人工智能学习
AI 大模型应用开发实战(04)-AI生态产业拆解

1 行业全景图
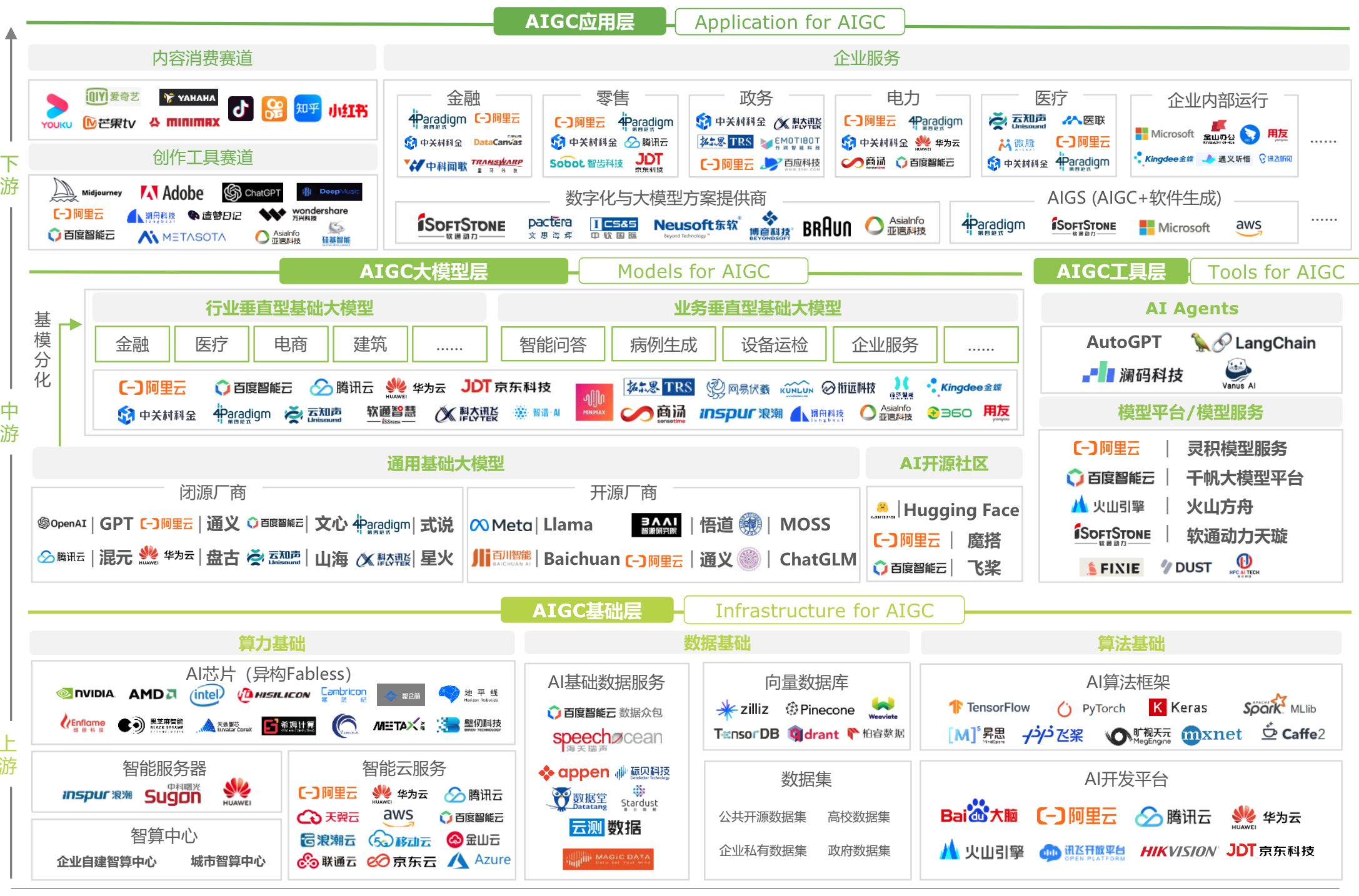
2 结构拆解AI GC
生成式AI这个产业。分成上中下游三大块。
2.1 上游基础层
主要包括:
- 算力:包括AI芯片和云服务等,例如像英伟达、AMD以及华为等厂商提供的算力基础设施。大型模型基于Transformer架构,对算力的需求很大。
- 数据:新时代的石油,分为基础数据服务、数据集和向量数据库。
- 算法:算法基础包括TensorFlow、PyTorch等著名算法框架,以及百度、阿里、腾讯等公司提供的AI开发平台。
这是AI的基础,也是过去AI研究的重点。
2.2 中游-AIGC大模型层和工具层
大模型层分为:
- 通用模型:如OpenAI、腾讯的宏源、百度的1000万等,
- 行业模型,根据具体行业或业务进行微调或二次训练。工具层包括AI Agent,其中包括像OutGPT这样的工具,以及模型平台和模型服务等
2.3 下游应用层
包括:
- 内容消费:在各种平台上生成内容,如抖音、快手等
- 创作工具:提供基于AI的工具,如MID Generate
- 企业服务:根据行业提供各种应用,如微软、亚马逊等
产业中,我们的位置是在AI GC工具层,即AI Agent层,作为中间件,承上启下。应用开发者的位置可能更多在中游和下游,发挥着重要作用。
3 名词解释
当然,可以按以下类别对这些概念进行细分解释:
3.1 模型与架构
- LLM (大型语言模型):具有大量参数,能处理复杂语言任务的模型。
- chatGPT:一种用于生成对话的自然语言处理模型。
- RWKV:结合RNN和Transformer优点的神经网络架构。
- CNN (卷积神经网络):一种擅长处理图像数据的神经网络。
- RNN (循环神经网络):处理序列数据的神经网络。
- stable diffusion:一种用于生成图像的扩散模型。
- DALL·E:OpenAI开发的生成图像的模型。
- RAG (检索增强生成):结合检索和生成的模型。
- AIGC (人工智能生成内容):指利用AI生成文本、图像等内容的技术。
3.2 技术与方法
-
多模态:处理多种不同类型数据的模型。支持多种形态的模型,如文字、图像、音频等
-
自监督学习:利用数据本身结构进行训练的方法。
-
预训练:在大规模数据上训练模型,以获得初始参数。
-
Few-shot:使用少量样本进行训练和推理的能力。
-
One-shot:使用单个样本进行训练和推理的能力。
-
Zero-shot:无需样本也能进行推理的能力。
-
Temperature:控制生成模型输出多样性的参数。
-
RLHF (基于人类反馈的强化学习):通过人类反馈优化AI行为的方法。
-
Fine-tunes:在预训练模型基础上,进行特定任务的微调。
-
向量搜索:通过向量化表示进行高效搜索的方法。
-
向量数据库:存储和检索向量化数据的数据库。
-
NLP (自然语言处理):处理和生成自然语言的技术。
-
CV (计算机视觉):理解和生成图像和视频的技术。
-
分析式AI:侧重于分析和理解数据的AI。
-
知识图谱:以图结构表示知识及其关系的数据结构。
-
过拟合:模型过度拟合训练数据而无法泛化到新数据的现象。
-
AI推理:AI对数据进行推断和决策的过程。
-
生成对抗网络:通过两个网络的对抗来提高生成结果质量的方法。一种神经网络类型,用于生成真实的图像。(Generative Adversarial Networks, GANs)是一种由 Ian Goodfellow 等人在 2014 年提出的深度学习模型。GANs 通过两个网络(生成器和判别器)相互对抗的方式来提高生成结果的质量。这两个网络的具体角色和对抗机制如下:
-
生成器(Generator):生成器接受一个随机噪声向量作为输入,并生成伪造的数据(例如图像)。它的目标是生成尽可能真实的数据,以便欺骗判别器。
-
判别器(Discriminator):判别器接受真实数据和生成器生成的伪造数据,并试图区分两者。判别器的目标是尽可能准确地识别出哪些数据是真实的,哪些是伪造的。
在训练过程中,生成器和判别器会交替优化自己的参数:
- 生成器的目标是生成越来越真实的伪造数据,以使判别器难以区分真假数据。
- 判别器的目标是提高其区分能力,准确判断数据的真假。
这种对抗机制形成了一个零和游戏,最终生成器会生成出非常逼真的数据,使得判别器难以辨别其真假。
综上,生成对抗网络是一种通过两个网络的对抗来提高生成结果质量的方法,也是一种用于生成真实图像的神经网络类型。
-
-
元学习:学习如何学习的方法,提高模型在新任务上的适应能力。
-
并行训练:同时训练多个模型或在多台设备上训练单个模型的方法。
3.3 平台与工具
- HuggingFace:提供自然语言处理模型和工具的公司。
- openAI:开发和研究人工智能的机构。
- Azure:微软的云计算服务平台。
- Heygan:一种AI生成模型(可能是特定应用的名称)。
- Copilot:编程助手工具,帮助开发者编写代码。
- midjourney:AI驱动的艺术创作平台。
- D-ID:用于生成和处理数字身份的技术。
3.4 概念与其他
- 具身智能:具有物理存在并能与环境互动的人工智能。
- AGI (人工通用智能):具有通用认知能力的AI。
- AI-Agents:自主行动并完成任务的人工智能代理。使用AI代替人类执行任务的智能体
- RPM:每分钟旋转数(Rotations Per Minute),这里可能表示模型的训练速度。
- 知知识幻觉:模型生成的看似合理但错误的知识。
- 咒语:特定输入词汇或短语,用来触发模型生成特定输出。
- 哼唱:AI生成的音乐或音频。
- CDN (内容分发网络):用于加速网络内容传输。
- 上下文:模型生成内容时参考的前后文信息。
- 炼丹:指模型训练和调优过程的比喻。
- 炼炉:可能是某种训练或计算环境的比喻。
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都技术专家,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
- 中央/分销预订系统性能优化
- 活动&优惠券等营销中台建设
- 交易平台及数据中台等架构和开发设计
- 车联网核心平台-物联网连接平台、大数据平台架构设计及优化
- LLM应用开发
目前主攻降低软件复杂性设计、构建高可用系统方向。
参考:
- 编程严选网
-
从零开始学习贪心算法12-26
-
线性模型入门教程:基础概念与实践指南12-26
-
探索随机贪心算法:从入门到初级应用12-25
-
树形模型进阶:从入门到初级应用教程12-25
-
搜索算法进阶:新手入门教程12-25
-
算法高级进阶:新手与初级用户指南12-25
-
随机贪心算法进阶:初学者的详细指南12-25
-
贪心算法进阶:从入门到实践12-25
-
线性模型进阶:初学者的全面指南12-25
-
朴素贪心算法教程:初学者指南12-25
-
树形模型教程:从零开始的图形建模入门指南12-25
-
搜索算法教程:初学者必备指南12-25
-
算法高级教程:入门与初级用户指南12-25
-
随机贪心算法教程:初学者指南12-25
-
贪心算法教程:入门与实践指南12-25
