人工智能学习
一文解码语言模型:语言模型的原理、实战与评估

在本文中,我们深入探讨了语言模型的内部工作机制,从基础模型到大规模的变种,并分析了各种评价指标的优缺点。文章通过代码示例、算法细节和最新研究,提供了一份全面而深入的视角,旨在帮助读者更准确地理解和评估语言模型的性能。本文适用于研究者、开发者以及对人工智能有兴趣的广大读者。
一、语言模型概述
什么是语言模型?
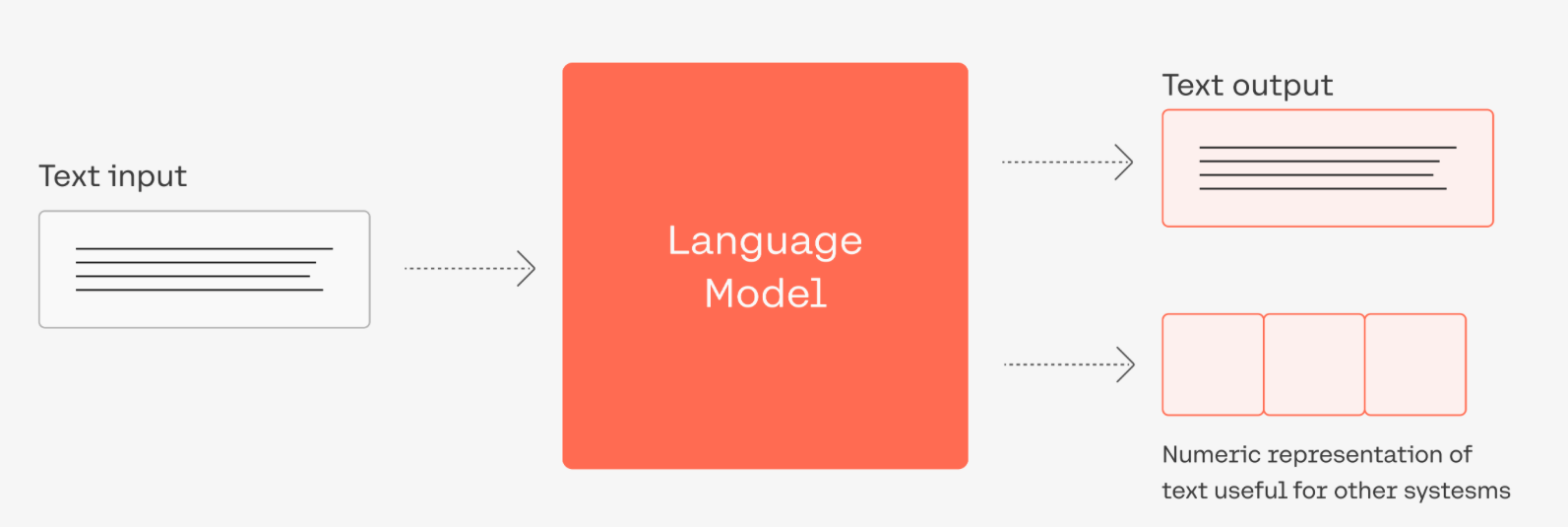
语言模型(Language Model,简称 LM)是一个用于建模自然语言(即人们日常使用的语言)的概率模型。简单来说,语言模型的任务是评估一个给定的词序列(即一个句子)在真实世界中出现的概率。这种模型在自然语言处理(NLP)的诸多应用中,如机器翻译、语音识别、文本生成等,都起到了关键性的作用。
核心概念和数学表示
语言模型试图对词序列 ( w_1, w_2, \ldots, w_m ) 的概率分布 ( P(w_1, w_2, \ldots, w_m) ) 进行建模。这里,( w_i ) 是词汇表 ( V ) 中的一个词,而 ( m ) 是句子的长度。
这种模型的一项基本要求是概率分布的归一化,即所有可能的词序列概率之和必须等于 1:
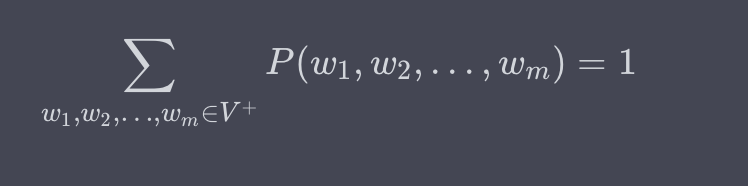
挑战:高维度和稀疏性
想象一下,如果我们有一个包含 10,000 个单词的词汇表,一个包含 20 个词的句子就有 (10,000^{20}) 种可能的组合,这个数量是一个天文数字。因此,直接建模这种高维度和稀疏性是不现实的。
链式法则与条件概率
为了解决这个问题,通常用到链式法则(Chain Rule),将联合概率分解为条件概率的乘积:
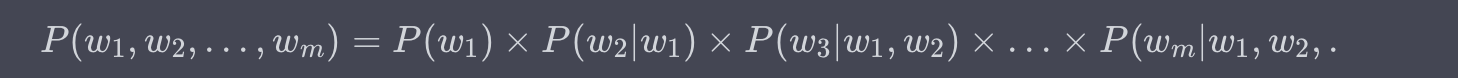
举例
假设我们有一个句子 “I love language models”,链式法则允许我们这样计算其概率:
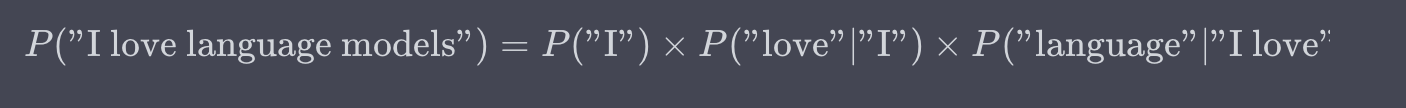
通过这种方式,模型可以更高效地估计概率。
应用场景
- 机器翻译:在生成目标语言句子时,语言模型用于评估哪个词序列更“自然”。
- 语音识别:同样的,语言模型可以用于从多个可能的转录中选择最可能的一个。
- 文本摘要:生成的摘要需要是语法正确和自然的,这也依赖于语言模型。
小结
总的来说,语言模型是自然语言处理中的基础组件,它能有效地模拟自然语言的复杂结构和生成规则。尽管面临着高维度和稀疏性的挑战,但通过各种策略和优化,如链式法则和条件概率,语言模型已经能在多个 NLP 应用中取得显著成效。
二、n元语言模型(n-gram Language Models)
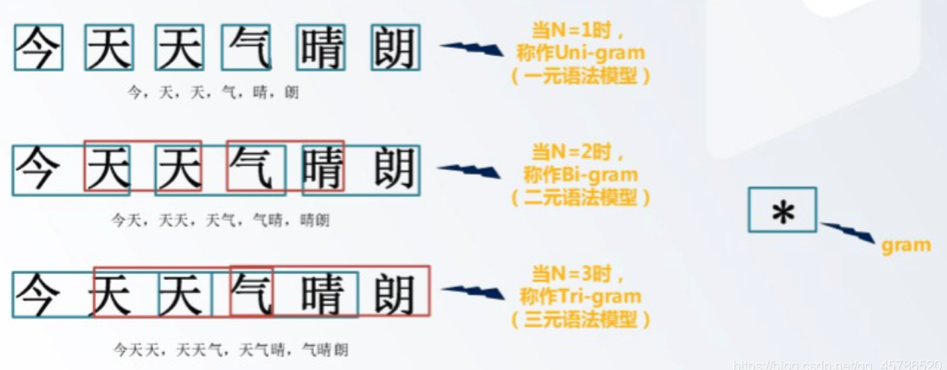
基本概念
在面对语言模型概率分布计算的高维度和稀疏性问题时,n元语言模型(n-gram models)是一种经典的解决方案。n元语言模型通过限制条件概率中考虑的历史词数来简化模型。具体来说,它只考虑最近的 ( n-1 ) 个词来预测下一个词。
数学表示
链式法则按照 n-gram 方法被近似为:
[
P(w_1, w_2, \ldots, w_m) \approx \prod_{i=1}^{m} P(w_i | w_{i-(n-1)}, w_{i-(n-2)}, \ldots, w_{i-1})
]
其中,( n ) 是模型的“阶数”(order),通常是一个小于等于 5 的整数。
