人工智能学习
知识图谱与大模型双向驱动的关键问题和应用探索

导读
知识图谱和大型语言模型都是用来表示和处理知识的手段。大模型补足了理解语言的能力,知识图谱则丰富了表示知识的方式,两者的深度结合必将为人工智能提供更为全面、可靠、可控的知识处理方法。在这一背景下,OpenKG组织新KG视点系列文章——“大模型专辑”,不定期邀请业内专家对知识图谱与大模型的融合之道展开深入探讨。本期邀请到蚂蚁集团知识引擎负责人梁磊分享“SPG与LLM双向驱动的关键问题和应用探索”,本文整理自梁磊老师在2023年10月26日沈阳举办的CNCC知识图谱论坛上的分享。
01 引言
企业级海量数据的知识化已日趋成为行业共识,通过海量数据的知识化集成,可以加速数据标准化、消除/减少歧义、链接数据孤岛等。知识图谱作为表达能力更强的数据建模形式,也需要不断技术升级与时俱进,SPG(Semantic-enhanced Programmable Graph)是蚂蚁集团和OpenKG联合发布的新一代工业级知识语义框架,是蚂蚁在多元化企业级图谱应用场景中的经验总结。在企业数字化升级、AI技术赋能千行百业的当下,期望通过OpenSPG构建加速企业海量数据知识化集成,知识符号化高效衔接AI系统的知识表示和图谱引擎框架,以期推动可控AI技术的业务落地。
Github地址:https://github.com/OpenSPG/openspg ,欢迎 Star 关注我们~
SPG官网:https://spg.openkg.cn/
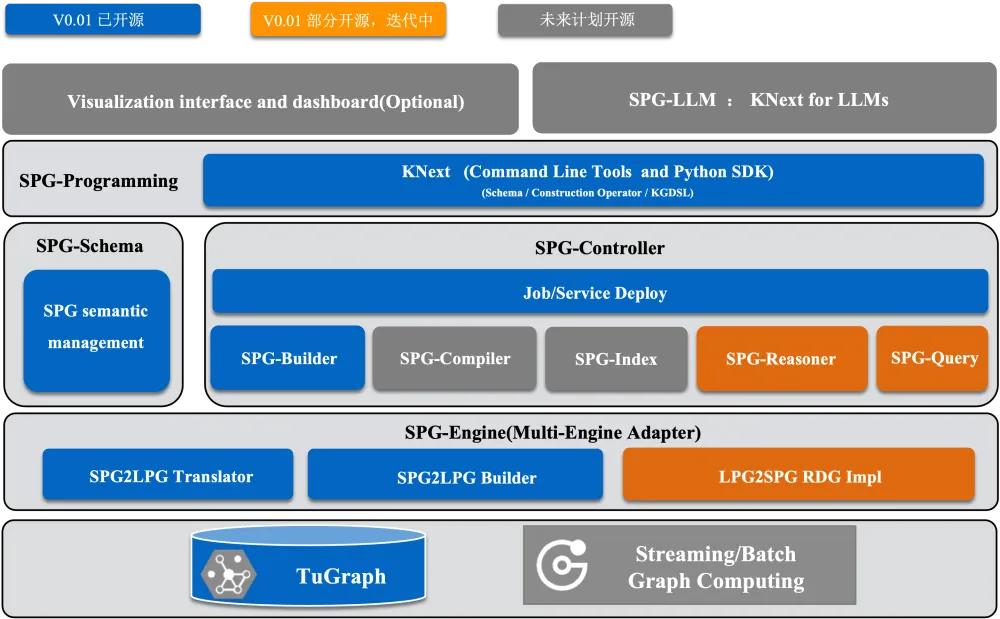
图 1. OpenSPG总体架构
02 知识图谱的与时俱进
知识图谱本身是多学科技术的综合体,也经常被笑谈为“也只有知识图谱能描绘清楚知识图谱的技术体系”,它生来就与大数据技术、NLP技术、图计算、图学习、AI技术体系等相互融合互通,也正因为此,知识图谱也更容易吸收融合其他的技术优势。大模型时代亦是如此,通过大模型强大的语言能力补足知识抽取/构建效率的不足,知识图谱技术积极进取、拥抱开放。
对内,通过SPG语义框架,图谱技术升级语义表示体系,从二元静态升级到多元动态,更好的实现事实的感知、常识知识归纳沉淀、深度上下文关联等,通过一套体系理解和使用知识图谱,避免对玲琅满目图谱概念的理解;对外,图谱技术积极拥抱新一代AI技术体系,如大模型(Large Language Model, LLM),实现二者的双驱动增强,定义融合互通的技术范式和关键问题,借助LLM强大的语言理解能力,为基于非/半结构化数据的图谱构建提效,同时在用户问答中,语言要素和语义结构的理解也会更加精准。
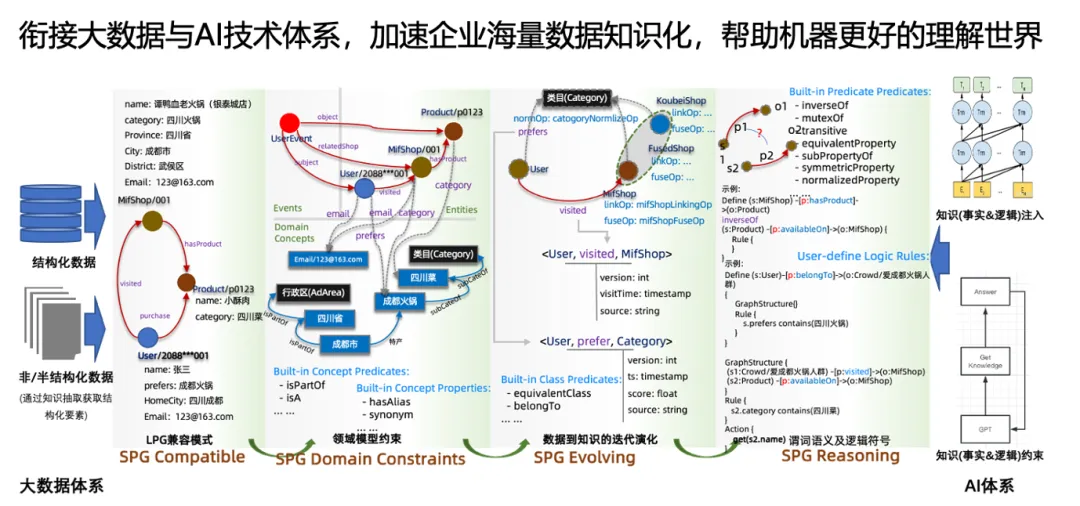
