C/C++教程
无限可能Langchain——向量存储和检索

欢迎关注微信公众号【千练极客】,尽享更多干货文章!
本教程将使您熟悉LangChain的向量存储和检索器抽象。这些抽象旨在支持从(向量)数据库和其他来源检索数据,以便与LLM工作流集成。它们对于获取数据作为模型推理的一部分进行推理的应用程序很重要,例如检索增强生成或RAG(请参阅我们的RAG教程这里)。
概念
这个指南专注于文本数据的检索。我们将涵盖以下概念:
- 文档;
- 向量存储;
- 检索器。
安装
参考前面文档:
《无限可能LangChain——开启大模型世界》
《无限可能LangChain——构建一个简单的LLM应用程序》
本教程还需要 langchain-chroma 包
pip install langchain langchain-chroma langchain-openai
请参阅官网的安装指南以获取更多详细信息。
Documents
LangChain 实现了一个 Document 抽象,旨在表示一个文本单元和相关的元数据。它有两个属性:
- page_content:表示内容的字符串;
- metadata:包含任意的元数据。
metadata 属性可以捕获有关文档源、与其他文档的关系以及其他信息的信息。请注意,单个 Document 对象通常代表较大文档的一大块。
让我们生成一些示例文档:
from langchain_core.documents import Document
documents = [
Document(
page_content="狗是很好的伴侣,以忠诚和友善而闻名。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="猫是独立的宠物,经常享受自己的空间。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="金鱼是深受初学者欢迎的宠物,需要相对简单的护理。",
metadata={"source": "fish-pets-doc"},
),
Document(
page_content="鹦鹉是一种聪明的鸟类,能够模仿人类的语言。",
metadata={"source": "bird-pets-doc"},
),
Document(
page_content="兔子是群居动物,需要足够的空间来跳跃。",
metadata={"source": "mammal-pets-doc"},
),
]
API Reference:Document
在这里,我们生成了五个文档,其中包含指示三个不同“来源”的元数据(mammal-pets-doc、fish-pets-doc、bird-pets-doc)。
VectorStore
向量搜索是存储和搜索非结构化数据(例如非结构化文本)的常用方法。这个想法是存储与文本关联的数字向量。给定一个查询,我们可以将嵌入为相同维度的向量,并使用向量相似度度量来识别存储中的相关数据。
LangChain VectorStore 对象包含用于添加文本和 Document对象记录到存储中,并使用各种相似度指标查询它们。它们通常用 嵌入模型,它确定如何将文本数据转换为数字向量。
LangChain 包括一套与不同矢量存储技术的集成。一些矢量存储由提供商(例如,各种云提供商)托管,需要特定的凭据才能使用;一些(例如 Postgres)在单独的基础架构中运行,可以在本地或通过第三方运行;其他人可以在内存中运行以实现轻量级工作负载。