代码示例:计算Bigram概率
下面是一个用Python和基础数据结构实现的Bigram(2-gram)语言模型的简单示例。
from collections import defaultdict, Counter
# 训练文本,简化版
text = "I love language models and I love coding".split()
# 初始化
bigrams = list(zip(text[:-1], text[1:]))
bigram_freq = Counter(bigrams)
unigram_freq = Counter(text)
# 计算条件概率
def bigram_probability(word1, word2):
return bigram_freq[(word1, word2)] / unigram_freq[word1]
# 输出
print("Bigram Probability of ('love', 'language'):", bigram_probability('love', 'language'))
print("Bigram Probability of ('I', 'love'):", bigram_probability('I', 'love'))
输入与输出
- 输入: 一组用空格分隔的词,代表训练文本。
- 输出: 两个特定词(如 ‘love’ 和 ‘language’)形成的Bigram条件概率。
运行上述代码,您应该看到输出如下:
Bigram Probability of ('love', 'language'): 0.5
Bigram Probability of ('I', 'love'): 1.0
优缺点
优点
- 计算简单:模型参数容易估计,只需要统计词频。
- 空间效率:相比于全序列模型,n-gram模型需要存储的参数数量少得多。
缺点
- 数据稀疏:对于低频或未出现的n-gram,模型无法给出合适的概率估计。
- 局限性:只能捕捉到局部(n-1词窗口内)的词依赖关系。
小结
n元语言模型通过局部近似来简化概率分布的计算,从而解决了一部分高维度和稀疏性的问题。然而,这也带来了新的挑战,比如如何处理稀疏数据。接下来,我们将介绍基于神经网络的语言模型,它们能够更有效地处理这些挑战。
三、神经网络语言模型(Neural Network Language Models)
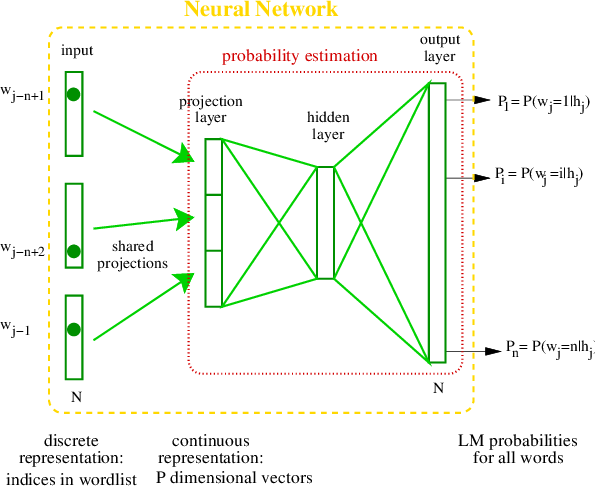
基本概念
神经网络语言模型(NNLM)试图用深度学习的方法解决传统n-gram模型中的数据稀疏和局限性问题。NNLM使用词嵌入(word embeddings)来捕捉词与词之间的语义信息,并通过神经网络来计算词的条件概率。
数学表示
对于一个给定的词序列 (w_1, w_2, \ldots, w_m),NNLM试图计算:
[
P(w_m | w_{m-(n-1)}, \ldots, w_{m-1}) = \text{Softmax}(f(w_{m-(n-1)}, \ldots, w_{m-1}; \theta))
]
其中,(f) 是一个神经网络函数,(\theta) 是模型参数,Softmax用于将输出转换为概率。
代码示例:简单的NNLM
以下是一个使用PyTorch实现的简单NNLM的代码示例。
import torch
import torch.nn as nn
