Python教程
词!自然语言处理之词全解和Python实战!

本文全面探讨了词在自然语言处理(NLP)中的多维角色。从词的基础概念、形态和词性,到词语处理技术如规范化、切分和词性还原,文章深入解析了每一个环节的技术细节和应用背景。特别关注了词在多语言环境和具体NLP任务,如文本分类和机器翻译中的应用。文章通过Python和PyTorch代码示例,展示了如何在实际应用中实施这些技术。
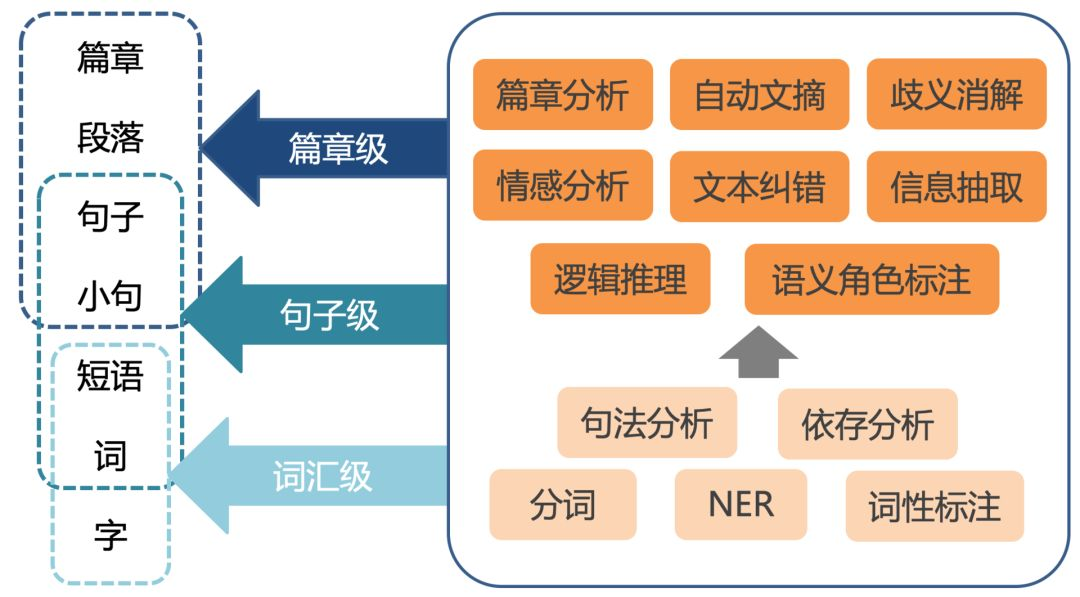
一、为什么我们需要了解“词”的各个方面
在自然语言处理(NLP,Natural Language Processing)领域,“词”构成了语言的基础单位。与此同时,它们也是构建高级语义和语法结构的基石。在解决各种NLP问题,如机器翻译、情感分析、问答系统等方面,对“词”的全面了解不仅有助于我们设计更高效的算法,还能加深我们对语言本质的认识。
词是语言的基础单位
在任何语言中,词都是最基础的组成单位。就像建筑物是由砖块堆砌而成的,自然语言也是由词组合而成的。一个词能携带多种信息,包括但不限于它的意义(语义)、它在句子中的功能(语法)以及它与其他词的关系(语境)。因此,对“词”的研究从根本上影响了我们对更高层次自然语言处理任务的理解和处理能力。
词的多维特性
词不仅具有表面形态(如拼写和发音),还有其词性、语境和多种可能的含义。例如,词性标注能告诉我们一个词是名词、动词还是形容词,这有助于我们理解它在句子或段落中的作用。词的这些多维特性使得它在自然语言处理中具有多样的应用场景和挑战。
词在NLP应用中的关键作用
-
文本分类和情感分析: 通过分析词的频率、顺序和词性,我们可以对文本进行分类,或者确定文本的情感倾向。
-
搜索引擎: 在信息检索中,词的重要性是显而易见的。词项权重(例如TF-IDF)和词的语义关联(例如Word2Vec)是搜索引擎排序算法的关键要素。
-
机器翻译: 理解词在不同语言中的对应关系和语义差异是实现高质量机器翻译的前提。
-
语音识别和生成: 词在语音识别和文本到语音(TTS)系统中也扮演着关键角色。准确地识别和生成词是这些系统成功的关键。
二、词的基础

在深入研究自然语言处理的高级应用之前,了解“词”的基础知识是至关重要的。这一部分将侧重于词的定义、分类、形态和词性。
什么是词?
