云计算
Prometheus Operator 与 kube-prometheus 之一-简介

简介
Prometheus Operator
Prometheus Operator: 在 Kubernetes 上管理 Prometheus 集群。该项目的目的是简化和自动化基于 Prometheus 的 Kubernetes 集群监控堆栈的配置。
kube-prometheus
最简单的方法是将 Prometheus Operator 作为 kube-prometheus 的一部分进行部署。kube-prometheus 部署了 Prometheus Operator,并且已经安排了一个名为 prometheus-k8s 的 prometheus,默认带有警报和规则,并且带有其他 prometheus 需要的组件,如:
- Grafana
- kube-state-metrics
- prometheus adapter
- node exporter
- …
Prometheus Operator vs. kube-prometheus vs. community helm chart
Prometheus Operator
Prometheus Operator 使用 Kubernetes 自定义资源,简化了 Prometheus、Alertmanager 和相关监控组件的部署和配置。
kube-prometheus
kube-prometheus 提供了一个基于 Prometheus 和 Prometheus Operator 的完整集群监控堆栈的示例配置。这包括部署多个 Prometheus 和 Alertmanager 实例、用于收集节点指标的指标导出器(如 node_exporters)、将 Prometheus 链接到各种指标端点的目标配置,以及用于通知集群中潜在问题的示例警报规则。
helm chart
prometheus-community/kube-prometheus-stack helm chart 提供了与 kube-prometheus 相似的特性集。这张 chart 是由 prometheus 社区维护的。
Prometheus Operator 功能
CRD
Prometheus Operator 的一个核心特性是 watch Kubernetes API 服务器对特定对象的更改,并确保当前 Prometheus 部署与这些对象匹配。Operator 对以下自定义资源定义 (crd) 进行操作:
monitoring.coreos.com/v1:
Prometheus: 它定义了 Prometheus 期望的部署。Alertmanager: 它定义了 AlertManager 期望的部署。ThanosRuler: 它定义了 ThanosRuler 期望的部署;如果有多个 Prometheus 实例,则通过ThanosRuler进行告警规则的统一管理。ServiceMonitor: Prometheus Operator 通过PodMonitor和ServiceMonitor实现对资源的监控,ServiceMonitor用于通过 Service 对 K8S 中的任何资源进行监控,推荐首选ServiceMonitor. 它声明性地指定了 Kubernetes service 应该如何被监控。Operator 根据 API 服务器中对象的当前状态自动生成 Prometheus 刮擦配置。PodMonitor: Prometheus Operator 通过PodMonitor和ServiceMonitor实现对资源的监控,PodMonitor用于对 Pod 进行监控,推荐首选ServiceMonitor.PodMonitor声明性地指定了应该如何监视一组 pod。Operator 根据 API 服务器中对象的当前状态自动生成 Prometheus 刮擦配置。Probe: 它声明性地指定了应该如何监视 ingress 或静态目标组。Operator 根据定义自动生成 Prometheus 刮擦配置。PrometheusRule: 用于管理 Prometheus 告警规则;它定义了一套所需的 Prometheus 警报和/或记录规则。Prometheus 生成一个规则文件,可以被 Prometheus 实例使用。AlertmanagerConfig: 用于管理 AlertManager 配置文件,主要是告警发给谁;它声明性地指定 Alertmanager 配置的子部分,允许将警报路由到自定义接收器,并设置禁止规则。
Prometheus Operator 自动检测 Kubernetes API 服务器对上述任何对象的更改,并确保匹配的部署和配置保持同步。
简化的部署配置
配置 Prometheus 的基础知识,如版本、持久性、保留策略和来自本机 Kubernetes 资源的副本。最简的持久化的 Prometheus 的部署,只需要创建如下 yaml 即可:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: persisted
spec:
storage:
volumeClaimTemplate:
spec:
storageClassName: ssd
resources:
requests:
storage: 40Gi
Prometheus 目标配置
根据熟悉的 Kubernetes 标签查询自动生成监控目标配置;无需学习普罗米修斯特定的配置语言。
大厂案例
哪些大厂在用 Prometheus Operator 或 kube-prometheus?
