人工智能学习
【2023年】第35天 生成对抗网络 2(TF-GAN,Generative Adversarial Networks)

1. Introduction 简介
Generative adversarial networks (GANs) are an exciting recent innovation in machine learning.
生成式对抗网络(GANs)是机器学习领域最近一项令人兴奋的创新。
GANs are generative models: they create new data instances that resemble your training data.
GAN 是一种生成模型:它能创建与训练数据相似的新数据实例。
For example, GANs can create images that look like photographs of human faces, even though the faces don’t belong to any real person.
例如,GAN 可以创建看起来像人脸照片的图像,尽管这些人脸并不属于任何真实的人。
These images were created by a GAN:
这些图像由 GAN 生成:
Figure 1: Images generated by a GAN created by NVIDIA.
图 1:英伟达创建的 GAN 生成的图像。
GANs achieve this level of realism by pairing a generator, which learns to produce the target output, with a discriminator, which learns to distinguish true data from the output of the generator.
GAN 通过将学习生成目标输出的生成器与学习从生成器输出中区分真实数据的判别器配对,来达到这种逼真度。
The generator tries to fool the discriminator, and the discriminator tries to keep from being fooled.
发生器试图欺骗判别器,判别器则试图避免被欺骗。
Course Learning Objectives
- Understand the difference between generative and discriminative models.
了解生成模型和判别模型的区别。 - Identify problems that GANs can solve.
确定 GAN 可以解决的问题。 - Understand the roles of the generator and discriminator in a GAN system.
了解生成器和鉴别器在 GAN 系统中的作用。 - Understand the advantages and disadvantages of common GAN loss functions.
了解常见 GAN 损失函数的优缺点。 - Identify possible solutions to common problems with GAN training.
找出 GAN 训练常见问题的可能解决方案。 - Use the TF GAN library to make a GAN.
使用 TF GAN 库创建 GAN。
2. Generative Models
(1)Background: What is a Generative Model?
背景介绍: 什么是生成模型?
What does “generative” mean in the name “Generative Adversarial Network”?
生成对抗网络 "中的 "生成 "是什么意思?
“Generative” describes a class of statistical models that contrasts with discriminative models.
"生成 "描述的是一类统计模型,与判别模型形成对比。
Informally: 非正式地
- Generative models can generate new data instances.
生成模型可以生成新的数据实例。 - Discriminative models discriminate between different kinds of data instances.
判别模型对不同类型的数据实例进行判别。
A generative model could generate new photos of animals that look like real animals, while a discriminative model could tell a dog from a cat. GANs are just one kind of generative model.
生成模型可以生成与真实动物相似的新动物照片,而判别模型则可以分辨出狗和猫。GAN 只是生成模型的一种。
More formally, given a set of data instances X and a set of labels Y:
更正式地说,给定一组数据实例 X 和一组标签 Y:
- Generative models capture the joint probability p(X, Y), or just p(X) if there are no labels.
生成模型捕捉联合概率 p(X,Y),如果没有标签,则只捕捉 p(X)。 - Discriminative models capture the conditional probability p(Y | X).
判别模型捕捉条件概率 p(Y | X)。
A generative model includes the distribution of the data itself, and tells you how likely a given example is.
生成模型包括数据本身的分布,并告诉你给定例子的可能性有多大。
For example, models that predict the next word in a sequence are typically generative models (usually much simpler than GANs) because they can assign a probability to a sequence of words.
例如,预测序列中下一个单词的模型通常是生成模型(通常比 GAN 简单得多),因为它们可以为单词序列分配概率。
A discriminative model ignores the question of whether a given instance is likely, and just tells you how likely a label is to apply to the instance.
判别模型忽略了给定实例是否可能的问题,而只是告诉你一个标签适用于该实例的可能性有多大。
Note that this is a very general definition. There are many kinds of generative model. GANs are just one kind of generative model.
请注意,这是一个非常笼统的定义。生成模型有很多种。GAN 只是生成模型的一种。
(2)Modeling Probabilities 概率建模
Neither kind of model has to return a number representing a probability. You can model the distribution of data by imitating that distribution.
这两种模型都不必返回一个代表概率的数字。您可以通过模仿数据的分布来建立模型。
For example, a discriminative classifier like a decision tree can label an instance without assigning a probability to that label. Such a classifier would still be a model because the distribution of all predicted labels would model the real distribution of labels in the data.
例如,像决策树这样的判别分类器可以给一个实例贴标签,而不给该标签分配概率。这样的分类器仍然是一个模型,因为所有预测标签的分布将模拟数据中标签的真实分布。
Similarly, a generative model can model a distribution by producing convincing “fake” data that looks like it’s drawn from that distribution.
同样,生成模型可以通过生成令人信服的 "假 "数据来模拟分布,这些数据看起来就像是从分布中提取的。
(3)Generative Models Are Hard 生成模型很难
Generative models tackle a more difficult task than analogous discriminative models. Generative models have to model more.
