Kubernetes
有状态软件如何在 k8s 上快速扩容甚至自动扩容

概述
在传统的虚机/物理机环境里, 如果我们想要对一个有状态应用扩容, 我们需要做哪些步骤?
- 申请虚机/物理机
- 安装依赖
- 下载安装包
- 按规范配置主机名, hosts
- 配置网络: 包括域名, DNS, 虚 ip, 防火墙…
- 配置监控
今天虚机环境上出现了问题, 是因为 RabbitMQ 资源不足. 手动扩容的过程中花费了较长的时间.
但是在 K8S 上, 有状态应用的扩容就很简单, YAML 里改一下replicas副本数, 等不到 1min 就扩容完毕.
当然, 最基本的: 下镜像, 启动 pod(相当于上边的前 3 步), 就不必多提. 那么, 还有哪些因素, 让有状态应用可以在 k8s 上快速扩容甚至自动扩容呢?
原因就是这两点:
- peer discovery +peer discovery 的 相关实现(通过 hostname, dns, k8s api 或其他)
- 可观察性 + 自动伸缩
我们今天选择几个典型的有状态应用, 一一梳理下:
- Eureka
- Nacos
- Redis
- RabbitMQ
- Kafka
- TiDB
K8S 上有状态应用扩容
在 Kubernetes 上, 有状态应用快速扩容甚至自动扩容很容易. 这得益于 Kubernetes 优秀的设计以及良好的生态. Kubernetes 就像是一个云原生时代的操作系统. 它自身就具有:
- 自动化工具;
- 内部服务发现 + 负载均衡
- 内部 DNS
- 和 Prometheus 整合
- 统一的声明式 API
- 标准, 开源的生态环境.
所以, 需要扩容, 一个 yaml 搞定全部. 包括上边提到的: 下载, 安装, 存储配置, 节点发现, 加入集群, 监控配置…
Eureka 扩容

🔖 备注:
有状态扩容第一层:
StatefulSet + Headless Service
eureka 的扩容在 K8S 有状态应用中是最简单的, 就是:
headless service + statefulset
Eureka 要扩容, 只要 eureka 实例彼此能相互发现就可以. headless service 在这种情况下就派上用场了, 就是让彼此发现.
Eureka 的一个完整集群 yaml, 如下:详细说明如下:
apiVersion: v1
kind: Service
metadata:
name: eureka
namespace: ms
spec:
clusterIP: None
ports:
- name: eureka
port: 8888
selector:
project: ms
app: eureka
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: eureka
namespace: ms
spec:
serviceName: eureka
replicas: 3
selector:
matchLabels:
project: ms
app: eureka
template:
metadata:
labels:
project: ms
app: eureka
spec:
terminationGracePeriodSeconds: 10
imagePullSecrets:
- name: registry-pull-secret
containers:
- name: eureka
image: registry.example.com/kubernetes/eureka:latest
ports:
- protocol: TCP
containerPort: 8888
env:
- name: APP_NAME
value: "eureka"
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: APP_OPTS
value: "
--eureka.instance.hostname=${POD_NAME}.${APP_NAME}
--registerWithEureka=true
--fetchRegistry=true
--eureka.instance.preferIpAddress=false
--eureka.client.serviceUrl.defaultZone=http://eureka-0.${APP_NAME}:8888/eureka/,http://eureka-1.${APP_NAME}:8888/eureka/,http://eureka-2.${APP_NAME}:8888/eureka/
- 配置名为
eureka的 Service - 在名为
eureka的 statefulset 配置下,共 3 个 eureka 副本, 每个 eureka 的 HOSTNAME 为:${POD_NAME}.${SERVICE_NAME}. 如:eureka-0.eureka - 彼此通过
--registerWithEureka=true --fetchRegistry=true --eureka.instance.preferIpAddress=false --eureka.client.serviceUrl.defaultZone=http://eureka-0.${APP_NAME}:8888/eureka/,http://eureka-1.${APP_NAME}:8888/eureka/,http://eureka-2.${APP_NAME}:8888/eureka/通过 HOSTNAME 相互注册, 完成了集群的创建.
那么, 如果要快速扩容到 5 个:
- 调整 StatefulSet:
replicas: 5 - 在环境变量
APP_OPTS中加入新增的 2 个副本 hostname:http://eureka-3.${APP_NAME}:8888/eureka/,http://eureka-4.${APP_NAME}:8888/eureka/
即可完成.
Headless Service
有时不需要或不想要负载均衡,以及单独的 Service IP。 遇到这种情况,可以通过指定 Cluster IP(spec.clusterIP)的值为 None 来创建 Headless Service。
您可以使用无头 Service 与其他服务发现机制进行接口,而不必与 Kubernetes 的实现捆绑在一起。
对这无头 Service 并不会分配 Cluster IP,kube-proxy 不会处理它们, 而且平台也不会为它们进行负载均衡和路由。 DNS 如何实现自动配置,依赖于 Service 是否定义了选择算符。
Nacos

