消息队列MQ
AutoMQ 中的元数据管理

本文所述 AutoMQ 的元数据管理机制均基于 AutoMQ Release 1.1.0 版本 [1]。
01
前言
AutoMQ 作为新一代基于云原生理念重新设计的 Apache Kafka 发行版,其底层存储从传统的本地磁盘替换成了以对象存储为主的共享存储服务。对象存储为 AutoMQ 带来可观成本优势的同时,其与传统本地磁盘的接口和计费方式的差异也为 AutoMQ 在实现上带来了挑战,为解决这一问题,AutoMQ 基于 KRaft 进行拓展,实现了一套针对对象存储环境的流存储元数据管理机制,在兼顾成本的同时,极大的保证了基于对象存储的读写性能。
02
AutoMQ 需要哪些元数据
KV 元数据
在之前的文章中(AutoMQ 如何做到 Apache Kafka 100% 协议兼容 [2]),我们介绍过了 AutoMQ 的存储层如何基于 S3Stream [3] 实现对对象存储服务的流式读写的,每个分区都有与之对应的多个 Stream 来分别负责存储分区的元数据、消息、Time Index、Txn Index 等。AutoMQ 通过 KV 元数据来保存分区所对应的 MetaStream 的 StreamId,从而保证分区在不同节点打开时都能正确获得与 Stream 的映射关系。
Stream 元数据
由于分区和 Stream 有着一对多的映射关系,当分区发生迁移、数据写入、位点 Trim 等事件时,其对应的 Stream 状态也会相应发生变化。因此 AutoMQ 对每个 Stream 都维护了相应的元数据,主要由以下部分组成:
-
Stream Epoch:当分区发生迁移时,会提升对应的 Stream Epoch,后续所有对 Stream 的操作都需要对 Epoch 进行检查,保证只有 Stream 当前所在节点能够对 Stream 进行操作
-
Start Offset:用于表示 Stream 的起始位点,当分区发生 Trim 时,其对应的 Stream 的起始位点也会被相应更新
-
End Offset:用于表示 Stream 的最大位点,当分区消息成功写入并提交后,Stream 的最大位点也会相应推进
-
Ranges:随着分区的迁移,Stream 也会在不同的节点上产生数据,Ranges 保存着 Stream 在各个节点打开期间的位点变化,在后文中会具体介绍 Ranges 的作用
-
StreamObjects:用于保存 Stream 对应的 StreamObject 的 ObjectId,以及在相应 Object 上的位点范围
每当 Controller 接收到 Stream 的相关操作时(如 create, open, commit, trim 等),都会产生相应的 S3StreamRecord,通过 KRaft 层持久化后将状态更新到内存中,并同步更新到各个 Broker 的元数据缓存。
Node 元数据
Node 元数据由以下部分组成:
-
Node Id:即节点 Id
-
