MySql教程
从 MySQL 迁移到 TiDB:使用 SQL-Replay 工具进行真实线上流量回放测试 SOP

导读
在 MySQL 迁移至 TiDB 的过程中,兼容性和性能验证至关重要。SQL-Replay 是一款实用工具,用于评估数据库的兼容性和性能,支持日志解析、查询回放、性能测量和报告生成等功能。
本文介绍了 SQL-Replay 工具的安装和使用步骤,以及如何运用 SQL-Replay 工具,通过回放 MySQL 慢查询日志或抓包流量文件,验证 TiDB 集群的兼容性和性能,提高数据库迁移的成功率和效率。
SQL-Replay 工具介绍
1.1 工具简介
流量回放工具:GitHub - Bowen-Tang/sql-replay: mysql slow query replay
抓包工具:https://github.com/Bowen-Tang/parse-tshark
SQL-Replay 工具是一个设计用于回放 MySQL 慢查询文件和 parse-tshark 抓包文件的 GitHub 开源项目,目的是帮助评估数据库兼容性和性能。这个工具支持多种操作模式,包括解析慢查询日志、回放这些日志、将回放结果加载到数据库中以及生成报告。
1.2 原理概述
以下是 SQL-Replay 工具的核心功能原理:
1. 日志捕获与解析:
a. MySQL 的慢日志文件以及通过 parse-tshark 抓包生成的文件,这些日志中包括 SQL 执行时间、SQL 文本。
b. 该工具可以解析这些日志以提取相关信息,如 SQL 语句、执行时间,以及可能的其他元数据,如执行上下文或执行查询的用户。
2. 查询回放:
a. 在受控环境中回放提取的 SQL 查询至另一套 TiDB 数据库。
3. 性能测量与分析:
a. 在回放期间,通过执行 SQL 查询获取在 TiDB 数据库中的执行时间。
b. 它将这些指标与基准或之前的运行结果进行比较,以识别性能下降或改进。这有助于确定可能引起问题的特定查询或数据库设置。
4. 报告生成:
a. 最后,SQL-Replay 生成报告,提供查询兼容性和性能的见解。这些报告帮助数据库管理员和开发人员理解不同查询对系统的影响,并做出有关优化的明智决策。
通过使用像 SQL-Replay 这样的工具,团队可以确保他们的数据库为性能优化并能有效处理实际负载。这在涉及数据库迁移、升级或重大架构更改的场景中有有作用,对查询性能的影响至关重要。
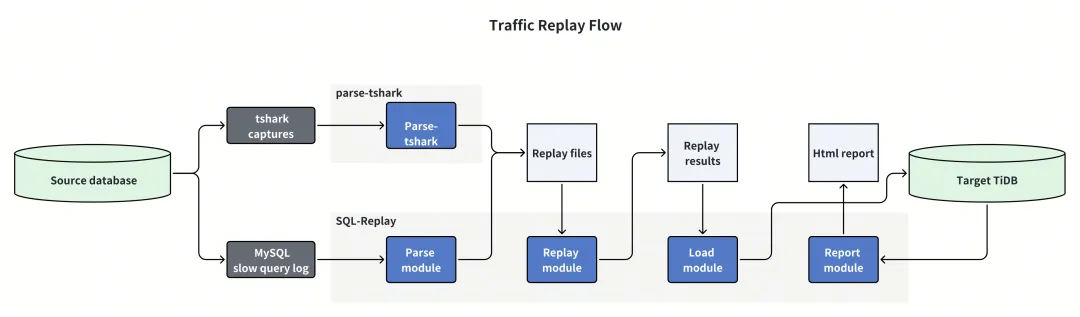
1.3 适用场景
根据 SQL-Replay 工具的特性和功能,以下是一些适用的场景:
1. SQL 兼容性评估:
使用该工具可以将在 MySQL 数据库上执行过的 SQL 回放至下游 TiDB 数据库,根据执行结果判断下游数据库对 SQL 的兼容度。
2. 数据库性能评估:
在数据库升级或迁移前后,使用 SQL-Replay 来回放实际的生产查询,帮助评估数据库的性能改进或退化。这对于在实施重大更改之前理解潜在的性能问题非常有用。
3. 容灾和高可用性测试:
在计划容灾策略和高可用性解决方案时,SQL-Replay 可用于模拟实际查询负载,以测试系统在主机故障或网络中断时的表现。
4. 开发和测试:
开发人员和测试人员可以使用 SQL-Replay 在开发和测试环境中回放生产环境的查询,确保新开发的功能和优化在面对实际数据和负载时的稳定性和性能。
通过使用 SQL-Replay,团队可以更有效地理解更换数据库带来的差异,确保任何更改都符合预期的性能标准,并减少在生产环境中出现问题的风险。
1.4 支持的 MySQL 数据库
已知支持对以下 MySQL 数据库的慢查询回放至 TiDB。
- MySQL 5.6、5.7、8.0
- 华为云 MySQL RDS
- Aurora MySQL 5.7、8.0
当前验证支持的慢日志格式实例如下:
# Time: 2024-01-19T16:29:48.141142Z # User@Host: t1[t1] @ [10.2.103.21] Id: 797 # Query_time: 0.000038 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1 SET timestamp=1705681788; SELECT c FROM sbtest1 WHERE id=250438; # Time: 240119 16:29:48 # User@Host: t1[t1] @ [10.2.103.21] Id: 797 # Query_time: 0.000038 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1 SET timestamp=1705681788; SELECT c FROM sbtest1 WHERE id=250438; # Time: 231106 0:06:36 # User@Host: