Java教程
脚本相关:sed、awk、shell

shell中的常用特殊字符
shell中的通配符
当用户需要用命令处理一组文件,例如 file1.txt, file2.txt, file3.txt … 用户不必一一输入文件名,可以使用shell通配符。shell通配符如下:
| 通配符 | 含义 | 实例 |
|---|---|---|
| 星号(*) | 匹配任意长度的字符串 | ls file_*.txt file_1.txt file_2.txt file_3.txt |
| 问号(?) | 匹配一个长度的字符串 | ls file_?.txtfile_1.txt file_a.txt file.x.txt |
| 方括号([…]) | 匹配其中指定的一个字符 | ls file_[otr].txt file_o.txt file_r.txt file_t.txt |
| 方括号([-]) | 匹配指定的一个字符范围 | ls file_[a-z].txt file_a.txt file_b.txt file_z.txt |
| 方括号([^…]) | 除了其中指定的字符,其他均可匹配 | ls file_[^obt].txt 显示除了file_o.txt,file_b.txt,file_t.txt外的其他文件 |
输入/输出重定向
输入/输出重定向是改变shell命令或程序默认的标准输入/输出目标,重新定向到新的目标。
Linux中默认的标准输入定义为键盘,标准输出定义为终端窗口
用户可以为当前操作改变输入或输出,迫使某个特定命令的输入或输出来源作为外部文件。
输出重定向(>)
含义:把本来应该输出到屏幕上的正确的数据,修改输出到其他的地方(文件)。例如:
echo "hello world" > log [把hello world写入log.txt文件中,写入前会把log.txt文件内容清掉。]
echo "happy" >> log [追加的方式写]
输入重定向(<)
含义: 改变默认的输入源,把本来应该从键盘输入的信息该从其他位置获取。(例如从文件中)[linux@linux ~]# cat /etc/passwd #这里省略输出信息,读者可自行查看
[linux@linux ~]# cat < /etc/passwd #输出结果同上面命令相同
#注意,虽然执行结果相同,但第一行代表是以键盘作为输入设备,
#而第二行代码是以 /etc/passwd 文件作为输入设备。
[linux@linux ~]# cat a.txt
[linux@linux ~]# cat < /etc/passwd > a.txt
[linux@linux ~]# cat a.txt #输出了和 /etc/passwd 文件内容相同的数据
#可以看到,通过重定向 /etc/passwd 作为输入设备,并输出重定向到 a.txt,
#最终实现了将 /etc/passwd 文件中内容复制到 a.txt 中。
错误重定向(2>)
含义:把本来应该输出到屏幕上错误的信息改输出到文件中。
示例:
dasfs123 2> log.txt
说明:
dasds123本身是不存在的命令,它是一条错误的命令。本来应该向屏幕上输出command not found
,这条命令现在会输出到log.txt文件中。
命令置换
含义:将一个命令的输出当作另一个命令的参数,我们叫做命令置换.格式:
command1 `command2` command2的输出当作command1的参数
注:这里不是单引号,而是反撇号! esc下面的键为反撇号
示例:
find `pwd` -name hello.c
ls `pws`
sed
超大文件处理;
对文件进行批量增加,替换等。
有规律的文本,例如 以分号,空格等分隔的日志文件等
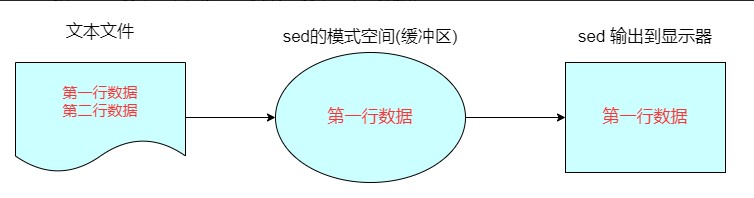
sed 会根据脚本命令来处理文本文件中的数据,这些命令要么从命令行中输入,要么存储在一个文本文件中,此命令执行数据的顺序如下:
每次仅读取一行内容;
根据提供的规则命令匹配并修改数据。注意,sed 默认不会直接修改源文件数据,而是会将数据复制到缓冲区中,修改也仅限于缓冲区中的数据;
将执行结果输出。
当一行数据匹配完成后,它会继续读取下一行数据,并重复这个过程,直到将文件中所有数据处理完毕。
sed语法
sed [options] '{command}[flags]' [filename]
options 命令选项
-e 脚本命令 该选项会将其后面的脚本命令添加到已有的命令中。
-f 脚本文件 该选项会将其文件中的脚本命令添加到已有的命令中。
-n 只显示匹配的行
-i 直接对原文件进行操作,会修改原文件内容。sed命令默认不修改文件
{command}[flags]
