消息队列MQ
Flink Sink Kafka 和 Flink 端到端一致性建议

Flink Sink Kafka 和 Flink 端到端一致性建议
大家好,好久不见,我是大圣!
今天,我们来聊一聊 Apache Flink 在与 Kafka 对接时的两个常见问题。
首先,咱们要一起探讨下如何灵活而高效地将数据 sink 到 Kafka 的各个分区中。有没有什么实用技巧能让这个环节更加顺畅呢?
其次,我们将针对 Flink Sink Kafka 端到端一致性问题展开讨论。如何确保数据的准确传输,避免丢失或重复,是我们今天要共同解答的另一个问题。
Flink Sink Kafka 分区问题
当我们使用 Flink Sink Kafka 的时候,如果没有指定进入 Kafka 的 key 的话,你觉得数据会根据什么样的策略选择分区呢?
我会说它会按照 round-robin 策略将数据均匀分配到各个 partition 中,其实我一开始也是这样认为的,毕竟我们背八股文的时候都是这样背的。但是在 Flink 1.13 版本 kafka 的连接器里面不是这样的。
先说结论:当你没有指定 key 的时候,它会尝试维护“粘性”分区选择,这意味着它会尽可能长时间地将消息发送到同一个分区,直到触发某些条件(例如分区负载不均衡或 leader 分区更改)它才会选择一个新的分区。
下面对这部分源码进行简单的分析,这里面涉及到 FlinkKafkaProducer、KafkaProducer、DefaultPartitioner 这三个类:
1.FlinkKafkaProducer
- 在Flink应用中,FlinkKafkaProducer是一个Sink函数,它用来将流中的元素发送到Kafka主题。
- FlinkKafkaProducer通过内部使用Kafka的Java API创建一个KafkaProducer实例来实现此目的。
2.KafkaProducer
- KafkaProducer是Kafka Java客户端库的一部分,它负责将消息发送到Kafka broker。
- 在发送消息时,它会使用Partitioner来确定将消息发送到哪个分区。
- 默认情况下,它使用DefaultPartitioner,但你也可以提供自定义的Partitioner。
3.DefaultPartitioner
- DefaultPartitioner是一个类,它负责确定消息应该发送到哪个Kafka分区。
- 如果消息具有键,它将根据键的哈希值和分区的数量来确定分区。如果消息没有键,它将尝试均匀地将消息分配到各个分区(使用sticky partitioning策略来避免频繁的分区切换)。
下面我们来看看 DefaultPartitioner 类里面进行数据分区逻辑的 partition 方法: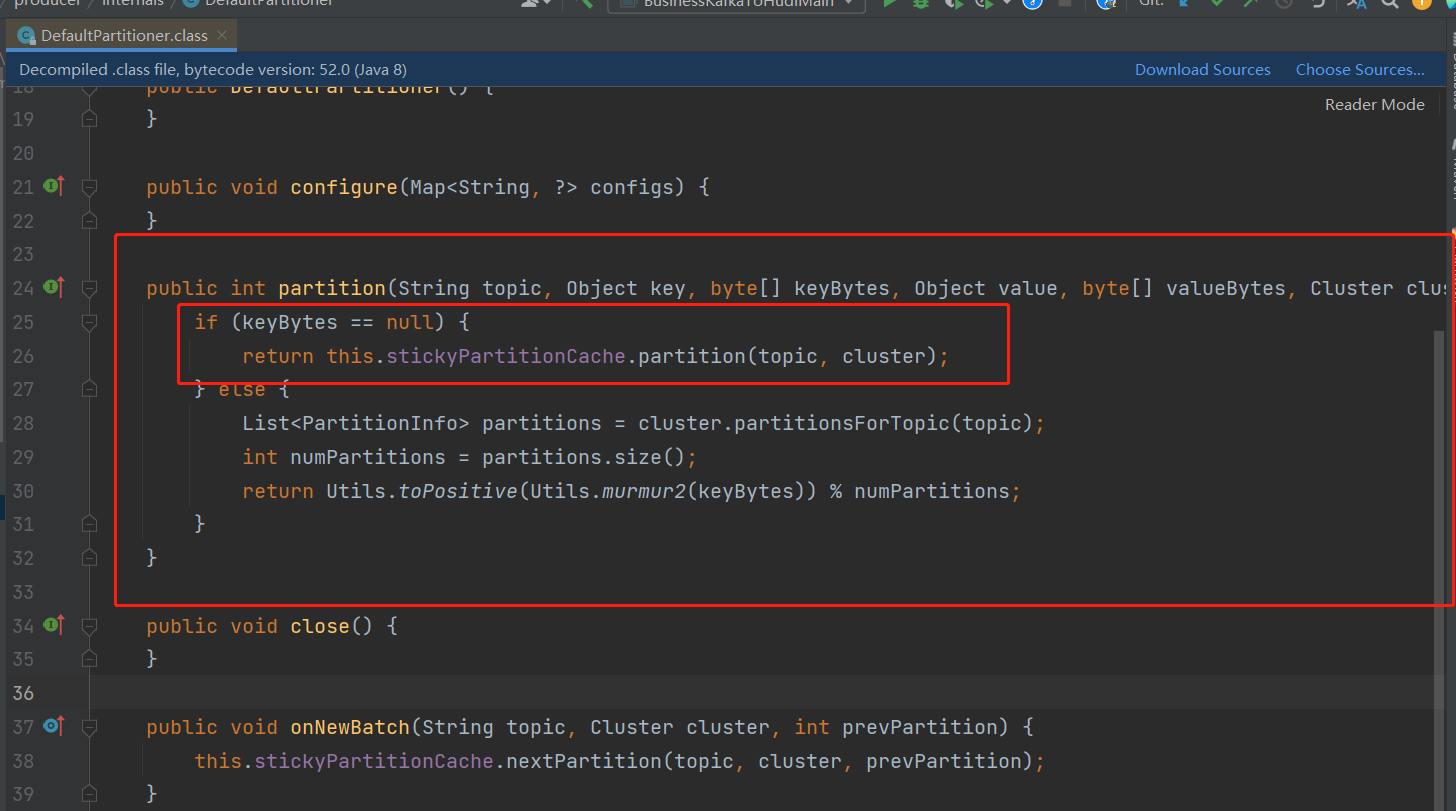
我们可以从源码里面清楚的看到,当我们没有指定 key 的时候,它不是采用的round-robin 策略,而是会尝试维护“粘性”分区选择。
其实这种"sticky"策略是新于 Kafka 2.4.0 版本的特性。在此之前,确实是用轮询策略来在没有指定 key 的情况下分配分区的
Flink 端到端一致性问题
说到 Flink 端到端一致性问题,首先大家要知道什么是 Flink 的端到端一致性。通俗的理解是指在一个分布式流处理系统中,从数据源(source)到数据结果(sink),整个处理过程能够保证数据的完整性和准确性,即使在面对各种故障(如节点宕机等)的情况下也是如此。
我举一个Flink 消费Kafka,然后进行业务逻辑处理过后再Sink 到 Kafka 的例子。
如果要实现 这个 端到端的一致性我们需要在代码层面怎么设置呢?
源端(Kafka Source)
你需要确保 Kafka Source 支持可重置数据源。Flink Kafka 消费者可以确保这一点,因为它能够从上次提交的偏移量处重新开始读取数据。你可以像这样创建 Kafka 消费者:
Properties consumerProperties = new Properties();