在这里,我们将使用 Chroma,Chroma 是一个AI原生开源矢量数据库,专注于开发人员的生产力和幸福感。其中包括一个内存实现。
OpenAI 嵌入
要实例化向量存储,我们通常需要提供一个嵌入模型以指定如何将文本转换为数字向量。这里我们将使用 OpenAI嵌入。
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(
documents,
embedding=OpenAIEmbeddings(),
)
**API Reference: **OpenAIEmbeddings
DashScope 嵌入(灵积模型)
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
vectorstore = Chroma.from_documents(
documents,
embedding=DashScopeEmbeddings(),
)
调用 .from_documents 将文档添加到矢量存储中。VectorStore 实现了添加文档的方法,这些文档也可以在对象实例化后调用。大多数实现将允许您连接到现有的向量存储——例如,通过提供客户端、索引名称或其他信息。有关特定的 集成了解更多细节。
一旦我们实例化了一个 VectorStore包含文档,我们可以查询它。 VectorStore包括查询方法:
- 同步和异步;
- 通过字符串查询和向量;
- 有和没有返回相似度分数;
- 通过相似性和最大边际相关性(平衡相似性与查询到检索结果的多样性)。
这些方法通常会在其输出中包含 Document 对象的列表。
搜索实例
根据与字符串查询的相似性返回文档:
from langchain_core.documents import Document
# 构造文档
documents = [
Document(
page_content="狗是很好的伴侣,以忠诚和友善而闻名。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="猫是独立的宠物,经常享受自己的空间。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="金鱼是深受初学者欢迎的宠物,需要相对简单的护理。",
metadata={"source": "fish-pets-doc"},
),
Document(
page_content="鹦鹉是一种聪明的鸟类,能够模仿人类的语言。",
metadata={"source": "bird-pets-doc"},
),
Document(
page_content="兔子是群居动物,需要足够的空间来跳跃。",
metadata={"source": "mammal-pets-doc"},
),
]
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
# 创建 Chroma 向量存储
vectorstore = Chroma.from_documents(
documents,
embedding=DashScopeEmbeddings(),
)
# 查询向量存储
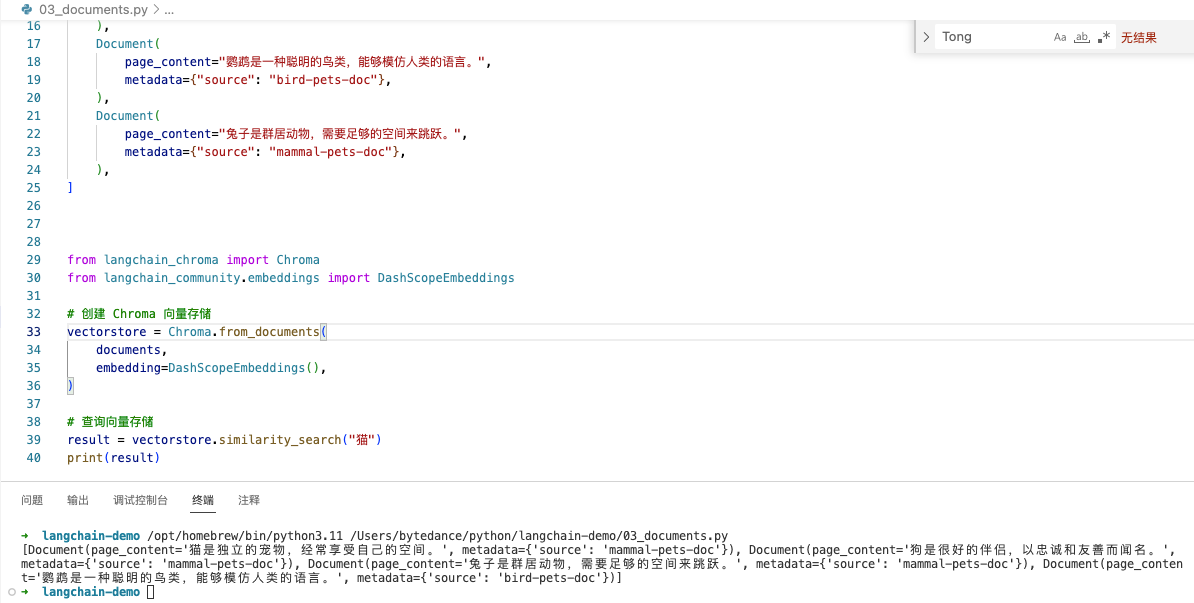
result = vectorstore.similarity_search("猫")
