云计算
Flink keyBy 算子源码与设计理念分析

大家好,我是大圣,很高兴又和大家见面。
今天我们来探究一下 Flink 使用 keyBy 算子的时候到底发生了什么,看完这篇文章,你会豁然开朗。
keyBy 算子基本知识
keyBy 会发生什么
专业解释
keyBy 使得相同key 的数据会进入同一个并行子任务,每一个子任务可以处理多个不同的key。这样使数据保证了有序性,并且每个子任务直接相互隔离。
我们确保了相同键的数据在逻辑上是有序的。即使在高度并行的环境中,具有相同键的所有数据都会按照其到达的顺序进行处理。这为后续的时间窗口操作、事件时间处理和状态管理提供了基础。
举例说明
假设你有一个Flink应用,该应用从一个数据源读取购物交易事件。每个交易事件都有一个userId和一个amount字段,分别表示发生交易的用户和交易金额。
现在,你希望使用Flink来计算每个用户的总交易金额。
代码可能如下:
DataStream<Transaction> transactions = ...
DataStream<Tuple2<Long, Double>> totalAmounts = transactions
.keyBy(transaction -> transaction.userId)
.sum("amount");
这里,keyBy操作基于userId字段将交易数据分组。
现在,假设我们有以下交易数据流:
User 1: $10 User 2: $5 User 1: $20 User 3: $15
同时,假设我们的Flink并行度为2。这意味着我们有两个并行任务来处理数据。
现在,考虑keyBy后的数据分发情况:
任务A处理: User 1的所有交易
任务B处理: User 2和User 3的所有交易
这是怎么做到的?
当Flink执行keyBy操作时,它使用键(这里是userId)的散列值来确定哪个子任务应该处理该事件。例如,它可能决定将userId=1的所有事件发送给任务A,而userId=2和userId=3的事件发送给任务B。
关键点是,同一个userId的所有事件都被路由到同一个任务。
现在,让我们看看任务A内部是怎么处理的:
由于每个Flink任务在单个线程内运行,所以任务A内部的处理是顺序的。
当任务A首先看到User 1: $10的交易时,它会更新User 1的总金额为$10。接下来,当它看到User 1: $20的交易时,它会更新User 1的总金额为$30。
在这个过程中,由于只有一个线程在处理数据,所以不可能出现两个线程尝试同时更新User 1的金额的情况,因此没有数据竞争。
任务B 工作流程
与任务A的处理方式相同,任务B也在其单个线程中顺序地处理每个事件。但是,任务B需要为User 2和User 3都维护状态,因为它负责这两个用户。
假设我们有以下事件流进入任务B:
User 2: $5 User 3: $15 User 2: $10 User 3: $20
任务B的处理如下:
当任务B首先看到User 2: $5的交易时,它会更新User 2的总金额为$5。
接下来,当任务B看到User 3: $15的交易时,它会为User 3创建一个新的状态(因为这是我们第一次看到User 3的交易)并设置其总金额为$15。
任务B再次看到User 2的交易,这次是User 2: $10。它将User 2的总金额更新为$15($5 + $10)。
最后,任务B看到User 3: $20的交易,它更新User 3的总金额为$35($15 + $20)。
在整个过程中,任务B为每个用户维护了独立的状态。当处理User 2的交易时,它查看并更新User 2的状态;当处理User 3的交易时,它查看并更新User 3的状态。
正如你所看到的,每次处理都是顺序的,因为它在单个线程中进行。因此,即使任务B同时处理两个用户的交易,也不会出现数据竞争,因为每个用户的状态都是独立的,并且每次只处理一个事件。
探究 keyBy 源码
举例说明
大家先看一下下面这个代码:
package com.atguigu.gmall.realtime.app.dim;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.util.concurrent.TimeUnit;
public class FlinkKeyByTest {
public static void main(String[] args) throws Exception {
// 获取流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 示例数据流
DataStream<String> sourceStream = env.fromElements("Hello", "Flink", "StreamingFileSink");
// 使用keyBy算子
KeyedStream<String, String> keyedStream = sourceStream.keyBy(new KeySelector<String, String>() {
