Go教程
golang 必会之 pprof 监控系列(1) —— go trace 统计原理与使用

golang pprof 监控系列(1) —— go trace 统计原理与使用
profile的中文是轮廓,对于计算机程序而言,抛开业务逻辑不谈,它的轮廓是是啥呢?不就是cpu,内存,各种阻塞开销,线程,协程概况 这些运行指标或环境。golang语言自带了工具库来帮助我们描述,探测,分析这些指标或者环境信息,让我们来学习它。
首先来看下go trace的使用和原理,trace 顾名思义,跟踪的含义,有链路追踪经验的同学应该知道现有的例如jarger 之类的工具能够在分布式环境下统计程序运行轨迹和耗时情况。 而golang 里的trace呢与之类似
关于go tool trace的使用,网上有相当多的资料,但拿我之前初学golang的经验来讲,很多资料都没有把go tool trace中的相关指标究竟是统计的哪些方法,统计了哪段区间讲解清楚。所以这篇文章不仅仅会介绍go tool trace的使用,也会对其统计的原理进行剖析。
golang版本 go1.17.12
简单说下go tool trace 的使用场景,在分析延迟性问题的时候,go tool trace能起到很重要的作用,因为它会记录各种延迟事件并且对其进行时长分析,连关键代码位置也能找出来。
接着我们简单看下golang 里如何使用trace 功能。
go trace 使用
package main
import (
_ "net/http/pprof"
"os"
"runtime/trace"
)
func main() {
f, _ := os.Create("trace.out")
defer f.Close()
trace.Start(f)
defer trace.Stop()
......
}
使用trace的功能其实比较容易,用trace.Start 便可以开启trace的事件采样功能,trace.Stop 则停止采用,采样的数据会记录到trace.Start 传来的输出流参数里,这里我是将一个名为trace.out 的文件作为输出流参数传入。
采样结束后便可以通过 go tool trace trace.out命令对采样文件进行分析了。
go tool trace 命令默认会使用本地随机一个端口来启动一个http服务,页面显示如下:

接着我会分析下各个链接对应的统计信息以及背后进行统计的原理,好的,接下来,正戏开始。
统计原理介绍
平时在使用prometheus对应用服务进行监控时,我们主要还是采用埋点的方式,同样,go runtime内部也是采用这样的方式对代码运行过程中的各种事件进行埋点,最后读取 整理后的埋点数据,形成我们在网页上看的trace监控图。
// src/runtime/trace.go:517
func traceEvent(ev byte, skip int, args ...uint64) {
mp, pid, bufp := traceAcquireBuffer()
.....
}
每次要记录相应的事件时,都会调用traceEvent方法,ev代表的是事件枚举,skip 是看栈帧需要跳跃的层数,args 在某些事件需要传入特定参数时传入。
在traceEvent 内部同时也会获取到当前事件发生时的线程信息,协程信息,p运行队列信息,并把这些信息同事件一起记录到一个缓冲区里。
// src/runtime/trace/trace.go:120
func Start(w io.Writer) error {
tracing.Lock()
defer tracing.Unlock()
if err := runtime.StartTrace(); err != nil {
return err
}
go func() {
for {
data := runtime.ReadTrace()
if data == nil {
break
}
w.Write(data)
}
}()
atomic.StoreInt32(&tracing.enabled, 1)
return nil
}
在我们启动trace.Start方法的时候,同时会启动一个协程不断读取缓冲区中的内容到strace.Start 的参数中。
在示例代码里,trace.Start 方法传入名为trace.out文件的输出流参数,所以在采样过程中,runtime会将采集到的事件字节流输出到trace.out文件,trace.out文件在被读取出的时候 是用了一个叫做Event的结构体来表示这些监控事件。
// Event describes one event in the trace.