图2. SPG总体语义框架
图2展示了SPG白皮书中发布的总体语义框架。本文从基于SPG知识表示的知识图谱视角出发,分析了需要解决的关键问题。通过不断地技术突破,我们希望大幅降低知识图谱的构建成本,持续降低领域图谱的应用门槛。同时,结合大模型在领域落地的典型场景,我们致力于构建SPG + LLM双驱动的行业落地范式,以提升领域应用的可控性和可信度。
另外,基于知识图谱解决LLM幻觉的问题是一项长期且复杂的工作。这需要构建涵盖各行各业的领域图谱,并实现它们之间的语义关联和迁移。在这个过程中,还有许多复杂的问题需要解决。目前,SPG的探索主要从垂直领域出发,致力于攻克SPG与LLM相互增强的关键技术,并积累领域知识图谱,以提升领域应用的可控性和可信度。
03 SPG与LLM双驱增强
首先,我们看下SPG和LLM各自及双向驱动能解决的问题范围,以企业中商户经营与风控应用场景为例,如表1所示,LLM和SPG应用的算法任务主要可以分为三类:
- LLM only:由于领域专业性和事实性的要求,LLM在商户经营与风控领域尚未有明确可落地的场景;
- LLM + SPG双驱动:主要体现在知识问答、报告生成等用户交互类场景中,比如前文提到的AI电话唤醒受害者和反洗钱智能审理报文生成等。此外,还有知识要素抽取、实体链指等知识构建类场景。文献中详细描述了LLM与SPG的双驱动,包括KG增强的LLM、LLM增强的SPG以及LLM+SPG框架协同三个方面;
- SPG only:在推理决策、分析查询、知识挖掘类等不需要复杂语言交互和意图理解的决策/挖掘场景中,基于图谱结构化知识直接做图表征学习、规则推理、知识查询等。通过框架的协同实现LLM与SPG双驱动,支持跨模态知识对齐、逻辑引导知识推理、自然语言知识查询等。这对SPG知识语义的统一表示和引擎框架的跨场景迁移提出了更高的要求。
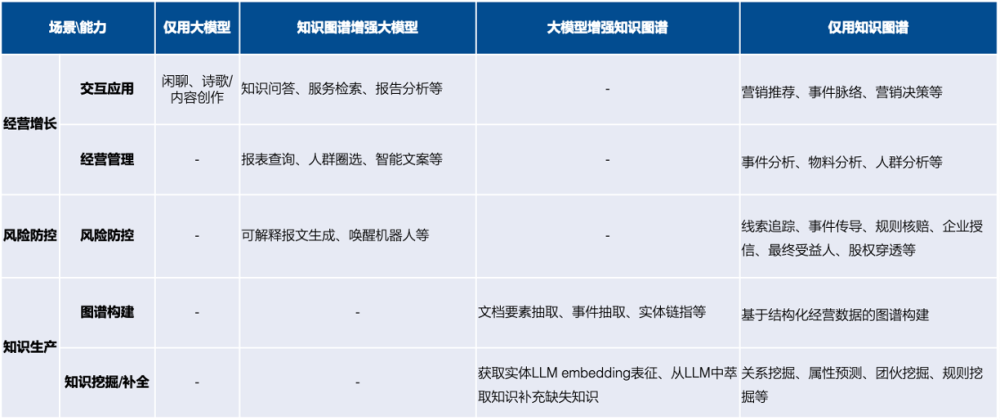
表1. 知识图谱和大模型在企业中应用场景分析
我们计划结合蚂蚁知识图谱实践和OpenSPG开源规划构建一个SPG与LLM双向融合的框架,实现知识生产和知识推理/查询的联动。总体能力定义上,核心包括三个部分:1)LLM增强SPG领域图谱构建。借助LLM强大的语言理解能力,构建可复用的知识生产流程,支持原子要素级及子图级的图谱构建。2)SPG增强LLM推理查询。为LLM应用提供必要的查询和推理能力,通过KGDSL规则推理或AGL图学习推理。3)LLM与SPG知识对齐。我们计划构建一个分层对齐(Alignment)架构,实现LLM与领域知识的对齐。
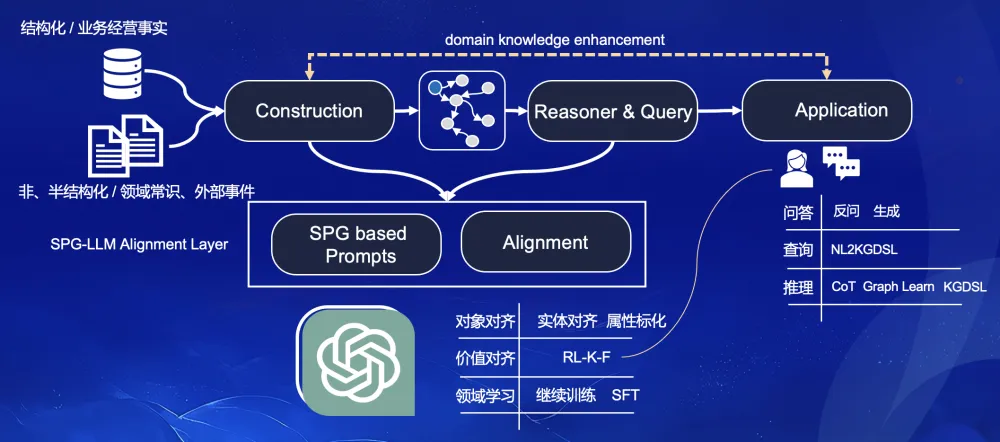