定义
在语言学中,对“词”的定义可以多种多样。但在自然语言处理(NLP)的环境下,我们通常将词定义为最小的独立意义单位。它可以是单独出现的,也可以是与其他词共同出现以构成更复杂的意义。在编程和算法处理中,一个词通常由一系列字符组成,这些字符之间以空格或特定的分隔符分隔。
分类
-
实词与虚词
- 实词:具有实际意义,如名词、动词、形容词。
- 虚词:主要用于连接和修饰实词,如介词、连词。
-
单词与复合词
- 单词:由单一的词根或词干构成。
- 复合词:由两个或多个词根或词干组合而成,如“toothbrush”。
-
开放类与封闭类
- 开放类:新词容易添加进来,如名词、动词。
- 封闭类:固定不变,新词很难加入,如介词、代词。
词的形态
词根、词干和词缀
-
词根(Root): 是词的核心部分,携带了词的主要意义。
- 例如,在“unhappiness”中,“happy”是词根。
-
词干(Stem): 由词根加上必要的词缀组成,是词的基础形态。
- 例如,在“running”中,“runn”是词干。
-
词缀(Affixes): 包括前缀、后缀、词中缀和词尾缀,用于改变词的意义或词性。
- 前缀(Prefix):出现在词根前,如“un-”在“unhappy”。
- 后缀(Suffix):出现在词根后,如“-ing”在“running”。
形态生成
词的形态通过规则和不规则的变化进行生成。规则变化通常通过添加词缀来实现,而不规则变化通常需要查找词形变化的数据表。
词的词性
词性是描述词在句子中充当的语法角色的分类,这是自然语言处理中非常重要的一环。
- 名词(Noun): 用于表示人、地点、事物或概念。
- 动词(Verb): 表示动作或状态。
- 形容词(Adjective): 用于描述名词。
- 副词(Adverb): 用于修饰动词、形容词或其他副词。
- 代词(Pronoun): 用于代替名词。
- 介词(Preposition): 用于表示名词与其他词之间的关系。
- 连词(Conjunction): 用于连接词、短语或子句。
- 感叹词(Interjection): 用于表达情感或反应。
三、词语处理技术

在掌握了词的基础知识之后,我们将转向一些具体的词语处理技术。这些技术为词在自然语言处理(NLP)中的更高级应用提供了必要的工具和方法。
词语规范化
定义
词语规范化是将不同形态或者拼写的词语转换为其标准形式的过程。这一步是文本预处理中非常重要的一环。
方法
- 转为小写: 最基础的规范化步骤,特别是对于大小写不敏感的应用。
- 去除标点和特殊字符: 有助于减少词汇表大小和提高模型的泛化能力。
词语切分(Tokenization)
定义
词语切分是将文本分割成词、短语、符号或其他有意义的元素(称为标记)的过程。
方法
- 空格切分: 最简单的切分方法,但可能无法正确处理像“New York”这样的复合词。
- 正则表达式: 更为复杂但灵活的切分方式。
- 基于词典的切分: 使用预定义的词典来查找和切分词语。
词性还原(Lemmatization)与词干提取(Stemming)
词性还原
- 定义: 将一个词转换为其词典形式。
- 例子: “running” -> “run”,“mice” -> “mouse”
词干提取
- 定义: 剪切掉词的词缀以得到词干。
- 例子: “running” -> “run”,“flies” -> “fli”
中文分词
- 基于字典的方法: 如最大匹配算法。
- 基于统计的方法: 如隐马尔科夫模型(HMM)。
- 基于深度学习的方法: 如Bi-LSTM。