type Event struct {
Off int // offset in input file (for debugging and error reporting)
Type byte // one of Ev*
seq int64 // sequence number
Ts int64 // timestamp in nanoseconds
P int // P on which the event happened (can be one of TimerP, NetpollP, SyscallP)
G uint64 // G on which the event happened
StkID uint64 // unique stack ID
Stk []*Frame // stack trace (can be empty)
Args [3]uint64 // event-type-specific arguments
SArgs []string // event-type-specific string args
// linked event (can be nil), depends on event type:
// for GCStart: the GCStop
// for GCSTWStart: the GCSTWDone
// for GCSweepStart: the GCSweepDone
// for GoCreate: first GoStart of the created goroutine
// for GoStart/GoStartLabel: the associated GoEnd, GoBlock or other blocking event
// for GoSched/GoPreempt: the next GoStart
// for GoBlock and other blocking events: the unblock event
// for GoUnblock: the associated GoStart
// for blocking GoSysCall: the associated GoSysExit
// for GoSysExit: the next GoStart
// for GCMarkAssistStart: the associated GCMarkAssistDone
// for UserTaskCreate: the UserTaskEnd
// for UserRegion: if the start region, the corresponding UserRegion end event
Link *Event
}
来看下Event事件里包含哪些信息:
P 是运行队列,go在运行协程时,是将协程调度到P上运行的,G 是协程id,还有栈id StkID ,栈帧 Stk,以及事件发生时可以携带的一些参数Args,SArgs。
Type 是事件的枚举字段,Ts是事件发生的时间戳信息,Link 是与事件关联的其他事件,用于计算关联事件的耗时。
拿计算系统调用耗时来说,系统调用相关的事件有GoSysExit,GoSysCall 分别是系统调用退出事件和系统调用开始事件,所以GoSysExit.Ts - GoSysCall.Ts 就是系统调用的耗时。
特别提示: runtime 内部用到的监控事件枚举在src/runtime/trace.go:39 位置 ,而 在读取文件中的监控事件用到的枚举是 在src/internal/trace/parser.go:1028 ,虽然是两套,但是值是一样的。
很明显Link 字段不是在runtime 记录监控事件时设置的,而是在读取trace.out里的监控事件时,将事件信息按照协程id分组后 进行设置的。同一个协程的 GoSysExit.Ts - GoSysCall.Ts 就是该协程的系统调用耗时。
