区块链技术
从零到生产:Go在Google的历程

2007年Go诞生于Google,2009年Google正式对外宣布了Go语言的开源!时至今日,距离Go开源已经过去了近15个年头了!Go在Google公司内部究竟是怎样的一个状态呢?前Google员工Yves Junqueira近期撰文从其个人所见所闻谈了Go在Google的历程!这里简单翻译,供大家参考!
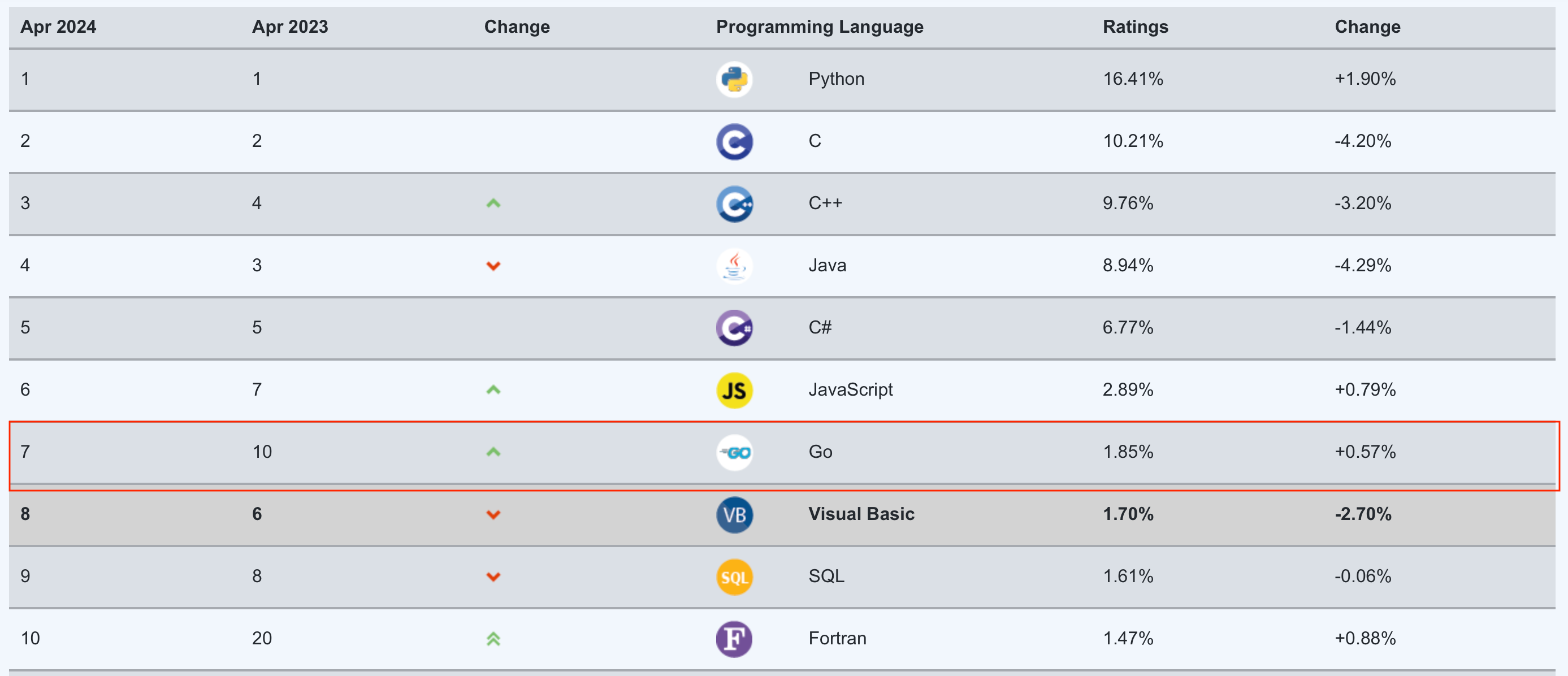
最近,Jeremy Mason和Sameer Ajmani撰写了有关使Go成为Google内部语言之一的传奇故事。Go目前是世界上第八大最受欢迎的编程语言(译者注:2024.4,Go已经攀升到第7位,见下图),并且仍在增长,因此人们有兴趣了解Go早期以及它是如何走到这一步的。
我想我应该从SRE、框架开发人员和早期采用者的角度来写。我分享的所有信息都与谷歌已经公开记录的系统相关,所以我不认为我泄露了任何秘密。这个故事有一些重要的部分(例如:envelopei(译者注:不知道是什么鬼))我在其他地方没有看到提到过,所以我不会讨论它们。
破冰:我在Google的Go编程简介
在Go公开发布之前我就开始关注它,当它发布时,我立即成为了它的粉丝和Google内部的早期用户。我喜欢它的简单性。
我在核心库上做了一些工作,并且在社区中很活跃,早期经常帮助go-nuts邮件列表中的用户,并编写开源库。后来,我帮助组织了西雅图的Go Meetup,并与他人共同组织了备受喜爱的会议Go Northwest。
据我所知,我在Google编写了第一个生产关键型工具,后来又用Go编写了第一个面向用户的服务。
第一个是用于监控Google+ Bigtable服务器运行状况的服务。这是我作为SRE的工作之一。Bigtable拥有有关每个tablet性能的详细内部统计数据,但有时我们需要了解为什么某个tablet如此过载以及系统其他地方发生了什么,以便我们能够了解根本原因。我们需要随着时间的推移收集这些数据并进行分析。因此,我构建了一个爬虫,可以检查数千台服务器并在全局仪表板中显示详细的统计数据。
2011 年,Andrew Gerrand在接受The Register采访时提到了这项工作。他当时向我证实,这指的是我的项目。我很兴奋!他在采访中这样说道:
谷歌有管理应用程序和服务的人员,他们需要编写工具来抓取几千台机器的状态并聚合数据,”他说。“以前,这些操作人员会用Python编写这些内容,但他们发现Go在性能和实际编写代码的时间方面要快得多。”
Go的运行速度和编写速度确实更快。最重要的是,使用起来很有趣。它让我更有效率,所以我迷上了Go!
低级库:节点身份验证和RPC
当Go启动时,它无法与Google的内部基础设施通信。
首先,团队必须构建一个基于proto buffer的stubby RPC 系统。这需要实现LOAS来加密和验证与远程节点的通信,并使用Chubby 进行名称解析(类似于kubernetes中使用的etcd)。