与类似的判别模型相比,生成模型的任务更加艰巨。生成模型必须建立更多的模型。
A generative model for images might capture correlations like “things that look like boats are probably going to appear near things that look like water” and “eyes are unlikely to appear on foreheads.” These are very complicated distributions.
图像生成模型可能会捕捉到 "看起来像船的东西可能会出现在看起来像水的东西附近 "和 "眼睛不太可能出现在额头上 "这样的相关性。这些分布非常复杂。
In contrast, a discriminative model might learn the difference between “sailboat” or “not sailboat” by just looking for a few tell-tale patterns. It could ignore many of the correlations that the generative model must get right.
与此相反,判别模型可能只需寻找一些蛛丝马迹,就能学会 "帆船 "与 "非帆船 "之间的区别。它可以忽略生成模型必须正确处理的许多相关性。
Discriminative models try to draw boundaries in the data space, while generative models try to model how data is placed throughout the space. For example, the following diagram shows discriminative and generative models of handwritten digits:
判别模型试图在数据空间中划定边界,而生成模型则试图模拟数据在整个空间中的位置。例如,下图显示了手写数字的判别模型和生成模型: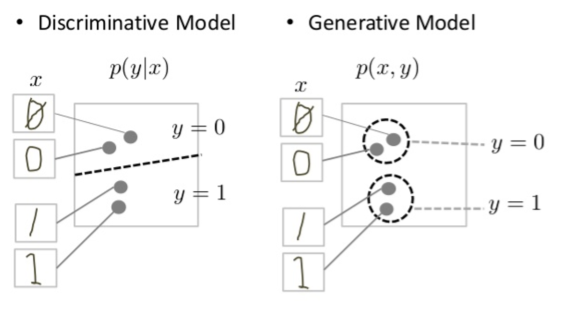
Figure 2: Discriminative and generative models of handwritten digits.
手写数字的判别模型和生成模型。
The discriminative model tries to tell the difference between handwritten 0’s and 1’s by drawing a line in the data space. If it gets the line right, it can distinguish 0’s from 1’s without ever having to model exactly where the instances are placed in the data space on either side of the line.
判别模型试图通过在数据空间中画一条线来区分手写的 "0 "和 “1”。如果这条线画对了,它就能区分 0 和 1,而无需对数据空间中位于这条线两侧的实例进行精确建模。
In contrast, the generative model tries to produce convincing 1’s and 0’s by generating digits that fall close to their real counterparts in the data space. It has to model the distribution throughout the data space.
相比之下,生成模型则试图通过生成与数据空间中真实对应数字相近的数字来生成令人信服的 1 和 0。它必须对整个数据空间的分布进行建模。
GANs offer an effective way to train such rich models to resemble a real distribution. To understand how they work we’ll need to understand the basic structure of a GAN.
GAN 提供了一种有效的方法来训练这种丰富的模型,使其类似于真实的分布。要了解它们的工作原理,我们需要了解 GAN 的基本结构。
3. Overview of GAN Structure
生成式对抗网络(GAN)由两部分组成:
- The generator learns to generate plausible data. The generated instances become negative training examples for the discriminator.
生成器学习生成合理的数据。生成的实例会成为判别器的负性训练示例。 - The discriminator learns to distinguish the generator’s fake data from real data. The discriminator penalizes the generator for producing implausible results.
判别器会学习区分生成器的虚假数据与真实数据。判别器通过生成可观测的结果来惩罚生成器。
When training begins, the generator produces obviously fake data, and the discriminator quickly learns to tell that it’s fake:
在开始训练时,生成器会生成明显的虚假数据,而判别器会快速学会辨别数据是虚假的:
As training progresses, the generator gets closer to producing output that can fool the discriminator:
随着训练的进行,生成器越来越接近能够分辨判别器的输出:
Finally, if generator training goes well, the discriminator gets worse at telling the difference between real and fake. It starts to classify fake data as real, and its accuracy decreases.
最后,如果生成器训练的进展顺利,判别器在区分真实和虚假方面会变得更加糟糕。它开始将虚假数据分类为真实数据,其准确性会降低。
Both the generator and the discriminator are neural networks. The generator output is connected directly to the discriminator input. Through backpropagation, the discriminator’s classification provides a signal that the generator uses to update its weights.
生成器和判别器都是神经网络。生成器输出直接连接到判别器输入。通过反向传播,判别器的分类提供了一个信号,供生成器用于更新其权重。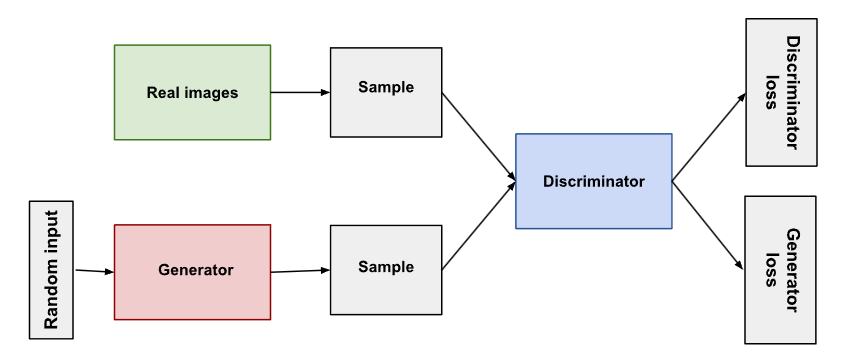
4. The Discriminator 判别器
The discriminator in a GAN is simply a classifier. It tries to distinguish real data from the data created by the generator. It could use any network architecture appropriate to the type of data it’s classifying.