英文分词
- 基于规则的方法: 如使用正则表达式。
- 基于统计的方法: 如使用n-gram模型。
- 基于深度学习的方法: 如Transformer模型。
词性标注(Part-of-Speech Tagging)
定义
词性标注是为每个词分配一个词性标签的过程。
方法
- 基于规则的方法: 如决策树。
- 基于统计的方法: 如条件随机场(CRF)。
- 基于深度学习的方法: 如BERT。
四、多语言词处理

随着全球化和多文化交流的加速,多语言词处理在自然语言处理(NLP)领域的重要性日益增加。不同语言有各自独特的语法结构、词汇和文化背景,因此在多语言环境中进行有效的词处理具有其特殊的挑战和需求。
语言模型适应性
Transfer Learning
迁移学习是一种让一个在特定任务上训练过的模型适应其他相关任务的技术。这在处理低资源语言时尤为重要。
Multilingual BERT
多语言BERT(mBERT)是一个多任务可适应多种语言的预训练模型。它在多语言词处理任务中,如多语言词性标注、命名实体识别(NER)等方面表现出色。
语言特异性
形态丰富性
像芬兰语和土耳其语这样的形态丰富的语言,单一的词可以表达一个完整的句子在其他语言中需要的信息。这需要更为复杂的形态分析算法。
字符集和编码
不同的语言可能使用不同的字符集,例如拉丁字母、汉字、阿拉伯字母等。正确的字符编码和解码(如UTF-8,UTF-16)是多语言处理中的基础。
多语言词向量
FastText
FastText 是一种生成词向量的模型,它考虑了词的内部结构,因此更适用于形态丰富的语言。
Byte Pair Encoding (BPE)
字节对编码(BPE)是一种用于处理多语言和未登录词的词分割算法。
代码示例:多语言词性标注
以下是使用 Python 和 PyTorch 利用 mBERT 进行多语言词性标注的示例代码。
from transformers import BertTokenizer, BertForTokenClassification
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
model = BertForTokenClassification.from_pretrained('bert-base-multilingual-cased')
inputs = tokenizer("Hola mundo", return_tensors="pt")
labels = torch.tensor([1] * inputs["input_ids"].size(1)).unsqueeze(0)
outputs = model(**inputs, labels=labels)
loss = outputs.loss
logits = outputs.logits
# 输出词性标注结果
print(logits)
注释:这个简单的示例演示了如何使用mBERT进行多语言词性标注。
五、词在自然语言处理中的应用
在自然语言处理(NLP)中,词是信息的基础单位。此部分将详细介绍词在NLP中的各种应用,特别是词嵌入(Word Embeddings)的重要性和用途。
5.1 词嵌入
定义和重要性
词嵌入是用来将文本中的词映射为实数向量的技术。词嵌入不仅捕捉词的语义信息,还能捕捉到词与词之间的相似性和多样性(例如,同义词或反义词)。
算法和模型
- Word2Vec: 通过预测词的上下文,或使用上下文预测词来训练嵌入。
- GloVe: 利用全局词频统计信息来生成嵌入。