print(result)
运行结果:
[Document(page_content='猫是独立的宠物,经常享受自己的空间。', metadata={'source': 'mammal-pets-doc'
}), Document(page_content='狗是很好的伴侣,以忠诚和友善而闻名。', metadata={'source': 'mammal-pets-doc'
}), Document(page_content='兔子是群居动物,需要足够的空间来跳跃。', metadata={'source': 'mammal-pets-doc'
}), Document(page_content='鹦鹉是一种聪明的鸟类,能够模仿人类的语言。', metadata={'source': 'bird-pets-doc'
})
]
异步查询
from langchain_core.documents import Document
# 构造文档
documents = [
Document(
page_content="狗是很好的伴侣,以忠诚和友善而闻名。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="猫是独立的宠物,经常享受自己的空间。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="金鱼是深受初学者欢迎的宠物,需要相对简单的护理。",
metadata={"source": "fish-pets-doc"},
),
Document(
page_content="鹦鹉是一种聪明的鸟类,能够模仿人类的语言。",
metadata={"source": "bird-pets-doc"},
),
Document(
page_content="兔子是群居动物,需要足够的空间来跳跃。",
metadata={"source": "mammal-pets-doc"},
),
]
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
# 创建 Chroma 向量存储
vectorstore = Chroma.from_documents(
documents,
embedding=DashScopeEmbeddings(),
)
# 查询向量存储
# result = vectorstore.similarity_search("猫")
async def asnc_search():
result = await vectorstore.asimilarity_search("猫")
print(result)
if __name__ == "__main__":
import asyncio
asyncio.run(asnc_search())
[Document(page_content='猫是独立的宠物,经常享受自己的空间。', metadata={'source': 'mammal-pets-doc'
}), Document(page_content='狗是很好的伴侣,以忠诚和友善而闻名。', metadata={'source': 'mammal-pets-doc'
}), Document(page_content='兔子是群居动物,需要足够的空间来跳跃。', metadata={'source': 'mammal-pets-doc'