接下来我们来挨个分析下trace页面的统计信息以及背后的统计原理。
View trace是每个事件的时间线构成的监控图,在生产环境下1s都会产生大量的事件,我认为直接看这张图还是会让人眼花缭乱。 所以还是跳过它吧,从Goroutine analysis开始分析。
Goroutine analysis
go tool trace最终引用的代码位置是在go/src/cmd/trace 包下,main函数会启动一个http服务,并且注册一些处理函数,我们点击Goroutine analysis 其实就是请求到了其中一个处理函数上。
下面这段代码是注册的goroutine的处理函数点击Goroutine analysis 就会映射到 /goroutines 路由上。
// src/cmd/trace/goroutines.go:22
func init() {
http.HandleFunc("/goroutines", httpGoroutines)
http.HandleFunc("/goroutine", httpGoroutine)
}
让我们点击下 Goroutine analysis

进入到了一个显示代码调用位置的列表,列表中的每个代码位置都是事件EvGoStart 协程开始运行时的位置,其中N代表 在采用期间 在这个位置上有N个协程开始过运行。
你可能会好奇,是怎样确定这10个协程是由同一段代码执行的?runtime在记录协程开始执行的事件EvGoStart 时,是会把栈帧也记录下来的,而栈帧中包含函数名和程序计数器(PC)的值,在Goroutine analysis 页面 中就是协程就是按PC的值进行分组的。 以下是PC赋值的代码片段。
// src/internal/trace/goroutines.go:176
case EvGoStart, EvGoStartLabel:
g := gs[ev.G]
if g.PC == 0 {
g.PC = ev.Stk[0].PC
g.Name = ev.Stk[0].Fn
}
我们再点击第一行链接 nfw/nfw_base/fw/routine.(*Worker).TryRun.func1 N=10 ,这里点击第一行的链接将会映射到 /goroutine 的路由上(注意路由已经不是s结尾了),由它的处理函数进行处理。点击后如图所示:
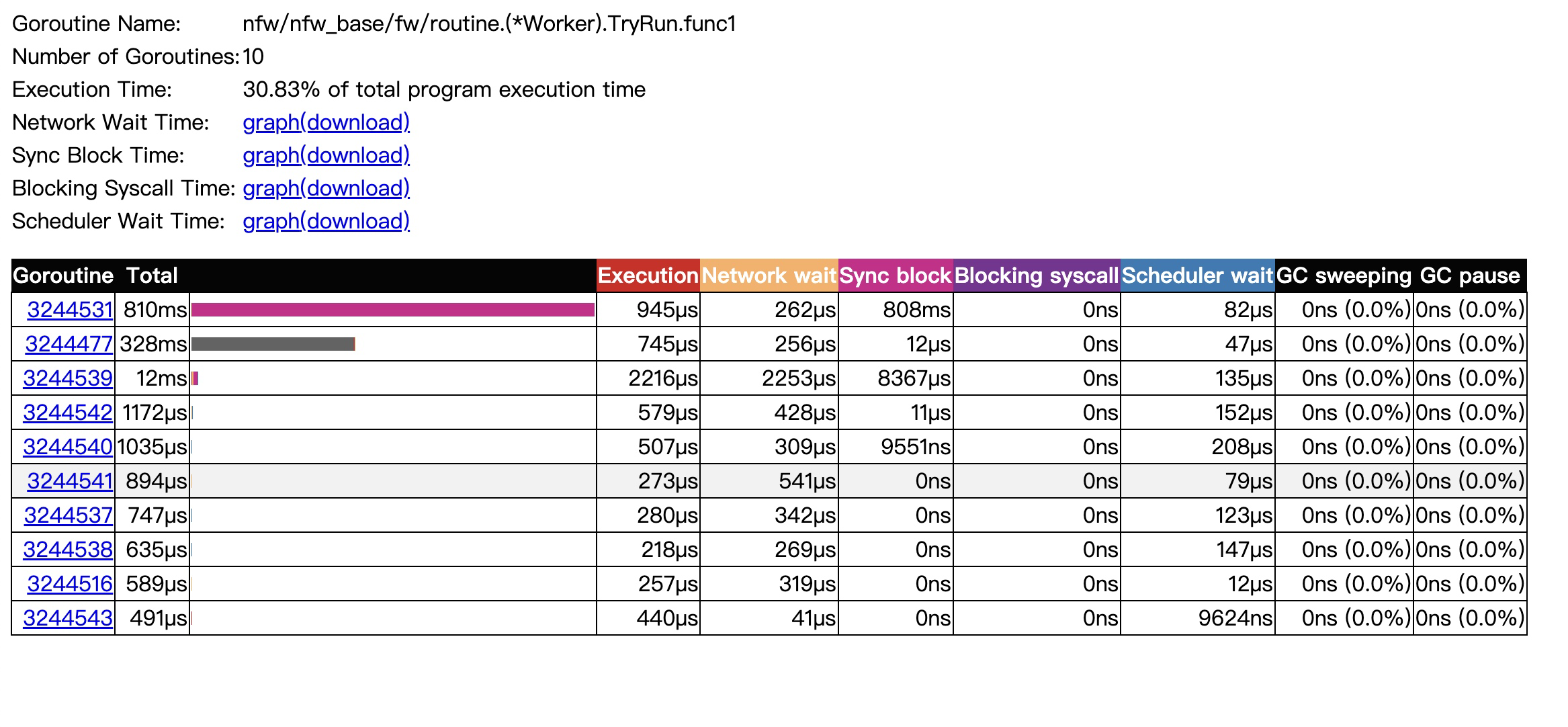
现在看到的就是针对这10个协程分别的系统调用,阻塞,调度延迟,gc这些统计信息。
接着我们从上到下挨个分析:
Execution Time 是指着10个协程的执行时间占所有协程执行的比例。
接着是用于分析网络等待时间,锁block时间,系统调用阻塞时间 ,调度等待时间的图片,这些都是分析系统延迟,阻塞问题的利器。 这里就不再分析图了,相信网上会有很多这种资料。
然后来看下 表格里的各项指标:
Execution
是协程在采样这段时间内的执行时间。
记录的方式也很简单,在读取event事件时,是按时间线从前往后读取,每次读取到协程开始执行的时间时,会记录下协程的开始执行的时间戳(时间戳是包含在Event结构里的),读取到协程停顿事件时,则会把停顿时刻的时间戳减去开始执行的时间戳 得到 一小段的执行时间,将这小段的时间 累加到该协程的总执行时间上。
停顿则是由锁block,系统调用阻塞,网络等待,抢占调度造成的。
Network wait
顾名思义,网络等待时长, 其实也是和Execution类似的记录方式,首先记录下协程在网络等待时刻的时间戳,由于event是按时间线读取的,当读取到unblock事件时,再去看协程上一次是不是网络等待事件,如果是的话,则将当前时刻时间戳减去 网络等待时刻的时间戳,得到的这一小段时间,累加到该协程的总网络等待时长上。
