云计算
大厂咋做多系统数据同步方案的?

1 背景
业务线与系统越来越多,系统或业务间数据同步需求也越频繁。当前互联网业务系统大多MySQL数据存储与处理方案:
- 随信息时代爆炸,大数据量场景下慢慢凸显短板,如:需对大量数据全文检索,对大量数据组合查询,分库分表后的数据聚合查询
- 自然想到如何使用其他更适合处理该类问题的数据组件(ES)
因此,公司亟需一套灵活易用的系统间数据同步与处理方案,让特定业务数据可很方便在其他业务或组件间流转,助推业务快速迭代。
2 方案选型
当前业界针对系统数据同步较常见的方案有同步双写、异步双写、侦听binlog等方式,各有优劣。本文以MySQL同步到ES案例讲解。
2.1 同步双写
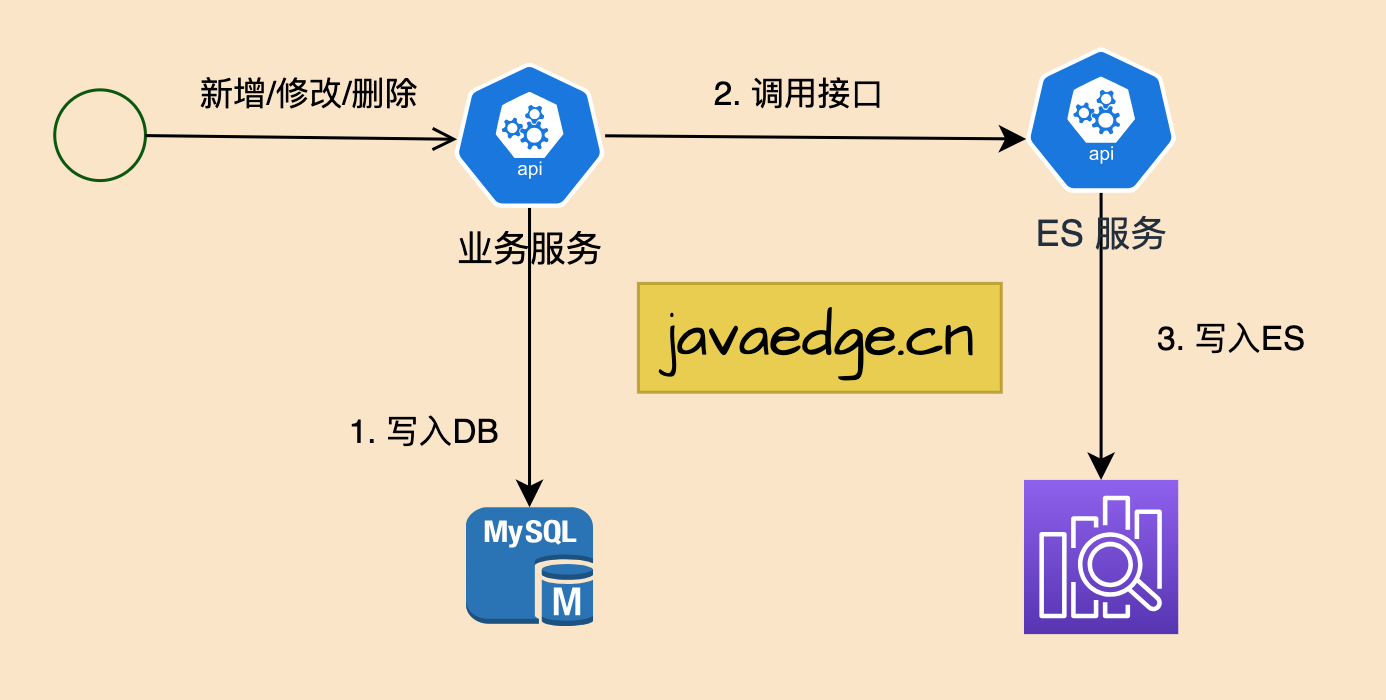
最简单方案,在将数据写到MySQL时,同时将数据写到ES,实现数据双写。
优点
- 设计简单易懂
- 实时性高
缺点
- 硬编码,有需要写入MySQL的地方都要添加写ES的代码,导致业务强耦合
- 存在双写可能失败导致数据丢失的风险,如:
- ES不可用
- 应用系统和ES之间网络故障
- 应用系统重启,导致系统来不及写入ES
- 对性能有较大影响,因为每次业务操作都要加个ES操作,若对数据有强一致性要求,还需事务处理
2.2 异步双写
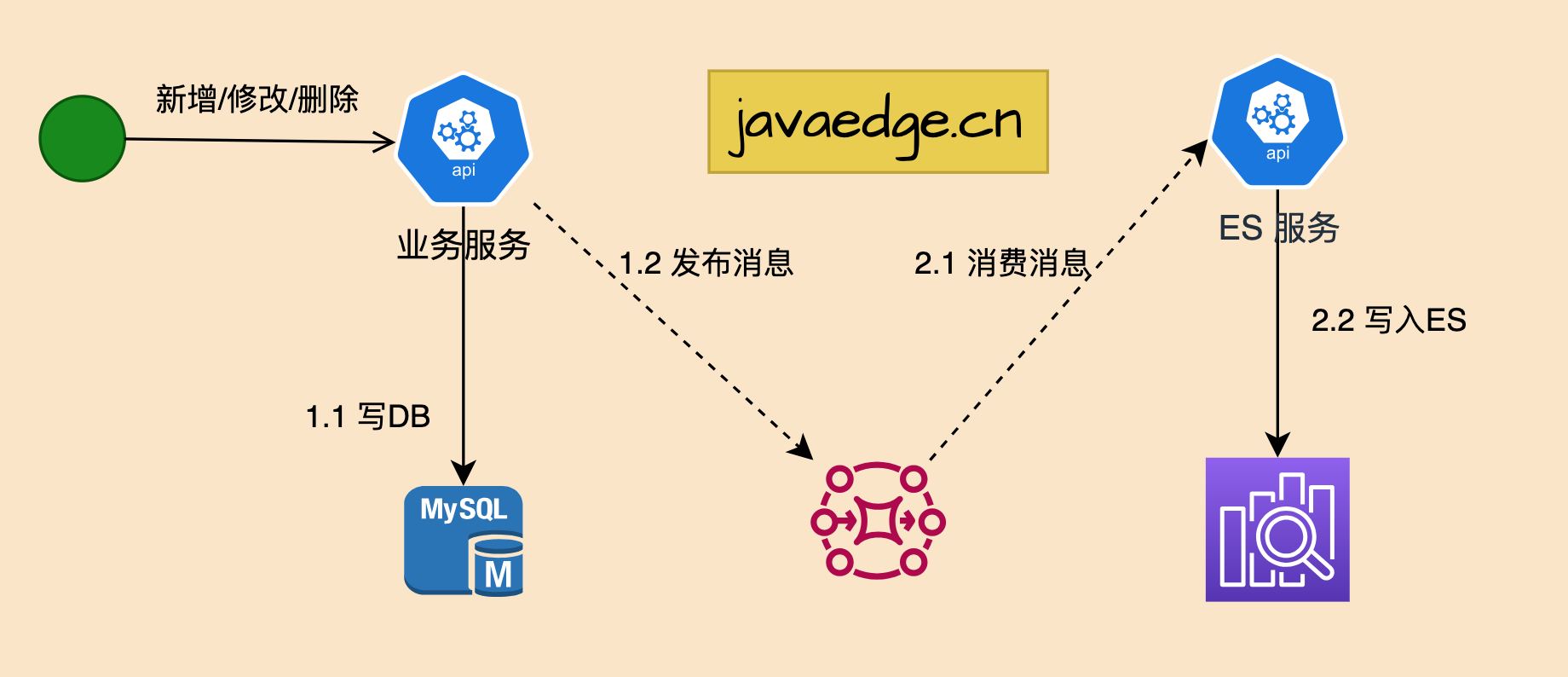
在同步双写基础加个MQ,实现异步写。
优点
- 解决性能问题,MQ的性能基本比mysql高出一个数量级
- 不易出现数据丢失问题,主要基于 MQ 消息的消费保障机制,比如 ES 宕机或者写入失败,还能重新消费 MQ 消息