图 3. SPG和LLM双驱的整体链路
本文后面将详细介绍知识构建与图谱推理查询的能力模型,这里简单介绍下LLM与SPG对齐部分的能力模型,期望从四个层面推进SPG与LLM对齐层的能力建设:
领域知识对齐。通过继续预训练与SFT的能力,在基座模型的基础上实现supervised fine tuning帮助大模型快速理解领域知识、专业词汇、逻辑结构等,基于领域知识库及SPG图谱实例自动生成用于预训练的指令数据,从而把知识及逻辑约束融入到预训练过程中。
价值行为对齐。包括多轮对话及知识查询时的用户行为反馈,及基于知识库三元组的一致性反馈等,也尝试构建基于图谱知识构建奖励模型,通过SPG中的事实和常识生成正确和错误的答案,以此为基础实现基于SPG的 RL-K-F。
实体对象对齐。实体对象对齐是SPG+LLM双驱框架非常重要的基础能力,目的是为了获取同一个对象的LLM及SPG表示,通过向量计算实现两者的对齐,在用户问答或答案生成时能准确的获取到SPG中存储的知识,这里需要解决的一类核心问题是,自然语言与结构知识的对齐,将用户问题(Query)、原始文档(Document)中通过NER识别的词汇与SPG中的实体、概念、事件结构化对象对齐。
ICL上下文对齐。结合SPG中存储的知识自动构造prompts,充分激活SPG中的deep context信息,减少用户prompts的构造成本。其中 1/3/4是当下我们建设的重点,2在保持探索。未来相关能力建设取得阶段性进展后,再做分享。
04 LLM增强SPG知识构建
知识图谱知识抽取算法可迁移性不足也是多年难题,而LLM强大的语言理解能力可以较好的补足抽取算法迁移性不足的问题,围绕SPG的能力模型,期望LLM为SPG提供的构建能力包括如图 4所示。
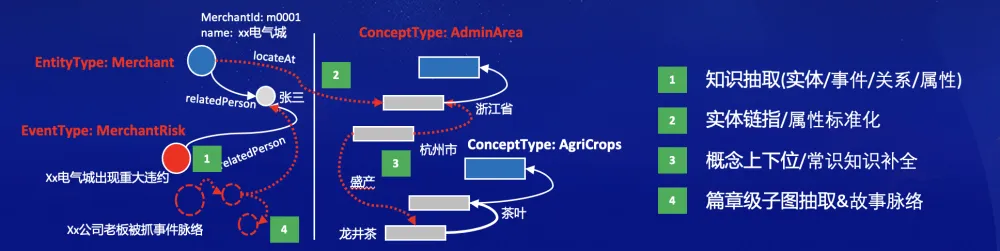
图 4. LLM增强SPG知识构建能力模型
1)知识要素抽取。这类是充分激活LLM的语言理解能力,SFT阶段通过指令微调让LLM充分理解领域知识并识别指令输入输出结构,ICL阶段基于SPG定义抽取的prompts模版并基于图谱实例构建prompts以提升知识抽取的准确性,可以严格按照SPG中语义结构定义模板并基于图谱实例填充prompts。常见的要素抽取任务包括:实体、概念、属性、事件等,结合Schema及实例自动构造的典型的关系抽取的prompt构造如下伪代码所示。
已知SPO关系包括:[疾病-疾病症状(表示疾病引起的症状)-症状(如头疼、颈部疼痛等),疾病-高发人群-人群(比如老年人、青年、儿童等),疾病-疾病科室-科室(如普外科、内分泌科等)]。从下列句子中提取定义的这些关系。最终抽取结果以json格式输出,输出存在多值的请用逗号分开,请不要输出规定格式外的任何信息。input:甲状腺结节是指在甲状腺内的肿块,可随吞咽动作随甲状腺而上下移动,是临床常见的病症,可由多种病因…