}), Document(page_content='鹦鹉是一种聪明的鸟类,能够模仿人类的语言。', metadata={'source': 'bird-pets-doc'
})
]
返回分数
from langchain_core.documents import Document
# 构造文档
documents = [
Document(
page_content="狗是很好的伴侣,以忠诚和友善而闻名。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="猫是独立的宠物,经常享受自己的空间。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="金鱼是深受初学者欢迎的宠物,需要相对简单的护理。",
metadata={"source": "fish-pets-doc"},
),
Document(
page_content="鹦鹉是一种聪明的鸟类,能够模仿人类的语言。",
metadata={"source": "bird-pets-doc"},
),
Document(
page_content="兔子是群居动物,需要足够的空间来跳跃。",
metadata={"source": "mammal-pets-doc"},
),
]
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
# 创建 Chroma 向量存储
vectorstore = Chroma.from_documents(
documents,
embedding=DashScopeEmbeddings(),
)
# 查询向量存储
result = vectorstore.similarity_search_with_score("猫")
print(result)
[
(Document(page_content='猫是独立的宠物,经常享受自己的空间。', metadata={'source': 'mammal-pets-doc'}),6132.1220703125),
(Document(page_content='狗是很好的伴侣,以忠诚和友善而闻名。', metadata={'source': 'mammal-pets-doc'}),9821.0986328125),
(Document(page_content='兔子是群居动物,需要足够的空间来跳跃。', metadata={'source': 'mammal-pets-doc'}),12847.712890625),
(Document(page_content='鹦鹉是一种聪明的鸟类,能够模仿人类的语言。', metadata={'source': 'bird-pets-doc'}),13557.1650390625)
]
根据与嵌入式查询的相似性返回文档:
from langchain_core.documents import Document
# 构造文档
documents = [
Document(
page_content="狗是很好的伴侣,以忠诚和友善而闻名。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="猫是独立的宠物,经常享受自己的空间。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="金鱼是深受初学者欢迎的宠物,需要相对简单的护理。",