GAN 中的判别器只是一个分类器。它试图将真实数据与生成器创建的数据区分开来。它可以使用任何适合其分类数据类型的网络架构。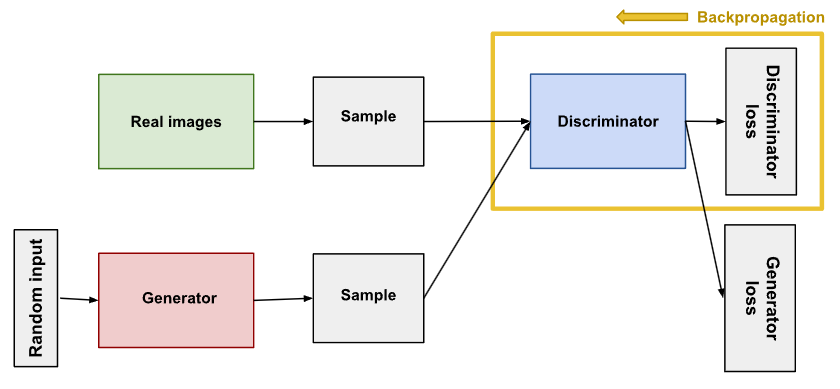
Backpropagation in discriminator training.
判别器训练中的反向传播。
(1)Discriminator Training Data 判别器训练数据
The discriminator’s training data comes from two sources:
判别器的训练数据有两个来源:
- Real data instances, such as real pictures of people. The discriminator uses these instances as positive examples during training.
真实数据实例,如真实的人物图片。在训练过程中,判别器会使用这些实例作为正面示例。 - Fake data instances created by the generator. The discriminator uses these instances as negative examples during training.
生成器创建的虚假数据实例。在训练过程中,判别器会将这些实例作为反例。
The two “Sample” boxes represent these two data sources feeding into the discriminator. During discriminator training the generator does not train. Its weights remain constant while it produces examples for the discriminator to train on.
两个 "样本 "方框代表输入判别器的这两个数据源。在判别器训练期间,生成器不进行训练。在生成样本供判别器训练时,其权重保持不变。
(2)Training the Discriminator 训练判别器
The discriminator connects to two loss functions. During discriminator training, the discriminator ignores the generator loss and just uses the discriminator loss. We use the generator loss during generator training.
判别器连接两个损失函数。在判别器训练期间,判别器忽略生成器损失,只使用判别器损失。在生成器训练过程中,我们会使用生成器损失函数。
(3)During discriminator training: 在判别器训练期间:
- The discriminator classifies both real data and fake data from the generator.
判别器可对来自生成器的真实数据和虚假数据进行分类。 - The discriminator loss penalizes the discriminator for misclassifying a real instance as fake or a fake instance as real.
判别器损失会对判别器将真实实例误判为假实例或将假实例误判为真实实例进行惩罚。 - The discriminator updates its weights through backpropagation from the discriminator loss through the discriminator network.
判别器通过判别器网络对判别器损失进行反向传播来更新权重。
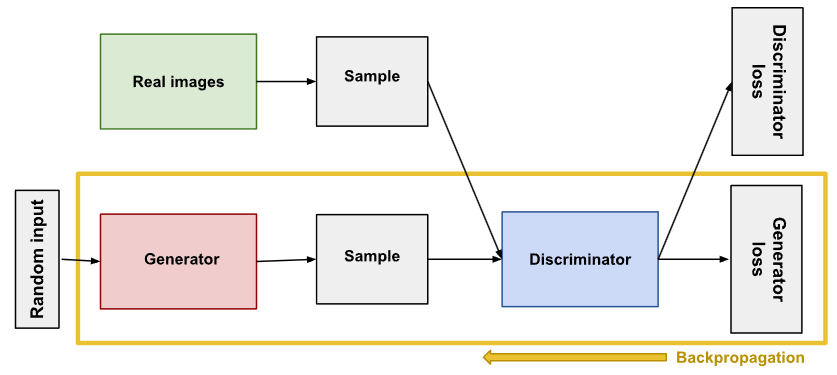
5. The Generator 生成器
The generator part of a GAN learns to create fake data by incorporating feedback from the discriminator. It learns to make the discriminator classify its output as real.
GAN 的生成器部分通过吸收判别器的反馈来学习创建虚假数据。它学会让判别器将其输出分类为真实数据。
Generator training requires tighter integration between the generator and the discriminator than discriminator training requires. The portion of the GAN that trains the generator includes:
与判别训练相比,生成器训练需要生成器与判别器之间更紧密的集成。训练生成器的 GAN 部分包括
- random input
随机输入 - generator network, which transforms the random input into a data instance
生成器网络,将随机输入转化为数据实例 - discriminator network, which classifies the generated data
判别器网络,对生成的数据进行分类 - discriminator output
判别器输出 - generator loss, which penalizes the generator for failing to fool the discriminator
生成器损失,这是对未能骗过判别器的生成器的惩罚
Backpropagation in generator training.
