云计算
消失的数去哪里了

大家好,我是大圣,最近消失了很长一段时间了,之前答应粉丝要更新的文章也没有按时更新。其实我这段时间去闭关修炼去了,现在满血归来啦,之前答应粉丝的文章都会陆续发出来的。
消失的 Count 去哪了
今天给大家分享一个面试经常问到的一个多线程问题,大家直接看下面的代码。
代码案例
public class Counter {
private int count = 0;
public synchronized void increment() {
count++;
}
public int getCount() {
return count;
}
}
class CounterTest {
public static void main(String[] args) throws InterruptedException {
Counter counter = new Counter();
Runnable incrementTask = () -> {
for (int i = 0; i < 1000; i++) {
counter.increment();
}
};
Thread thread1 = new Thread(incrementTask);
Thread thread2 = new Thread(incrementTask);
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("Final count: " + counter.getCount());
}
}
上面这段代码我相信做 Java 开发的小伙伴们都不会陌生,就是两个线程同时对一个成员变量 count 进行 for 循环相加 1000 次,然后最后打印出来的 count 的值会是多少呢?
结果讨论
可能大多数人都会回答这个最后打印出来的 count 每次都不固定,并且可能每次count的值会小于 2000。
其实最后打印出来的值确实是按照上面说的这样,我这边跑出来的结果如下图:
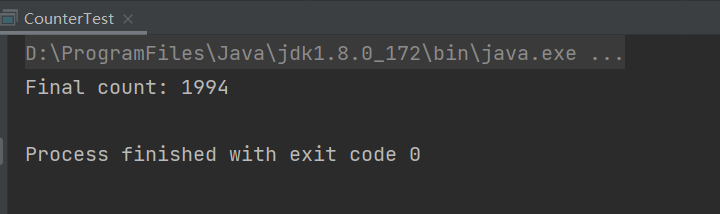
但是大家知道 count 值小于 2000 的原因吗?有很多小伙伴们会说是因为 CPU 的多级缓存导致的,如下图:
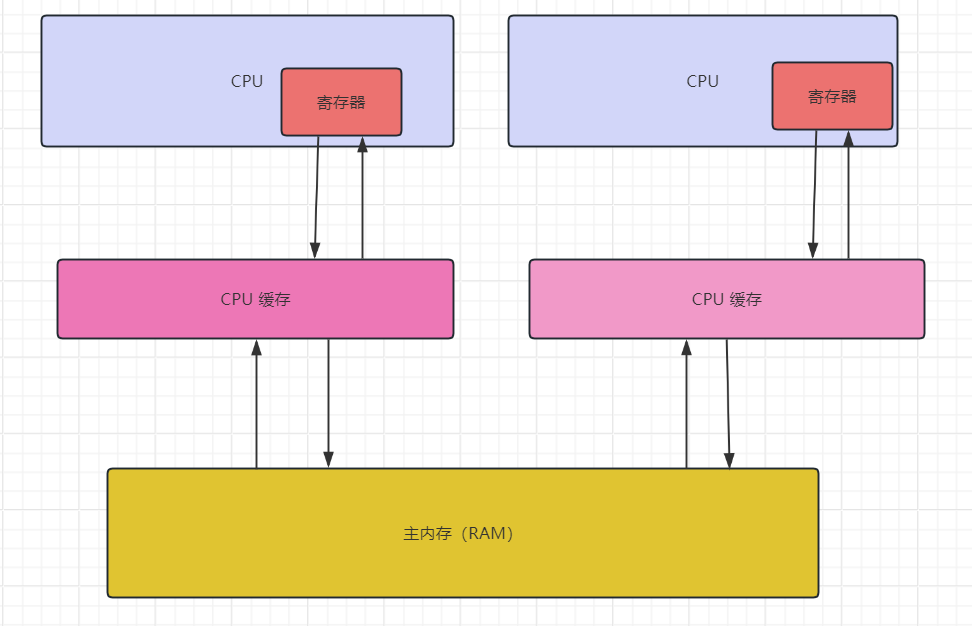
其实不是的,这个大家可以去验证一下,如果说是 CPU 多级缓存导致的话,咱们可以在 count 这个成员变量加上一个 volatile 关键字,加上过后你会发现测出来的结果还是小于 2000,又有人说了 volatile 不能解决 count++ 这样的非原子性操作,这个说法是对的,但是也不全对。
其实上面的案例代码 count 最后的值会小于 2000,是因为寄存器的问题。不知道说到这里大家有没有思路弄明白说为什么是寄存器的问题。 这个问题,我会在下一篇文章当中为大家解答。
写在最后
个人观点
其中有些人会有疑惑,学数据开发为什么要学把 Java 学的这么深入,个人觉得其实数据开发就是 Java 的高阶版本。如果你没有扎实的 Java 基础,是不能把数据开发中那些分布式框架学习明白的,当然了,如果你只想单纯的做 sql boy ,我觉得这个确实可以不用学习 Java 一些知识。
后续分享
我后面主要会分享 Java、数据开发、大模型开发等方面的知识,同时也会不定时分享自己对互联网行业的认识。
-
Fluss 写入数据湖实战12-23
-
揭秘 Fluss:下一代流存储,带你走在实时分析的前沿(一)12-22
-
DevOps与平台工程的区别和联系12-20
-
从信息孤岛到数字孪生:一本面向企业的数字化转型实用指南12-20
-
手把手教你轻松部署网站12-20
-
服务器购买课程:新手入门全攻略12-20
-
动态路由表学习:新手必读指南12-20
-
服务器购买学习:新手指南与实操教程12-20
-
动态路由表教程:新手入门指南12-20
-
服务器购买教程:新手必读指南12-20
-
动态路由表实战入门教程12-20
-
服务器购买实战:新手必读指南12-20
-
新手指南:轻松掌握服务器部署12-20
-
内网穿透入门指南:轻松实现远程访问12-20
-
网站部署入门教程12-20