🔖 备注:
有状态扩容第二层:
StatefulSet + Headless Service + Init Container(自动化发现) + PVC
相比 Eureka, nacos 通过一个init container,(这个 init container, 就是一个自动化的 peer discovery 脚本.) , 实现了一行命令快速扩容:
kubectl scale sts nacos --replicas=3
脚本链接为: https://github.com/nacos-group/nacos-k8s/tree/master/plugin/peer
扩容的相关自动化操作为:
- 从 Headless Service 自动发现所有的 replicas 的 HOSTNAME;
- 并将 HOSTNAME 写入到:
${CLUSTER_CONF}这个文件下. ${CLUSTER_CONF}这个文件就是 nacos 集群的所有 member 信息. 将新写入 HOSTNAME 的实例加入到 nacos 集群中.
在这里, 通过 Headless Service 和 PV/PVC(存储 nacos 插件或其他数据),实现了对 Pod 的拓扑状态和存储状态的维护,从而让用户可以在 Kubernetes 上运行有状态的应用。
然而 Statefullset 只能提供受限的管理,通过 StatefulSet 我们还是需要编写复杂的脚本(如 nacos 的peer-finder相关脚本), 通过判断节点编号来区别节点的关系和拓扑,需要关心具体的部署工作。
RabbitMQ

🔖 备注:
有状态扩容第三层:
StatefulSet + Headless Service + 插件(自动化发现和监控) + PVC
RabbitMQ 的集群可以参考这边官方文档: Cluster Formation and Peer Discovery
这里提到的, 动态的发现机制需要依赖外部的服务, 如: DNS, API(AWS 或 K8S).
对于 Kubernetes, 使用的动态发现机制是基于**rabbitmq-peer-discovery-k8s插件** 实现的.
通过这种机制,节点可以使用一组配置的值从 Kubernetes API 端点获取其对等方的列表:URI 模式,主机,端口以及令牌和证书路径。
另外, rabbitmq 镜像也默认集成了监控的插件 - rabbitmq_prometheus.
当然, 通过Helm Chart也能一键部署和扩容.
Helm Chart
一句话概括, Helm 之于 Kubernetes, 相当于 yum 之于 centos. 解决了依赖的问题. 将部署 rabbitmq 这么复杂的软件所需要的一大堆 yaml, 通过参数化抽象出必要的参数(并且提供默认参数)来快速部署.
Redis