训练中的反向传播。
(1)Random Input 随机输入
- Neural networks need some form of input. Normally we input data that we want to do something with, like an instance that we want to classify or make a prediction about. But what do we use as input for a network that outputs entirely new data instances?
神经网络需要某种形式的输入。通常,我们输入的数据是我们想要做的事情,比如我们想要对某个实例进行分类或预测。但是,对于一个能输出全新数据实例的网络,我们该用什么作为输入呢? - In its most basic form, a GAN takes random noise as its input. The generator then transforms this noise into a meaningful output. By introducing noise, we can get the GAN to produce a wide variety of data, sampling from different places in the target distribution.
GAN 的最基本形式是将随机噪声作为输入。然后,生成器将噪声转换为有意义的输出。通过引入噪声,我们可以让 GAN 从目标分布的不同位置采样,生成各种各样的数据。 - Experiments suggest that the distribution of the noise doesn’t matter much, so we can choose something that’s easy to sample from, like a uniform distribution. For convenience the space from which the noise is sampled is usually of smaller dimension than the dimensionality of the output space.
实验表明,噪声的分布并不重要,因此我们可以选择易于采样的分布,如均匀分布。为了方便起见,噪声采样空间的维度通常小于输出空间的维度。
(2)Using the Discriminator to Train the Generator 使用判别器训练生成器
- To train a neural net, we alter the net’s weights to reduce the error or loss of its output. In our GAN, however, the generator is not directly connected to the loss that we’re trying to affect.
要训练神经网络,我们需要改变网络的权重,以减少其输出的误差或损失。然而,在我们的 GAN 中,生成器与我们试图影响的损失并不直接相关。 - The generator feeds into the discriminator net, and the discriminator produces the output we’re trying to affect.
生成器馈入判别器网络,判别器产生我们试图影响的输出。 - The generator loss penalizes the generator for producing a sample that the discriminator network classifies as fake.
生成器的损失会对生成器产生的样本进行惩罚,因为判别网络会将其归类为假样本。 - This extra chunk of network must be included in backpropagation.
反向传播必须包括这部分额外的网络。 - Backpropagation adjusts each weight in the right direction by calculating the weight’s impact on the output — how the output would change if you changed the weight.
反向传播法通过计算权重对输出的影响(即如果改变权重,输出会发生怎样的变化),将每个权重调整到正确的方向。 - But the impact of a generator weight depends on the impact of the discriminator weights it feeds into.
但生成器权重的影响取决于它所输入的判别器权重的影响。 - So backpropagation starts at the output and flows back through the discriminator into the generator.
因此,反向传播从输出端开始,通过判别器流回发生器。 - At the same time, we don’t want the discriminator to change during generator training.
同时,我们也不希望在生成器训练过程中判别器发生变化。 - Trying to hit a moving target would make a hard problem even harder for the generator.
试图击中一个移动的目标,会让生成器的难题变得更难。
So we train the generator with the following procedure:
因此,我们按照以下程序对生成器进行训练:
- Sample random noise.
随机噪音采样 - Produce generator output from sampled random noise.
利用采样随机噪声产生信号生成器输出。 - Get discriminator “Real” or “Fake” classification for generator output.
获取生成器输出的鉴别器“真”或“假”的分类。 - Calculate loss from discriminator classification.
计算判别器分类的损失。 - Backpropagate through both the discriminator and generator to obtain gradients.
通过判别器和生成器进行反向传播,以获得梯度。 - Use gradients to change only the generator weights.
使用梯度只更改生成器权重。
This is one iteration of generator training.
这是生成器训练的一次迭代。
6. GAN Training 生成对抗网络的训练
Because a GAN contains two separately trained networks, its training algorithm must address two complications:
由于 GAN 包含两个单独训练的网络,其训练算法必须解决两个复杂问题:
- GANs must juggle two different kinds of training (generator and discriminator).
GAN 必须兼顾两种不同的训练(生成器和判别器)。 - GAN convergence is hard to identify.
GAN 网络收敛很难识别。
(1)Alternating Training
The generator and the discriminator have different training processes. So how do we train the GAN as a whole?
生成器和判别器有不同的训练过程。那么,我们该如何训练整个 GAN 呢?
GAN training proceeds in alternating periods: GAN 训练交替进行:
- The discriminator trains for one or more epochs.
判别器会进行一个或多个epochs的训练。 - The generator trains for one or more epochs.
信号生成器进行一个或多个epochs的训练。 - Repeat steps 1 and 2 to continue to train the generator and discriminator networks.
重复步骤 1 和 2,继续训练生成器和判别器网络。
- We keep the generator constant during the discriminator training phase.