import torch.optim as optim
# 数据准备
vocab = {"I": 0, "love": 1, "coding": 2, "<PAD>": 3} # 简化词汇表
data = [0, 1, 2] # "I love coding" 的词ID序列
data = torch.LongTensor(data)
# 参数设置
embedding_dim = 10
hidden_dim = 8
vocab_size = len(vocab)
# 定义模型
class SimpleNNLM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(SimpleNNLM, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.rnn = nn.RNN(embedding_dim, hidden_dim)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
x = self.embedding(x)
out, _ = self.rnn(x.view(len(x), 1, -1))
out = self.fc(out.view(len(x), -1))
return out
# 初始化模型与优化器
model = SimpleNNLM(vocab_size, embedding_dim, hidden_dim)
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 训练模型
for epoch in range(100):
model.zero_grad()
output = model(data[:-1])
loss = nn.CrossEntropyLoss()(output, data[1:])
loss.backward()
optimizer.step()
# 预测
with torch.no_grad():
prediction = model(data[:-1]).argmax(dim=1)
print("Predicted words index:", prediction.tolist())
输入与输出
- 输入: 一个词序列,每个词由其在词汇表中的索引表示。
- 输出: 下一个词的预测索引,通过模型计算得出。
运行上述代码,输出可能是:
Predicted words index: [1, 2]
这意味着模型预测"love"后面会跟"coding"。
优缺点
优点
- 捕获长距离依赖:通过循环或者自注意力机制,模型能捕获更长范围内的依赖。
- 共享表示:词嵌入可以在不同的上下文中重复使用。
缺点
- 计算复杂性:相比n-gram,NNLM具有更高的计算成本。
- 数据需求:深度模型通常需要大量标注数据进行训练。
小结
神经网络语言模型通过利用深度神经网络和词嵌入,显著提升了语言模型的表达能力和准确性。然而,这种能力的提升是以计算复杂性为代价的。在接下来的部分,我们将探讨如何通过预训练来进一步提升模型性能。
训练语言模型
自然语言处理领域基于预训练语言模型的方法逐渐成为主流。从ELMo到GPT,再到BERT和BART,预训练语言模型在多个NLP任务上表现出色。在本部分,我们将详细讨论如何训练语言模型,同时也会探究各种模型结构和训练任务。
预训练与微调