Stubby和Chubby是出了名的复杂。Stubby需要一个复杂的状态机来管理连接,但大部分繁重的工作都是由Chubby完成的,即使Borg 节点耗尽CPU,或者因为有人正在运行map reduce而占用了所有机架的交换机带宽而导致暂时的网络断开连接,Chubby也需要提供一致的world view,这很容易陷入死锁或可靠性问题。
根据海勒姆定律,系统的所有可观察行为都将取决于某人,因此团队必须确保与现有生产网络预期的行为完全匹配,并注意极端情况。例如,众所周知,健康检查很容易出错,不应该太严格,否则当网络的一部分暂时过载或与另一部分断开连接时,它们会为级联故障敞开大门。必须实现的其他的分布式系统功能,例如backend subsetting和负载均衡。我们需要诊断何时出现问题,因此很早就添加了日志记录和指标库。
为了找到要通信的host:port,服务使用Chubby进行名称解析(name resolution)。它作为少量数据的完全一致的存储系统,其最常用的功能是解析BNS 地址 - 类似于你今天在kubernetes中使用etcd看到的功能。
系统使用Stubby协议向其他服务发送数据并从其他服务接收数据。在Stubby(如gRPC)中,消息使用proto buffer wire format进行编码。使用反射在运行时创建proto buffer有效负载会太慢并且占用大量资源。工程师还会错过来自强类型系统的反馈。出于这些原因,谷歌为所有语言使用了生成代码库。幸运的是,proto buffer与语言无关。团队只需为现有构建系统逻辑编写Blaze 扩展,瞧,我们就为所有内部RPC服务提供了高质量的客户端库代码。
奇怪的是,为另一种语言生成代码会产生少量的增量构建时间成本,而Google拥有成千上万的RPC服务。因此,我们决定每个RPC服务的所有者必须选择允许构建系统为其特定服务生成Go代码。虽然有点官僚主义,但随着时间的推移,我们看到数千个CL(谷歌的等效Pull请求)飞来飞去,将Go添加到每个服务的生成代码集中。这对于我们的社区来说是一个愚蠢但有趣的进度衡量标准,因为我们可以计算代码库中“启用 Go”标志的实例数量。
影响全局Master选择和Bigtable引流执行
作为这些早期库的早期采用者和专注于生产系统的工程师,我能够了解内部系统的工作原理。我帮助调试并解决了许多奇怪的问题。随着时间的推移,我获得了构建系统来自动化运维SRE工作的信心。注意到我们的服务中大多数面向用户的中断发生在存储层(Bigtable 或 Colossus),我产生了创建一个控制系统的想法,该系统可以监视Bigtable分区的运行状况,并在检测到问题时在GSLB中小心地清空它们。当时,当发生中断时,SRE会进行分页,在确认这是存储问题后,他们会简单地清空集群并返回睡眠状态。
