云计算
K3S 系列文章-5G IoT 网关设备 POD 访问报错 DNS 'i/o timeout'分析与解决

开篇
- 《K3s 系列文章》
- 《Rancher 系列文章》
问题概述
20220606 5G IoT 网关设备同时安装 K3S Server, 但是 POD 却无法访问互联网地址,查看 CoreDNS 日志提示如下:
... [ERROR] plugin/errors: 2 update.traefik.io. A: read udp 10.42.0.3:38545->8.8.8.8:53: i/o timeout [ERROR] plugin/errors: 2 update.traefik.io. AAAA: read udp 10.42.0.3:38990->8.8.8.8:53: i/o timeout ...
即 DNS 查询 forward 到了 8.8.8.8 这个 DNS 服务器,并且查询超时。
从而导致需要联网启动的 POD 无法正常启动,频繁 CrashLoopBackoff, 如下图:
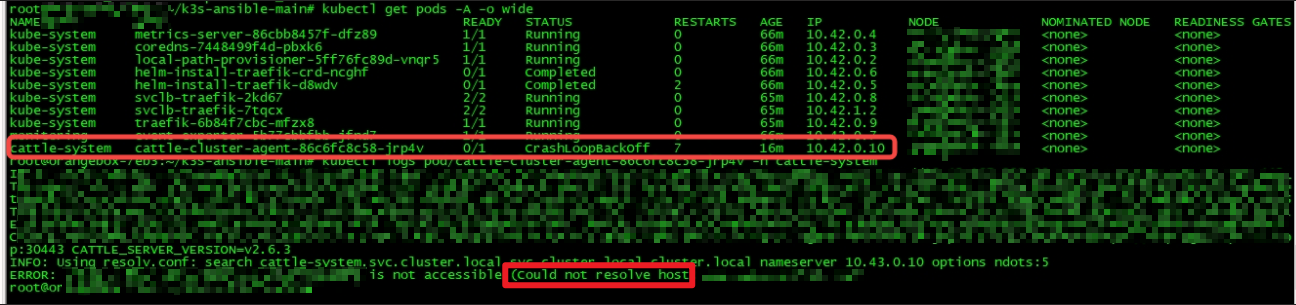
但是通过 Node 直接访问,却是可以正常访问的,如下图:

环境信息
- 硬件:5G IoT 网关
- 网络:
- 互联网访问:5G 网卡:就是一个 usb 网卡,需要通过拨号程序启动,程序会调用系统的 dhcp/dnsmasq/resolvconf 等
- 内网访问:wlan 网卡
- 软件:K3S Server v1.21.7+k3s1, dnsmasq 等
分析
网络详细配置信息
一步一步检查分析:
- 看
/etc/resolv.conf, 发现配置是 127.0.0.1 - netstat 查看 本地 53 端口确实在运行
- 这种情况一般都是本地启动了 DNS 服务器或 缓存,查看 dnsmasq 进程是否存在,确实存在
- dnsmasq 用的 resolv.conf 配置是
/run/dnsmasq/resolv.conf
$ cat /etc/resolv.conf
# Generated by resolvconf
nameserver 127.0.0.1
$ netstat -anpl|grep 53
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 0.0.0.0:53 0.0.0.0:* LISTEN -
tcp6 0 0 :::53 :::* LISTEN -
udp 0 0 0.0.0.0:53 0.0.0.0:* -
udp6 0 0 :::53 :::* -
$ ps -ef|grep dnsmasq
dnsmasq 912 1 0 6 月 06 ? 00:00:00 /usr/sbin/dnsmasq -x /run/dnsmasq/dnsmasq.pid -u dnsmasq -r /run/dnsmasq/resolv.conf -7 /etc/dnsmasq.d,.dpkg-dist,.dpkg-old,.dpkg-new --local-service --trust-anchor=...
$ systemctl status dnsmasq.service
● dnsmasq.service - dnsmasq - A lightweight DHCP and caching DNS server
Loaded: loaded (/lib/systemd/system/dnsmasq.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-06-06 17:21:31 CST; 16h ago
Main PID: 912 (dnsmasq)
Tasks: 1 (limit: 4242)
Memory: 1.1M
CGroup: /system.slice/dnsmasq.service
└─912 /usr/sbin/dnsmasq -x /run/dnsmasq/dnsmasq.pid -u dnsmasq -r /run/dnsmasq/resolv.conf -7 /etc/dnsmasq.d,.dpkg-dist,.dpkg-old,.dpkg-new --local-service --trust-anchor=...
6 月 06 17:21:31 orangebox-7eb3 dnsmasq[912]: started, version 2.80 cachesize 150
6 月 06 17:21:31 orangebox-7eb3 dnsmasq[912]: compile time options: IPv6 GNU-getopt DBus i18n IDN DHCP DHCPv6 no-Lua TFTP conntrack ipset auth DNSSEC loop-detect inotify dumpfile
6 月 06 17:21:31 orangebox-7eb3 dnsmasq-dhcp[912]: DHCP, IP range 192.168.51.100 -- 192.168.51.200, lease time 3d
6 月 06 17:21:31 orangebox-7eb3 dnsmasq[912]: read /etc/hosts - 8 addresses
6 月 06 17:21:31 orangebox-7eb3 dnsmasq[912]: no servers found in /run/dnsmasq/resolv.conf, will retry
6 月 06 17:21:31 orangebox-7eb3 dnsmasq[928]: Too few arguments.
