Javascript
页面的json数据浏览器无法访问,还有什么别的办法获取数据?

本文主要是介绍页面的json数据浏览器无法访问,还有什么别的办法获取数据?,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
大家好,我是皮皮。
一、前言
前几天在Python钻石流群【空】问了一个Python网络爬虫的问题,一起来看看吧。问题描述:
请教一个问题,页面的json数据浏览器无法访问,还有什么别的办法获取数据
图片如下:
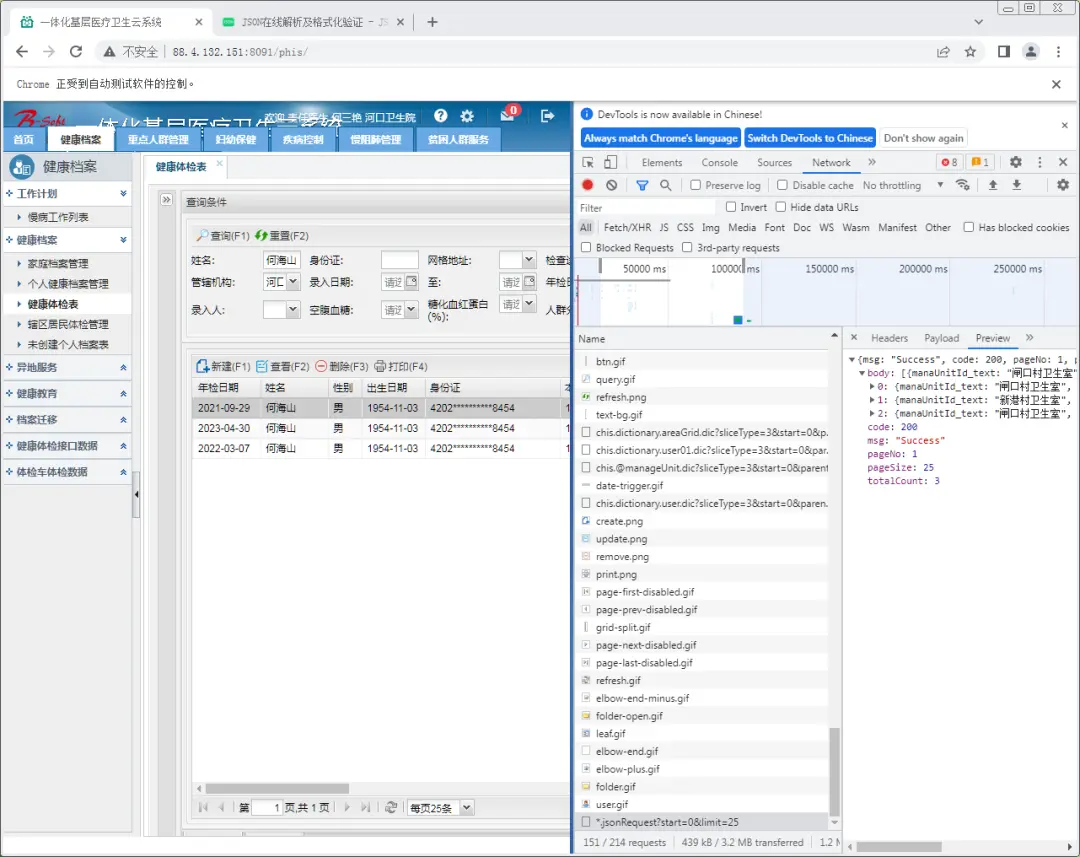
这个问题看上去有点怪怪的。
二、实现过程
看上去代码倒是很简洁,没啥难度,这里【猫药师Kelly】给了一个指导:
2种办法:
- 不用selenium,直接request.post提交json
- 用selenium,截取jsonRequest的响应
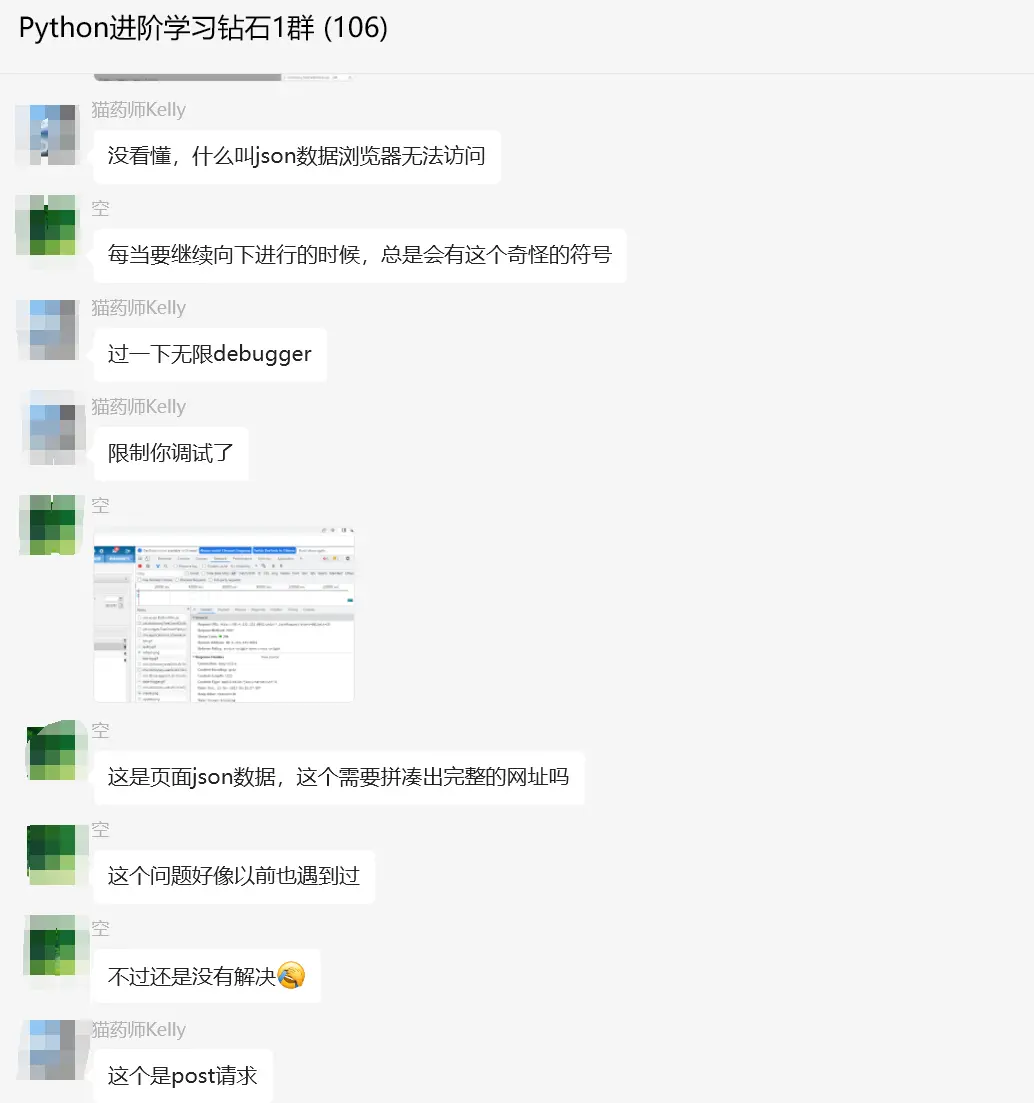
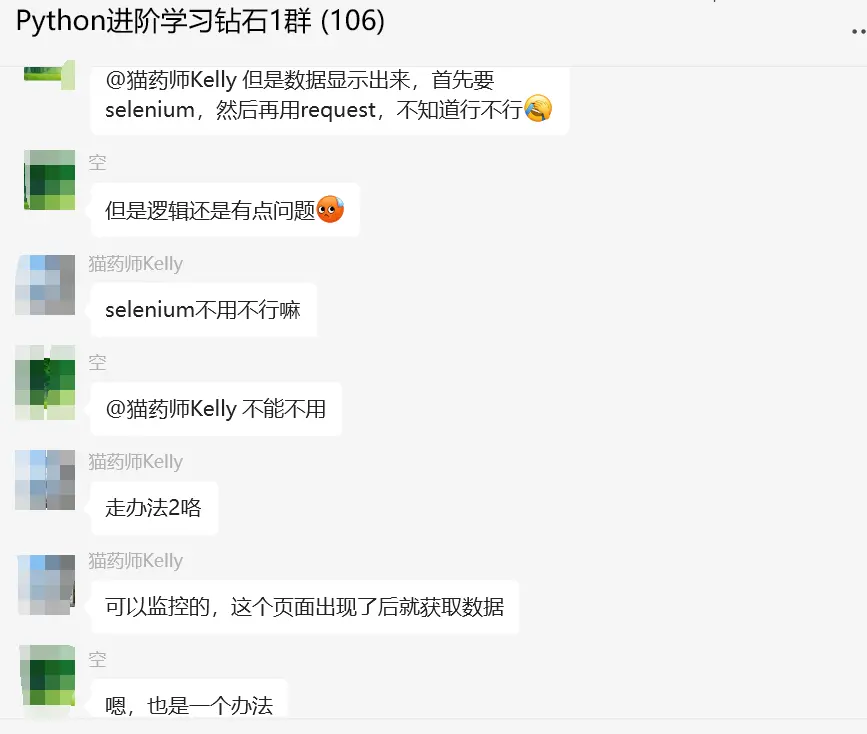
方法1值得优先尝试,方法2的话,原生selenium代码有点麻烦,换成selenium-wire也行,或者直接mitmproxy。
顺利地解决了粉丝的问题。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python可视化的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【空】提出的问题,感谢【猫药师Kelly】给出的思路,感谢【Brónson Ezrâ】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。
这篇关于页面的json数据浏览器无法访问,还有什么别的办法获取数据?的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
您可能喜欢
-
【JS逆向百例】爱疯官网登录逆向分析12-23
-
Vue3教程:新手入门到实践应用12-21
-
VueRouter4教程:从入门到实践12-21
-
Vue3项目实战:从入门到上手12-20
-
Vue3项目实战:新手入门教程12-20
-
VueRouter4项目实战:新手入门教程12-20
-
如何实现JDBC和jsp的关系?-icode9专业技术文章分享12-20
-
Vue项目中实现TagsView标签栏导航的简单教程12-20
-
Vue3入门教程:从零开始搭建你的第一个Vue3项目12-20
-
从零开始学习vueRouter4:基础教程12-20
-
Vuex4课程:新手入门到上手实战全攻略12-20
-
Vue3资料:新手入门及初级教程12-20
-
Vuex4入门指南:轻松掌握Vue状态管理12-20
-
Vue3学习:从入门到实践的简单教程12-20
-
Vue学习:从入门到简单项目实战12-20
栏目导航