我想用适当的控制系统取代这个手动whackamole。抽取流量可能会导致级联故障,因此这是一项危险的操作。当时,大多数SRE不想在自动化系统中冒这种风险。幸运的是,我有一个很好的团队。他们仔细审查了我的提案,提供了有关潜在故障模式的大量反馈,我们最终提出了一个我们有足够信心的设计。我们需要仔细聚合来自不同监控系统的信息(这可能会失败或提供不正确的数据),使用全局负载均衡器安全地离开集群,然后最终在Buganizer 中开具ticket,以便待命的SRE在工作期间进行处理。
系统需要多个副本始终处于运行状态以对中断做出反应,但一次只有一个副本保持活动状态至关重要。为了支持这一点,我为Go编写了一个全局“主选举(master election)”库,它将确保系统的单个副本一次处于活动状态。它使用全局Chubby锁服务来提供一个高级库来告诉应用程序开始运行或在无法证明我们持有“全局锁”时自行关闭。
为了支持这项工作,我还到处编写了一些小实用程序,并与Go团队合作修复错误。我报告了我发现的问题,他们修复了这些问题。
当时,Go团队的重点是外部用户。他们所有的注意力都集中在发布Go 1.0上。这是一个资源很少的小团队,但他们的“秘密武器”是他们是杰出的工程师,而且团队非常高效。不知何故,尽管针对内部用户的支持时间非常有限,但他们还是很好地完成了支持工作。内部邮件列表非常活跃,谷歌员工大多在业余项目中使用Go,但Go团队采用了非常强大的内部流程来使事情顺利运行。他们仔细审查了每个人的代码,并帮助建立了强大的内部代码质量文化。每当他们发布新的Go候选版本时,他们都会使用新版本重建所有内部项目并重新运行我们的测试以确保一切正常。他们总是以正确的方式做事。
生产中JID代理部署的最初洞察
几个月后,我在Google用Go编写了第一个面向用户的服务。我所说的面向用户的意思是,如果它停止工作,许多面向用户的产品将停止工作。这是一个简单的RPC服务,但所有Google消息服务都使用它。
该服务根据从另一个RPC服务获取的内部用户ID将数据与JID格式 相互转换。该服务很简单,但规模很大,当时每秒执行数十万个请求。它对于为Android、Hangouts和其他产品提供支持的Google消息服务核心至关重要。
这次迁移是Google Go的一个非常重要的测试平台。重要的是,它为我们提供了一个令人难以置信的基础来比较Go与其他生产语言(特别是 Java)的性能。该服务正在取代难以维护的基于Java的服务(不是因为Java,而是因为其他原因),因此我们使用实际生产流量同时运行这两个服务,并密切比较它们的性能。
我们从第一个大规模实验中吸取了重要的教训:Go使用比Java更多的CPU内核来服务相同的流量,但垃圾收集(GC) 暂停非常短。作为一个努力减少GC暂停以改善面向用户的服务的尾部延迟的SRE,这是非常有希望的。Go团队对这个结果很满意,但他们并不感到惊讶:Go只是在做它设计的事情!
