云计算
分布式数据库系统环境的“无感”升级

导读
本文聚焦于杭州银行在数字化转型背景下,通过高可用机制实现关键业务系统“无感”升级的探索实践。随着金融行业加速线上化和移动化转型,业务系统的连续性要求显著提升,传统的数据库变更方式已无法满足新时期的需求。杭州银行基于 TiDB 分布式架构设计的新一代关键业务系统,通过节点冗余、数据副本、故障转移和负载均衡等机制,实现了系统的高可靠性与可维护性。
文章详细阐述了在这一架构下进行业务“无感”维护的技术要点,包括节点不可用时的业务影响评估、滚动升级的操作方法、以及存储和计算节点的连接管理策略。
随着金融科技的飞速发展,传统银行业务快速向线上化、移动化转型,各种新渠道、新场景对系统连续性目标提出了更高要求。在此背景下,杭州银行基于分布式架构建设新一代关键业务系统(如图 1 所示),利用节点冗余、数据副本、故障转移和负载均衡等机制实现架构高可靠性设计,并探索利用高可用机制完成业务“无感”维护,显著提升了内部使用体验和客户服务体验。
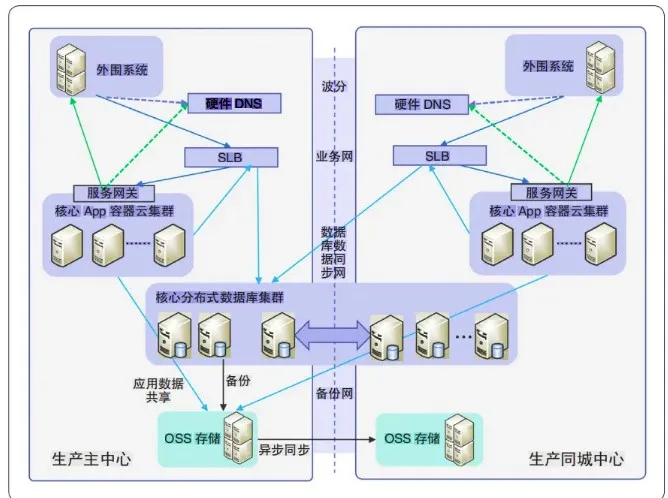
“无感” 升级技术落地探索
与传统基于小型机的架构设计相比,新一代关键业务系统按照“单点不可靠”思路设计的分布式架构在可维护性方面优势明显,不仅通过组件全冗余设计消除了架构中的单点故障,同时还支持基于策略的节点流量调度。为避免软件环境升级补丁对关键业务系统生产集群及容灾集群运行连续性造成影响,杭州银行在分布式环境中进一步探索“无感”升级的可行路径,并重点梳理了以下技术要点:一是确定节点不可用及恢复上线时的业务影响范围和影响时长;二是在分布式架构下,探索不影响可用性的流量调拨操作方法及滚动式操作的粒度;三是实施滚动式操作时,制定防范出现二次故障或者出现二次故障后的快速恢复方法;四是基于每日操作窗口时间,科学设计节点批次。
分布式架构的组件按照处理请求时是否依赖外部状态可分为有状态组件和无状态组件,且不同组件的高可用机制及其对业务的影响也各有不同(见表 1)。考虑上述特点,杭州银行利用高可用机制和流量调拨方法设计了节点重启方案。在此模式下,计算节点保有应用层的数据库长连接,通过负载均衡转发策略与应用连接池的淘汰机制结合,可实现非活跃连接转移和新节点的连接恢复。存储节点上数据分片多副本的 Leader 角色响应计算节点的读写请求,通过对指定节点进行 Leader 角色的迁移或者排斥操作来实现数据读写请求的迁移。