RedHat
从 Prometheus Operator 的 API 也能看出来,这个 Operator 最早是由 CoreOS 开发并开源的,而现在 CoreOS 已经被 RedHat 收购,所以 RedHat 的 OpenShift 4 完全是采用 Prometheus Operator 作为它的 Metrics 解决方案的。典型的架构如下图:
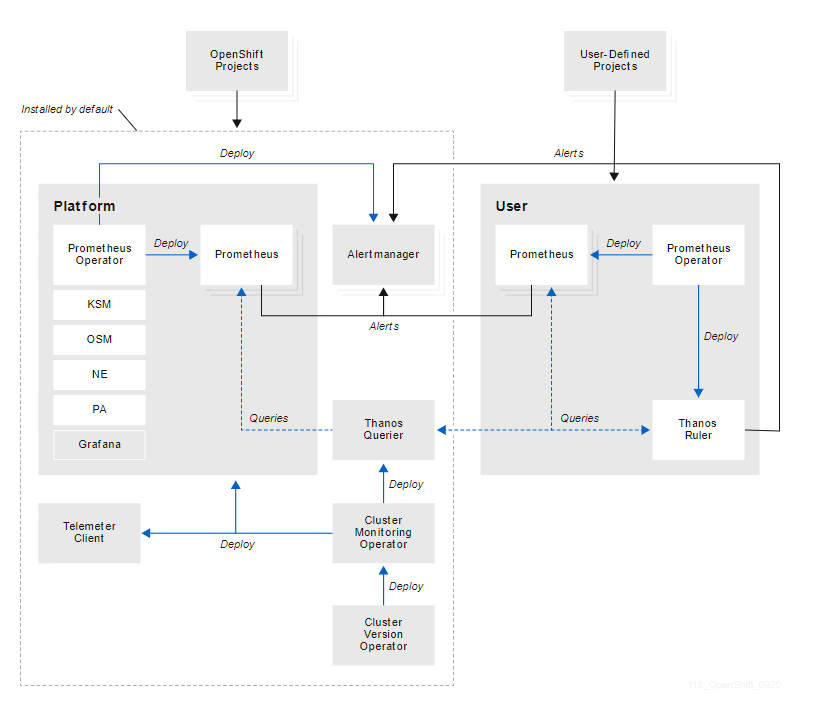
可以看到 Prometheus 和 AlertManager 都是通过 Prometheus Operator 来进行管理的。
Rancher
Rancher 2 以后的 rancher-monitoring 也是基于 kube-prometheus 做了进一步的改进而来的,这是通过 rancher-monitoring helm chart 部署后的关系图,可以看到部署的组件还是非常多的:
- Grafana
- Prometheus CRD
- Prometheus Operator
- Prometheus
- AlertManager
- kube-state-metrics
- prometheus adapter
- node exporter
- …

我为什么推荐你用 Prometheus Operator 或 kube-prometheus 而非原生 prometheus?
理由如下:
- 众多大厂的选择;
- 极大简化了 Prometheus 的配置复杂度;
- 开箱即用的大量:
- 监控对象,如:K8S 组件 - coredns, kubelet, controller manager, apiserver, etcd, scheduler, kube proxy; 监控组件自监控 - grafana, AlertManager, prometheus 等;
- 仪表板,自带 24 个仪表板,非常实用,涵盖:集群/组件/网络/存储/Node/Pod 等等维度;
- 告警规则,自带了 100 多个告警规则,涵盖 K8S 的方方面面;
- 流行的开源产品,很多也默认会带有对 Prometheus Operator 的支持,如 Loki 就有相关的 ServiceMonitor;
- 通过 ServiceMonitor 等,其实反而相比添加 Prometheus Annotation 有更大的灵活性;如下面的例子
- 高可用的支持,如:
- 多个 Prometheus 的 shards
- 多个 AlertManager
- ThanosRuler
- RBAC: 如默认可以创建 3 个 monitoring 的角色:admin/edit/viewer, 可以分别对应监控的管理员,维护人员和只读用户;
示例,灵活性:
spec:
endpoints:
- honorLabels: true
params:
_scheme:
- https
port: metrics
proxyUrl: http://pushprox-k3s-server-proxy.cattle-monitoring-system.svc:8080
relabelings:
- sourceLabels:
- __metrics_path__
targetLabel: metrics_path
jobLabel: component
namespaceSelector:
matchNames:
- cattle-monitoring-system
podTargetLabels:
- component
- pushprox-exporter
selector:
matchLabels:
component: k3s-server
k8s-app: pushprox-k3s-server-client
provider: kubernetes
release: rancher-monitoring
📚️ 参考文档
- prometheus-operator/prometheus-operator: Prometheus Operator creates/configures/manages Prometheus clusters atop Kubernetes (github.com)
- Prometheus Operator - Running Prometheus on Kubernetes (prometheus-operator.dev)
- OperatorHub.io | The registry for Kubernetes Operators
以上
EOF
三人行, 必有我师; 知识共享, 天下为公. 本文由东风微鸣技术博客 EWhisper.cn 编写.
-
Fluss 写入数据湖实战12-23
-
揭秘 Fluss:下一代流存储,带你走在实时分析的前沿(一)12-22
-
DevOps与平台工程的区别和联系12-20
-
从信息孤岛到数字孪生:一本面向企业的数字化转型实用指南12-20
-
手把手教你轻松部署网站12-20
-
服务器购买课程:新手入门全攻略12-20
-
动态路由表学习:新手必读指南12-20
-
服务器购买学习:新手指南与实操教程12-20
-
动态路由表教程:新手入门指南12-20
-
服务器购买教程:新手必读指南12-20
-
动态路由表实战入门教程12-20
-
服务器购买实战:新手必读指南12-20
-
新手指南:轻松掌握服务器部署12-20
-
内网穿透入门指南:轻松实现远程访问12-20
-
网站部署入门教程12-20