输出格式为:
{"spo":[{"subject":,"predicate":,"object":},]}
output:
{“spo”:[{“subject”:“甲状腺结节”,“predicate”:“疾病症状”,“object”:“颈部疼痛,咽喉部异物感,压迫感”}, ....]}
2)属性标化及实体链指。标化及链指是对象对齐能力的核心应用之一,基于SPG Evolving及SPG DC的能力定义,这一部分更多是构造符合SPG语义约束的知识表示,知识图谱的Slogan是 “Things, not Strings”,SPG的目标是每个属性、关系都有明确的领域模型,SPG Schema定义的典型示例如:
Company(企业):EntityType properties: hasPhone(电话号码):STD.ChinaMobile registerPlace(注册地):AdminArea IND#tax0fCompany(属于):Tax0fCompany relations: hasCert(拥有证书):Cert holdShare(持股):Company
通过LLM构造文本和结构化要素的embedding向量表示,借助向量数据库向量计算实现高效的对象对齐,将抽取结果文本链指/标化到目标类型的概念、实体实例上,通过这种方式,能加速知识的标准化,实现稀疏关系的可解释稠密化。SPG白皮书中对本段内容也有较多详细介绍。
3)概念上下位/常识知识补全。LLM的基本原理从海量语料中学习并归纳出词句之间的共现概率,做下一个词预测;常识及概念上下位也是人们从多种事实中归纳总结出来的具有企业内或行业间共识的通用知识。常识图谱和大模型之间有较强的相似性,都是对事实的归纳总结。不同的是,大模型基于海量语料具有超强的学习和归纳能力。LLM接收三元组的序列(h, r, t)中的任意两个,并输出头、尾概念或中间谓词。例如,<浙江省, 省会, ?> 可以补全为杭州市。常识知识补全可广泛应用在产业链上下游预测、实体词的同义词/反义词补全、分类概念上下位预测等场景中,也是概念知识抽取中概念标化算子中的基础依赖。
4)篇章级子图抽取&故事脉络。知识抽取的最终目标,是希望它具备抽取专业文献、读书的能力,输入一篇文档或一部书,通过反复的多轮抽取提取出核心知识图谱,并基于SPG实现知识分类和分层。篇章级抽取能力的实现有 原子知识要素抽取、自动知识建模和图谱子图融合等原子基础能力依赖,原子知识要素抽取是在确定好任务目标的情况下保证抽取的准确率和覆盖率,如抽取出人名、地名等基本属性,人-人关系,人-出生地-地域关系等。自动知识建模,是基于当前文档结构和基础Schema发现新的实体/概念/事件类型(Class)、属性名、关系名等, 并基于人工校验实现半自动建模, 图谱子图融合是将抽取出的新的子图结构和存量基础图谱融合。