coplo2o[coplo2o] @ [10.0.2.34] Id: 45827727 # Query_time: 1.066695 Lock_time: 0.000042 Rows_sent: 1 Rows_examined: 7039 Thread_id: 45827727 Schema: db Errno: 0 Killed: 0 Bytes_received: 0 Bytes_sent: 165 Read_first : 0 Read_last: 0 Read_key: 1 Read_next: 7039 Read_prev: 0 Read_rnd: 0 Read_rnd_next: 0 Sort_merge_passes: 0 Sort_range_count: 0 Sort_rows: 0 Sort_scan_count: 0 Created_tmp_ disk_tables: 0 Created_tmp_tables: 0 Start: 2023-11-06T00:06:35.589701 End: 2023-11-06T00:06:36.656396 Launch_time: 0.000000 # QC_Hit: No Full_scan: No Full_join: No Tmp_table: No Tmp_table_on_disk: No Filesort: No Filesort_on_disk: No use db; SET timestamp=1699200395; SELECT c FROM sbtest1 WHERE id=250438;
SQL-Replay 使用 SOP
2.1 安装和设置
2.1.1 使用 SQL-Replay
直接下载,或从 GitHub 克隆源码进行本地编译。
根据仓库中提供的文档设置工具,确保所有依赖正确安装。
- 下载 SQL-Replay 可执行程序
mkdir replay && cd replay && wget https://github.com/Bowen-Tang/sql-replay/releases/download/0.3.2/0.3.2.zip unzip 0.3.2.zip
- 编译安装 SQL-Replay
#安装 golang (1.20 及以上) #下载项目 git clone https://github.com/Bowen-Tang/sql-replay #编译 sql-replay cd sql-replay go mod tidy go build
- 开启上游 MySQL slow log
设置 long_query_time 为 0,从将每一个 SQL 均记录在慢日志中。MySQL 修改完 long_query_time 参数后应用连接重建后才会生效。
需要注意的是慢日志 long_query_time 设置为 0 会导致大量的慢日志写入,在高并发场景下,可能会对性能有较大的影响(20%+)
--开启慢查询日志 set global slow_query_log=on; --设置慢查询时间为 0 SET GLOBAL long_query_time = 0; --获取<慢查询日志路径> show variables like 'slow_query_log_file';
2.1.2 使用 Parse-tshark
- 在需要抓取流量的 MySQL 上安装抓包程序 tshark
# Centos 7 自带的版本较低,但也能工作,建议编译安装 3.2.3 版本 yum install -y wireshark
- 或者下载 parse-tshark 可执行程序
mkdir parse-tshark && cd parse-tshark && wget https://github.com/Bowen-Tang/parse-tshark/releases/download/0.1.2/parse-tshark-v0.1.2.zip unzip parse-tshark-v0.1.2.zip
- 或者编译安装 parse-tshark
# Install golang (1.20 and above) # Download project git clone https://github.com/Bowen-Tang/parse-tshark # Compile parse-tshark cd parse-tshark go mod tidy go build
2.1.3 创建下游 TiDB 回放信息表
- 在下游 TiDB 创建回放信息表