在判别器训练阶段,我们保持生成器不变。 - As discriminator training tries to figure out how to distinguish real data from fake, it has to learn how to recognize the generator’s flaws.
当判别器训练试图找出如何区分真实数据和伪造数据时,它必须学会如何识别生成器的缺陷。 - That’s a different problem for a thoroughly trained generator than it is for an untrained generator that produces random output.
对于训练有素的生成器来说,这与未经训练、随机输出的生成器所面临的问题是不同的。 - Similarly, we keep the discriminator constant during the generator training phase.
同样,在生成器训练阶段,我们也会保持判别器不变。 - Otherwise the generator would be trying to hit a moving target and might never converge.
否则,生成器将试图击中一个移动的目标,而且可能永远不会收敛。 - It’s this back and forth that allows GANs to tackle otherwise intractable generative problems.
正是这种反反复复的过程使得 GAN 能够解决原本难以解决的生成问题。 - We get a toehold in the difficult generative problem by starting with a much simpler classification problem.
我们可以从一个简单得多的分类问题入手,来解决这个困难的生成问题。 - Conversely, if you can’t train a classifier to tell the difference between real and generated data even for the initial random generator output, you can’t get the GAN training started.
反之,如果您无法训练分类器来区分真实数据和生成数据,即使是初始随机生成器输出的数据,您也无法开始 GAN 训练。
(2) Convergence 收敛
- As the generator improves with training, the discriminator performance gets worse because the discriminator can’t easily tell the difference between real and fake. If the generator succeeds perfectly, then the discriminator has a 50% accuracy.
随着生成器在训练中不断改进,鉴别器的性能会越来越差,因为鉴别器不容易区分真假。如果生成器完全成功,那么鉴别器的准确率就是 50%。 - In effect, the discriminator flips a coin to make its prediction.
实际上,判别器是通过掷硬币来做出预测的。 - This progression poses a problem for convergence of the GAN as a whole: the discriminator feedback gets less meaningful over time.
随着时间的推移,判别器反馈的意义越来越小。 - If the GAN continues training past the point when the discriminator is giving completely random feedback, then the generator starts to train on junk feedback, and its own quality may collapse.
如果 GAN 在判别器给出完全随机的反馈后继续训练,那么生成器就会开始根据垃圾反馈进行训练,其自身的质量可能会下降。 - For a GAN, convergence is often a fleeting, rather than stable, state.
对于 GAN 来说,收敛往往是一种短暂而非稳定的状态。
7. Loss Functions 损失函数
GANs try to replicate a probability distribution.
GAN 尝试复制一种概率分布。
They should therefore use loss functions that reflect the distance between the distribution of the data generated by the GAN and the distribution of the real data.
因此,他们应该使用能反映 GAN 生成的数据分布与真实数据分布之间距离的损失函数。
How do you capture the difference between two distributions in GAN loss functions?
如何在 GAN 损失函数中捕捉两个分布之间的差异?
This question is an area of active research, and many approaches have been proposed.
这个问题是一个活跃的研究领域,已经提出了许多方法。
We’ll address two common GAN loss functions here, both of which are implemented in TF-GAN:
这里我们将讨论两种常见的 GAN 损失函数,这两种函数都在 TF-GAN 中实现:
- minimax loss: The loss function used in the paper that introduced GANs.
minimax loss(最小损失): 引入 GANs 的论文中使用的损失函数。 - Wasserstein loss: The default loss function for TF-GAN Estimators. First described in a 2017 paper.
Wasserstein 损失: TF-GAN 估计器的默认损失函数。在 2017 年的一篇论文中首次描述。
TF-GAN implements many other loss functions as well.
TF-GAN 还实现了许多其他损失函数。
(1)One Loss Function or Two?
- A GAN can have two loss functions: one for generator training and one for discriminator training.
GAN 可以有两个损失函数:一个用于生成器训练,另一个用于判别器训练。 - How can two loss functions work together to reflect a distance measure between probability distributions?
两个损失函数如何共同反映概率分布之间的距离度量? - In the loss schemes we’ll look at here, the generator and discriminator losses derive from a single measure of distance between probability distributions.
在我们将要讨论的损失方案中,生成器损耗和判别器损失都来自于对概率分布间距离的单一测量。 - In both of these schemes, however, the generator can only affect one term in the distance measure: the term that reflects the distribution of the fake data.
然而,在这两种方案中,生成器只能影响距离测量中的一个项:反映假数据分布的项。 - So during generator training we drop the other term, which reflects the distribution of the real data.
因此,在生成器训练过程中,我们去掉了反映真实数据分布的另一个项。
(2)Minimax Loss
In the paper that introduced GANs, the generator tries to minimize the following function while the discriminator tries to maximize it:
在引入 GAN 的论文中,生成器试图最小化以下函数,而判别器则试图最大化以下函数: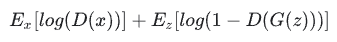
In this function:
- D(x) is the discriminator’s estimate of the probability that real data instance x is real.
D(x) 是判别器对真实数据实例 x 真实性概率的估计。 - Ex is the expected value over all real data instances.