事实上,几年后,当SRE领导层正式审查Go的生产就绪情况并要求Go团队确保Go具有良好的GC性能时,我认为这很大程度上只是形式上的。Go很早就证明了Go具有出色的GC性能,并且多年来它不断变得更好。
遇到内部库缺失的情况
在早期,在Flywheel之前,在dl.google.com 服务之前,在Vitess之前,Go被Google的大多数工程师忽视了。如果有人想向用户交付产品,他们首先必须编写基本构建块,让他们连接到谷歌的其他服务。对于大多数人来说,这是不可能的。
锁服务(chubby)和RPC系统(stubby)的底层库相对较快地出现(同样,Go团队非常优秀),Google最重要的库是与我们存储系统的接口:Bigtable、 Megastore、Spanner、Colossus。如果你想读取或写入数据,你基本上还不能使用Go。但是,慢慢地,Go团队(有时与核心基础设施团队合作)开始应对这一挑战。
他们最终一一为Bigtable、Colossus甚至Spanner 创建了库(不是Megastore,因为它很大程度上是一个被Spanner 取代的库)。这是一项重大成就。
Google的Go 使用量仍然有限,但我们的社区正在不断壮大。我在Google开设了第一门官方的Go编程简介课程,并帮助位于苏黎世的Google员工找到了可以使用Go进行工作的有趣项目。大约在这个时候我终于获得了Go的“可读性”(译者注:这似乎是Go团队对代码review者资格的一种认可),后来加入了Go可读性团队。
需要站点可靠性工程师来指导应用程序功能
Go中缺少的另一件事是与生产相关的功能,我们多年来了解到这些功能对于生产团队来说是必需的。也就是说,如果你想运行大型系统而不需要一直处于运维和救火模式。
每当发生中断并诊断根本原因时,随着时间的推移,我们会了解到系统中应该改进的弱点。目标是减少停机和运维开销。很多时候,为了使系统更加可靠,我们必须对应用程序运行时进行更改。我们很难理解我们需要观察和控制系统以使其真正可靠的细节深度。
例如,我们需要确保,除了记录传入请求之外,应用程序还应该记录有关该操作中涉及的传出请求的详细信息。这样,我们就可以确定地指出,比如说,我们的“CallBob”服务在上午 11:34 变慢是因为“FindAddress”调用的延迟增加。当我们操作大型系统时,我们不能满足于猜测工作和弱相关性。有太多的转移注意力和根本原因查找工作需要处理。我们需要对原因有更高的确定性:我们希望看到失败的特定请求确实经历了高延迟,并排除其他解释(即:未触发缓慢的 FindAddress 调用的传入请求不应失败)。
同样,多年来我们注意到SRE的大部分时间都花在团队之间的协调上,以确定一个服务每秒应发送到另一个服务的确切连接数和请求数,以及如何准确建立这些连接。例如,如果多个服务想要连接到后端,我们希望清楚哪些节点正在连接到哪些其他节点。这称为后端子集化(backend subsetting)。需要仔细调整,考虑整个系统的健康状况,而不仅仅是一个节点或一对节点的健康状况,而是整个网络的健康状况。太大的子集会导致资源占用过多,太小的子集会导致负载不平衡。因此,随着时间的推移,SRE团队开始帮助维护用于与其服务通信的客户端库,以便他们可以检测正在发生的情况,并保留对其他节点与其系统通信方式的一些控制。
揭开魔法:Go服务器工具包
SRE共同拥有客户端库的模型在实践中运行得非常好,随着时间的推移,我们了解到向这些库添加流量和负载管理是一个好主意。
- 当你的系统开始过载时,你会如何处理传入的RPC?
- 你应该将这些请求保留在队列中,还是立即拒绝它们?
- 你应该使用哪些指标来确定你的系统是否过载?
- 当系统的太多部分认为它们过载时,如何避免进入级联故障?