CREATE TABLE `test`.`replay_info` ( `sql_text` longtext DEFAULT NULL, `sql_type` varchar(16) DEFAULT NULL, `sql_digest` varchar(64) DEFAULT NULL, `query_time` bigint(20) DEFAULT NULL, `rows_sent` bigint(20) DEFAULT NULL, `execution_time` bigint(20) DEFAULT NULL, `rows_returned` bigint(20) DEFAULT NULL, `error_info` text DEFAULT NULL, `file_name` varchar(64) DEFAULT NULL );
2.2 生成真实业务流量文件
2.2.1 使用 SQL-Replay
慢日志文件方式:在上游 MySQL 数据库上发起真实业务测试,观测 slow log 中是否已有慢日志生成。
tail -n 10 <慢查询日志路径>
2.2.2 使用 parse-tshark
抓包方式获取流量文件:在所有线上 MySQL 实例上,使用 tshark 进行 port 过滤,再二次过滤文件中的 mysql.query 和 响应时间。该方式生成的文件比较大,但对生产性能影响小(7%左右)。
- 抓包
该命令只是根据 3306 端口和 eth0 网卡抓包,以抓取 1 小时为例(每个文件大约 2000MB,最多生成 200 个)
cd ~/parse-tshark sudo tshark -i eth0 -f "tcp port 3306" -a duration:3600 -b filesize:2000000 -b files:200 -w ts.pcap
该命令会生成 ts*.pcap 文件。
- 获取抓包过程中的 user db 信息
由于 tshark 抓包时获取 user/db 信息过于复杂、且存在局限性,所以通过工具每隔 500ms 获取一次 MySQL 数据库的 processlist 视图信息,通过源端 IP+端口 与 processlist 视图中的 host 匹配,将信息输出到 host.ini文件中。
./parse-tshark -mode getmysql -dbinfo 'username:password@tcp(localhost:3306)/information_schema' -output host.ini
注意:该工具需要和 tshark 抓包同时运行,才能获取完整的 user/db 信息。
- 分析包
该命令针对抓包生成的 pcap 文件进行处理,处理成 SQL-replay 工具可读的文件(建议随后将这些文件传输到执行 SQL 回放的服务器处理)。
for i in `ls -rth ts*.pcap` do sudo tshark -r $i -Y "mysql.query or ( tcp.srcport==3306)" -d tcp.port==3306,mysql -o tcp.calculate_timestamps:true -T fields -e tcp.stream -e tcp.len -e tcp.time_delta -e ip.src -e tcp.srcport -e ip.dst -e tcp.dstport -e frame.time_epoch -e mysql.query -E separator='|' >> tshark.log done
多个文件将会被合并至 tshark.log 中。
2.3 解析线上流量日志
2.3.1 使用 SQL-Replay
使用 parse 模式将慢查询日志转换成结构化的 JSON 格式,便于回放。这涉及指定包含慢查询的输入文件和 JSON 文件的输出路径。
./sql-replay -mode parse -slow-in <慢查询日志路径> -slow-out <慢查询输出JSON文件路径>
2.3.2使用 parse-tshark
生成 sql-replay 可回放的文件。
./parse-tshark -mode parse2file -parsemode 1 -tsharkfile ./tshark.log -hostfile ./host.ini -replayfile ./tshark.out -defaultuser user_null -defaultdb db_null
将输入的抓包文件 tshark.log、db 和 user 信息文件 host.ini 。根据需要回放的 SQL 填写参数 user_null、db_null。输出可执行 SQL 到 tshark.out 文件中,供回放使用。
2.4 回放 SQL
使用 replay 模式将 MySQL 数据库的 SQL 回放至下游 TiDB。
# 回放所有用户、所有 SQL ./sql-replay -mode replay -db <TiDB 连接字符串> -speed <回放速度> -slow-out <慢查询输出JSON文件路径> -replay-out <回放输出路径>/<回放任务名称> -username all -sqltype all -dbname all
回放结果会存放在<回放输出路径>下,以<回放任务名称>开头,例如,<回放任务名称>为 sb1_all,则输出文件以 sb1_all.* 命名。