6 月 06 17:21:31 orangebox-7eb3 systemd[1]: Started dnsmasq - A lightweight DHCP and caching DNS server.
6 月 06 17:22:18 orangebox-7eb3 dnsmasq[912]: reading /run/dnsmasq/resolv.conf
6 月 06 17:22:18 orangebox-7eb3 dnsmasq[912]: using nameserver 222.66.251.8#53
6 月 06 17:22:18 orangebox-7eb3 dnsmasq[912]: using nameserver 116.236.159.8#53
$ cat /run/dnsmasq/resolv.conf
# Generated by resolvconf
nameserver 222.66.251.8
nameserver 116.236.159.8
CoreDNS 分析
这里很奇怪,就是没发现哪儿有配置 DNS 8.8.8.8, 但是日志中却显示指向了这个 DNS:
[ERROR] plugin/errors: 2 update.traefik.io. A: read udp 10.42.0.3:38545->8.8.8.8:53: i/o timeout [ERROR] plugin/errors: 2 update.traefik.io. AAAA: read udp 10.42.0.3:38990->8.8.8.8:53: i/o timeout
先查看一下 CoreDNS 的配置:(K3S 的 CoreDNS 是通过 manifests 启动的,位于:/var/lib/rancher/k3s/server/manifests/coredns.yaml 下)
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health
ready
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
hosts /etc/coredns/NodeHosts {
ttl 60
reload 15s
fallthrough
}
prometheus :9153
forward . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
这里主要有 2 个配置需要关注:
forward . /etc/resolv.confloop
CoreDNS 问题常用分析流程
检查 DNS Pod 是否正常运行 - 结果:是的;
# kubectl -n kube-system get pods -l k8s-app=kube-dns NAME READY STATUS RESTARTS AGE coredns-7448499f4d-pbxk6 1/1 Running 1 15h
检查 DNS 服务是否存在正确的 cluster-ip - 结果:是的:
# kubectl -n kube-system get svc -l k8s-app=kube-dns NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterIP 10.43.0.10 <none> 53/UDP,53/TCP,9153/TCP 15h
检查是否能解析域名:
先是内部域名 - 结果:无法解析:
$ kubectl run -it --rm --restart=Never busybox --image=busybox -- nslookup kubernetes.default Server: 10.43.0.10 Address: 10.43.0.10:53 ;; connection timed out; no servers could be reached
再试外部域名 - 结果:无法解析:
$ kubectl run -it --rm --restart=Never busybox --image=busybox -- nslookup www.baidu.com Server: 10.43.0.10 Address: 10.43.0.10:53 ;; connection timed out; no servers could be reached
检查 resolv.conf 中的 nameserver 配置 - 结果:确实是 8.8.8.8
$ kubectl run -i --restart=Never --rm test-${RANDOM} --image=ubuntu --overrides='{"kind":"Pod", "apiVersion":"v1", "spec": {"dnsPolicy":"Default"}}' -- sh -c 'cat /etc/resolv.conf'
nameserver 8.8.8.8
pod "test-7517" deleted
综上:
应该是 POD 内的 /etc/resolv.conf 被配置为 nameserver 8.8.8.8 导致了此次问题。
但是整个 Node OS 级别并没有配置 nameserver 8.8.8.8, 所以怀疑是:Kubernetes、Kubelet、CoreDNS 或 CRI 层面有这样的机制:在 DNS 配置异常时,自动配置其为 nameserver 8.8.8.8。
那么,要解决问题,还是要找到 DNS 配置异常。
容器网络 DNS 服务
我这里暂时没有查到 Kubernetes、Kubelet、CoreDNS 或 CRI 的相关 DNS 的具体证据,K3S 的 CRI 是 containerd,但是我在 Docker 的官方文档 看到了这样的描述:
📚️ Reference:
If the container cannot reach any of the IP addresses you specify, Google’s public DNS server 8.8.8.8 is added, so that your container can resolve internet domains.