Ex 是所有真实数据实例的预期值。 - G(z) is the generator’s output when given noise z.
G(z) 是给定噪声 z 时生成器的输出。 - D(G(z)) is the discriminator’s estimate of the probability that a fake instance is real.
D(G(z))是判别器对假冒实例真实概率的估计。 - Ez is the expected value over all random inputs to the generator (in effect, the expected value over all generated fake instances G(z)).
Ez 是生成器所有随机输入的期望值(实际上是所有生成的假实例 G(z) 的期望值)。 - The formula derives from the cross-entropy between the real and generated distributions.
该公式源于真实分布和生成分布之间的交叉熵。 - The generator can’t directly affect the log(D(x)) term in the function, so, for the generator, minimizing the loss is equivalent to minimizing log(1 - D(G(z))).
生成器不能直接影响函数中的 log(D(x)) 项,因此,对于生成器来说,最小化损耗等同于最小化 log(1 - D(G(z)))
(3) Modified Minimax Loss 修正的最小损失
- The original GAN paper notes that the above minimax loss function can cause the GAN to get stuck in the early stages of GAN training when the discriminator’s job is very easy.
最初的 GAN 论文指出,上述 minimax 损失函数会导致 GAN 在 GAN 训练的早期阶段陷入困境,因为此时判别器的工作非常容易。 - The paper therefore suggests modifying the generator loss so that the generator tries to maximize log D(G(z)).
因此,本文建议修改生成器机损耗,使发生成器尝试最大化 log D(G(z))。
(4) Wasserstein Loss
- This loss function depends on a modification of the GAN scheme (called “Wasserstein GAN” or “WGAN”) in which the discriminator does not actually classify instances.
这种损失函数取决于对 GAN 方案(称为 "Wasserstein GAN "或 “WGAN”)的一种修改,在这种方案中,判别器实际上并不对实例进行分类。 - For each instance it outputs a number. This number does not have to be less than one or greater than 0, so we can’t use 0.5 as a threshold to decide whether an instance is real or fake.
对于每个实例,它都会输出一个数字。这个数字不一定小于 1 或大于 0,因此我们不能用 0.5 作为阈值来判断一个实例是真的还是假的。 - Discriminator training just tries to make the output bigger for real instances than for fake instances.
判别器训练只是试图使真实实例的输出大于虚假实例的输出。 - Because it can’t really discriminate between real and fake, the WGAN discriminator is actually called a “critic” instead of a “discriminator”.
由于无法真正辨别真假,WGAN 鉴别器实际上被称为 “批评者”,而不是 “判别器”。 - This distinction has theoretical importance, but for practical purposes we can treat it as an acknowledgement that the inputs to the loss functions don’t have to be probabilities.
这一区别在理论上具有重要意义,但在实际应用中,我们可以将其视为承认损失函数的输入不一定是概率。
The loss functions themselves are deceptively simple:
损失函数本身非常简单:
Critic Loss: D(x) - D(G(z))
- The discriminator tries to maximize this function. In other words, it tries to maximize the difference between its output on real instances and its output on fake instances.
判别器试图最大化这个函数。换句话说,它试图最大化对真实实例的输出与对虚假实例的输出之间的差异。
Generator Loss: D(G(z)) - The generator tries to maximize this function. In other words, It tries to maximize the discriminator’s output for its fake instances.
生成器试图最大化这个函数。换句话说,它试图最大化判别器对假实例的输出。
In these functions:
- D(x) is the critic’s output for a real instance.
D(x) 是批评者对真实实例的输出结果 - G(z) is the generator’s output when given noise z.
G(z) 是给定噪声 z 时生成器的输出。 - D(G(z)) is the critic’s output for a fake instance.
D(G(z)) 是批评者对虚假实例的输出结果。 - The output of critic D does not have to be between 1 and 0.
批判者 D 的输出不必介于 0 和 1 之间。 - The formulas derive from the earth mover distance between the real and generated distributions.
这些公式源于真实分布和生成分布之间的移动距离。
8. Common Problems 常见的问题
(1)Vanishing Gradients 梯度消失
- Research has suggested that if your discriminator is too good, then generator training can fail due to vanishing gradients. In effect, an optimal discriminator doesn’t provide enough information for the generator to make progress.
研究表明,如果判别器太好,那么信号生成器的训练就会因为梯度消失而失败。实际上,一个最佳的判别器并不能提供足够的信息让生成器取得进展。
Attempts to Remedy 补救措施
- Wasserstein loss: The Wasserstein loss is designed to prevent vanishing gradients even when you train the discriminator to optimality.
Wasserstein 损失的设计目的是防止梯度消失,即使你将判别器训练到最佳状态。 - Modified minimax loss: The original GAN paper proposed a modification to minimax loss to deal with vanishing gradients.
修改后的最小损失 最初的 GAN 论文提出了对 minimax loss 的修改,以解决梯度消失的问题。
(2)Mode Collapse 模式崩溃
- Usually you want your GAN to produce a wide variety of outputs. You want, for example, a different face for every random input to your face generator.