- FastText: 基于Word2Vec,但考虑了词内字符的信息。
代码示例:使用Word2Vec
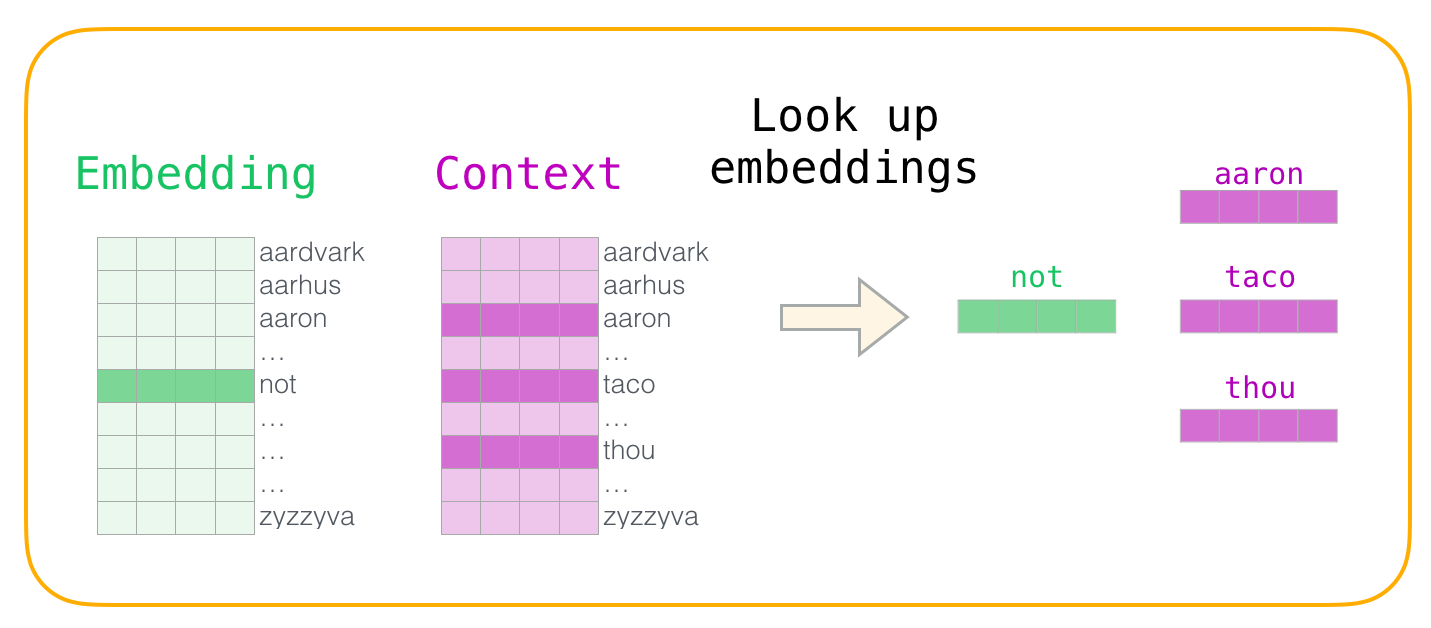
下面的例子使用Python和PyTorch实现了一个简单的Word2Vec模型。
import torch
import torch.nn as nn
import torch.optim as optim
# 定义模型
class Word2Vec(nn.Module):
def __init__(self, vocab_size, embed_size):
super(Word2Vec, self).__init__()
self.in_embed = nn.Embedding(vocab_size, embed_size)
self.out_embed = nn.Embedding(vocab_size, embed_size)
def forward(self, target, context):
in_embeds = self.in_embed(target)
out_embeds = self.out_embed(context)
scores = torch.matmul(in_embeds, torch.t(out_embeds))
return scores
# 词汇表大小和嵌入维度
vocab_size = 5000
embed_size = 300
# 初始化模型、损失和优化器
model = Word2Vec(vocab_size, embed_size)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 假设target和context已经准备好
target = torch.tensor([1, 2, 3]) # 目标词ID
context = torch.tensor([2, 3, 4]) # 上下文词ID
# 前向传播和损失计算
scores = model(target, context)
loss = criterion(scores, context)
# 反向传播和优化
loss.backward()
optimizer.step()
# 输出嵌入向量
print(model.in_embed.weight)
注释:
- 输入:
target和context是目标词和上下文词的整数ID。 - 输出:
scores是目标词和上下文词之间的相似性得分。
5.2 词在文本分类中的应用
文本分类是自然语言处理中的一个核心任务,它涉及将文本文档分配给预定义的类别或标签。在这一节中,我们将重点讨论如何使用词(特别是词嵌入)来实现有效的文本分类。
任务解析
在文本分类中,每个文档(或句子、段落等)都被转换成一个特征向量,然后用这个特征向量作为机器学习模型的输入。这里,词嵌入起着至关重要的作用:它们将文本中的每个词转换为一个实数向量,捕捉其语义信息。
代码示例:使用LSTM进行文本分类
下面是一个使用PyTorch和LSTM(长短时记忆网络)进行文本分类的简单例子:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义LSTM模型
class TextClassifier(nn.Module):
def __init__(self, vocab_size, embed_size, num_classes):