sed内部常用命令
i :insert,在指定匹配到的行前面添加新行内容为 string
a :append,在指定或匹配到的行后面追加新行,内容为 string
d :delete,删除符合地址定界条件的的行
p :print,默认 sed 对模式空间内的处理完毕后,将输出的结果输出在标准输出,
添加 p 命令,相当于输出了原文,又一次输出了模式匹配处理后的内容。
s : 查找并替换,默认只替换每行中第一次被模式匹配到的字符串 ,如果修饰符为 g,
则为全部替换。
awk
AWK语言的基本功能是在文件或者字符串中基于指定规则浏览和抽取信息。awk抽取信息后,才能对其他文本操作。它是一个强大的文本分析工具。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
awk的适用场景
超大文件处理;
输出格式化的文本报表;
执行算数运算;
执行字符串操作等。
语法:
awk [options] 'pattern {action}' filename
options : 可选参数
-F : 指明输入时用到的字段分隔符,默认分隔符为空格或tab键
-v (var=VALUE) : 自定义变量
pattern :匹配规则
action :某些计算操作/格式化数据/流控制语句
filename:文件名
示例:
awk -F ":" '{print $1}' /etc/passwd
awk基础用法
awk '条件1 {动作1} 条件2 {动作2} ... ' 文件名
条件(pattern
一般使用关系表达式作为条件,条件符合执行对应的动作。
x > 10 判断变量x是否大于10
x >= 10 大于等于10
x <=10 小于等于
动作(Action)
格式化输出
流程控制语句
awk BEGIN关键字
默认情况下,awk 会从输入中读取一行文本,然后针对该行的数据执行程序脚本,但有时可能需要在处理数据前运行一些脚本命令,这就需要使用 BEGIN 关键字
BEGIN{commands}
功能:在执行awk命令前,先执行BEGIN对应的动作
shell脚本
脚本:
使用同一特定的描述性语言,依据一定的格式编写的可执行文件。
在windows中,大家可能常常见到。windows中的脚本以.bat结尾的。
什么是shell?
答:shell是一个命令行解释。
shell脚本?
答:shell脚本就是shell命令的有序集合。
shell脚本运行的方法
方法1:
1、建立XX.sh文件
2、赋予我们shelll文件执行权限
3、执行shell文件。
方法2:
1、建立.sh文件
2、bash + XX.sh
shell中的变量
1、我们shell变量不支持数据类型,他将任意赋值给变量的数据当作字符串识别。
2、我们定义变量的时候,不需要给钱($)。我们输出的时候需要给钱。
给变量赋值的时候,等号两边不能有空格
示例代码:
DATA=1
echo "DATA : $DATA"
变量分类
用户自定义变量
特点:变量没有类型,不需要定义,直接使用,所有的内容被解释为字符串
说明:
1、在shell中引用一个变量必须要加$,
2、在shell中,对变量赋值的时候,"="两边不能有空格
3、单引号引用的数据全部会转换为字符串
示例:
str="hello world"
my_data=$str
echo "my_data = $my_data"
示例代码:
str1="hello world"
str2="say : ${str1}"
echo $str2
cmd=`ls`
echo $cmd
mystr1='say : ${str1}'
echo $mystr1
位置变量
$0 : shell 脚本的名字
$1-$9 : 第一个参数~第九个参数,空格做为分隔符
$# : 位置参数的个数[不包括shell脚本本身]
$*:所有的位置参数
$@:所有的位置参数
$?:上一条命令的执行状态或获取shell函数的返回值
注:0代表状态为真,非0代表状态为假
$$:获得我们shell脚本的进程号
示例代码:
echo '$0' : $0
echo
#注释: 下面的| |,仅仅是作为区分,不做实际用途
echo '$1' : "|$1|"
echo '$2' : "|$2|"
echo '$3' : "|$3|"
echo '$4' : "|$4|"
echo '$5' : "|$5|"
echo '$6' : "|$6|"
echo '$7' : "|$7|"
echo '$8' : "|$8|"
echo '$9' : "|$9|"
echo '$10' : "|${10}|"
echo
echo '$*' : "|$*|"
echo '$@' : "|$@|"
echo '$#' : "|$#|"
echo '$?' : "$?"