@Override
public String getKey(String value) throws Exception {
return value; // 使用字符串本身作为键
}
});
String outputPath = "D:\\tmp\\test";
// 创建StreamingFileSink
StreamingFileSink<String> fileSink = StreamingFileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
.withMaxPartSize(1024 * 1024 * 1024)
.build()
)
.build();
// 添加sink到数据流
keyedStream.addSink(fileSink);
// 执行任务
env.execute("Flink StreamingFileSink with KeyBy to Local File System Example");
}
}
这个代码就是加载数据源,然后进行 keyBy,最后 Sink 到本地文件目录。
解释
大家可以在 org.apache.flink.streaming.runtime.partitioner.KeyGroupStreamPartitioner 这个类 的 public int selectChannel(SerializationDelegate<StreamRecord> record) 这个方法里面打个断点,然后 debug 执行上面 Flink 程序就可以了,如下图:
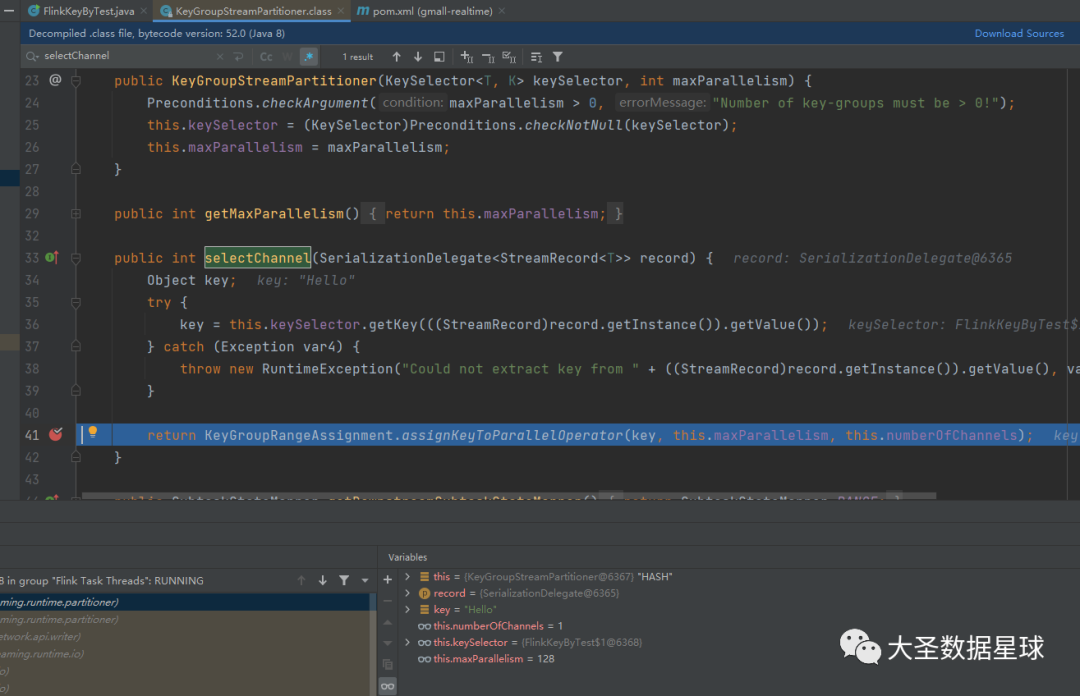
里面最重要的就是下面这两行代码:
keyGroupId = MathUtils.murmurHash(keyHash) % maxParallelism; keyGroupId * parallelism / maxParallelism;
这几个类的调用关系大家点进去多走几遍就能摸清楚,我在这里就不给大家展示出来了。
上面两行代码,第一行代码我添加了 "keyGroupId = “”,是为了让大家更好的理解,第一行代码就是用你传进来的 key,计算 key 的 keyGroupId
第二行代码就是计算你这个 key 被分配到哪个并行的子任务去处理。
看到这,大家估计想问源码我是看了,但是为什么这么设计阿?接下来,我们相信说。
源码设计理念
为什么要 keyGroupId * parallelism / maxParallelism; 这样计算
基础知识
maxParallelism
这是 Flink 作业的最大并行度。这个值定义了键组的最大数量。即使并行任务的数量在作业的生命周期中变化,这个值保持不变。
parallelism
这是当前 Flink 作业的并行度。这指的是当前有多少个任务并行执行。
keyGroupId
要查询的键组的 ID。
问题1:为什么 keyGroupId * parallelism
专业解释
首先,要理解keyGroupId * parallelism这个乘法的目的,我们需要考虑两个关键点:keyGroupId的范围和parallelism的意义。
keyGroupId的范围:
keyGroupId的范围是从0到maxParallelism-1。这意味着最大的keyGroupId是maxParallelism-1。
parallelism的意义:
parallelism表示我们想要在当前作业中运行的并行任务数。这是我们真正关心的任务数。
现在,考虑keyGroupId * parallelism这个乘法:
当我们乘以parallelism,我们实际上是在“扩展”或“拉伸”keyGroupId的范围。原来的范围是[0, maxParallelism-1],现在它被拉伸到[0, maxParallelism * parallelism-1]。
为什么这么做呢?这是因为我们想要确保在拉伸后的范围内,key groups 被均匀地分布到所有可能的并行任务上。通过乘以parallelism,我们实际上是在确保每个任务处理大约相同数量的key groups
举例理解
假设maxParallelism = 100,也就是说我们有100个可能的key groups (编号从0到99)。而当前的parallelism = 4,也就是说我们希望运行4个并行任务。
如果没有乘以parallelism:
假设我们直接使用keyGroupId / maxParallelism:
对于keyGroupId = 0到24,结果是0。
对于keyGroupId = 25到49,结果是0.25。
对于keyGroupId = 50到74,结果是0.5。
对于keyGroupId = 75到99,结果是0.75。
这些浮点数结果实际上意味着每个任务分别处理以下key groups:
任务0:0-24
任务1:没有key groups!
