人工智能学习
3、最大池化maxinmum pooling

了解有关最大池化特征提取的更多信息。
简介
在第二课中,我们开始讨论卷积神经网络(convnet)的基础如何进行特征提取。我们了解了这个过程中的前两个操作是在带有 relu 激活的 Conv2D 层中进行的。
在这一课中,我们将看一下这个序列中的第三个(也是最后一个)操作:通过最大池化进行压缩,这在 Keras 中是通过 MaxPool2D 层完成的。
通过最大池化进行压缩
在我们之前的模型中添加压缩步骤,将得到以下结果:
In [1]:
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Conv2D(filters=64, kernel_size=3), # activation is None
layers.MaxPool2D(pool_size=2),
# More layers follow
])
MaxPool2D 层很像 Conv2D 层,只不过它使用一个简单的最大函数而不是内核,其中 pool_size 参数类似于 kernel_size。然而,MaxPool2D 层没有像卷积层在其内核中那样的可训练权重。
让我们再看一下上一课中的提取图。记住,MaxPool2D 是 Condense 步骤。

注意,应用 ReLU 函数(Detect)后,特征图最终会有很多“死区”,即只包含 0 的大面积区域(图像中的黑色区域)。如果让这些 0 激活值通过整个网络,将会增加模型的大小,而不会添加太多有用的信息。相反,我们希望压缩特征图,只保留最有用的部分——特征本身。
这实际上就是最大池化所做的。最大池化在原始特征图的激活块中取最大的激活值。
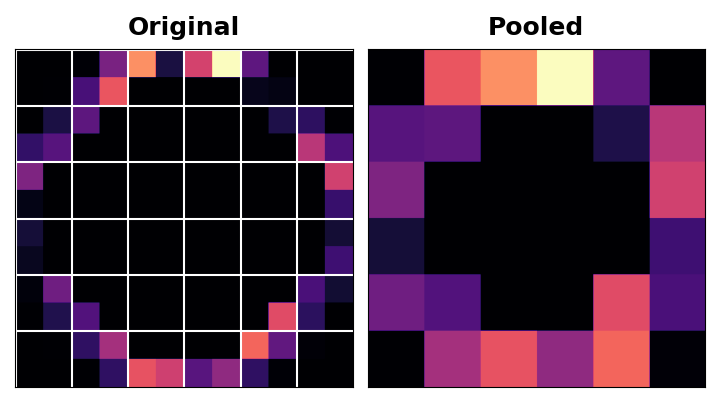
当在 ReLU 激活后应用时,它具有“强化”特征的效果。池化步骤增加了活动像素与零像素的比例。
示例 - 应用最大池化
让我们在第二课中的示例中添加“压缩”步骤。这个下一个隐藏单元将带我们回到我们之前的位置。
In [2]:
import tensorflow as tf
import matplotlib.pyplot as plt
import warnings
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
plt.rc('image', cmap='magma')
warnings.filterwarnings("ignore") # to clean up output cells
# Read image
image_path = '../input/computer-vision-resources/car_feature.jpg'
image = tf.io.read_file(image_path)
image = tf.io.decode_jpeg(image)
# Define kernel
kernel = tf.constant([
[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1],
], dtype=tf.float32)
# Reformat for batch compatibility.
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
image = tf.expand_dims(image, axis=0)
kernel = tf.reshape(kernel, [*kernel.shape, 1, 1])
# Filter step
image_filter = tf.nn.conv2d(
input=image,
filters=kernel,
# we'll talk about these two in the next lesson!
strides=1,
padding='SAME'
)
# Detect step
image_detect = tf.nn.relu(image_filter)
# Show what we have so far
plt.figure(figsize=(12, 6))
plt.subplot(131)
plt.imshow(tf.squeeze(image), cmap='gray')
plt.axis('off')
plt.title('Input')
plt.subplot(132)
plt.imshow(tf.squeeze(image_filter))
plt.axis('off')
plt.title('Filter')
plt.subplot(133)
plt.imshow(tf.squeeze(image_detect))
plt.axis('off')
plt.title('Detect')
plt.show();

我们将使用 tf.nn 中的另一个函数来应用池化步骤,即 tf.nn.pool。这是一个 Python 函数,它做的事情与你在模型构建时使用的 MaxPool2D 层相同,但是,作为一个简单的函数,直接使用更容易。
In [3]:
import tensorflow as tf
image_condense = tf.nn.pool(
input=image_detect, # image in the Detect step above
window_shape=(2, 2),
pooling_type='MAX',
# we'll see what these do in the next lesson!
strides=(2, 2),
padding='SAME',
)
plt.figure(figsize=(6, 6))
plt.imshow(tf.squeeze(image_condense))
plt.axis('off')
plt.show();