负载均衡支持以手工或者感知计算节点状态端口的方式将计算节点在“计划内”下线,即保持原有连接的同时,新连接不再连接到下线节点。同时,使用应用程序的 hikariCP 连接池的 maxlifetime 参数标识一个“连接”生命周期的上限,超过该时间会被标记为过期连接,如果是闲置状态,则会被连接池关闭并重新创建,新连接会被负载均衡转发到其他在线的节点上。当下线节点所有的数据库连接超出 maxlifetime 的时间后均会被释放,从而使节点重启过程对业务无影响。在节点恢复后,再由负载均衡将节点上线,根据最少连接策略将应用侧连接池的新建连接转移到连接较少的刚恢复的计算节点。所有节点的连接平衡后,再进行下一组节点的操作。
基于上述方式,杭州银行通过滚动式升级依次完成了所有的计算节点升级重启并保持连接平衡,且其间即便有节点发生故障,亦有剩余可用节点来接收所有的应用连接。计算节点滚动式重启的连接状态如图 2 所示。
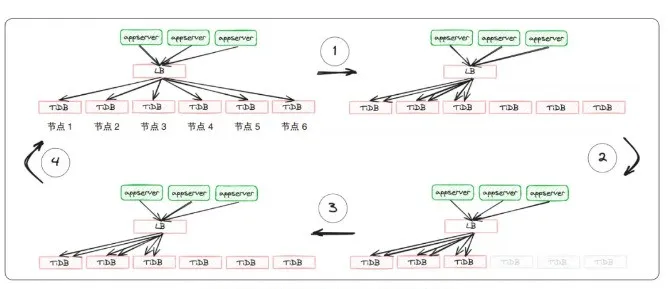
其间,使用数据库管理工具可添加准备下线存储节点的 Leader 角色的排斥调度,当同一数据分片 Raft 组的 Leader 角色切换到其他存储节点的数据副本后,计算节点的读写流量会随之调拨。当存储节点上没有 Leader 角色的数据分片后,仅保持副本同步状态,没有计算节点的访问流量。多副本组成的 Raft 组可容忍少数派的副本成员下线,所以仅有 Follower 角色数据分片的节点进行升级重启时对业务无影响,且同一副本成员节点恢复后,将自动保持副本同步状态,管理员可通过管理工具恢复 Leader 角色的调度能力。存储节点滚动式重启的数据分片副本状态如图 3 所示。
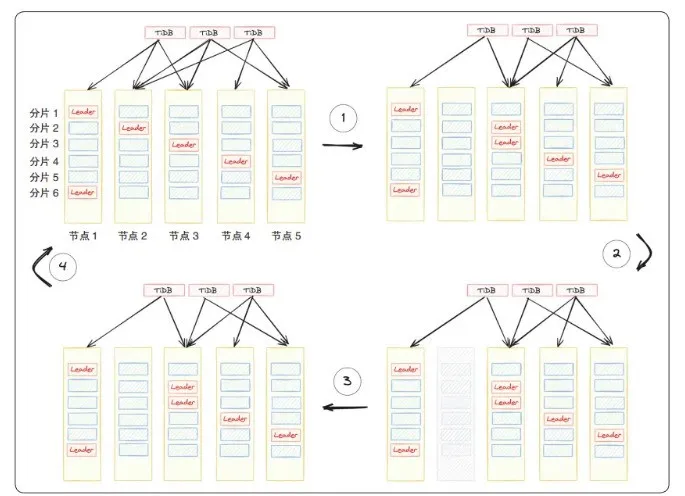
杭州银行 “无感” 升级实践
通过滚动式升级,杭州银行依次完成所有的节点升级重启并保持 Leader 角色的数量平衡。以关键系统生产集群为例,数据库节点涉及两个机房的数十台服务器,服务器升级微码重启的操作过程约 30 分钟,结合连接维护超时操作,单台服务器需要约 1 个小时,每日维护窗口时间大致为从 19:00 到 23:00 的 4 个小时,因此需分批进行升级操作;同时,考虑存储节点出现故障的概率更大,选择优先升级存储节点,再升级计算节点/调度节点,最后升级数据同步节点。单次滚动集群组件的批次设计见表 2。
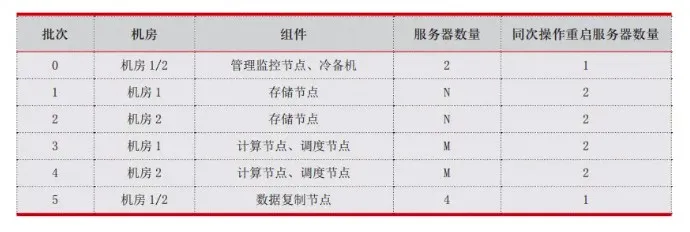
在存储节点下线时,杭州银行将需要同次操作重启服务器的存储节点设置为调度驱逐 Leader 角色,并使用 Raft 算法来保证系统存储节点可用性;同时,通过重点关注 Leader 角色的数据分片数量,并使用监控查看每台存储节点的 Leader 数量下降为 0,实现了操作系统升级后的重启过程对业务无影响;基于负载均衡控制台将需要同次操作重启服务器的计算节点设置为“禁用”,即从 Virtual Server 转发的 Real Server 列表中剥离,使数据库长连接开始超时退出。
从计算节点禁用后的连接状态变化来看,10 分钟内每台 4000 个连接快速下降到接近为 0,仅有少量的平台类应用连接未配置 maxlifetime 参数,等待 20 分钟后直接关闭计算节点进程开始升级。计算节点系统重启后,负载均衡将恢复的计算节点设置为“启用”,从而在接下来的 10 分钟内,连接开始逐步恢复到正常水平。组件中断影响记录见表 3。

综上所述,杭州银行以提升客户满意度为目标,采用数据库运维与应用连接管理策略协作等创新技术,实现了分布式数据库系统环境的“无感”升级,不仅有效规避了停机窗口限制,拓宽了维护场景,也为同类系统的升级改造提供了可行参考。后续,杭州银行数据库运维团队还将积极探索自动化作业、多层流量联动等技术手段在升级场景的应用,以高质量技术服务助力银行业务可持续创新发展。
-
Fluss 写入数据湖实战12-23
-
揭秘 Fluss:下一代流存储,带你走在实时分析的前沿(一)12-22
-
DevOps与平台工程的区别和联系12-20
-
从信息孤岛到数字孪生:一本面向企业的数字化转型实用指南12-20
-
手把手教你轻松部署网站12-20
-
服务器购买课程:新手入门全攻略12-20
-
动态路由表学习:新手必读指南12-20
-
服务器购买学习:新手指南与实操教程12-20
-
动态路由表教程:新手入门指南12-20
-
服务器购买教程:新手必读指南12-20
-
动态路由表实战入门教程12-20
-
服务器购买实战:新手必读指南12-20
-
新手指南:轻松掌握服务器部署12-20
-
内网穿透入门指南:轻松实现远程访问12-20
-
网站部署入门教程12-20