受到计算机视觉领域采用ImageNet对模型进行一次预选训练的影响,预训练+微调的范式也在NLP领域得到了广泛应用。预训练模型可以用于多个下游任务,通常只需要微调即可。
ELMo:动态词向量模型
ELMo使用双向LSTM来生成词向量,每个词的向量表示依赖于整个输入句子,因此是“动态”的。
GPT:生成式预训练模型
OpenAI的GPT采用生成式预训练方法和Transformer结构。它的特点是单向模型,只能从左到右或从右到左对文本序列建模。
BERT:双向预训练模型
BERT利用了Transformer编码器和掩码机制,能进一步挖掘上下文所带来的丰富语义。在预训练时,BERT使用了两个任务:掩码语言模型(MLM)和下一句预测(NSP)。
BART:双向和自回归Transformer
BART结合了BERT的双向上下文信息和GPT的自回归特性,适用于生成任务。预训练任务包括去噪自编码器,使用多种方式在输入文本上引入噪音。
代码示例:使用PyTorch训练一个简单的语言模型
下面的代码展示了如何使用PyTorch库来训练一个简单的RNN语言模型。
import torch
import torch.nn as nn
import torch.optim as optim
# 初始化模型
class RNNModel(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size):
super(RNNModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.RNN(embed_size, hidden_size)
self.decoder = nn.Linear(hidden_size, vocab_size)
def forward(self, x, h):
x = self.embedding(x)
out, h = self.rnn(x, h)
out = self.decoder(out)
return out, h
vocab_size = 1000
embed_size = 128
hidden_size = 256
model = RNNModel(vocab_size, embed_size, hidden_size)
# 损失和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
for epoch in range(10):
# 输入与标签
input_data = torch.randint(0, vocab_size, (5, 32)) # 随机生成(序列长度, 批量大小)的输入
target_data = torch.randint(0, vocab_size, (5, 32)) # 随机生成标签
hidden = torch.zeros(1, 32, hidden_size)
optimizer.zero_grad()
output, hidden = model(input_data, hidden)
loss = criterion(output.view(-1, vocab_size), target_data.view(-1))
loss.backward()
optimizer.step()
print(f"Epoch [{epoch+1}/10], Loss: {loss.item():.4f}")
输出
Epoch [1/10], Loss: 6.9089 Epoch [2/10], Loss: 6.5990 ...