提示:
- 通过设置 speed 为 n,提高 SQL 回放频率,可以提升 SQL 回放的速度。
- 当数据库中就一个 database,一个 user 时,使用 -username all -dbname all 来回放。
- 当数据库中有多个 database、多个 user 时,建议启动多个 SQL-Replay 进程并行回放(否则将出现大量 SQL 报错),每个进程对应不同的 -username 和 -dbname(注意 -db 中的用户名、数据库名也需保持一致)。
2.5 加载回放结果
使用 load 模式将回放结果加载到指定的数据库表中进行进一步分析。其中,<回放输出路径>可以为 SQL-Replay 或 parse-tshark 两种模式的回放 SQL 输出文件。
./sql-replay -mode load -db <TiDB 连接字符串> -out-dir <回放输出路径> -replay-name <回放任务名称> -table replay_info
通过查询 TiDB 数据中目标表的数据,确认是否已完成数据加载。
select count(1) from replay_info where file_name like 'sb1_all.%' limit 11
2.6 生成报告
使用 report 模式从回放数据生成详细报告,帮助理解不同查询对数据库兼容性和性能报告。
./sql-replay -mode report -db <TiDB 连接字符串> -replay-name <回放任务名称> -port <Web报告端口>
通过访问 http://ip:8081 可以查看流量回放报告。
Replay Summary 中,记录了 SQL 总耗时对比、快的 SQL 条数、慢的 SQL 条数、错误的 SQL 条数。
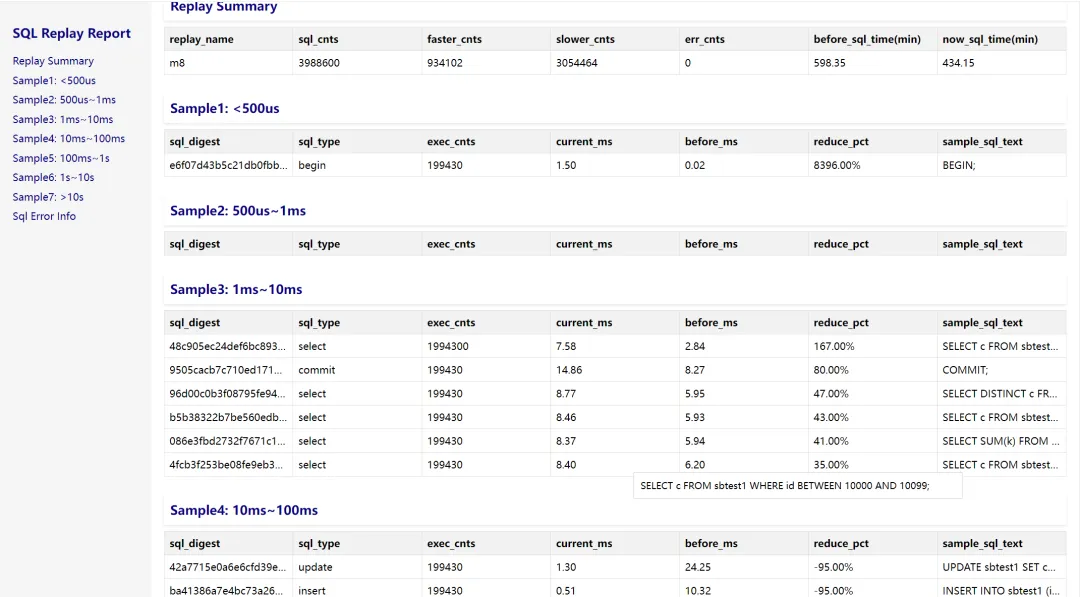
Sql Error Info 中,根据 sql_digest 以及 error_info(前 10 位)排序。

常见问题
如果慢查询中 connection 没有 use db 该怎么办?
通过慢查询回放时,由于日志中没有记录 database 信息,所以在 replay 时,只能指定 -db all,或者不指定,否则不会进行回放(如果想要在慢查询回放时过滤库,可以通过指定 -username 以及 -db 中的用户名和数据库名的形式来完成对应库的回放)。
是否支持流量放大?
没有设计自动的流量放大功能,如果仅需要放大读流量,可以通过启动多个回放程序来加大读流量的方式实现流量放大。
SQL 回放的顺序和上游完全一致么?
SQL 回放顺序并不完全与真实执行顺序相等。
客户长链接和短连接有什么影响么?
在短连接的情况下,可能存在连接数过多的问题
对于海量数据(20TB+)的场景,如何进行真实流量压测?
仿真流量测试在大数据量场景下,还是建议可以全量数据和流量进行测试。如果因为时间周期、成本、重要程度、复杂程度等因素综合考虑无法全量数据压测,建议按照业务主维度(例如游戏服的玩家、订单系统的订单)的 1/4 或者 1/2 等数据进行压测,并且压测时需要将流量放大指定倍数到全流量级别,以便尽量模拟线上的场景,另外就算这样做了,还是可能会存在和线上真实流量较大的偏差,比如其它维度(例如商家维度查询)的跨主维度查询时的数据量可能只有真实流量的 1/4 或者 1/2,从而导致测试数据有一定的偏差。
云上 RDS MySQL 都支持么?
云上 RDS 的慢查询日志格式不尽相同,不一定支持(需要验证慢日志格式);暂不支持 MariaDB,当前无法获取 connection_id,后续加上。
回放时会遇到 too many open files
当 connection_id 值过多(>4096)时,进行回放时会遇到 too many open files 错误,临时解决办法:回放前 ulimit -n 1000000。
-
如何部署MySQL集群资料:新手入门教程12-25
-
MySQL集群部署资料:新手入门教程12-24
-
MySQL集群资料详解:新手入门教程12-24
-
MySQL集群部署入门教程12-24
-
部署MySQL集群学习:新手入门教程12-24
-
部署MySQL集群入门:一步一步搭建指南12-24
-
MySQL读写分离入门:轻松掌握数据库读写分离技术12-07
-
MySQL读写分离入门教程12-07
-
MySQL分库分表入门详解12-07
-
MySQL分库分表入门指南12-07
-
MySQL慢查询入门:快速掌握性能优化技巧12-07
-
MySQL入门:新手必读的简单教程12-07
-
MySQL入门:从零开始学习MySQL数据库12-07
-
MySQL索引入门:新手快速掌握MySQL索引技巧12-07
-
BinLog学习:MySQL数据库BinLog入门教程12-06