通常,您希望您的 GAN 能够产生各种各样的输出。例如,您希望每次随机输入到人脸生成器的人脸都是不同的。 - However, if a generator produces an especially plausible output, the generator may learn to produce only that output. In fact, the generator is always trying to find the one output that seems most plausible to the discriminator.
但是,如果生成器产生了一个特别可信的输出,生成器就可能学会只产生这个输出。事实上,生成器一直在努力寻找一种在判别器看来最可信的输出。 - If the generator starts producing the same output (or a small set of outputs) over and over again, the discriminator’s best strategy is to learn to always reject that output.
如果生成器开始反复产生相同的输出(或一小组输出),判别器的最佳策略就是学会始终拒绝该输出。 - But if the next generation of discriminator gets stuck in a local minimum and doesn’t find the best strategy, then it’s too easy for the next generator iteration to find the most plausible output for the current discriminator.
但如果下一代判别器陷入局部最小值,找不到最佳策略,那么下一代生成器就很容易为当前判别器找到最合理的输出。 - Each iteration of generator over-optimizes for a particular discriminator, and the discriminator never manages to learn its way out of the trap.
生成器的每一次迭代都会对特定的判别器进行过度优化,而判别器永远无法学会如何摆脱陷阱。 - As a result the generators rotate through a small set of output types. This form of GAN failure is called mode collapse.
因此,生成器只能在一小部分输出类型中旋转。这种 GAN 失效形式被称为模式崩溃。
Attempts to Remedy 补救措施
- The following approaches try to force the generator to broaden its scope by preventing it from optimizing for a single fixed discriminator:
以下方法试图通过阻止生成器对单一固定判别器进行优化,来迫使生成器扩大范围: - Wasserstein loss: The Wasserstein loss alleviates mode collapse by letting you train the discriminator to optimality without worrying about vanishing gradients. If the discriminator doesn’t get stuck in local minima, it learns to reject the outputs that the generator stabilizes on. So the generator has to try something new.
Wasserstein损失可以缓解模式崩溃,让你训练判别器达到最优,而不用担心梯度消失。如果判别器没有陷入局部最小值,它就会学会拒绝生成器稳定的输出。因此,生成器必须尝试新的方法。 - Unrolled GANs: Unrolled GANs use a generator loss function that incorporates not only the current discriminator’s classifications, but also the outputs of future discriminator versions. So the generator can’t over-optimize for a single discriminator.
Unrolled GANs 使用的生成器损失函数不仅包含当前判别器的分类,还包含未来判别器版本的输出。因此,生成器无法对单个判别器进行过度优化。
(3) Failure to Converge 无法收敛
- GANs frequently fail to converge, as discussed in the module on training.
正如训练模块所讨论的,GAN 经常无法收敛。
Attempts to Remedy 补救措施
- Researchers have tried to use various forms of regularization to improve GAN convergence, including:
研究人员尝试使用各种形式的正则化来提高 GAN 的收敛性,其中包括 - Adding noise to discriminator inputs: See, for example, Toward Principled Methods for Training Generative Adversarial Networks.
在判别器输入中添加噪音: 例如,请参阅《训练生成式对抗网络的原则性方法》(Toward Principled Methods for Training Generative Adversarial Networks)。 - Penalizing discriminator weights: See, for example, Stabilizing Training of Generative Adversarial Networks through Regularization.
对判别器权重进行惩罚: 例如,参见《通过正则化稳定生成对抗网络的训练》。
9. GAN Variations GAN 变体
- Researchers continue to find improved GAN techniques and new uses for GANs. Here’s a sampling of GAN variations to give you a sense of the possibilities.
研究人员不断发现改进的 GAN 技术和 GAN 的新用途。下面是一些 GAN 变体的样本,让您了解各种可能性。
(1) Progressive GANs 渐进式 GAN
- In a progressive GAN, the generator’s first layers produce very low resolution images, and subsequent layers add details. This technique allows the GAN to train more quickly than comparable non-progressive GANs, and produces higher resolution images.
在渐进式 GAN 中,生成器的第一层生成分辨率非常低的图像,随后各层增加细节。与同类非渐进式 GAN 相比,这种技术能更快地训练 GAN,并生成更高分辨率的图像。
(2) Conditional GANs 条件式 GAN
- Conditional GANs train on a labeled data set and let you specify the label for each generated instance.
条件型 GAN 在有标签的数据集上进行训练,并允许您为每个生成的实例指定标签。 - For example, an unconditional MNIST GAN would produce random digits, while a conditional MNIST GAN would let you specify which digit the GAN should generate.
例如,无条件 MNIST GAN 将生成随机数字,而有条件 MNIST GAN 将允许您指定 GAN 应生成哪个数字。 - Instead of modeling the joint probability P(X, Y), conditional GANs model the conditional probability P(X | Y).
条件 GAN 模拟的不是联合概率 P(X,Y),而是条件概率 P(X | Y)。
(3) Image-to-Image Translation 图像到图像的转换
- Image-to-Image translation GANs take an image as input and map it to a generated output image with different properties.