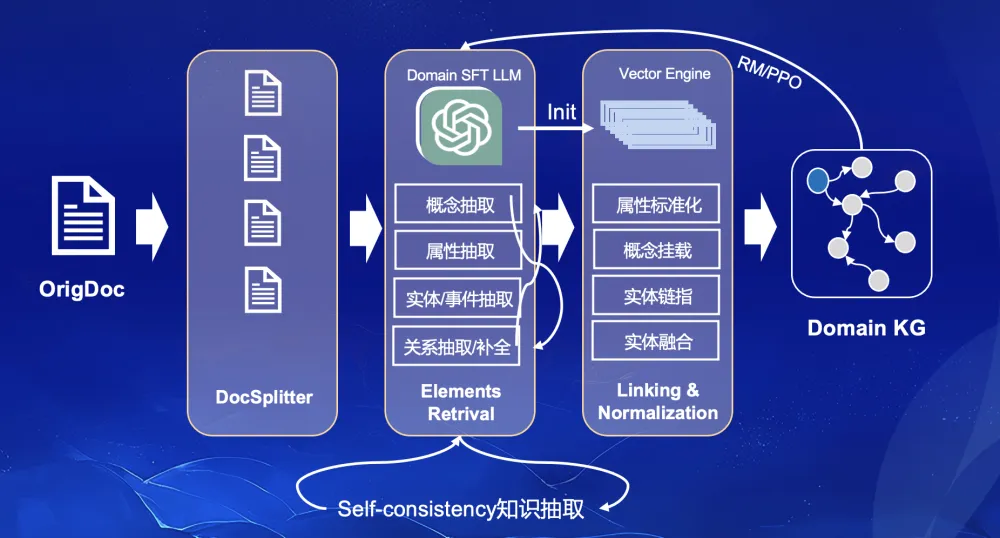
图 5. LLM增强SPG的知识构建pipeline
为实现可复用的知识生产过程,结合SPG的算子(Operator)化可编程模型,我们对知识生产过程做了组件化、流程化的抽象,如图5所示,总体上包含四大部分:文档切分、要素抽取、知识标化和知识评估。其中文档切分(Document Splitter),提供实现对输入文档做篇章、段落切分所必需的算子Operator,构建文档的段落结构,以实现逐段落的抽取。要素抽取(Elements Retrival)和知识标化(Linking & Normalization),前文已经介绍,不再赘述。知识评估(Knowledge evaluation),目前知识图谱平台主要还是靠接标注平台依赖人工评估完成知识正确性校验,成本相对还是比较高的,我们也在探索一些自动化评估的方法以提升知识抽取的准确性。
下面我们举个基于大模型self-consistency提升知识抽取准确率的一个简单示例。众所周知,医疗是典型的知识密集型应用场景,如何医疗知识的抽取和理解准确率也是我们面临的关键问题。

图 6. 基于self-consistency抽取示例
如图6所示的例子,以基于ChatGPT抽取"前列腺增生"为例,LLM在多次回答中可能会将其判定为疾病、症状或部位类型,导致结果存在一些不一致性。然而,通过让大模型生成不同的观点并进行自我辩论,也能取得不错的效果。为了提高医疗实体抽取的准确性,可以构造不同的辩论观点模板,给LLM定义不同的思考和生成方式。通过基于不同的提示和分类标签生成可能的论据,并让LLM对所有观点进行打分和判定,从而得出可能的结论。这种方法也可以显著提升医疗实体抽取的准确性。
除了基于LLM提取领域实体、概念这些文本意义上的知识外,在企业垂直领域的应用场景中,专家规则也非常重要,如何高效沉淀和管理领域专家经验,业界也有较多的探索和讨论。SPG提出了规则知识化的解决方案,实现专家规则与事实知识的有机融合,同时也构建知识要素之间的逻辑依赖形成规则链。图7给出了一个规则知识化的简单示例,通过规则知识化,可以构建部门、业务线、公司、行业等不同级别的专家经验的定义和复用。
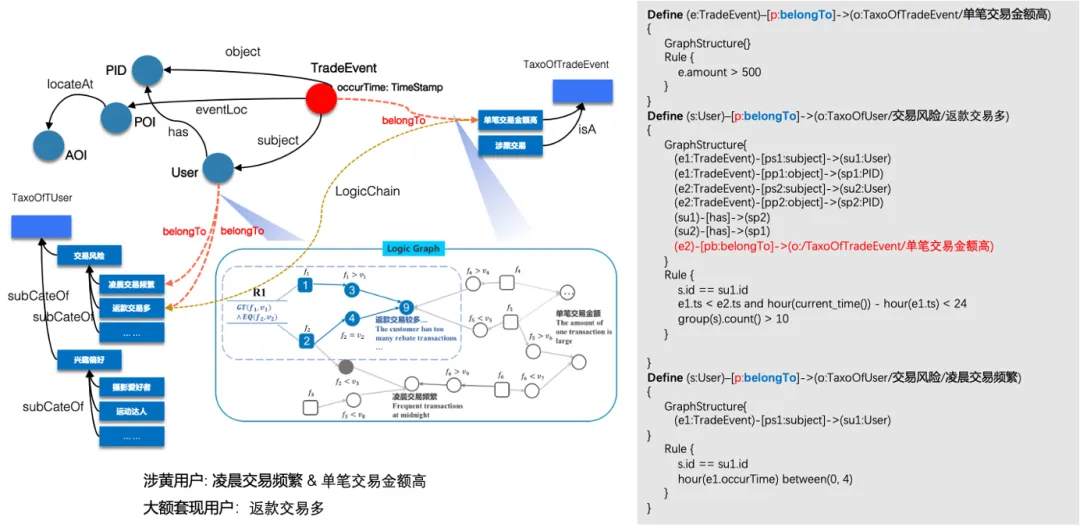
图 7. SPG规则链示意图