super(TextClassifier, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, 128)
self.fc = nn.Linear(128, num_classes)
def forward(self, x):
x = self.embedding(x)
lstm_out, _ = self.lstm(x)
lstm_out = lstm_out[:, -1, :]
output = self.fc(lstm_out)
return output
# 初始化模型、损失函数和优化器
vocab_size = 5000
embed_size = 100
num_classes = 5
model = TextClassifier(vocab_size, embed_size, num_classes)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# 假设输入数据和标签已经准备好
input_data = torch.LongTensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 文本数据(词ID)
labels = torch.LongTensor([0, 1, 2]) # 类别标签
# 前向传播
output = model(input_data)
# 计算损失
loss = criterion(output, labels)
# 反向传播和优化
loss.backward()
optimizer.step()
# 输出结果
print("Output Class Probabilities:", torch.softmax(output, dim=1))
注释:
- 输入:
input_data是文本数据,每行代表一个文档,由词ID构成。 - 输出:
output是每个文档对应各个类别的预测得分。
5.3 词在机器翻译中的应用
机器翻译是一种将一种自然语言(源语言)的文本自动翻译为另一种自然语言(目标语言)的技术。在这一节中,我们将重点介绍序列到序列(Seq2Seq)模型在机器翻译中的应用,并讨论词如何在这一过程中发挥作用。
任务解析
在机器翻译任务中,输入是源语言的一段文本(通常为一句话或一个短语),输出是目标语言的等效文本。这里,词嵌入用于捕获源语言和目标语言中词的语义信息,并作为序列到序列模型的输入。
代码示例:使用Seq2Seq模型进行机器翻译
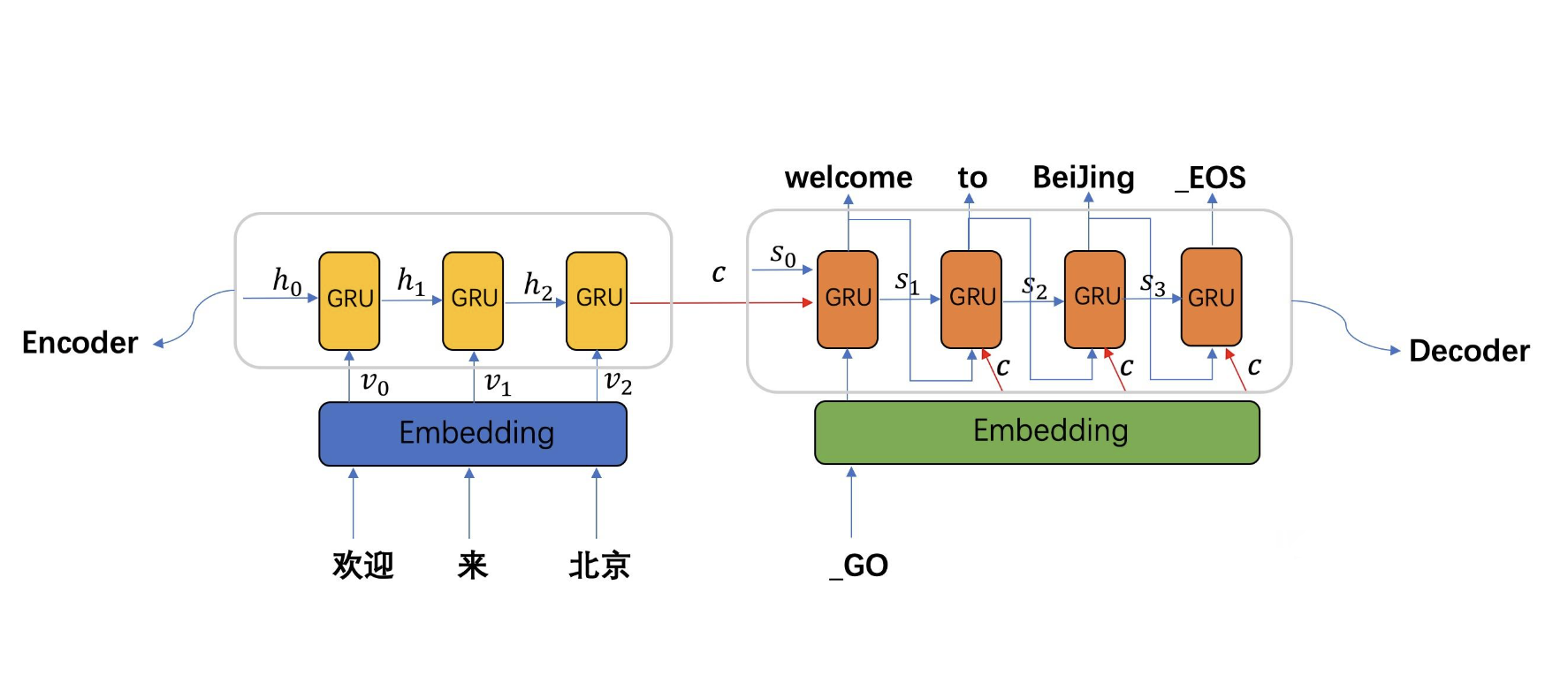
下面是一个使用PyTorch实现的简单Seq2Seq模型示例:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义Seq2Seq模型
class Seq2Seq(nn.Module):
def __init__(self, input_vocab_size, output_vocab_size, embed_size):
super(Seq2Seq, self).__init__()
self.encoder = nn.Embedding(input_vocab_size, embed_size)
self.decoder = nn.Embedding(output_vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size, 128)
self.fc = nn.Linear(128, output_vocab_size)