metadata={"source": "fish-pets-doc"},
),
Document(
page_content="鹦鹉是一种聪明的鸟类,能够模仿人类的语言。",
metadata={"source": "bird-pets-doc"},
),
Document(
page_content="兔子是群居动物,需要足够的空间来跳跃。",
metadata={"source": "mammal-pets-doc"},
),
]
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
# 创建 Chroma 向量存储
vectorstore = Chroma.from_documents(
documents,
embedding=DashScopeEmbeddings(),
)
# 查询向量存储
embedding = DashScopeEmbeddings().embed_query("猫")
result = vectorstore.similarity_search_by_vector(embedding)
print(result)
[Document(page_content='猫是独立的宠物,经常享受自己的空间。', metadata={'source': 'mammal-pets-doc'
}), Document(page_content='狗是很好的伴侣,以忠诚和友善而闻名。', metadata={'source': 'mammal-pets-doc'
}), Document(page_content='兔子是群居动物,需要足够的空间来跳跃。', metadata={'source': 'mammal-pets-doc'
}), Document(page_content='鹦鹉是一种聪明的鸟类,能够模仿人类的语言。', metadata={'source': 'bird-pets-doc'
})
]
了解更多:
- VectorStore API引用
- 如何指导
- Integration-specific文档
Retrievers
LangChain VectorStore 对象不是子类 可运行,因此不能立即集成到 LangChain 表达式语言中 链。
朗链 检索器是Runnables,因此它们实现了一组标准方法(例如,同步和异步 invoke 和 batch 操作)并被设计为合并到LCEL链中。
我们可以自己创建一个简单的版本,无需子类化 Retriever。如果我们选择希望使用什么方法来检索文档,我们可以轻松创建一个可运行的。下面我们将围绕 similarity_search 方法:
from langchain_core.documents import Document
# 构造文档
documents = [
Document(
page_content="狗是很好的伴侣,以忠诚和友善而闻名。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="猫是独立的宠物,经常享受自己的空间。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="金鱼是深受初学者欢迎的宠物,需要相对简单的护理。",
metadata={"source": "fish-pets-doc"},
),
Document(