consumerProperties.setProperty("bootstrap.servers", "localhost:9092");
consumerProperties.setProperty("group.id", "test");
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<>(
"input_topic",
new SimpleStringSchema(),
consumerProperties
);
Flink 内部
你需要开启 Flink 的检查点(Checkpointing)并配置为精准一次语义(Exactly-Once)。这可以通过在你的 Flink 环境中调用以下方法实现:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.enableCheckpointing(10000); // 例如,设置检查点时间间隔为 10000 毫秒 env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
汇端(Kafka Sink)
在配置 Kafka Sink 的时候,你需要设置语义为 EXACTLY_ONCE,这可以通过在创建 FlinkKafkaProducer 时传递适当的参数实现:
FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>(
"output_topic", // target topic
new KafkaSerializationSchema<String>() {
@Override
public ProducerRecord<byte[], byte[]> serialize(String element, @Nullable Long timestamp) {
return new ProducerRecord<>("output_topic", element.getBytes(StandardCharsets.UTF_8));
}
},
producerProperties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE
);
这里千万要注意,当你创建 FlinkKafkaProducer 对象的时候一定要显式的声明 FlinkKafkaProducer.Semantic.EXACTLY_ONCE 这个参数。
因为如果你不显式指定上面那个参数的话,它这个参数的默认值是 AT_LEAST_ONCE,这样在 Sink 端就实现不了精准一次性,从而实现不了端到端一致性。
但是 flink sink hdfs、mysql 是不需要 sink 的时候设置精准一致性,因为 flink 内部已经实现了 flink sink mysql、hdfs 的sink 端精准一次性。
以上就是今天说的 Flink Sink Kafka 和 Flink 端到端一致性的一些平时容易被忽略的点,希望对大家可以有帮助,有不同意见的,欢迎大家加我微信,大家一起讨论。
-
MQ-2烟雾传感器详解12-21
-
Kafka消息丢失资料:新手入门指南12-09
-
Kafka消息队列入门:轻松掌握Kafka消息队列12-07
-
Kafka消息队列入门:轻松掌握消息队列基础知识12-07
-
Kafka重复消费入门:轻松掌握Kafka消费的注意事项与实践12-07
-
Kafka重复消费入门教程12-07
-
RabbitMQ入门详解:新手必看的简单教程12-07
-
RabbitMQ入门:新手必读教程12-07
-
Kafka解耦学习入门教程12-06
-
Kafka入门教程:快速上手指南12-06
-
Kafka解耦入门教程:实现系统间高效通信12-06
-
Kafka消息队列入门教程:从零开始轻松掌握12-06
-
RabbitMQ入门指南:轻松搭建与使用教程12-06
-
知乎启用AutoMQ替换Kafka,开辟成本优化与运维提效新纪元12-02
-
海外开发者为 AutoMQ 写的精品介绍,太干了!11-27