为避免专家规则过于复杂,我们可以将规则做原子粒度的拆分,图7中根据专家对灰黑产、赌诈盗的日常判定过程,涉嫌风险交易的用户典型判定维度有单笔交易金额、凌晨交易是否频繁、返款交易是否频繁等、是否频繁多卡交易、是否频繁境外交易等。我们可以将这些显性的专家判定过程定义成规则知识,专家可以直接基于文本标签做事实的判定和认证,文本标签又会反向的关联判定结构和可能的线索,反向溯因能较好的提升专家的判定效率和结果的可解释性。
05 SPG增强LLM可控问答
随着LLM的应用不断增加,LLM幻觉、复杂推理不足、知识更新时效性差等问题也极大的限制了LLM的产业落地,为缓解上述问题,业界也有较多的探索,检索增强(RAG)、插件外挂/插件学习、数据增强、图谱增强等方式,层出不穷,我们试图站在SPG的视角拆解下需要解决的几类关键问题。
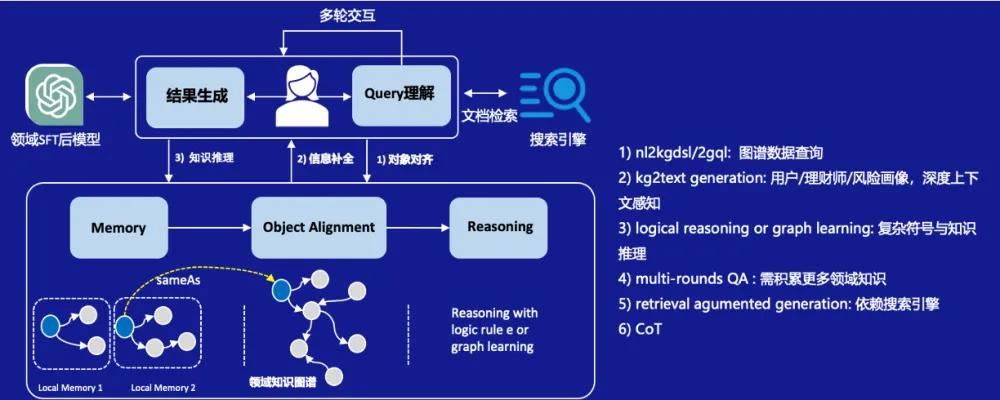
图 8. SPG增强LLM应用示意图
知识问答的核心过程是问和答,问是用户信息不输入的过程,答则是基于用户的输入收敛答案的范围,给用户一个可靠且满意的答案。SPG增强LLM从能力上可以分为三部分,获取事实知识、知识符号推理、LLM与SPG融合推理,结合这三种分类,在企业级垂直领域,SPG可提供的典型分类如下:
- 子图结构查询类。也即为NL2GQL或NL2KGDSL,将自然语言翻译成图谱查询语言,典型的数据多维分析、营销圈人等,将用户定义的逻辑结构生成确定的规则查询表达式,提升运营及数据分析的效能。
- 实体子图详情类。这类应用是SPG深度上下文(deep context)的典型应用。仅仅通过画像标签的归纳意义上的文本是不足以完整描述目标对象的深度信息的。换句话说,这类应用需要同时具备归纳性的结论和支撑结论所需的论据。它们需要能够进行正向推理和反向溯源,并提供结论所需的可解释线索。
- 符号逻辑推理类。符号化推理有LLM难以比拟的推理准确性、任务复杂度、计算成本等方面的优势,将用户问题转换成符号表示,并实现用户上下文与图谱数据的连接,完成最终的推理。可以直接规则符号推理也可以用图学习的方法做关系预测或属性分类等。这类任务和NL2KGDSL类似,需要借助LLM准确的理解问题结构和关键参数,实现LLM神经网络与SPG符号表示的有效协同。此类问题延伸,还有CoT/ToT/GoT等复杂问题多步求解问题,未来也希望将SPG的规则链和思维链的多步推导做融合,让LLM理解推理步骤并获取参数实现多步骤的联动推理。