Alejo Forero Cuervo 在SRE书籍章节“处理过载”中写了一些经验教训,值得一读。我们一一向库中添加了谨慎的逻辑,以根据经验和内部传感器自动设置这些参数。
在《不断发展的SRE参与模型》中,我的前同事 Ashish Bhambhani和我的前老板Acacio Cruz解释说,我们最终发展了SRE参与模型,以包括服务器框架(server framework)的工作和采用。该模型使SRE能够直接影响系统在细微差别领域的行为,这得益于我们丰富的现场经验。
我和我的SRE团队希望将这些功能引入Go,但它们对于Go团队来说太过奇特和专业,无法处理。我设立了一个20%的项目(后来变成了一个全职项目),并招募了一群愿意做出贡献的经验丰富的工程师。我飞往纽约,会见了一位非常出色的Go团队成员,我们共同努力为Go中的“服务器框架”构建了路线图。
Go团队一开始不太愿意接受我们的方法。整个“框架”概念对他们来说有点危险。这可能会成为一场宗教战争,但Go团队花时间详细解释了他们担心的原因。Sameer尤其具有一种不可思议的能力,能够用技术术语反思和解释为什么他认为某件事以某种方式比另一种方式效果更好。
Sameer强烈认为,Go不应该有不一致的开发人员体验,无论是内部还是外部,无论是否有“框架”。如果Google有不同的方法来构建Go应用程序,那将对内部Go社区造成损害。与他的担忧一致,我们的20%人组成的乌合之众团队竭尽全力确保我们的“框架”感觉更像是另一个库,而不是一个框架,并且它不会为Go引入不同的编程模型。目标是通过简单的库导入来引入我们的可靠性功能。如果你使用我们的库包装你的Go HTTP或Stubby服务器,所有内容在代码中看起来都一样,但你神奇地获得了开箱即用的日志记录、检测、负载卸载、流量管理,甚至每请求级别的实验性支持。
为了创建这个让服务变得更好的神奇库,我们必须对Google的内部RPC库甚至构建系统进行重大更改 - 以使我们的框架团队能够为RPC系统创建任意“扩展”,从而无需任何操作即可无缝运行,并避免接收和发送请求时产生显着的性能开销。
结果是值得的。效果非常好。我们的项目使服务变得更容易管理,而无需强加与Go团队想要的不同的编程风格。为了避免混淆,我们将其称为服务器“工具包”,它成为在Google构建生产就绪系统的正确方法。人们经常在他们的LinkedIn个人资料中引用我们的内部服务器框架:)。它被称为Goa,不要与不相关的外部Goa 框架混淆。以下是某人LinkedIn个人资料中的示例:

凭借其生产就绪功能,我们的Go工具包消除了Go内部增长的主要障碍。工程师现在可以确信他们的Go项目的性能与旧的Java和C++项目一样好,并且可调试。也就是说,增长还没有完全发生。Go需要一个杀手级用例才能在Google流行起来。
Go在多个SRE团队中的采用
当时,我所在的SRE团队在Google具有特殊地位,即社交SRE团队。我们在SWE和SRE都有出色的工程师和出色的管理人员。所以我们能够以正确的方式做事。一些SRE团队正在追尾救火,但我们有幸能够正确地进行工程设计。这创造了一个良性循环,我们在问题变得严重之前不断解决问题,这意味着我们有时间进一步优化运维,等等。
结果,我们的SRE团队编写了很多有用的代码。像我的高级工程师同事一样,我帮助人们找到要做的事情,因此我帮助启动了许多早期的Go中与生产相关的工具。如果其中一个工具发现有问题,它会自动、安全地从整个Bigtable集群中删除流量。
还有其他与流量和负载管理相关的Java和C++项目,由其他高级工程师领导。这种创新环境吸引了人才,我们不断取得良好的成果,因此我们的SRE团队不断壮大。
我们的工程总监Acacio Cruz(负责我们团队以及山景城的同事所发生的许多积极的事情)非常关注工程效率:我们是否将工程时间用于最有影响力的事情?他明白标准化可以提高效率,而且他看到我们的工程师很高兴并且富有成效。他的想法是推动Go成为我们团队中任何自动化的首选工具。该建议是避免使用Python并使用Go来编写生产工具。令我惊讶的是,我的队友没有人反对。这加速了Go在我们的社交SRE团队中的使用,很快我们区域之外的人们就注意到了。
核心库、服务器框架、成功的生产工具和围绕Go的社交SRE标准化——它们都促成了人们对Go正在成为Google的一种严肃语言的看法的改变。