Node Epoch:即节点 Epoch,与 Stream Epoch 作用类似,当节点发生重启时会提升相应的 Node Epoch,来保证只有带有最新 Epoch 的节点能够进行 Stream 相关操作
-
Failover Mode:用于标识当前节点是否处在 Failover 模式(关于 AutoMQ 的 Failover 能力会在后续的文章中介绍)
-
StreamSetObjects:用于保存当前节点产生的各个 StreamSetObject,以及各 Object 上不同 Stream 的位点索引信息
其中, Node Epoch 及 Failover Mode 会在节点首次启动时,通过 open streams 接口产生一条 NodeWALMetadataRecord 来进行更新,而 StreamSetObjects 则会在节点向 Controller 提交 StreamSetObject 时通过 S3StreamSetObjectRecord 更新。
Object 元数据
Object 元数据负责所有对象存储对象的生命周期管理,包括对象的状态、大小、Key、过期时间、提交时间、标记删除时间等。
03
整体流程
本节将介绍 AutoMQ 如何在各个阶段利用上述介绍的元数据实现对对象存储的高效利用。
分区打开
分区打开时,节点会先向 Controller 请求该分区对应的 MetaStream Id,若 MetaStream 不存在,则表示该分区为首次创建,此时节点会为该分区创建一个 MetaStream 并将分区到 MetaStream 的映射关系发送给 Controller,Controller 收到后根据 Key 和 Value 创建出 KVRecord,通过 KRaft 层持久化后将 KV 映射关系写入内存中。若 MetaStream 存在,则从 MetaStream 中读取出分区各 Segment 对应的 Stream 的信息,从而能够使得后续对分区的读写能够正确转换为对 Stream 的读写。
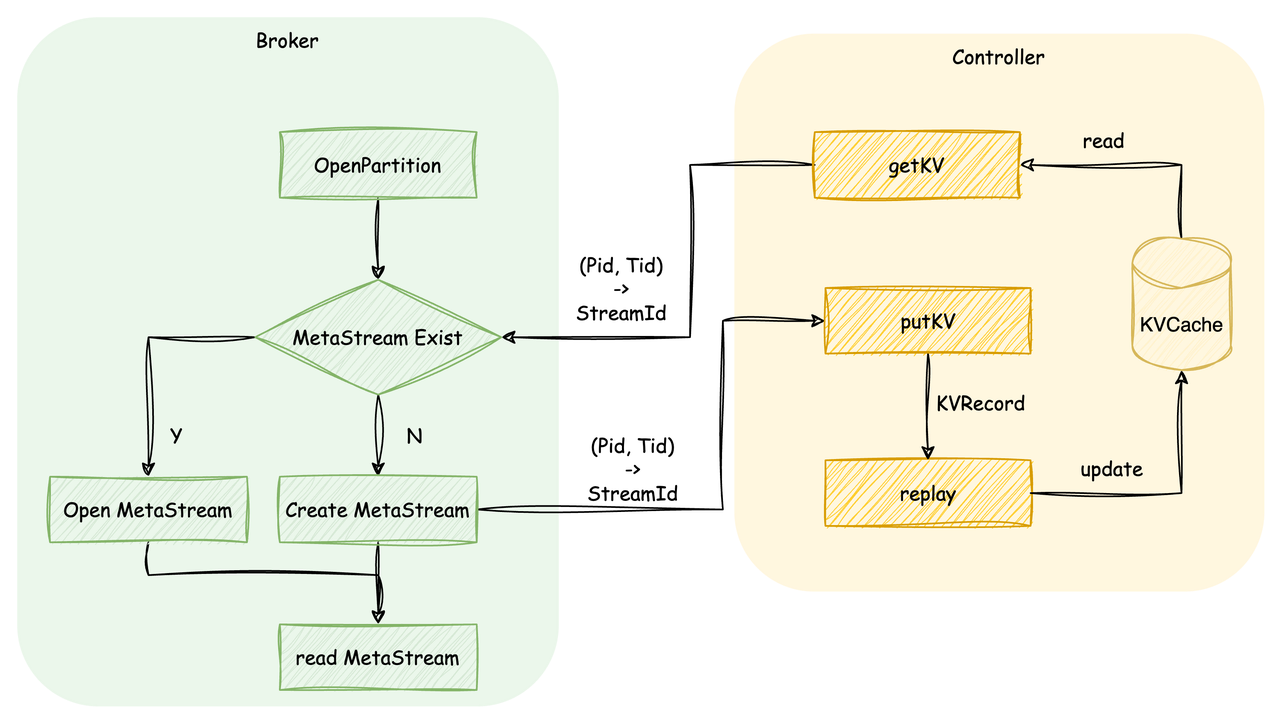
分区数据写入
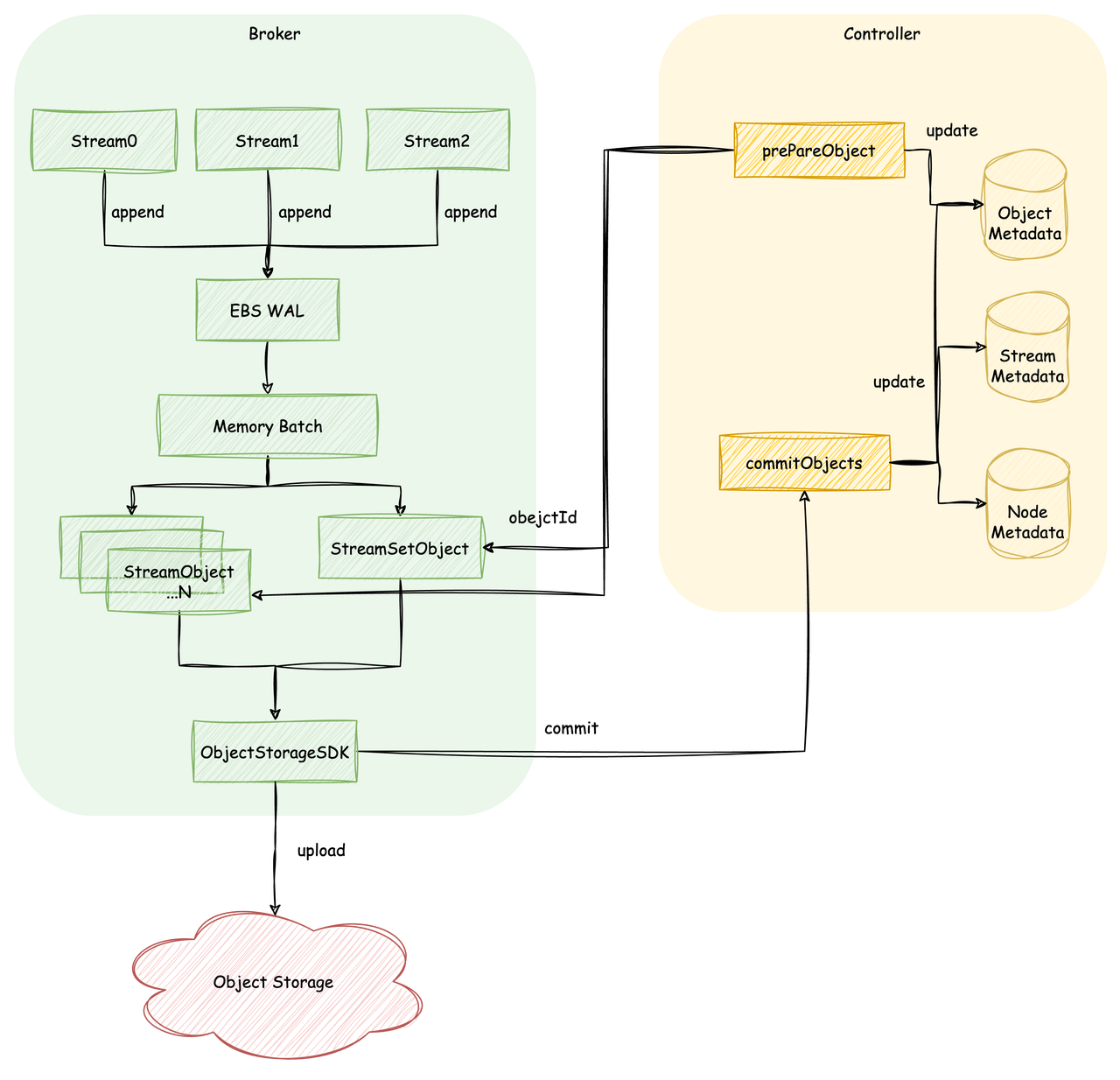
所有针对分区的写入通过上述 MetaStream 中解析出的映射关系,最终都会转变为对 Stream 的写入,而所有 Stream 写入的数据都会首先写入 EBS WAL,持久化成功后直接向上层返回结果;同时写入的数据会继续在内存中进行混合攒批,直到攒批大小超过阈值时触发上传。上传触发后,节点会遍历此次攒批的数据中的各个 Stream,将连续数据段超过一定阈值大小的上传为 StreamObject,剩余数据上传为 StreamSetObject。每个 Object 上传时,节点会先向 Controller 申请全局唯一的 Object Id,此时 Controller 的 Object 元数据中会记录下该 Object 的状态和过期时间,节点通过 Object Id 生成对象存储的写入路径并上传数据。当本次上传任务产生的所有 Object 全部写入完成后,节点会向 Controller 发起 Commit 请求,Controller 将产生一系列 KRaft Record 更新元数据:
-
Object 元数据:将此次提交的 Object 状态从 PREPARED 置为 COMMITTED
-
Stream 元数据:推进此次提交的批数据中的各 Stream 最大位点,以及更新 Stream 对应的 StreamObjects
-
Node 元数据:更新对应节点的 StreamSetObjects
若在上传过程中,节点发生异常导致上传终止,Controller 则会通过定时任务将超出过期时间依旧未提交的 Object 删除,以避免对象泄漏。
分区数据读取
分区数据的读取同样会转换为对 Stream 的读取,当需要读取的数据段已不再存在于节点缓存中时,就需要向对象存储发起读取,而通过上文介绍的分区写入流程,我们已经知道元数据中已经保存了 Stream 各数据段所在的 Object,此时只需从元数据中索引出需要读取的数据段对应的 Object 列表,再向对象存储发起读取请求即可。这里需要注意的是,由于 AutoMQ 的元数据全部基于 KRaft 机制构建,故上述的元数据变更全部会跟随 KRaft Record 的同步而分发到每台节点上,也即每台 Broker 都缓存有最新的元数据信息,所以索引的过程全部发生在本地缓存中。具体的索引流程如下:
-
首先从本地的 Stream 元数据缓存中获取 Stream 对应的 StreamObjects,由于每一个 StreamObject 都对应着 Stream 的一个连续数据段,此时只需从第一个 StreamObject 开始遍历,并将满足范围的加入到结果中,直到遇到第一个超出期望读取的数据范围的 StreamObject,或所有 StreamObject 都已被遍历完毕。
-
当对 StreamObject 的遍历退出后,若此时还未满足期望的读取范围,则意味着接下来的数据存在于 StreamSetObject 中,从上述元数据介绍中我们知道,Stream 元数据中记录了 Ranges 信息,其对应着 Stream 在不同节点上的位点范围。而 Ranges 是一个按位点顺序排列的有序列表,此时只需通过一次二分查找即可找到当前期望数据段所在的 Range,和对应 Range 所在的 Node Id。
-
找到 Node Id 后即可在 Node 元数据中获取该 Node 对应的 StreamSetObejcts,而每个 StreamSetObject 中都保存了组成该 Object 的各 Stream 的位点信息,此时对 StreamSetObjects 进行一次遍历,即可获得符合当前期望数据段的 StreamSetObject。
-
当 StreamSetObjects 遍历完成后,可能依旧存在期望读取的数据还未得到满足的情况,此时会再次进入步骤 1,从上次一的 StreamObject 遍历点开始继续下一轮搜索,直到请求范围得到满足;或因为元数据同步延迟等原因,所有 Object 均遍历完毕依旧没能满足请求,此时会直接将部分满足的请求返回,等待下次请求重试。