def forward(self, src, trg):
src_embed = self.encoder(src)
trg_embed = self.decoder(trg)
encoder_output, _ = self.rnn(src_embed)
decoder_output, _ = self.rnn(trg_embed)
output = self.fc(decoder_output)
return output
# 初始化模型、损失函数和优化器
input_vocab_size = 3000
output_vocab_size = 3000
embed_size = 100
model = Seq2Seq(input_vocab_size, output_vocab_size, embed_size)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# 假设输入(源语言)和输出(目标语言)数据已经准备好
src_data = torch.LongTensor([[1, 2, 3], [4, 5, 6]]) # 源语言文本(词ID)
trg_data = torch.LongTensor([[7, 8, 9], [10, 11, 12]]) # 目标语言文本(词ID)
# 前向传播
output = model(src_data, trg_data)
# 计算损失
loss = criterion(output.view(-1, output_vocab_size), trg_data.view(-1))
# 反向传播和优化
loss.backward()
optimizer.step()
# 输出结果
print("Output Translated IDs:", torch.argmax(output, dim=2))
注释:
- 输入:
src_data是源语言的文本数据,每行代表一个文档,由词ID构成。 - 输出:
output是目标语言文本的预测得分。
六、总结
词是自然语言处理的基本构建块,但其处理绝非单一或直观。从词形态到词嵌入,每一个步骤都有其复杂性和多样性,这直接影响了下游任务如文本分类、情感分析和机器翻译的性能。词的正确处理,包括但不限于词性标注、词干提取、和词嵌入,不仅增强了模型的语义理解能力,还有助于缓解数据稀疏性问题和提高模型泛化。特别是在使用深度学习模型如Seq2Seq和Transformer时,对词的精细处理更能发挥关键作用,例如在机器翻译任务中通过注意力机制准确地对齐源语言和目标语言的词。因此,对词的全维度理解和处理是提高NLP应用性能的关键步骤。
-
Python编程基础详解11-24
-
Python编程基础教程11-21
-
Python编程基础与实践11-20
-
Python编程基础与高级应用11-20
-
Python 基础编程教程11-19
-
Python基础入门教程11-19
-
在FastAPI项目中添加一个生产级别的数据库——本地环境搭建指南11-17
-
`PyMuPDF4LLM`:提取PDF数据的神器11-16
-
四种数据科学Web界面框架快速对比:Rio、Reflex、Streamlit和Plotly Dash11-16
-
获取参数学习:Python编程入门教程11-14
-
Python编程基础入门11-14
-
Python编程入门指南11-14
-
Python基础教程11-13
-
Python编程基础指南11-12
-
Python基础编程教程11-12