- 通过异步的方式做到了系统解耦,多源写入之间相互隔离,便于扩展更多的数据源写入
缺点
- 数据同步实时性,由于MQ消费网络链路增加,导致用户写入的数据不一定马上看到,有延时
- 虽在系统逻辑做到解耦,但存在业务逻辑里依然需增加MQ代码耦合
- 复杂度增加:多个MQ中间件维护
- 硬编码问题,接入新的数据源需要实现新的消费逻辑
2.3 监听binlog
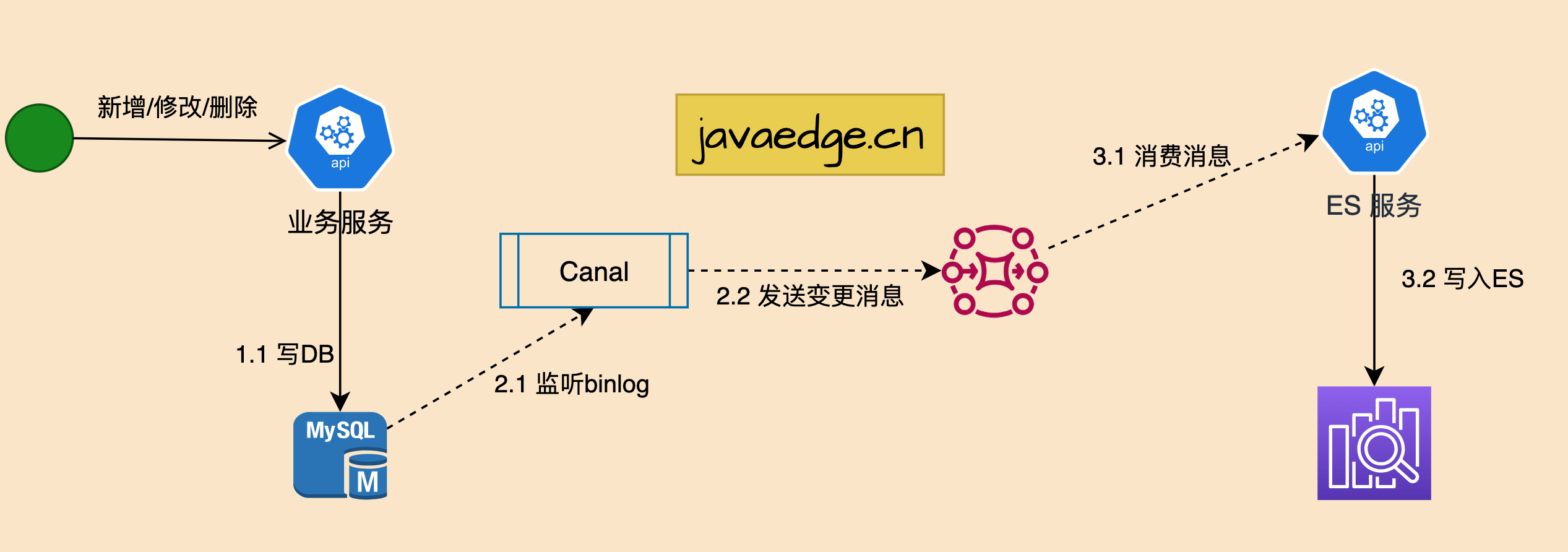
第二种方案基础上,主要解决业务耦合问题,所以引入数据变动自动监测与处理机制。
优点
- 无代码侵入,原有系统无需任何变化,无感知
- 性能高,业务代码完全无需新增任何多余逻辑
- 耦合度极低,完全无需关注原系统业务逻辑
缺点
- 存在一定技术复杂度
- 数据同步实时性可能有问题
基础组件的设计主要考虑尽量做到对业务无侵入,业务接入无感知,同时系统耦合度低,综上选型方案三,同时考虑该方案在可复用和可扩展还存在短板,所以在此基础又做优化。
3 整体方案设计
3.1 概述
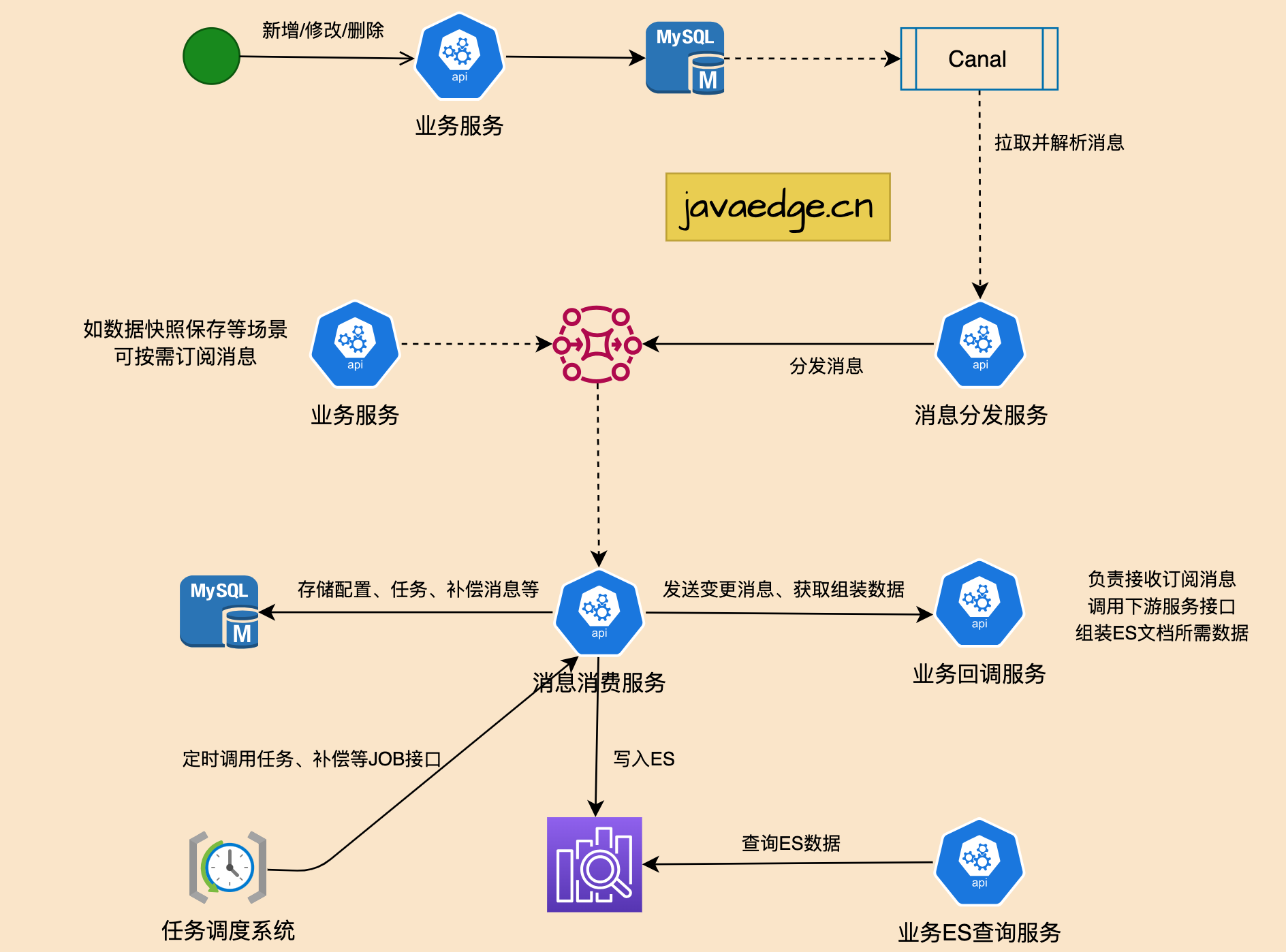
需求数据源都是MySQL,所以先考虑选择组件对MySQL数据变动做实时监听,业界成熟方案最熟悉的就是[canal],功能完善度,社区活跃度,稳定性等都符合。所以,基于canal对方案三优化,以满足多系统数据同步,达到业务解耦、可复用、可扩展。
设计核心理念
通过统一的“消息分发服务”实现与Canal Client对接,并将消息按统一格式分发到不同MQ集群,通过统一的“消息消费服务”去消费消息并回调业务接口,业务系统无需关注数据流转,只需关注特定业务的数据处理和数据组装。
