C/C++教程
巧用 TiCDC Syncpoint 构建银行实时交易和准实时计算一体化架构

导读
本文阐述了某商业银行如何利用 TiCDC Syncpoint 功能,在 TiDB 平台上构建一个既能处理实时交易又能进行准实时计算的一体化架构,用以优化其零售资格业务系统的实践。通过迁移到 TiDB 并巧妙应用 Syncpoint,该银行成功解决了原有多个 MySQL 集群所面临的数据分布复杂性和跨库关联查询的挑战,实现了数据处理效率和应用性能的显著提升,确保了实时交易的快速响应和数据分析处理的计算资源需求。
场景概述
某商业银行的零售资格业务系统专门设计用于计算和管理客户的消费积分及优惠。每当用户完成一笔交易,系统内的关键模块便会自动整合用户的历史消费数据,迅速进行积分计算,并将当前可用的优惠信息及时推送给用户,例如通知当前能够兑换的优惠或赠品,提示额外消费达到一定额度后能够获得的特定奖励等。该系统旨在通过提供实时的优惠信息和激励措施,增强客户的消费体验。
用户的消费信息按照用户 ID 进行分组,存储在 30 多个 MySQL 集群。随着业务的增长,以及需要开放第三方应用使用数据,完成资格的计算。分库分表的 MySQL 就不满足业务需求了。一方面,分库分表后数据分布复杂;另外,分库分表难以实现跨 MySQL 库的关联查询。 如果把这些 MySQL 库的数据汇聚到 HBase 等大数据平台,即不能保障用户交易以事务的粒度同步到大数据平台,也很难保证数据的时效性(大数据通常都只做 T+1 的计算)。
为了优化应用性能和数据处理效率,行方决定将应用迁移到 TiDB 平台,并采取策略将实时交易和准实时计算分配到两个不同的 TiDB 数据库集群中。资格落地模块用来完成准实时资格的计算。因为落地数据计算量大,并且有准实时性的要求,为了不影响实时业务,落地计算是通过 TiDB 备集群 2 进行计算,该集群的数据来自 TiCDC 从实时集群同步过来的准实时数据。
这样的架构设计旨在平衡交易的即时性和数据处理的计算需求,确保实时交易的快速响应,同时为数据分析和处理提供足够的计算资源。
TiCDC 和 Syncpoint 特性简介
本文以商业银行零售资格业务系统为例,向大家介绍怎样通过 TiCDC 的 Syncpiont 功能,来确定目标端的同步进度,并且以此为依据,计算每笔业务对用户资格数据的贡献。
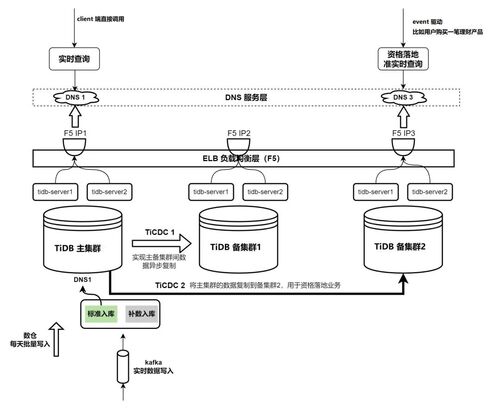
图 1:实时交易和准实时计算一体化架构
“TiDB 主集群”为实时集群;“TiDB 备集群 2”是专门为资格落地准备的准实时集群;“TiDB 备集群 1”是容灾集群*
众所周知,在业界,几乎所有的变更数据捕获(CDC)产品都通过异步方式进行数据同步,这导致主集群与备集群之间不可避免地会出现数据延迟。TiCDC 采用分布式架构设计,也会受到主备之间延迟的影响,不能保证目标端的事务提交顺序和源端的事务提交顺序完全一致,无法动态地获取主备集群的一致性关系。
行方原先考虑在源端提交以后,等待一分钟左右时间,再去备集群计算,但是,如果遇到大的事务,或者集群因为某些原因提交缓慢,即使等待 N 分钟,也不能保证备集群能完成同步。
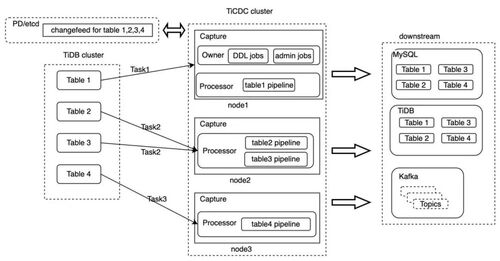
图 2:TiCDC 分布式同步架构
在使用 TiCDC 构建 TiDB 主从集群的过程中,有时需要在不中断数据同步的情况下,进行数据的一致性快照读取或验证。由于 TiCDC 采用的是分布式架构,其标准同步模式仅确保数据的最终一致性,而不能保证在同步过程中的数据一致性。这就使得对实时变化的数据进行一致性读取变得具有挑战性。为了解决这个问题,TiCDC 引入了 Syncpoint 功能,它允许用户在特定时间点获取数据的一致性视图,从而进行一致性读取和数据验证,满足了对数据一致性有严格要求的业务场景。
Syncpoint 通过利用 TiDB 提供的 snapshot 特性,让 TiCDC 在同步过程中维护了一个上下游具有一致性 snapshot 的 ts-map。把校验动态数据的一致性问题转化为了校验静态 snapshot 数据的一致性问题,达到了接近数据一致性实时校验的效果。当启用 Syncpoint 功能后,就可以使用一致性快照读和数据一致性校验。
巧用 Syncpoint
要开启 Syncpoint 功能,只需在创建同步任务时把 TiCDC 的配置项 enable-sync-point 设置为 true。开启 Syncpoint 功能后,TiCDC 会向下游 TiDB 集群写入如下信息:
在数据的同步过程中,TiCDC 会定期(使用 sync-point-interval 参数配置)对齐上下游的快照,并将上下游的 TSO 的对应关系保存在下游的 tidb_cdc.syncpoint_v1 表中。