echo '$$' : "|$$|"
# read 类似于C语言getchar(),读取用户输入的一个数据。
read
功能性语句
输入功能——read
格式: read 变量1 变量2 变量3 。
功能: 从键盘标准读入一行,并赋值给后面的变量
示例:
read var1 var2
特点:
shell编程中若是利用read函数读取参数的时候,若是输入>大于当前参数,则当前参数前面依次对齐,最后一个把所有输入之后的参数全部当作最后一个参数输入
若是输入=当前参数,正常输入
若是输入<当前参数,取输入的个数与当前参数对齐,不足者补空格。
示例代码:
#! /bin/bash
#
#
echo -n "Input var : "
read VAR1 VAR2
echo VAR1 : $VAR1
echo VAR2 : $VAR2
算数计算——expr
格式1:
expr 第一个操作数 运算符 第二个操作数
格式2:
((C语言语句))
示例:
var=`expr 1 + 3`
echo "var = $var"
((var=1 + 3))
echo "var = $var"
代码用法:
#! /bin/bash
echo -n "Input two num : "
read DAT1 DAT2
RES=`expr $DAT1 + $DAT2`
echo "$DAT1 + $DAT2 = $RES"
RES=`expr $DAT1 - $DAT2`
echo "$DAT1 - $DAT2 = $RES"
RES=`expr $DAT1 \* $DAT2`
echo "$DAT1 * $DAT2 = $RES"
RES=`expr $DAT1 / $DAT2`
echo "$DAT1 / $DAT2 = $RES"
运行结果
Input two num : 12 4
12 + 4 = 16
12 - 4 = 8
12 * 4 = 48
12 / 4 = 3
字符串
= 测试两个字符串是否相等
!= 测试两个字符串是否不相等
-z 测试两个字符串长度是否为0
-n 测试两个字符串是否不为0
示例:
test 123 = 321
echo $?
test -z 456
echo $?
STR=123
test $STR = 123
echo $?
示例代码:
# -n 代表输出不换行
echo -n "Input str1 str2 : "
read STR1 STR2
#test测试命令字符串的时候,建议被子字符串用""引用起来
test "$STR1" = "$STR2"
echo "|$STR1| = |$STR2|" : $?
test "STR1" != "STR2"
test -n "$STR1"
echo "|$STR1| len is no zeor : $?"
test -z "$STR2"
echo "|$STR2| len is zero : $?"
整数
-eq 等于
-ne 不等于
-ge 大于等于
-le 小于等于
-gt 大于
-lt 小于
示例代码:
echo -n "please input two int data : "
read VAR1 VAR2
test $VAR1 -eq $VAR2
echo "$VAR1 -eq $VAR2 : $?"
test $VAR1 -ne $VAR2
echo "$VAR1 -ne $VAR2 : $?"
test $VAR1 -gt $VAR2
echo "$VAR1 -gt $VAR2 : $?"
test $VAR1 -ge $VAR2
echo "$VAR1 -ge $VAR2 : $?"
test $VAR1 -lt $VAR2
echo "$VAR1 -lt $VAR2 : $?"
test $VAR1 -le $VAR2
echo "$VAR1 -le $VAR2 : $?"
且与或
-a 且的关系连接多个命令
-o 或的关系连接多个命令
示例代码:
echo -n "Input on number : "
read x
#(( x > 8 && x < 100))
test $x -gt 8 -a $x -lt 100
echo $?
文件
-d : 测试是否是一个目录文件
-f : 测试是否是一个普通文件
-w : 测试是否可写
-r : 测试是否可读
-x : 测试是否可执行
echo -n "please input a filename : "
read filename
#test -f $filename
[ -f $filename ]
echo "$filename : $?"
#test -d /home/linux
[ -d /home/linux ]
echo "/home/linux : $?"
-
Springboot应用的多环境打包入门11-23
-
Springboot应用的生产发布入门教程11-23
-
Python编程入门指南11-23
-
Java创业入门:从零开始的编程之旅11-23
-
Java创业入门:新手必读的Java编程与创业指南11-23
-
Java对接阿里云智能语音服务入门详解11-23
-
Java对接阿里云智能语音服务入门教程11-23
-
JAVA对接阿里云智能语音服务入门教程11-23
-
Java副业入门:初学者的简单教程11-23
-
JAVA副业入门:初学者的实战指南11-23
-
JAVA项目部署入门:新手必读指南11-23
-
Java项目部署入门:新手必看指南11-23
-
Java项目部署入门:新手必读指南11-23
-
Java项目开发入门:新手必读指南11-23
-
JAVA项目开发入门:从零开始的实用教程11-23