“消息分发服务”和“消息消费服务”对各业务线,实现了数据流转过程中的功能复用。“消息消费服务”中的可分发到不同的MQ集群,和“消息消费服务”中的配置指定数据源输出实现了功能扩展。
核心模块
- canal:监听数据源的数据变动
- 消息分发服务:对接canal客户端,拉取变化的数据,将消息解析为JSON,按固定规则分发到MQ,MQ可根据业务配置指定到不同集群,实现横向扩展。由于变更数据可能批量,这里会将消息拆分为单条发送到MQ中,并且通过配置可以过滤掉一些业务上不需要的大字段,减少mq消息体
- 消息消费服务:从配置表中加载MQ队列,消费MQ中的消息,通过队列、回调接口、ES索引三者映射,将消息POST给业务回调接口,接收到业务回调接口返回的操作指令和ES文档后,写入对应的ES索引。写入失败时插入补偿表,等待补偿。这里ES索引可以根据业务配置指定到不同的集群,实现横向扩展
- 任务调度系统:定时调用消息消费服务中的消息补偿等定时任务接口
- 业务回调服务:接收消息消费服务POST过来的消息,根据消息中的指令和数据,结合数据库中的数据或下游服务接口返回的数据组装ES文档中所需要的数据,设置相应的操作指令返回给消息消费服务去写入ES
- 业务ES查询服务:通过ES SDK查询ES索引中的数据,通过接口返回给业务调用方
3.2 数据订阅消息分发服务
将数据的订阅与数据的消费通过MQ进行解耦,“数据订阅消息分发服务”的职责是对接Canal Client,解析数据变更消息,转换为常用的JSON格式的消息报文,按照业务配置规则分发到不同的MQ集群、路由。
3.2.1 基于Canal的数据变更监听机制
Canal主要是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费:
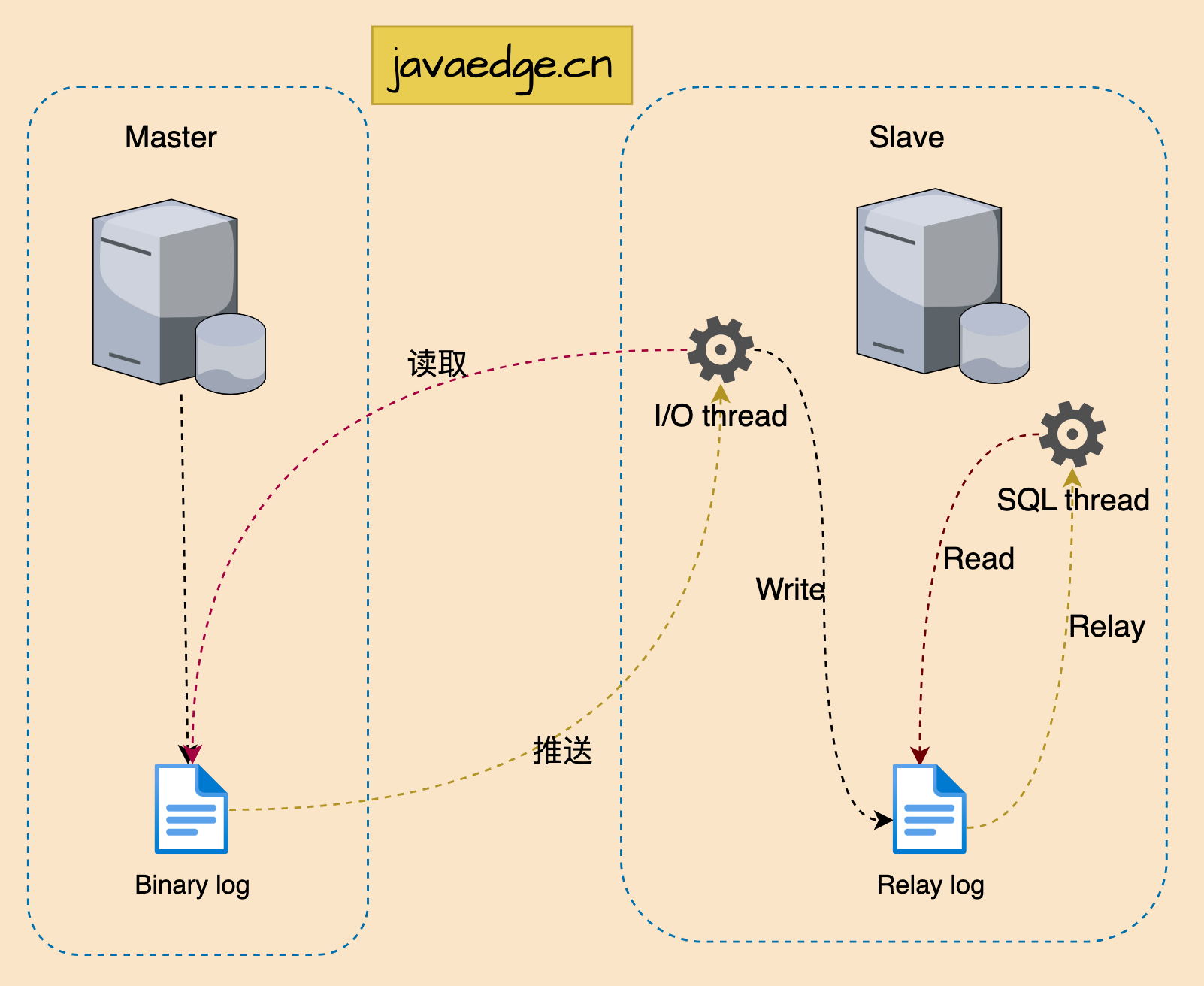
- MySQL master 将数据变更写入二进制日志(binary log,其中记录叫二进制日志事件binary log events,可通过 show binlog events查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
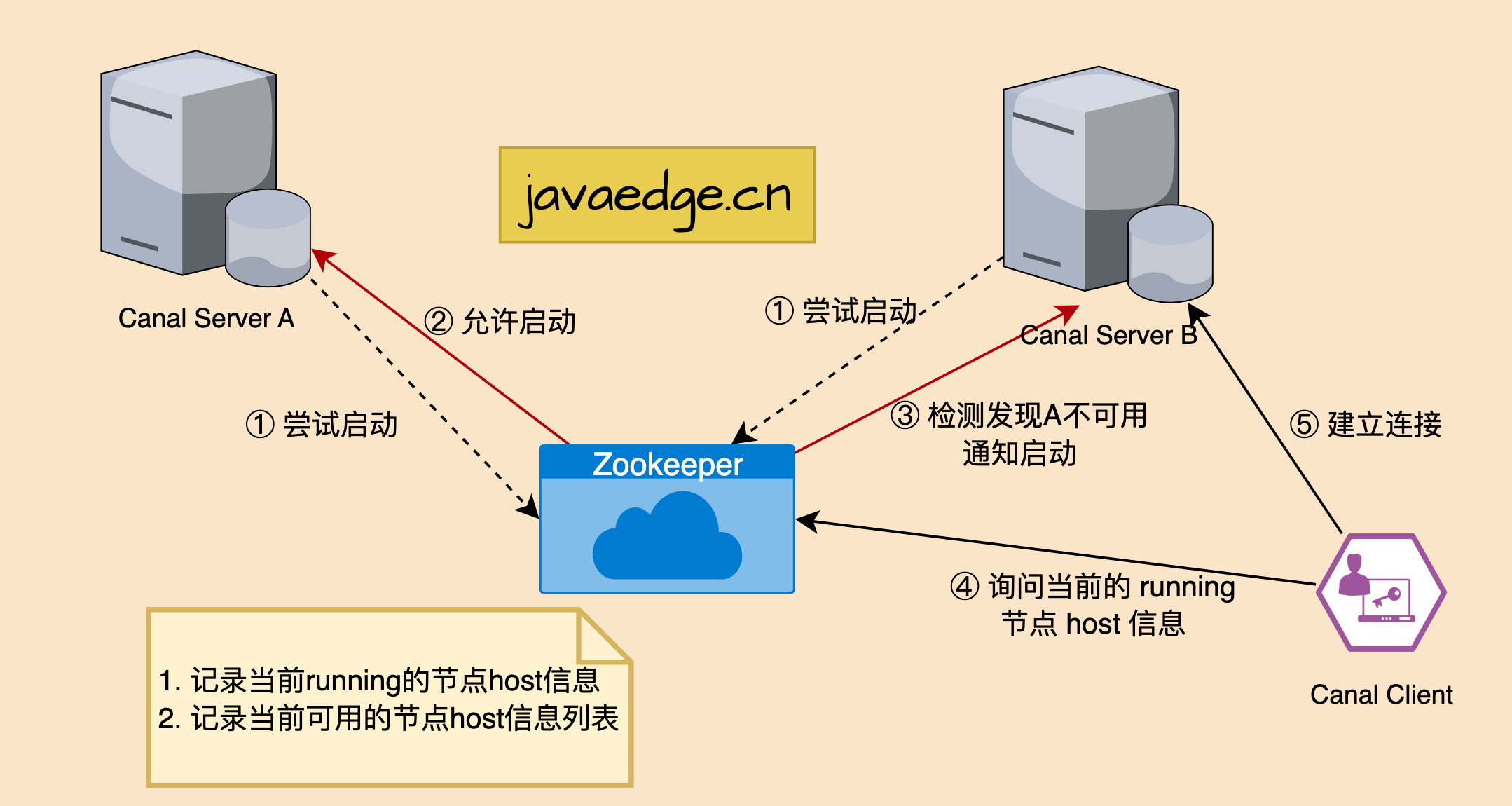
- Canal server 和 client 端高可用依赖zk,启动 canal server 和 client 时都会从 zk 读信息
- Canal server 和 client 启动时都会去抢占 zk 对应的 running 节点,保证只有一个 server 和 client 在运行,而 server 和 client 高可用切换也是基于监听 running 节点
- Canal server 要启动某个 canal instance 时都先向 zookeeper 进行一次尝试启动判断 (实现:创建 EPHEMERAL 节点,谁创建成功就允许谁启动)
- 创建 zookeeper 节点成功后,对应的 canal server 就启动对应的 canal instance,没有创建成功的 canal instance 就会处于 standby 状态
- 一旦 zookeeper 发现 canal server A 创建的节点消失后,立即通知其他的 canal server 再次进行步骤 1 的操作,重新选出一个 canal server 启动 instance