图像到图像转换 GAN 将图像作为输入,并将其映射到具有不同属性的生成输出图像。 - For example, we can take a mask image with blob of color in the shape of a car, and the GAN can fill in the shape with photorealistic car details.
例如,我们可以获取一张带有汽车形状色块的遮罩图像,而 GAN 可以将逼真的汽车细节填充到图像中。 - Similarly, you can train an image-to-image GAN to take sketches of handbags and turn them into photorealistic images of handbags.
同样,您也可以训练图像到图像的 GAN,将手袋草图转化为逼真的手袋图像。

In these cases, the loss is a weighted combination of the usual discriminator-based loss and a pixel-wise loss that penalizes the generator for departing from the source image.
在这种情况下,损失是通常的基于判别器的损失和像素损失的加权组合,后者对生成器偏离源图像进行惩罚。
(4) CycleGAN 循环 GAN
-
CycleGANs learn to transform images from one set into images that could plausibly belong to another set.
CycleGANs 学会将一个集合中的图像转换成可能属于另一个集合的图像。 -
For example, a CycleGAN produced the righthand image below when given the lefthand image as input.
例如,当输入左侧图像时,CycleGAN 生成了下图中右侧的图像。 -
It took an image of a horse and turned it into an image of a zebra.
它把一匹马的图像变成了斑马的图像。 -
The training data for the CycleGAN is simply two sets of images (in this case, a set of horse images and a set of zebra images).
CycleGAN 的训练数据就是两组图像(本例中为一组马匹图像和一组斑马图像)。 -
The system requires no labels or pairwise correspondences between images.
该系统无需标签或图像之间的成对对应关系。

(5) Text-to-Image Synthesis 文本到图像的合成
-
Text-to-image GANs take text as input and produce images that are plausible and described by the text.
从文本到图像的 GAN 将文本作为输入,并生成文本所描述的可信图像。 -
For example, the flower image below was produced by feeding a text description to a GAN.
例如,下图中的花朵图像就是通过向 GAN 输入文字描述生成的。
“This flower has petals that are yellow with shades of orange.”
“这朵花的花瓣黄中带橙” -
Note that in this system the GAN can only produce images from a small set of classes.
请注意,在该系统中,GAN 只能生成一小部分类别的图像。

(6) Super-resolution 超分辨率
-
Super-resolution GANs increase the resolution of images, adding detail where necessary to fill in blurry areas.
超分辨率 GAN 可提高图像的分辨率,在必要时增加细节以填补模糊区域。 -
For example, the blurry middle image below is a downsampled version of the original image on the left.
例如,下面模糊的中间图像就是左边原始图像的下采样版本。 -
Given the blurry image, a GAN produced the sharper image on the right:
在图像模糊的情况下,GAN 生成了右侧更清晰的图像: -
The GAN-generated image looks very similar to the original image, but if you look closely at the headband you’ll see that the GAN didn’t reproduce the starburst pattern from the original.
GAN 生成的图像与原始图像非常相似,但如果仔细观察头带,就会发现 GAN 并没有再现原始图像中的星形图案。 -
Instead, it made up its own plausible pattern to replace the pattern erased by the down-sampling.
取而代之的是,它自己编造了一个似是而非的模式来取代被向下采样所抹去的模式。

(7) Face Inpainting 面部彩绘
- GANs have been used for the semantic image inpainting task. In the inpainting task, chunks of an image are blacked out, and the system tries to fill in the missing chunks.
GANs 已被用于语义图像内绘任务。在嵌画任务中,图像的大块部分被涂黑,系统会尝试填补缺失的部分。

(8) Text-to-Speech 文本到语音
- Not all GANs produce images. For example, researchers have also used GANs to produce synthesized speech from text input.
并非所有的 GAN 都能生成图像。例如,研究人员还利用 GANs 从文本输入中生成合成语音。
10. Course Summary and Next Steps
You should now be able to:
- Understand the difference between generative and discriminative models.
- Identify problems that GANs can solve.
- Understand the roles of the generator and discriminator in a GAN system.
- Understand the advantages and disadvantages of common GAN loss functions.
- Identify possible solutions to common problems with GAN training.
可查看原文:网站地址
-
动态面包屑学习:新手入门教程11-01
-
动态权限学习入门指南11-01
-
动态主题处理学习:初学者指南11-01
-
11 个全球最好的 AI 文本转语音工具分析(2024 年)10-31
-
数据回测教程:初学者必备指南10-30
-
自动交易学习:新手入门指南10-30
-
基于卡尔曼滤波器的递归状态估计与ROS 2的应用讲解10-30
-
?? pgai 向量化工具:用一条 SQL 命令在 PostgreSQL 自动生成 AI 嵌入向量10-30
-
量化进阶实战:零基础到初级量化交易者的必修课10-30
-
量化交易项目实战:初学者指南10-30
-
数据回测实战入门教程10-30
-
使用 FastGPT 工作流搭建 GitHub Issues 自动总结机器人10-30
-
量化交易项目实战:新手入门教程10-30
-
量化交易实战:新手入门量化交易的全面指南10-30
-
数据回测实战:初学者指南10-30