同步过程中,TiCDC 还会定期(使用 sync-point-interval 参数配置)通过执行 SET GLOBAL tidb_external_ts = @@tidb_current_ts ,在备用集群中设置已复制完成的一致性快照点。
Syncpoint 表结构如下:
select * from tidb_cdc.syncpoint_v1;+------------------+-------------+--------------------+--------------------+--------------------+| ticdc_cluster_id | changefeed | primary_ts | secondary_ts | created_at | +------------------+-------------+--------------------+--------------------+--------------------+ | default | test-2 | 435953225454059520 | 435953235516456963 | 2022-09-1308:40:15 | +------------------+-------------+--------------------+--------------------+--------------------+
ticdc_cluster_id:插入该条记录的 TiCDC 集群的 ID。
changefeed:插入该条记录的 Changefeed 的 ID。通过 ticdc_cluster_id 和 Changefeed 的 ID 来确 认一个 Changefeed 所插入的 ts-map。
primary_ts:上游数据库 snapshot 的时间戳。
secondary_ts:下游数据库 snapshot 的时间戳。
created_at:插入该条记录的时间。
通过查询 ts-map 的方式选取之前的时间点进行快照读。syncpoint_v1 中的 primary_ts,就代表备集群,当前已经完成的事务,对应到主集群的时间戳。
资格应用在实时集群完成一笔业务后,只需要记下业务完成时的时间戳,然后在备集群中去查询 tidb_cdc.syncpoint_v1 中 max(primary_ts),如果获取到的 primary_ts 大于当时业务记录的完成时间戳,就代表该业务已经在备集群完成,应用就可以针对该笔业务,计算用户当前的资格。
因为资格下游集成了很多子系统,并且 syncpoint_v1 是按照一定的时间间隔更新的,所以没有必要每笔交易、下游子系统都查询一次 tidb_cdc.syncpoint_v1,这样会对数据库造成性能影响,所以根据业务需求,资格系统将以一定时间间隔读取 tidb_cdc.syncpoint_v1,缓存 primary_ts,通过缓存提供给下游业务使用。具体流程如下图所示:
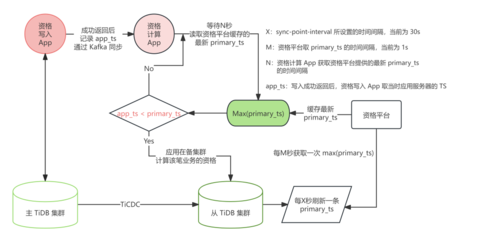
图 3:启用 Syncpoint 后的资格落地计算流程
通过以上的流程 ,资格下游的应用就可以准确的得到每笔业务产生的资格更新。Syncpoint 的启用步骤如下:
1. 编辑 changefeed.toml,增加如下内容
# 开启 SyncPointenable-sync-point = true# 每隔 30s对齐一次上下游的 snapshotsync-point-interval = "30s"# 每隔 1 小时清理一次下游 tidb_cdc.syncpoint_v1 表中的 ts-map 数据sync-point-retention = "1h"
2. 动态启用配置文件
TiCDC 支持非动态修改同步任务配置,修改 changefeed 配置需要按照 :暂停任务 -> 修改配置 -> 恢复任务的流程
cdc cli changefeed pause -c test-cf --server=http://10.0.10.25:8300cdc cli changefeed update -c test-cf --server=http://10.0.10.25:8300 --sink-uri="mysql://127.0.0.1:3306/?max-txn-row=20&worker-number=8" --config=changefeed.tomlcdc cli changefeed resume -c test-cf --server=http://10.0.10.25:8300
3. 获取 ts-map