- 多轮对话更多是上述三个基本能力的应用,识别意图、获取知识、交互反馈、生成答案。它更依赖于记录用户历史以实现长程历史记忆,将用户交互信息存储为原始文本难以有效归档且会越来越庞大,且历史对话规模巨大,直接喂给LLM会出现灾难性遗忘或同一问题反复询问的情况,我们也在探索通过要素抽取构造临时图谱将用户历史存储到用户私有命名空间中。另外,最近大热的检索增强方法(RAG),是搜索引擎应用的继续,它是缓解LLM大模型幻觉短期内比较有效的方法,从长期来看,搜索引擎固有问题如事实性、多源融合等问题依然没有得到解决,还会引入用户难以溯源的新问题。
结合上面几类应用的划分,站在SPG的视角,新增需要解决的核心问题有:
- 用户上下文记忆。可以构建基于图谱的用户历史Memory,将用户Query及Query扩展提取成结构化的子图表示,并将新的子图与Memory KG融合。同时,记录关键实体、概念节点与原始对话记录的索引关联,方便在新一轮对话时构造信息完备有效的prompt。在多轮对话过程中,可以提取历史memory,也方便基于memory构建用户事件脉络,例如医疗场景的用户既往病史和就医经历等。此外,借助SPG语义标准化,还可以实现Memory KG与Base KG的非物化自动连接。
- 自然语言查询。通过学习图谱Schema、实例及DSL逻辑结构,可以实现NL2KGDSL任务,从而自动生成查询子图。目前,业界也有许多基于大模型的自然语言问答探索。相对于传统的知识库问答(KBQA)方法,使用LLM可以大大降低提取实体要素和逻辑结构的成本。通过指令微调,让LLM学习SPG Schema结构、语义约束以及多种KGDSL语法结构,从而能够理解用户问题并生成目标KGDSL查询。在对其进行校正后,便可执行查询操作。
- 对象对齐能力。对象对齐前文已经介绍不再赘述。值得说明的是,通过与领域知识生产过程的联动,问答可以和知识抽取复用一套领域SFT LLM,复用统一的知识要素抽取能力和相同的对象对齐框架。
- 在知识查询过程中,经常会遇到需要进行逻辑计算或解释知识标签的情况。通过SPG逻辑规则定义逻辑标签,可以将用户问题转换成逻辑计算,并在给出结论的同时输出支撑结论的反向线索。
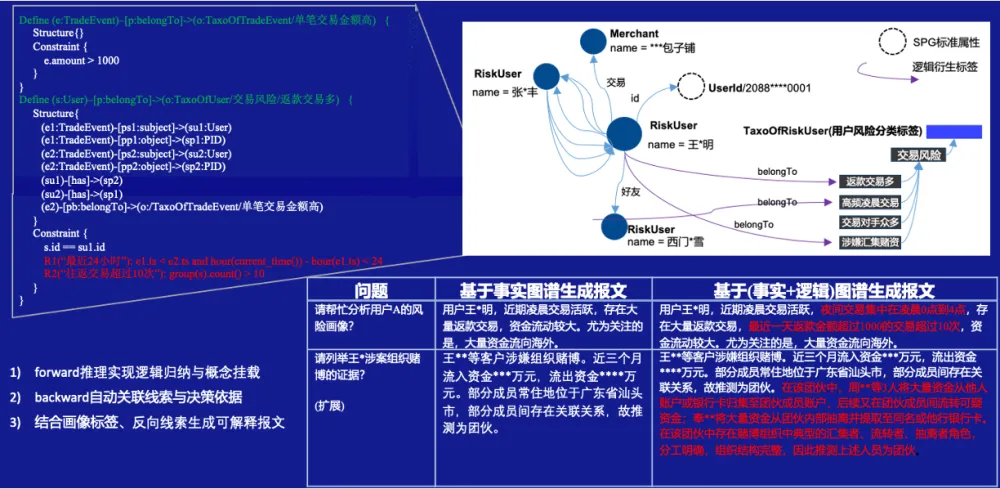
图 9.SPG深度上下文示例
如图9所示,通过实体、概念反向查询关联的图结构和画像信息,可以有效补全研报或风险画像生成过程中的事实信息。对于报文要素中依赖的逻辑关系和逻辑属性,SPG可以通过反向线索推理获取支撑结论的线索和证据,从而提供更具体的文案说明,提升结论的可解释性。
06 SPG与OpenKG社区联动
本次分享,给大家介绍了SPG的总体思想及SPG与LLM双驱应用的关键问题,SPG的核心目标是构建衔接大数据与AI技术体系的新一代知识语义框架及引擎,希望在AI时代,加速数据知识化高效集成企业海量数据,通过知识符号化更好地与AI技术体系联动。本次OpenSPG开源的主要能力是基础的SPG语义框架、查询能力和python SDK框架,我们也将持续迭代优化。