Sync block,Blocking syscall,Scheduler wait
这三个时长 计算方式和前面两张也是类似的,不过注意下与之相关联的事件的触发条件是不同的。
Sync block 时长是由于 锁 sync.mutex ,通道channel,wait group,select case语句产生的阻塞都会记录到这里。 下面是相关代码片段。
// src/internal/trace/goroutines.go:192 case EvGoBlockSend, EvGoBlockRecv, EvGoBlockSelect, EvGoBlockSync, EvGoBlockCond: g := gs[ev.G] g.ExecTime += ev.Ts - g.lastStartTime g.lastStartTime = 0 g.blockSyncTime = ev.Ts
Blocking syscall 就是系统调用造成的阻塞了。
Scheduler wait 是协程从可执行状态到执行状态的时间段,注意协程是可执行状态时 是会放到p 运行队列等待被调度的,只有被调度后,才会真正开始执行代码。 这里涉及到golang gpm模型的理解,这里就不再展开了。
后面两栏就是GC 占用total时间的一个百分比了,golang 的gc相关的知识也不继续展开了。
各种profile 图
还记得最开始分析trace.out生成的网页时,Goroutine analysis 下面是什么吗?是各种分析延迟相关的profile 图,数据的来源和我们讲Goroutine analysis 时分析单个Goroutine 的等待时间的指标是一样的,不过这里是针对所有goroutine而言。
Network blocking profile () Synchronization blocking profile () Syscall blocking profile () Scheduler latency profile ()
关于golang 的这个trace工具,还允许用户可以自定义监控事件 ,生成的trace网页里,User-defined tasks,User-defined regions 就是记录用户自定义的一些监控事件,这部分的应用等到以后再讲了。
Minimum mutator utilization 是一个看gc 对程序影响情况的曲线图,这个等以后有机会讲gc时再详细谈谈了。
-
SendGrid 的 Go 客户端库怎么实现同时向多个邮箱发送邮件?-icode9专业技术文章分享11-15
-
SendGrid 的 Go 客户端库怎么设置header 和 标签tag 呢?-icode9专业技术文章分享11-15
-
Cargo deny安装指路11-12
-
MongoDB项目实战:从入门到初级应用11-02
-
随时随地一键转录,Google Cloud 新模型 Chirp 2 让语音识别更上一层楼11-01
-
Google Cloud动手实验详解:如何在Cloud Run上开发无服务器应用10-25
-
AI ?先驱齐聚 BAAI 2024,发布大规模语言、多模态、具身、生物计算以及 FlagOpen 2.0 等 AI 模型创新成果。10-24
-
goland工具下,如修改一个项目的标准库SDK的版本-icode9专业技术文章分享10-20
-
Go学习:初学者的简单教程10-17
-
Go学习:新手入门完全指南10-17
-
Golang学习:初学者入门教程10-17
-
Golang学习:新手入门教程10-17
-
Gozero学习指南:初学者必备教程10-17
-
GoZero学习:新手入门与实践指南10-17
-
Go Zero入门:新手必读指南10-17