非常酷!希望你能看到池化步骤是如何通过在最活跃的像素周围压缩图像来强化特征的。
平移不变性
我们称零像素为“不重要”。这是否意味着它们根本不携带任何信息?实际上,零像素携带位置信息。空白空间仍然将特征定位在图像中。当 MaxPool2D 移除其中一些像素时,它移除了特征图中的一些位置信息。这给卷积网络赋予了一种称为平移不变性的属性。这意味着一个带有最大池化的卷积网络倾向于不通过图像中的位置来区分特征。(“平移”是改变某物位置而不旋转它或改变其形状或大小的数学词汇。)
观察当我们反复应用最大池化到以下特征图时会发生什么。
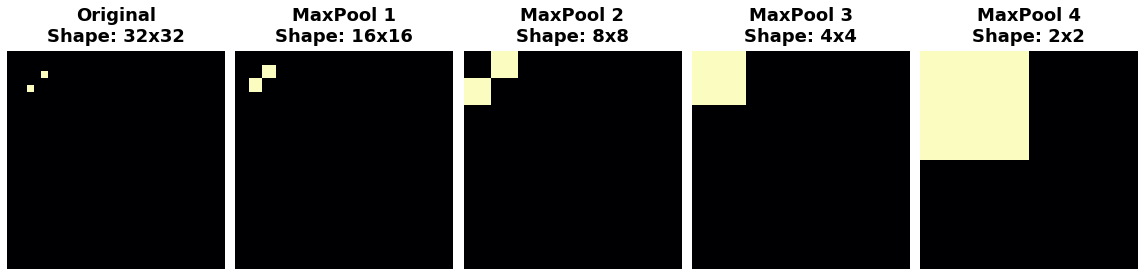
池化倾向于破坏位置信息
原始图像中的两个点在反复池化后变得无法区分。换句话说,池化破坏了它们的一些位置信息。由于网络在特征图中无法再区分它们,所以它也无法在原始图像中区分它们:它对位置差异已经不变。
实际上,池化只在网络中的小距离上创建平移不变性,就像图像中的两个点一样。开始时相距很远的特征在池化后仍然会保持不同;只有一些位置信息丢失了,但并非全部。
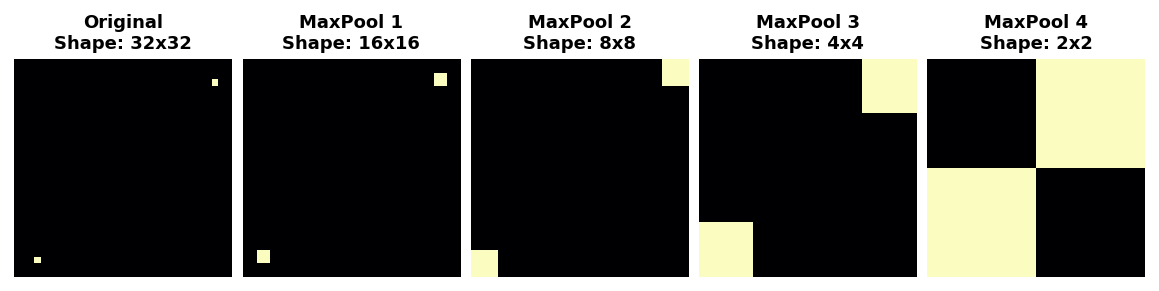
但只在小距离上。两个相距很远的点保持分离
对于图像分类器来说,对特征位置的小差异具有不变性是一个很好的属性。仅仅因为视角或构图的差异,同一种类型的特征可能会位于原始图像的各个部分,但我们仍然希望分类器能够识别出它们是相同的。因为这种不变性是内置在网络中的,我们可以使用更少的数据进行训练:我们不再需要教它忽略那种差异。这使得卷积网络比只有密集层的网络具有很大的效率优势。(你将在第6课中看到另一种免费获得不变性的方法——数据增强!)
结论
在这一课中,我们学习了关于特征提取的最后一步:使用 MaxPool2D 进行压缩。在第4课中,我们将完成我们对卷积和池化的讨论,以滑动窗口结束。
本文由博客一文多发平台 OpenWrite 发布!
-
从零开始学习贪心算法12-26
-
线性模型入门教程:基础概念与实践指南12-26
-
探索随机贪心算法:从入门到初级应用12-25
-
树形模型进阶:从入门到初级应用教程12-25
-
搜索算法进阶:新手入门教程12-25
-
算法高级进阶:新手与初级用户指南12-25
-
随机贪心算法进阶:初学者的详细指南12-25
-
贪心算法进阶:从入门到实践12-25
-
线性模型进阶:初学者的全面指南12-25
-
朴素贪心算法教程:初学者指南12-25
-
树形模型教程:从零开始的图形建模入门指南12-25
-
搜索算法教程:初学者必备指南12-25
-
算法高级教程:入门与初级用户指南12-25
-
随机贪心算法教程:初学者指南12-25
-
贪心算法教程:入门与实践指南12-25