通过这个简单的例子,你可以看到输入是一个随机整数张量,代表着词汇表索引,输出是一个概率分布,用于预测下一个词的可能性。
小结
预训练语言模型改变了NLP的许多方面。通过各种结构和预训练任务,这些模型能够捕获丰富的语义和语境信息。此外,微调预训练模型也相对简单,能迅速适应各种下游任务。
大规模语言模型
近年来,大规模预训练语言模型(Pre-trained Language Models, PLM)在自然语言处理(NLP)领域起到了革命性的作用。这一波浪潮由ELMo、GPT、BERT等模型引领,至今仍在持续。这篇文章旨在全面、深入地探究这些模型的核心原理,包括它们的结构设计、预训练任务以及如何用于下游任务。我们还将提供代码示例,以便深入了解。
ELMo:动态词嵌入的先行者
ELMo(Embeddings from Language Models)模型首次引入了上下文相关的词嵌入(contextualized word embeddings)的概念。与传统的静态词嵌入不同,动态词嵌入能根据上下文动态调整词的嵌入。
代码示例:使用ELMo进行词嵌入
# 用于ELMo词嵌入的Python代码示例 from allennlp.modules.elmo import Elmo, batch_to_ids options_file = "https://allennlp.s3.amazonaws.com/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_options.json" weight_file = "https://allennlp.s3.amazonaws.com/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5" # 创建模型 elmo = Elmo(options_file, weight_file, 1, dropout=0) # 将句子转换为字符id sentences = [["I", "ate", "an", "apple"], ["I", "ate", "a", "carrot"]] character_ids = batch_to_ids(sentences) # 计算嵌入 embeddings = elmo(character_ids) # 输出嵌入张量的形状 print(embeddings['elmo_representations'][0].shape) # Output: torch.Size([2, 4, 1024])
GPT:生成式预训练模型
GPT(Generative Pre-trained Transformer)采用生成式预训练方法,是一个基于Transformer架构的单向模型。这意味着它在处理输入文本时只能考虑文本的一侧上下文。
代码示例:使用GPT-2生成文本
# 使用GPT-2生成文本的Python代码示例
import torch
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
# 编码文本输入
input_text = "Once upon a time,"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
# 生成文本
with torch.no_grad():
output = model.generate(input_ids, max_length=50)
# 解码生成的文本
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(output_text)
# Output: Once upon a time, there was a young prince who lived in a castle...
BERT:双向编码器表示
BERT(Bidirectional Encoder Representations from Transformers)由多层Transformer编码器组成,并使用掩码机制进行预训练。
代码示例:使用BERT进行句子分类
# 使用BERT进行句子分类的Python代码示例
from transformers import BertTokenizer, BertForSequenceClassification
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
labels = torch.tensor([1]).unsqueeze(0) # 类别标签
outputs = model(**inputs, labels=labels)
loss = outputs.loss
logits = outputs.logits
print(logits)
# Output: tensor([[ 0.1595, -0.1934]])
语言模型评价方法
评价语言模型的性能是自然语言处理(NLP)领域中一项至关重要的任务。不同的评价指标和方法对于模型选择、调优以及最终的应用场景有着直接的影响。这篇文章将详细介绍几种常用的评价方法,包括困惑度(Perplexity)、BLEU 分数、ROUGE 分数等,以及如何用代码来实现这些评价。
困惑度(Perplexity)
困惑度是衡量语言模型好坏的一种常用指标,它描述了模型预测下一个词的不确定性。数学上,困惑度定义为交叉熵损失的指数。
代码示例:计算困惑度
import torch
import torch.nn.functional as F
# 假设我们有一个模型的输出logits和真实标签
logits = torch.tensor([[0.2, 0.4, 0.1, 0.3], [0.1, 0.5, 0.2, 0.2]])
labels = torch.tensor([1, 2])
# 计算交叉熵损失
loss = F.cross_entropy(logits, labels)
# 计算困惑度
perplexity = torch.exp(loss).item()
print(f'Cross Entropy Loss: {loss.item()}')
print(f'Perplexity: {perplexity}')
# Output: Cross Entropy Loss: 1.4068
# Perplexity: 4.0852
BLEU 分数
BLEU(Bilingual Evaluation Understudy)分数常用于机器翻译和文本生成任务,用于衡量生成文本与参考文本之间的相似度。
代码示例:计算BLEU分数
from nltk.translate.bleu_score import sentence_bleu
reference = [['this', 'is', 'a', 'test'], ['this', 'is' 'test']]
candidate = ['this', 'is', 'a', 'test']
score = sentence_bleu(reference, candidate)
print(f'BLEU score: {score}')
# Output: BLEU score: 1.0
ROUGE 分数
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是用于自动摘要和机器翻译等任务的一组评价指标。
代码示例:计算ROUGE分数
from rouge import Rouge
rouge = Rouge()
hypothesis = "the #### transcript is a written version of each day 's cnn student news program use this transcript to he lp students with reading comprehension and vocabulary use the weekly newsquiz to test your knowledge of storie s you saw on cnn student news"
reference = "this page includes the show transcript use the transcript to help students with reading comprehension and vocabulary at the bottom of the page , comment for a chance to be mentioned on cnn student news . you must be a teac her or a student age # # or older to request a chance to be mentioned on cnn student news ."