与此同时,SRE已经看到了几代用Python编写的工具,这些工具运行得非常好,但随着时间的推移变得非常难以维护。Google SRE喜欢Python,我们编写了大量的Python代码。不幸的是,当时缺乏类型和编译时语法错误检查导致了许多难以修复的问题:
-
当你从事其他人启动的项目时,该项目可能有也可能没有良好的测试覆盖率。为不是你编写的代码添加测试是很困难的。你并不真正知道正在使用什么以及如何使用。所以你最终会测试太多的东西或测试太少的东西。在生产关键型工具中,我们在进行更改时不能冒险。
-
当时,人们通常一会儿编写代码,一会儿运行测试。如果你在运行测试时才意识到有语法错误,也许你已经将上下文切换到执行其他操作,所以现在你必须返回并修复它。这会浪费时间并增加不确定性。
随着越来越多的SRE开始用Go编写自动化,很明显这些团队很高兴并且富有成效,并且不太可能陷入难以维护的代码中。人们开始意识到,Go项目更容易发展和维护,而这不仅仅是这些项目更新、更干净或设计得更好的结果。
SRE领导层注意到了这种影响,并决定采取行动并在组织内进行广泛的沟通:SRE团队最好使用Go进行与生产相关的项目,并避免使用Python。我不知道这在谷歌现在是否被视为独裁,但当时我认为这感觉像是整个组织范围内良好的沟通和决策。
Go生产平台和爆炸式增长
此后事情进展得很快。我们创建了一个从早期就对Go提供强大支持的生产平台,并用高级抽象取代了许多样板配置和重复过程。该平台出现了强劲增长,最终其他平台也出现了。Go和我们的服务器框架变得无处不在。我最终离开了谷歌,但我仍然快乐地记得那些日子。
虽然我只是该语言的用户,但观看一个项目从零到成为前10名的编程语言的经历教会了我很多东西。我亲眼看到,一个强大的团队,周围有一个强大的社区,真的可以做出大事。
观察Go的崛起
我在Google从事Go编程工作改变了游戏规则,让我对项目的技术方面以及世界著名团队的运作方式有了深入的了解。随着项目的进行,我可以清楚地看到Go如何使项目和团队扩展变得更容易。
Go对简约设计的强调促进了统一编码,使新程序员可以轻松地集成到项目中,这一功能在时间紧迫的项目中特别有用。随着项目的发展,新的库和工具包也出现了,提高了它的受欢迎程度,并促进了包括Apple、Facebook和Docker在内的几家大型科技公司的采用。
尽管Rust具有更为广泛和丰富的功能特性,但Go在各个行业的广泛接受表明,强大的软件不一定需要复杂。
回顾过去,很明显,虽然我们的旅程充满了挑战,但每一次的曲折、每一次的调整和进步,都是塑造今天Go的关键。随着社区不断向前发展,我很高兴看到我们下一步的发展方向。
Go gopher由Renee French设计,并根据 Creative Commons 3.0 属性许可证获得许可。
讲师主页:tonybai_cn
讲师博客: Tony Bai
专栏:《改善Go语言编程质量的50个有效实践》
实战课:《Kubernetes实战:高可用集群搭建,配置,运维与应用》
免费课:《Kubernetes基础:开启云原生之门》
-
Kubernetes生产环境问题排查指南:实战教程12-21
-
使用Encore.ts构建和部署TypeScript微服务到Kubernetes集群12-20
-
Kubernetes:从理念到1.0的历程12-20
-
第28天:Kubernetes中的蓝绿部署讲解12-18
-
从零到Kubernetes安全大师:简化集群安全防护12-15
-
掌握Kubernetes节点调度:污点、容忍、节点选择器和节点亲和性12-15
-
第五天:与容器互动12-14
-
CKA(Kubernetes管理员认证)速查表12-11
-
.NET Aspire应用部署到Azure和Kubernetes实战指南12-08
-
云原生周报:K8s未来三大发展方向不容错过12-07
-
《 Kubernetes开发者的书评:从入门到生产实战》12-07
-
Longhorn: Rancher 推出的 Kubernetes 云原生存储解决方案12-06
-
为Amazon EKSBlueprints for CDK项目贡献代码指南12-04
-
KubeShark:Kubernetes集群的网络流量监控神器,就像Wireshark一样好用!12-02
-
云原生周报:Knative 1.15版本发布啦!12-02