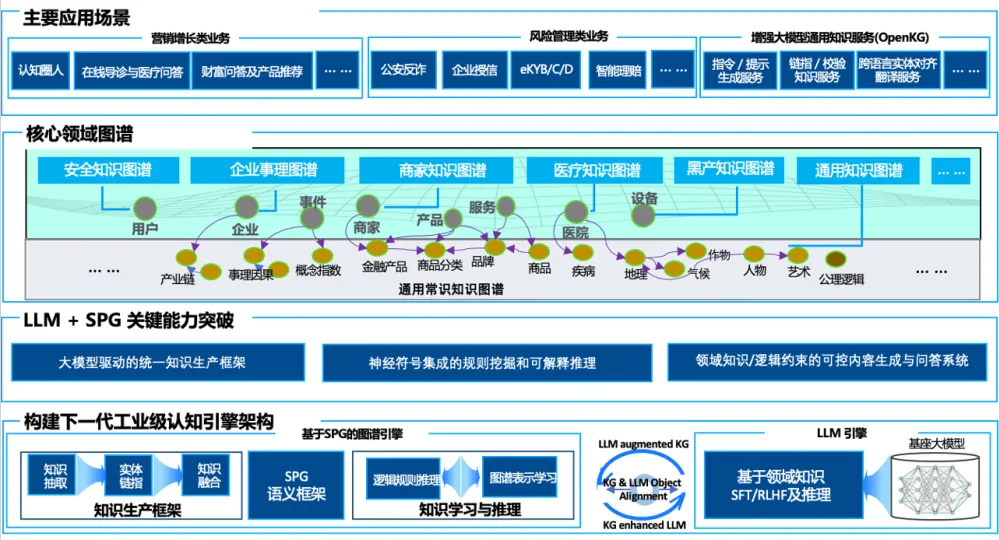
图 10.SPG + LLM双驱总体技术框架
未来,我们期望以OpenSPG为基础与OpenKG的深度协作,结合行业领域应用,不断提升提升OpenSPG的知识沉淀和系统引擎的能力:
联动OpenKG沉淀领域常识知识图谱。如SPG白皮书介绍,SPG语义框架可以自动实现领域通用常识与业务事实知识的分离,领域通用常识采用概念体系建模,构建他们之间的因果、上位、下位、语义体系,这类知识具有较强的行业通用性,可以在公司内、行业间等共享,我们也会通过OpenKG发布更多常识知识图谱和服务。
基于OpenSPG构建联动LLM技术范式。本次分享重点介绍了SPG、LLM双驱范式下需要解决的技术问题,未来我们也将持续攻坚克难,提升LLM增强的SPG知识构建,SPG增强的LLM可控生成,持续攻坚以SPG为代表的符号引擎与LLM为代表的神经网络在OpenSPG技术体系下神经符号融合,持续推动相关技术能力的升级和业务的应用落地。
OpenKG知识服务及领域扩展与应用。未来期望通过在各行业应用的深度落地,不断提升SPG的语义表达能力,扩展GeoSPG、ScienceSPG、MedicalSPG等领域语义模型,持续推进SPG语言范式的完善。通过OpenKG构建知识增强的大模型知识服务如知识对齐、指令生成、知识校验等特色知识能力。
目前OpenSPG已开源,欢迎更多有兴趣的业界同仁一起讨论、共建,推进知识图谱技术的成熟,建设新一代可控AI技术范式。
分享嘉宾:梁磊,蚂蚁集团知识引擎负责人、OpenKG TOC专家,CCF 专业会员。个人主要研究方向为知识图谱、图学习与推理引擎、AI工程、搜索引擎等。
笔记整理 | 邓鸿杰(OpenKG)
内容审定 | 陈华钧
-
从零开始学习贪心算法12-26
-
线性模型入门教程:基础概念与实践指南12-26
-
探索随机贪心算法:从入门到初级应用12-25
-
树形模型进阶:从入门到初级应用教程12-25
-
搜索算法进阶:新手入门教程12-25
-
算法高级进阶:新手与初级用户指南12-25
-
随机贪心算法进阶:初学者的详细指南12-25
-
贪心算法进阶:从入门到实践12-25
-
线性模型进阶:初学者的全面指南12-25
-
朴素贪心算法教程:初学者指南12-25
-
树形模型教程:从零开始的图形建模入门指南12-25
-
搜索算法教程:初学者必备指南12-25
-
算法高级教程:入门与初级用户指南12-25
-
随机贪心算法教程:初学者指南12-25
-
贪心算法教程:入门与实践指南12-25