page_content="鹦鹉是一种聪明的鸟类,能够模仿人类的语言。",
metadata={"source": "bird-pets-doc"},
),
Document(
page_content="兔子是群居动物,需要足够的空间来跳跃。",
metadata={"source": "mammal-pets-doc"},
),
]
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
# 创建 Chroma 向量存储
vectorstore = Chroma.from_documents(
documents,
embedding=DashScopeEmbeddings(),
)
# 查询向量存储
from langchain_core.runnables import RunnableLambda
retriever = RunnableLambda(vectorstore.similarity_search).bind(k=1) # 选择顶部结果
result = retriever.batch(["猫", "鲨鱼"])
print(result)
API Reference:Document | RunnableLambda
运行结果: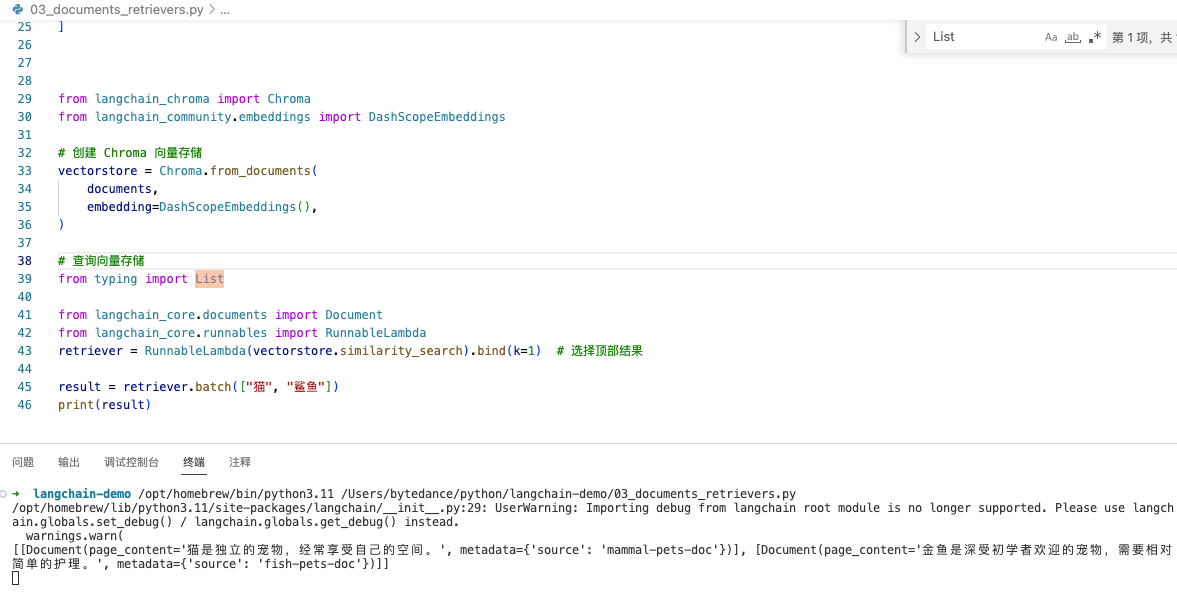
[
[Document(page_content='猫是独立的宠物,经常享受自己的空间。', metadata={'source': 'mammal-pets-doc'
})
],
[Document(page_content='金鱼是深受初学者欢迎的宠物,需要相对简单的护理。', metadata={'source': 'fish-pets-doc'
})
]
]
Vectorstore 实现了一个 as_retriever 将生成 Retriever 的方法,特别是 VectorStoreRetriever。这些检索器包括特定的 search_type 和 search_kwargs 属性,用于标识要调用的底层向量存储的哪些方法,以及如何参数化它们。例如,我们可以使用以下内容复制上述内容:
from langchain_core.documents import Document
# 构造文档
documents = [
Document(
page_content="狗是很好的伴侣,以忠诚和友善而闻名。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="猫是独立的宠物,经常享受自己的空间。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="金鱼是深受初学者欢迎的宠物,需要相对简单的护理。",
metadata={"source": "fish-pets-doc"},
),
Document(
page_content="鹦鹉是一种聪明的鸟类,能够模仿人类的语言。",
metadata={"source": "bird-pets-doc"},
),
Document(
page_content="兔子是群居动物,需要足够的空间来跳跃。",
metadata={"source": "mammal-pets-doc"},
),
]
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
