主要依赖 LogStore 优化写入性能。
LogStore
- 专为存储日志数据而设计,类似于数据库的 binlog。
- 数据只能追加,不可修改,确保数据完整性。
- 主要用于低延迟的流式读取,同时作为 KvStore 的预写日志(WAL)。
KvStore
- 用于存储表格化数据,支持高效的查询、更新和删除操作。
- 生成完整的变更日志以追踪数据修改。
- 适用于需要频繁数据操作的场景。
Tablet / Bucket
- 数据根据桶策略分为多个桶(Bucket)。
- 每个 Tablet 包含 LogTablet 和(可选的)KvTablet,具体取决于表是否支持更新。
- Tablet 通过复制(Replication)机制确保高可用性。
- 注意:目前,KvTablet 不支持复制。
ZooKeeper
- Fluss 当前使用 ZooKeeper 进行集群协调、元数据存储和配置管理。
- 未来版本中,计划用 KvStore 替代 ZooKeeper 的元数据存储功能,并使用 Raft 协议实现集群协调和一致性。
远程存储(Remote Storage)
远程存储主要有两个用途:
- 分层存储(LogStores):
-
- 减少 LogStore 数据的存储成本。
- 加速扩展操作。
- 持久化存储(KvStores):
-
- 为 KvStore 提供持久化存储。
- 与 LogStore 协作,实现故障恢复。
未来计划支持批量写入操作,优化数据导入流程并提高性能。
客户端(Client)
Fluss 提供的客户端/SDK 支持以下操作:
- 流式读写
- 批量读写
- 数据定义语言(DDL)操作
- 主键点查(Point Queries)
目前,主要的客户端实现是 Flink Connector,用户可以通过 Flink SQL 轻松操作 Fluss 的表和数据。
写在最后
这篇文章说了Fluss 架构中的服务组件的职能和工作流程,后面会对 Fluss 查询数据湖和本地数据合并部分做讲解。欢迎大家关注 "大圣数据星球"一起来讨论大数据技术。
-
阿里云部署方案学习入门:新手必读指南12-27
-
阿里云RDS学习入门:新手必读指南12-27
-
初学者指南:轻松掌握阿里云部署12-27
-
阿里云RDS入门指南:轻松搭建和管理数据库12-27
-
Sentinel监控流量:新手入门教程12-27
-
阿里云部署方案学习:新手入门教程12-27
-
阿里云RDS学习:新手入门指南12-27
-
Hbase项目实战:新手入门与初级技巧12-24
-
Hbase入门教程:轻松掌握大数据存储技术12-24
-
Hbase学习:从入门到初级实战教程12-24
-
Hbase入门:新手必读指南12-24
-
Hbase教程:新手入门指南12-24
-
内网穿透项目实战:新手入门指南12-24
-
Fluss 写入数据湖实战12-23
-
揭秘 Fluss:下一代流存储,带你走在实时分析的前沿(一)12-22