可以看到,由于 StreamSetObject 构成的复杂性,索引的大多数成本花费在了对 StreamSetObject 的搜索中,为提升索引速度,AutoMQ 还额外实现了 Compaction 机制,能够使得 Stream 的大多数数据都存在于 StreamObject 中(感兴趣的读者可参考:AutoMQ 对象存储数据高效组织的秘密: Compaction [4])。
04
总结
本文介绍了 AutoMQ 基于 KRaft 的元数据管理机制,相比传统基于 Zookeeper 的元数据管理,Controller 由于成为了所有元数据的处理节点,其稳定性对系统的正常运行起到了至关重要的作用,而 AutoMQ 在进一步拓展了对象存储相关的元数据后,对 Controller 节点的稳定性也提出了更高的要求。为此,AutoMQ 团队也在持续优化元数据规模和索引效率,保障在单一超大规模集群下的高效稳定运行。
参考资料
[1] AutoMQ Release 1.1.0:https://github.com/AutoMQ/automq/releases/tag/1.1.0
[2] AutoMQ 如何做到 Apache Kafka 100% 协议兼容:https://mp.weixin.qq.com/s/ZOTu5fA0FcAJlCrCJFSoaw
[3] S3Stream: A Shared Streaming Storage Library:https://github.com/AutoMQ/automq/tree/main/s3stream
[4] AutoMQ 对象存储数据高效组织的秘密: Compaction:https://mp.weixin.qq.com/s/z_JKxWQ8YCMs-fbC42C0Lg
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com?utm_source=openwrite
-
MQ-2烟雾传感器详解12-21
-
Kafka消息丢失资料:新手入门指南12-09
-
Kafka消息队列入门:轻松掌握Kafka消息队列12-07
-
Kafka消息队列入门:轻松掌握消息队列基础知识12-07
-
Kafka重复消费入门:轻松掌握Kafka消费的注意事项与实践12-07
-
Kafka重复消费入门教程12-07
-
RabbitMQ入门详解:新手必看的简单教程12-07
-
RabbitMQ入门:新手必读教程12-07
-
Kafka解耦学习入门教程12-06
-
Kafka入门教程:快速上手指南12-06
-
Kafka解耦入门教程:实现系统间高效通信12-06
-
Kafka消息队列入门教程:从零开始轻松掌握12-06
-
RabbitMQ入门指南:轻松搭建与使用教程12-06
-
知乎启用AutoMQ替换Kafka,开辟成本优化与运维提效新纪元12-02
-
海外开发者为 AutoMQ 写的精品介绍,太干了!11-27