# 创建 Chroma 向量存储
vectorstore = Chroma.from_documents(
documents,
embedding=DashScopeEmbeddings(),
)
# 查询向量存储
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 1},
)
result = retriever.batch(["猫", "鲨鱼"])
print(result)
运行结果: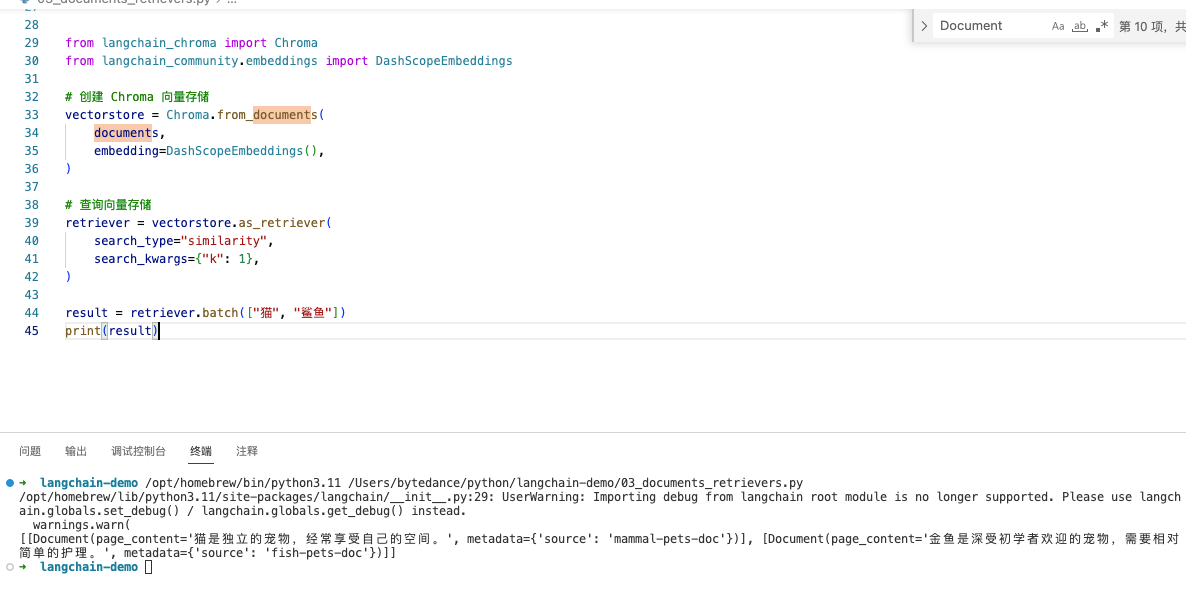
[
[Document(page_content='猫是独立的宠物,经常享受自己的空间。', metadata={'source': 'mammal-pets-doc'
})
],
[Document(page_content='金鱼是深受初学者欢迎的宠物,需要相对简单的护理。', metadata={'source': 'fish-pets-doc'
})
]
]
VectorStoreRetriever 支持搜索类型 “similarity”(默认), “mmr”(最大边际相关性,如上所述),以及
"similarity_score_threshold"。我们可以使用后者根据相似度分数对检索器输出的文档进行阈值。
检索器可以很容易地合并到更复杂的应用程序中,例如检索增强生成(RAG)应用程序,它将给定问题与检索到的上下文组合成LLM的提示。下面我们展示一个最小的例子。
from langchain_core.documents import Document
# 构造文档
documents = [
Document(
page_content="狗是很好的伴侣,以忠诚和友善而闻名。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="猫是独立的宠物,经常享受自己的空间。",
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="金鱼是深受初学者欢迎的宠物,需要相对简单的护理。",
metadata={"source": "fish-pets-doc"},
),
Document(
page_content="鹦鹉是一种聪明的鸟类,能够模仿人类的语言。",
metadata={"source": "bird-pets-doc"},
),
Document(
page_content="兔子是群居动物,需要足够的空间来跳跃。",
metadata={"source": "mammal-pets-doc"},
),
]
# 构造 prompt
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
message = """
仅使用提供的上下文回答此问题。
{question}
上下文:
{context}
"""
prompt = ChatPromptTemplate.from_messages([("human", message)])
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
# 创建 Chroma 向量存储
vectorstore = Chroma.from_documents(
documents,
embedding=DashScopeEmbeddings(),