在下游 TiDB 中执行以下 SQL 语句,从结果中可以获取上游 TSO (primary_ts) 和下游 TSO (secondary_ts) 信息。
select * from tidb_cdc.syncpoint_v1 limit 1;+------------------+------------+--------------------+--------------------+--------------------+| ticdc_cluster_id | changefeed | primary_ts | secondary_ts | created_at | +------------------+------------+--------------------+--------------------+--------------------+ | default | test-2 | 435953225454059520 | 435953235516456963 | 2022-09-1308:40:15 | +------------------+------------+--------------------+--------------------+--------------------+
获取当前最后一个一致性的时间戳。
select max(primary_ts) from tidb_cdc.syncpoint_v1
注意事项
同个数据库的多张表,可以通过不同的 changefeed 来进行同步,这样可以分摊一些 workload,但是由于 syncpoint 一致性是以 changefeed 为最小粒度的,所以要求,有事务关联性的所 有表, 必须在同一个 changefeed 里面同步 。如果涉及多个 changefeed 的情况下 ,取 primary_ts 要带上 changefeed 字段,如果 TiCDC 还涉及多个 TiDB Cluster 同步数据,那还应该带上 ticdc_cluster_id,如:
select max(primary_ts ) from tidb_cdc.syncpoint_v1 where changefeed=’test-2’select max(primary_ts ) from tidb_cdc.syncpoint_v1 where changefeed=‘test-2’and ticdc_cluster_id=‘default’
关于 TiCDC 使用的优化点:
首先,应用端应该尽量避免使用大事务,TiCDC 只有在源端事务已经提交后,才会在目标端开始执行事务(源端 pre-write 阶段,数据会缓存在 TiCDC,并不会在目标端也 pre-write,只有等到源端提交后,目标端才开始执行),所以如果源端的事务执行时间比较久,目标端并不一定会比源端执行时间短。
因为是分布式系统,可以通过增加 changefeed 的 worker 的数量,来加快下游同步的速度,具体需要根据业务的实际情况来设定,worker-num 默认为 16。
关于使用 syncpoint 取到的数据,最大延时计算参考:
tidb_cdc.syncpoint_v1 表中的数据,刷新间隔是按照 sync-point-interval 设置的时间间隔刷新的,所以从该表中获取的最新快照的时间,最大的延时近似于 sync-point-interval+实际延时。
总结
在需要对 TiCDC 上下游动态变更的数据执行一致性读取的应用场景中,启用 Syncpoint 功能是一种有效的解决方案。通过查询下游 tidb_cdc.syncpoint_v1 表中的 primary_ts 字段,用户能够获取到下游事务的确切完成时间点。这一机制显著提升了计算的准实时性,确保了数据读取的时效性,为用户提供了可靠的准实时数据处理方案。
-
从 Elastic 迁移到 Easysearch 指引12-29
-
uni-app 中使用 Vant Weapp,怎么安装和配置npm ?-icode9专业技术文章分享12-29
-
Nacos多环境配置学习入门12-27
-
Nacos快速入门学习入门12-27
-
Nacos快速入门学习入门12-27
-
Nacos配置中心学习入门指南12-27
-
Nacos配置中心学习入门12-27
-
Nacos做项目隔离学习入门12-27
-
Nacos做项目隔离学习入门12-27
-
Nacos初识学习入门:轻松掌握服务发现与配置管理12-27
-
Nacos初识学习入门:轻松掌握Nacos基础操作12-27
-
Nacos多环境配置学习入门12-27
-
阿里云ECS学习入门:新手必看教程12-27
-
阿里云ECS新手入门指南:轻松搭建您的第一台云服务器12-27
-
Nacos做项目隔离:简单教程与实践指南12-27