- Canal client 每次进行 connect 时,会首先向 zookeeper 询问当前是谁启动了 canal instance,然后和其建立链接,一旦链接不可用,会重新尝试 connect
3.2.2 基于Canal Client 分摊设计提升系统处理效率
从Canal服务高可用设计可见,Canal Client当有多个实例启动时,会保证只有一个实例在运行,消费binlog消息。而承载Canal Client的"数据订阅消息分发服务"会部署在多台服务器,由于服务发布时每台服务器启动时间不同,所有Canal Client活跃实例都会集中在先启动的那台服务器运行,消费binlog消息。
其余服务器运行的Canal Client都处备用状态,不能充分利用每台服务器资源。因此希望不同destination分摊在不同服务器执行,但所在服务器宕机时会自动转移到其他服务器执行,这样充分利用每一台服务器,提供binlog消息消费性能。
为此,引入elasticjob-lite组件,利用分片特性二次封装,实现侦听destination在某台服务器中上下线的变更事件。
elasticjob-lite分片原理
ElasticJob 中任务分片项的概念,使任务可在分布式环境运行,每台任务服务器只运行分配给该服务器的分片。随着服务器的增加或宕机,ElasticJob 会近乎实时的感知服务器数量的变更。
若作业分 4 片,用两台服务器执行,则每个服务器分到 2 片:
新增Job服务器时,ElasticJob 会通过注册中心的临时节点的变化感知到新服务器,并在下次任务调度时重分片,新服务器会承载一部分作业分片:
当作业服务器在运行中宕机时,注册中心同样会通过临时节点感知,并将在下次运行时将分片转移至仍存活的服务器,以达到作业高可用。本次由于服务器宕机而未执行完的作业,则可以通过失效转移的方式继续执行。
3.2.3 资源隔离
该系统使用方包含公司各业务线,如何保障线上问题后,各业务不相互影响。
在MQ集群和队列级别都支持基于业务的资源隔离;将从canal中拉取出来的变更消息,按规则分发到不同MQ集群,设置统一路由键规则, 以便各业务在对接时申请自己业务的MQ队列,按需绑定对应MQ集群和消息路由。
- MQ集群路由
通过配置将不同的destination映射到不同的MQ集群和ZK集群,可达到性能横向扩展。
- MQ消息路由规则
canal从binlog中获取消息后,将批量消息拆分成单条消息,进行分片规则运算后发送到指定rabbitmq交换机和路由键,以便根据不同业务场景,按不同业务规则绑定到不同队列,通过消费服务进行消息消费处理,同时会建立一个名为“exchange.canal”的exchange,类型为 topic,路由键规则:key.canal.{destination}.{database}.{table}.{sharding},sharding按pkName-value排序后的hashcode取模分片,队列命名规则约定:queue.canal.{appId}.{bizName} 如:
queue.canal.trade_center.order_search.0 绑定 key.canal.dev-instance.trade_order.order_item.0 queue.canal.trade_center.order_search.0 绑定 key.canal.dev-instance.trade_order.order_extend.0 ...