scores = rouge.get_scores(hypothesis, reference)
print(f'ROUGE scores: {scores}')
# Output: ROUGE scores: [{'rouge-1': {'f': 0.47, 'p': 0.8, 'r': 0.35}, 'rouge-2': {'f': 0.04, 'p': 0.09, 'r': 0.03}, 'rouge-l': {'f': 0.27, 'p': 0.6, 'r': 0.2}}]
其他评价指标
除了前文提到的困惑度(Perplexity)、BLEU 分数和 ROUGE 分数,还有其他多种评价指标用于衡量语言模型的性能。这些指标可能针对特定的任务或问题而设计,如文本分类、命名实体识别(NER)或情感分析等。本部分将介绍几种其他常用的评价指标,包括精确度(Precision)、召回率(Recall)和 F1 分数。
精确度(Precision)
精确度用于衡量模型识别为正例的样本中,有多少是真正的正例。
代码示例:计算精确度
from sklearn.metrics import precision_score
# 真实标签和预测标签
y_true = [0, 1, 1, 1, 0, 1]
y_pred = [0, 0, 1, 1, 0, 1]
# 计算精确度
precision = precision_score(y_true, y_pred)
print(f'Precision: {precision}')
# Output: Precision: 1.0
召回率(Recall)
召回率用于衡量所有真正的正例中,有多少被模型正确地识别出来。
代码示例:计算召回率
from sklearn.metrics import recall_score
# 计算召回率
recall = recall_score(y_true, y_pred)
print(f'Recall: {recall}')
# Output: Recall: 0.8
F1 分数
F1 分数是精确度和召回率的调和平均,用于同时考虑精确度和召回率。
代码示例:计算 F1 分数
from sklearn.metrics import f1_score
# 计算 F1 分数
f1 = f1_score(y_true, y_pred)
print(f'F1 Score: {f1}')
# Output: F1 Score: 0.888888888888889
AUC-ROC 曲线
AUC-ROC(Area Under the Receiver Operating Characteristic Curve)是一种用于二分类问题的性能度量,表达模型对正例和负例的分类能力。
代码示例:计算 AUC-ROC
from sklearn.metrics import roc_auc_score
# 预测概率
y_probs = [0.1, 0.4, 0.35, 0.8]
# 计算 AUC-ROC
roc_auc = roc_auc_score(y_true, y_probs)
print(f'AUC-ROC: {roc_auc}')
# Output: AUC-ROC: 0.8333333333333333
评估语言模型的性能不仅限于单一的指标。根据不同的应用场景和需求,可能需要组合多种指标以得到更全面的评估。因此,熟悉和理解这些评价指标对于构建和优化高效的语言模型至关重要。
总结
语言模型是自然语言处理(NLP)和人工智能(AI)领域中一个非常核心的组件,其在多种任务和应用场景中起到关键作用。随着深度学习技术的发展,特别是像 Transformer 这样的模型结构的出现,语言模型的能力得到了显著提升。这一进展不仅推动了基础研究,也极大地促进了产业的商业化应用。
评估语言模型的性能是一个复杂且多层次的问题。一方面,像困惑度、BLEU 分数和 ROUGE 分数这样的传统指标在某些情境下可能不足以反映模型的全面性能。另一方面,精确度、召回率、F1 分数和 AUC-ROC 等指标虽然在特定任务如文本分类、情感分析或命名实体识别(NER)等方面具有很强的针对性,但它们也不总是适用于所有场景。因此,在评估语言模型时,我们应该采取多维度、多角度的评估策略,综合不同的评价指标来获取更全面、更深入的理解。
-
探索随机贪心算法:从入门到初级应用12-25
-
树形模型进阶:从入门到初级应用教程12-25
-
搜索算法进阶:新手入门教程12-25
-
算法高级进阶:新手与初级用户指南12-25
-
随机贪心算法进阶:初学者的详细指南12-25
-
贪心算法进阶:从入门到实践12-25
-
线性模型进阶:初学者的全面指南12-25
-
朴素贪心算法教程:初学者指南12-25
-
树形模型教程:从零开始的图形建模入门指南12-25
-
搜索算法教程:初学者必备指南12-25
-
算法高级教程:入门与初级用户指南12-25
-
随机贪心算法教程:初学者指南12-25
-
贪心算法教程:入门与实践指南12-25
-
大厂算法入门指南12-25
-
广度优先搜索算法入门教程12-25