)
# 查询向量存储
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 1},
)
# 使用 Tongyi LLM,并设置温度为 1,代表模型会更加随机,但也会更加不确定
from langchain_community.llms import Tongyi
llm = Tongyi(temperature=1)
# 构建 RAG 链
rag_chain = {"context": retriever, "question": RunnablePassthrough()} | prompt | llm
# 使用 RAG 链并打印结果
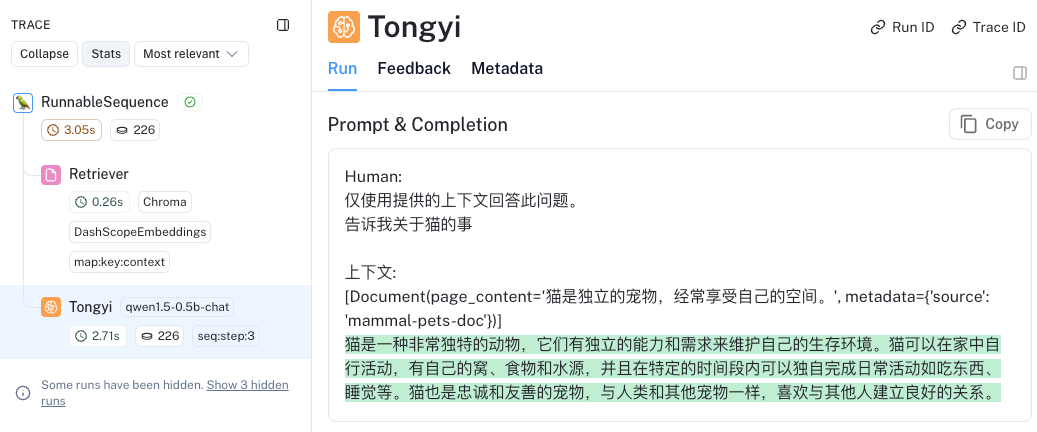
response = rag_chain.invoke("告诉我关于猫的事")
print(response)
API Reference:ChatPromptTemplate | RunnablePassthrough
运行结果: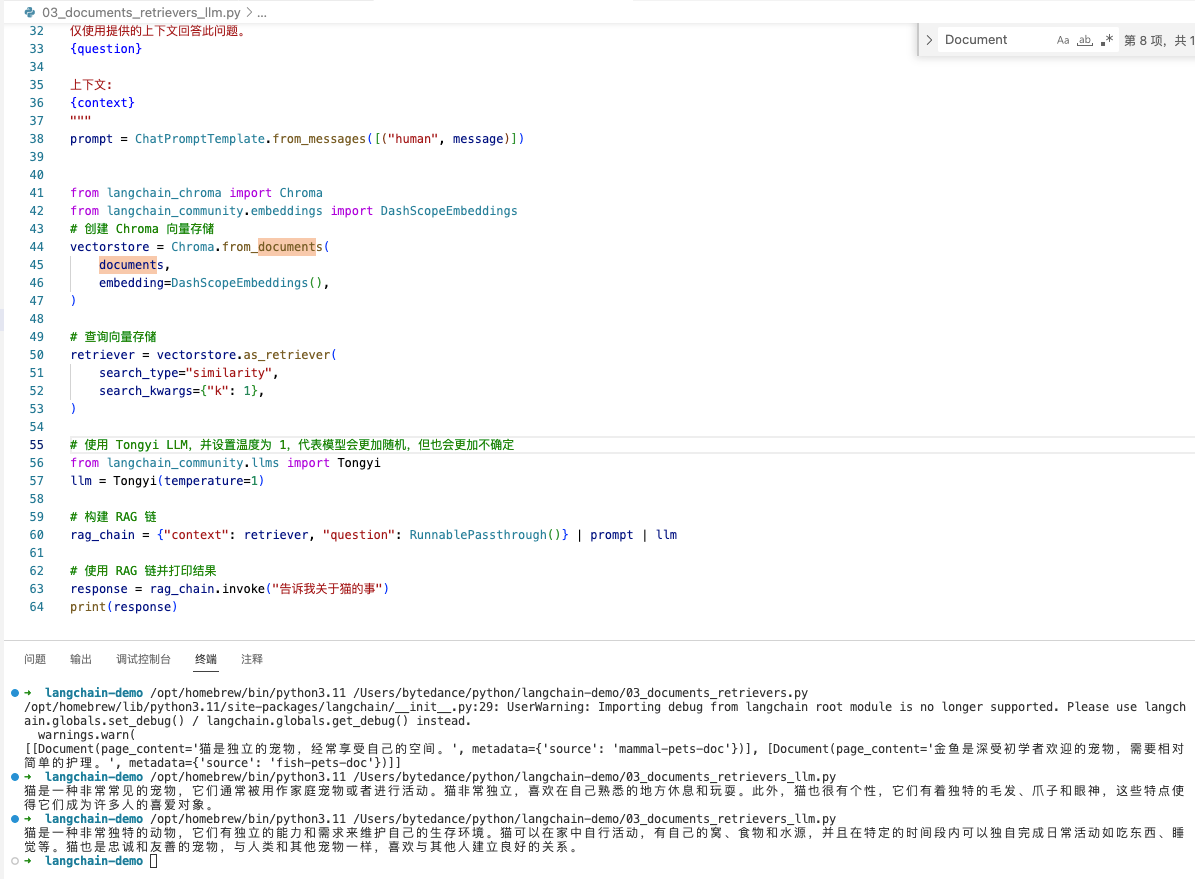
langsmith 日志:搜索日志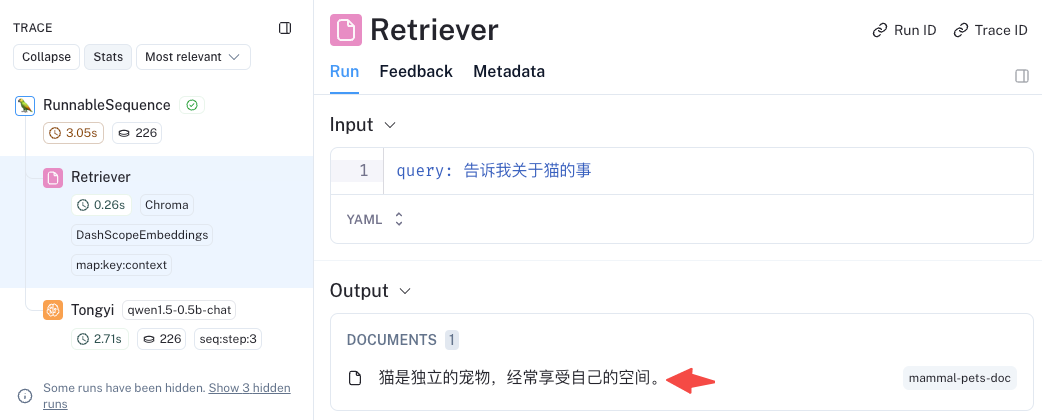
小结
本文我们了解了 Documents、VectorStore 、Retrievers 的简单用法,作为目前最火的 RAG 应用方向,值得我们深入去了解学习。
如果想继续深入,我们可以了解以下内容,比如检索策略可能丰富而复杂。
- 我们可以从查询中推断出硬规则和过滤器(例如,“使用2020年之后发布的文档”);
- 我们可以以某种方式(例如,通过某些文档分类)返回链接到检索到的上下文的文档;
- 我们可以为每个上下文单元生成多个嵌入;
- 我们可以从多个检索器集成结果;
- 我们可以为文档分配权重,例如,将最近的文档的权重提高。
操作指南的检索器部分涵盖了这些和其他内置检索策略。扩展BaseRetriever类以实现自定义检索器也很简单。请参阅我们的操作指南 此处。
本文由博客一文多发平台 OpenWrite 发布!
-
vscode 打开终端-icode9专业技术文章分享07-16
-
vscode 设置内存-icode9专业技术文章分享07-16
-
INFINI Easysearch 尝鲜 Hands on07-15
-
Easysearch 数据可视化和管理平台:INFINI Console 使用介绍07-15
-
我用cpca 截取地址中的省市区,突然就乱了,这是什么原因07-15
-
无限可能LangChain——开启大模型世界07-15
-
无限可能LangChain——构建一个简单的LLM应用程序07-15
-
无限可能LangChain——构建聊天机器人07-15
-
“粘土风格”轻松拿捏,基于函数计算部署 ComfyUI实现AI生图07-15
-
IDC行业新动向:政策引领、技术创新与投资热潮共绘未来蓝图07-15
-
AIGC如何助力创意设计低成本、快速、高效的创作优质内容?07-15
-
IDC调查揭示了3个行业将面临人工智能显著颠覆!07-15
-
AutoMQ 产品动态 | 发布 1.1.0,兼容至 Apache Kafka 3.7,支持 Kaf07-15
-
云原生周刊:Score 成为 CNCF 沙箱项目|2024.7.1507-15
-
易优如何解除绑定微信公众号-icode9专业技术文章分享07-14