任务2:50-74
任务3:没有key groups!
这意味着,如果我们仅仅按照keyGroupId除以maxParallelism,我们的key groups分布会非常不均匀。
在这种情况下,只有任务0和任务2得到了key groups,而任务1和任务3一个key group都没有。这不是我们想要的结果,因为它没有有效地利用所有的并行任务。
乘以parallelism
使用公式 (keyGroupId * parallelism) / maxParallelism:
对于keyGroupId = 0到24,结果范围是0-0.96,因此所有这些key groups都分配给任务0。
对于keyGroupId = 25到49,结果范围是1-1.96,所以这些key groups都被分配给任务1。
对于keyGroupId = 50到74,结果范围是2-2.96,所以这些key groups都被分配给任务2。
对于keyGroupId = 75到99,结果范围是3-3.96,所以这些key groups都被分配给任务3。
这意味着每个任务会处理以下key groups:
任务0:0-24
任务1:25-49
任务2:50-74
任务3:75-99
通过对比,可以清晰地看到,在没有乘以parallelism的情况下,任务的负载分配是不均匀的,只有两个任务在处理数据,而其他两个任务则闲置。而当使用乘以parallelism的方式时,所有任务都被均匀地分配了key groups,从而确保了任务的均匀负载和高效率。
问题2:为什么要除以 最大并行度
专业解释
除以最大并行度(maxParallelism)是为了确保得到的结果位于期望的范围内,从0到所选并行度(parallelism) - 1之间。
Flink的并行度(parallelism)代表了任务或算子实际的并行实例数量,而最大并行度(maxParallelism)是一个上限值,它定义了系统能够处理的键组(key groups)的最大数量。
这里的关键在于理解为什么要使用maxParallelism而不是parallelism。
举例理解
maxParallelism = 100
parallelism 在开始时为 4,随后变为 8
当 parallelism = 4:
我们希望将 100 个可能的键组(key groups)均匀分布在 4 个并行任务中。
使用之前描述的算法 keyGroupId * parallelism / maxParallelism:
对于 keyGroupId 0-24:0-24 * 4 / 100 → 任务 0
对于 keyGroupId 25-49:25-49 * 4 / 100 → 任务 1
对于 keyGroupId 50-74:50-74 * 4 / 100 → 任务 2
对于 keyGroupId 75-99:75-99 * 4 / 100 → 任务 3
这样,每个任务处理大约 25 个键组。
当我们将 parallelism 改为 8:
我们希望将 100 个可能的键组均匀分布在 8 个并行任务中。
对于 keyGroupId 0-12:0-12 * 8 / 100 → 任务 0
对于 keyGroupId 13-24:13-24 * 8 / 100 → 任务 1
对于 keyGroupId 25-37:25-37 * 8 / 100 → 任务 2
对于 keyGroupId 38-49:38-49 * 8 / 100 → 任务 3
对于 keyGroupId 50-62:50-62 * 8 / 100 → 任务 4
对于 keyGroupId 63-74:63-74 * 8 / 100 → 任务 5
对于 keyGroupId 75-87:75-87 * 8 / 100 → 任务 6
对于 keyGroupId 88-99:88-99 * 8 / 100 → 任务 7
这样,每个任务处理大约 12 或 13 个键组。
状态重新分配过程
例如,考虑一个简化的例子,我们有key group 0-99。在并行度为4的设置中,任务0可能处理key group 0-24。
但是,在并行度为8的新设置中,任务0可能只处理key group 0-12,而任务1处理key group 13-24。因此,保存点中与key group 13-24相关的状态将从旧的任务0迁移到新的任务1。
总结
这篇文章我们对 keyBy 源码进行了分析,也教了大家怎么去调试 keyBy 算子的源码,大家可以去尝试一下。
另外也对 keyBy 算子的源码设计理念进行了分析,我敢说这是全网第一家可以把 keyBy 算子说的这么透彻的。
其实 keyBy 算子还有很多东西,比如如何避免数据倾斜等,后面也会说的,还有模板代码提供给大家避免数据倾斜。
-
Fluss 写入数据湖实战12-23
-
揭秘 Fluss:下一代流存储,带你走在实时分析的前沿(一)12-22
-
DevOps与平台工程的区别和联系12-20
-
从信息孤岛到数字孪生:一本面向企业的数字化转型实用指南12-20
-
手把手教你轻松部署网站12-20
-
服务器购买课程:新手入门全攻略12-20
-
动态路由表学习:新手必读指南12-20
-
服务器购买学习:新手指南与实操教程12-20
-
动态路由表教程:新手入门指南12-20
-
服务器购买教程:新手必读指南12-20
-
动态路由表实战入门教程12-20
-
服务器购买实战:新手必读指南12-20
-
新手指南:轻松掌握服务器部署12-20
-
内网穿透入门指南:轻松实现远程访问12-20
-
网站部署入门教程12-20