3.3 数据订阅消息消费服务
为实现消息的消费与业务系统解耦,独立出"数据订阅消费服务”。消费从”数据订阅消息分发服务“中投递的数据变更MQ消息,根据业务配置回调指定的业务回调接口。业务回调接口负责接收数据变更消息,组装需要执行的ES文档信息,返回给消费服务进行ES数据操作。
3.3.1 执行指令
从binlog订阅的消息有3类操作:INSERT,UPDATE,DELETE,这里新增一个SELECT指令,作用是业务回调接口在收到该指令后,从数据库中重新获取最新的数据组装成需要执行的ES文档信息,返回给消费服务进行ES数据操作。
主要应用在全量同步,部分同步,文档刷新,消息补偿等场景。
3.3.2 增量同步
- MQ队列动态加载
新的业务功能上线时,会配置对应的队列绑定相关的路由键,订阅到业务场景需要的数据变更的消息。为避免每次有新业务接入需要重新更新消费服务代码,重新发布服务,需实现能定时加载配置表数据,实现动态添加MQ队列侦听的功能。
使用SimpleMessageListenerContainer容器设置消费队列的动态监听。为每个MQ集群创建一个SimpleMessageListenerContainer实例,并动态注册到Spring容器。
- 业务队列绑定规则
一个业务通常对应一个ES索引,一或多个MQ队列(队列绑定路由键的规则见: MQ消息分片规则):
- MQ消息顺序消费
一个queue,有多个consumer去消费, 因为无法保证先读到消息的 consumer 一定先完成操作,所以可能导致顺序错乱。因为不同消息都发到了一个queue,然后多个消费者又消费同一个queue的消息。为此,可创建多个queue,每个消费者只消费一个queue, 生产者按规则把消息放入同一queue(见:3.4.4.2 MQ消息分片规则),这样同一个消息就只会被同一个消费者顺序消费。
服务通常集群部署,天然每个queue就会有多个consumer。为解决这问题引入elasticjob-lite对MQ分片,如有2个服务实例,5个队列,可让实例1消费队列1、2、3,让实例2消费队列4、5。当其中有一个实例1挂掉时会自动将队列1、2、3的消费转移到实例2上,当实例1重启启动后队列1、2、3的消费会重新转移到实例1。
RabbitMQ消费顺序错乱原因通常是队列消费是单机多线程消费或消费者是集群部署,由于不同的消息都发送到了同一个 queue 中,多个消费者都消费同一个 queue 的消息。如消费者A执行增加,消费者B执行修改,消费者C执行删除,但消费者C执行比消费者B快,消费者B又比消费者A快,导致消费 binlog 执行到ES时顺序错乱,本该增加、修改、删除,变成删除、修改、增加。
对此,可给 RabbitMQ 创建多个 queue,每个消费者单线程固定消费一个 queue 的消息,生产者发送消息的时候,同一个单号的消息发送到同一个 queue 中,由于同一个 queue 的消息有序,那同一单号的消息就只会被一个消费者顺序消费,从而保证消息顺序性:
但如何保证集群模式下,一个队列只在一台机器上进行单线程消费,若这台机器宕机如何进行故障转移。 对此,引入elasticjob-lite对MQ分片,如有2个服务实例,5个队列,我们可以让实例1消费队列1、2、3,让实例2消费队列4、5。当其中有一个实例1挂掉时会自动将队列1、2、3的消费转移到实例2上,当实例1重启启动后队列1、2、3的消费会重新转移到实例1。
对消息顺序消费敏感的业务场景,通过队列分片提升整体并发度。对消息顺序消费不敏感业务场景也可配置成某队列集群消费或单机并发消费。针对不同的业务场景合理选择不同的配置方案,提升整体性能。
3.3.3 全量同步
通过Canal获取的变更消息只能满足增量订阅数据的业务场景,然而我们通常我们还需要进行一次全量的历史数据同步后增量数据的订阅才会有意义。对于业务数据表的id是自增模式时,可以通过给定一个最小id值,最大id值,然后进行切片,如100个一片,生成MQ报文,发送到MQ中。消费MQ消息后对消息进行组装,生成模拟增量数据变更的消息报文,走原有的增量消息回调的方式同步数据。
3.3.4 部分同步
有的时候我们需要修复指定的数据,或业务表的id是非自增模式的,需要进行全量同步。可以通过部分同步的接口,指定一组需要同步的id列表,生成分片MQ报文,发送到MQ中。消费服务接收到同步MQ消息后对消息进行组装,生成模拟增量数据变更的消息报文,走原有的增量消息回调的方式同步数据。
3.3.5 刷新文档
当我们ES索引中有大批量的数据异常,需要重新刷新ES索引数据时,可以通过生成一个全量同步的任务,分页获取指定ES索引的文档ID列表,模拟生成部分同步消息报文,发送到MQ中。消费MQ消息后对消息进行组装,生成模拟增量数据变更的消息报文,走原有的增量消息回调的方式同步数据。
3.3.6 消息补偿
将同步失败的消息存储到消息重试表中,通过Job执行补偿,便于监控。补偿时将消息重置为 SELECT 类型的MQ报文。业务回调接口接收到消息后会从数据库中获取最新的数据更新ES文档。
3.4 ES SDK功能扩展
目前ES官方推荐使用的客户端是RestHighLevelClient,我们在此基础上进行了二次封装开发,主要从扩展性和易用性方面考虑。
3.4.1、常用功能封装
- 使用工厂模式,方便注册和获取不同ES集群对应的RestHighLevelClient实例,为业务端使用时对ES集群的扩展提供便利。
- 对RestHighLevelClient的主要功能进行二次封装如:索引的存在判断、创建、更新、删除;文档的存在判断、获取、新增、更新、保存、删除、统计、查询。 降低开发人员使用RestHighLevelClient的复杂度,提高开发效率。