如果容器无法到达您指定的任何 (DNS) IP 地址,则添加谷歌的公共 DNS 服务器 8.8.8.8,以便您的容器可以解析 internet 域。
这里猜测 Kubernetes、Kubelet、CoreDNS 或 CRI 可能也有类似的机制。
从这里分析可以知道,根因还是 DNS 配置问题,CoreDNS 配置是默认的,那么最大的可能就是 /etc/resolv.conf 配置为 nameserver 127.0.0.1 导致的此次问题。
根因分析
根因: /etc/resolv.conf 配置为 nameserver 127.0.0.1 导致的此次问题。
CoreDNS 的官方文档明确说明了这种情况:
📚️ Reference:
loop | CoreDNS Docs
当 CoreDNS 日志包含消息Loop ... detected ...时,这意味着检测插件loop在其中一个上游 DNS 服务器中检测到无限转发循环。这是一个致命错误,因为使用无限循环进行操作将消耗内存和 CPU,直到主机最终内存不足死亡。
转发环路通常由以下原因引起:
最常见的是,CoreDNS 直接转发请求给自己。例如,通过127.0.0.1、::1或127.0.0.53等环回地址
要解决此问题,请查看 Corefile 中检测到循环的区域的任何转发。确保他们没有转发到一个本地地址或到另一个 DNS 服务器,这是转发请求回 CoreDNS。如果 forward 正在使用一个文件(例如/etc/resolv.conf),请确保该文件不包含本地地址。
这里可以看到,我们的 CoreDNS 配置包含:forward . /etc/resolv.conf, 且 Node 上的 /etc/resolv.conf 为nameserver 127.0.0.1. 和上面提到的无限转发循环 的 致命错误 匹配。
转发环路通常由以下原因引起:
最常见的是,CoreDNS 将请求直接转发到自身。例如,通过环回地址,例如 ,或 127.0.0.1::1127.0.0.53
解决办法
📚️ Reference:
loop | CoreDNS Docs
官方提供了 3 种解决办法:
- kubelet 添加
--resolv-conf直接指向"真正"的resolv.conf, 一般是:/run/systemd/resolve/resolv.conf- 禁用 Node 上的本地 DNS 缓存
- quick dirty 办法:修改 Corefile, 把
forward . /etc/resolv.conf替换为forward . 8.8.8.8等可以访问的 DNS 地址
针对上面的办法,我们逐一分析下:
- ✔️ 可行:kubelet 添加
--resolv-conf直接指向"真正"的resolv.conf: 如上文所述,我们的"真正"的resolv.conf为:/run/dnsmasq/resolv.conf - ❌ 不可行:禁用 Node 上的本地 DNS 缓存,因为这是基于 5G IoT 网关的特殊情况,5G 网关程序机制就是如此,要用到 dnsmasq
- ❌ 不可行:dirty 的办法,并且 5G 网关获取到的 DNS 是不固定,随时变化的,所以我们也无法指定
forward . <固定的 DNS 地址>
综上,解决办法如下:
在 K3S service 中添加如下字段:--resolv-conf /run/dnsmasq/resolv.conf
添加后如下:
[Unit] Description=Lightweight Kubernetes Documentation=https://k3s.io Wants=network-online.target After=network-online.target [Install] WantedBy=multi-user.target [Service] Type=notify EnvironmentFile=/etc/systemd/system/k3s.service.env KillMode=process Delegate=yes # Having non-zero Limit*s causes performance problems due to accounting overhead # in the kernel. We recommend using cgroups to do container-local accounting. LimitNOFILE=1048576 LimitNPROC=infinity LimitCORE=infinity TasksMax=infinity TimeoutStartSec=0 Restart=always RestartSec=5s ExecStartPre=-/sbin/modprobe br_netfilter ExecStartPre=-/sbin/modprobe overlay ExecStart=/usr/local/bin/k3s server --flannel-iface wlan0 --write-kubeconfig-mode "644" --disable-cloud-controller --resolv-conf /run/dnsmasq/resolv.conf
然后执行如下命令 reload 和 重启:
systemctl daemon-reload systemctl stop k3s.service k3s-killall.sh systemctl start k3s.service
即可恢复正常。
如果需要在安装时解决,解决办法如下:
- 使用 k3s-ansible 脚本,group_vars 额外再添加如下
--resolv-conf参数:extra_server_args: '--resolv-conf /run/dnsmasq/resolv.conf' - 使用 k3s 官方脚本:参考 K3s Server 配置参考 | Rancher 文档, 添加参数:
--resolv-conf /run/dnsmasq/resolv.conf或使用环境变量:K3S_RESOLV_CONF=/run/dnsmasq/resolv.conf
🎉🎉🎉
📚️参考文档
- DNS | Rancher 文档
- loop | CoreDNS Docs
- K3s Server 配置参考 | Rancher 文档
- Container networking | Docker Documentation
三人行, 必有我师; 知识共享, 天下为公. 本文由东风微鸣技术博客 EWhisper.cn 编写.
-
Fluss 写入数据湖实战12-23
-
揭秘 Fluss:下一代流存储,带你走在实时分析的前沿(一)12-22
-
DevOps与平台工程的区别和联系12-20
-
从信息孤岛到数字孪生:一本面向企业的数字化转型实用指南12-20
-
手把手教你轻松部署网站12-20
-
服务器购买课程:新手入门全攻略12-20
-
动态路由表学习:新手必读指南12-20
-
服务器购买学习:新手指南与实操教程12-20
-
动态路由表教程:新手入门指南12-20
-
服务器购买教程:新手必读指南12-20
-
动态路由表实战入门教程12-20
-
服务器购买实战:新手必读指南12-20
-
新手指南:轻松掌握服务器部署12-20
-
内网穿透入门指南:轻松实现远程访问12-20
-
网站部署入门教程12-20