3.4.2、ES查询数据权限隔离
对于一些有数据隔离需求的业务场景,我们提供了一个ES数据隔离插件。在ES SDK中设计了一个搜索过滤器的接口,采用拦截器的方式对统计文档,搜索文档等方法的搜索条件参数进行拦截过滤。
/**
* 搜索过滤器
*/
public interface SearchSourceBuilderFilter {
String getFilterName();
void filter(SearchSourceBuilder searchSourceBuilder);
}
4 坑
4.1 Canal相关
4.1.1 Canal Admin 部署时需注意的配置项
- 如何支持HA:‘canal.instance.global.spring.xml’ 设置为 ‘classpath:spring/default-instance.xml’
- 设置合适的并行线程数:canal.instance.parser.parallelThreadSize,我们当前设置的是16,如果该配置项被注释掉,那么可能会导致解析阻塞
- 开启tsdb导致的各种问题:canal默认开启tsdb功能,也就是会通过h2数据库缓存解析的表结构,但是实际情况下,如果上游变更了表结构,h2数据库对应的缓存是不会更新的,这个时候一般会出现神奇的解析异常,异常的信息一般如下:‘Caused by: com.alibaba.otter.canal.parse.exception.CanalParseException: column size is not match for table’,该异常还会导致一个可怕的后果:解析线程被阻塞,也就是binlog事件不会再接收和解析。目前认为比较可行的解决方案是:禁用tsdb功能,也就是canal.instance.tsdb.enable设置为false。如果不禁用tsdb功能,一旦出现了该问题,必须要「先停止」Canal服务,接着「删除」$CANAL_HOME/conf/目标数据库实例标识/h2.mv.db文件,然后「启动」Canal服务。目前我们是设置为禁用的。
- 设置合理的订阅级别:其配置项是‘canal.instance.filter.regex’;库表订阅的配置建议配置到表级别,如果定义到库级别一方面会消费一些无效的消息,给下游的MQ等带来不必要的压力。还有可能订阅到一些日志表等这类有着大字段数据的消息,消息过大在JSON化的时候可能导致内存溢出异常。针对这个问题我们进行大字段过滤和告警的改造。
4.1.2 binlog文件不存在,导致同步异常
如果发现Canal Client 长时间获取不到binlog消息,可以去Canal Admin 后台去看一下Instance管理中的日志。大概率会出现“could not find first log file name in binary log index file”,这个是因为zk集群中缓存了binlog信息导致拉取的数据不对,包括定义了binlog position但是启动服务后不对也是同样的原因。
解决:
- 单机部署的删除canal/conf/$instance目录中的meta.dat文件
- 集群模式需要进入zk删除/otter/canal/destinations/xxxxx/1001/cursor,然后重启canal
4.2 ES updateByQuery问题
ES的Update By Query对应的就是关系型数据库的update set … where…语句;该命令在ES上支持得不是很成熟,可能会导致的问题有:批量更新时非事务模式执行(允许部分成功部分失败)、大批量操作会超时、频繁更新会报错(版本冲突)、脚本执行太频繁时又会触发断路器等。我们的解决办法也比较简单,直接在生产环境放弃使用updateByQuery方法,配置成使用先查询出符合条件的数据,然后分发到MQ中单条分别更新的模式。
5 规划
- 问题时及时报警,特别在业务连续性监控上,如系统内特定组件工作异常导致数据同步流中断,是后续需重点优化的方向
- 有些对实时性要求较高的业务依赖该系统进行数据同步,随着业务量越来越大,该方案当前当前采用的MQ组件在性能和高可用性都有所欠缺,后续打算采用性能更好,可用性机制更完善的MQ组件
- 由于采用小步快跑迭代,设计更多考虑线上运行顺畅性,而忽略新业务接入便利性,目前一个新的业务服务对接数据同步系统,需要维护人员做不少配置文件,数据库等相关的修改,并做人工确认,随着接入需求越来越频繁,亟需一个管理后台,提升接入的效率和自动化度
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都国企技术专家兼架构,多家大厂后台研发和架构经验,负责复杂度极高业务系统的模块化、服务化、平台化研发工作。具有丰富带团队经验,深厚人才识别和培养的积累。
参考:
- 编程严选网
-
Fluss 写入数据湖实战12-23
-
揭秘 Fluss:下一代流存储,带你走在实时分析的前沿(一)12-22
-
DevOps与平台工程的区别和联系12-20
-
从信息孤岛到数字孪生:一本面向企业的数字化转型实用指南12-20
-
手把手教你轻松部署网站12-20
-
服务器购买课程:新手入门全攻略12-20
-
动态路由表学习:新手必读指南12-20
-
服务器购买学习:新手指南与实操教程12-20
-
动态路由表教程:新手入门指南12-20
-
服务器购买教程:新手必读指南12-20
-
动态路由表实战入门教程12-20
-
服务器购买实战:新手必读指南12-20
-
新手指南:轻松掌握服务器部署12-20
-
内网穿透入门指南:轻松实现远程访问12-20
-
网站部署入门教程12-20