🔖 备注:
有状态扩容第四层:
通过 Operator 统一编排和管理:
Deployment(哨兵) + StatefulSet + Headless Service + Sidecar Container(监控) + PVC
这里以 UCloud 开源的: redis-operator 为例. 它是基于 哨兵模式 的 redis 集群.
于之前的 StatefulSet + Headless 不同, 这里用到了一项新的 K8S 技术: operator.
Operator 原理
📖 说明:
解释 Operator 不得不提 Kubernetes 中两个最具价值的理念:“声明式 API” 和 “控制器模式”。“声明式 API”的核心原理就是当用户向 Kubernetes 提交了一个 API 对象的描述之后,Kubernetes 会负责为你保证整个集群里各项资源的状态,都与你的 API 对象描述的需求相一致。Kubernetes 通过启动一种叫做“控制器模式”的无限循环,WATCH 这些 API 对象的变化,不断检查,然后调谐,最后确保整个集群的状态与这个 API 对象的描述一致。
比如 Kubernetes 自带的控制器:Deployment,如果我们想在 Kubernetes 中部署双副本的 Nginx 服务,那么我们就定义一个 repicas 为 2 的 Deployment 对象,Deployment 控制器 WATCH 到我们的对象后,通过控制循环,最终会帮我们在 Kubernetes 启动两个 Pod。
Operator 是同样的道理,以我们的 Redis Operator 为例,为了实现 Operator,我们首先需要将自定义对象的说明注册到 Kubernetes 中,这个对象的说明就叫 CustomResourceDefinition(CRD),它用于描述我们 Operator 控制的应用:redis 集群,这一步是为了让 Kubernetes 能够认识我们应用。然后需要实现自定义控制器去 WATCH 用户提交的 redis 集群实例,这样当用户告诉 Kubernetes 我想要一个 redis 集群实例后,Redis Operator 就能够通过控制循环执行调谐逻辑达到用户定义状态。
简单说, operator 可以翻译为: 运维人(操作员) . 就是将高级原厂运维专家多年的经验, 浓缩为一个: operator. 那么, 我们所有的 运维打工人 就不需要再苦哈哈的"从零开始搭建 xxx 集群", 而是通过这个可扩展、可重复、标准化、甚至全生命周期运维管理的operator。 来完成复杂软件的安装,扩容,监控, 备份甚至故障恢复。
Redis Operator
使用 Redis Operator 我们可以很方便的起一个哨兵模式的集群,集群只有一个 Master 节点,多个 Slave 节点,假如指定 Redis 集群的 size 为 3,那么 Redis Operator 就会帮我们启动一个 Master 节点,两个 Salve 节点,同时启动三个 Sentinel 节点来管理 Redis 集群:
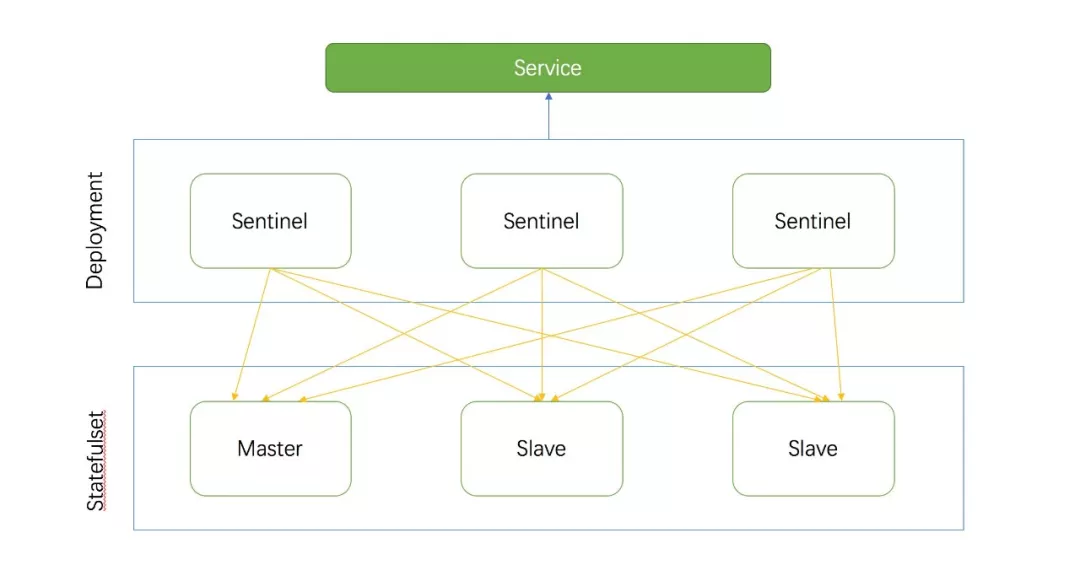
Redis Operator 通过 Statefulset 管理 Redis 节点,通过 Deployment 来管理 Sentinel 节点,这比管理裸 Pod 要容易,节省实现成本。同时创建一个 Service 指向所有的哨兵节点,通过 Service 对客户端提供查询 Master、Slave 节点的服务。最终,Redis Operator 控制循环会调谐集群的状态,设置集群的拓扑,让所有的 Sentinel 监控同一个 Master 节点,监控相同的 Salve 节点,Redis Operator 除了会 WATCH 实例的创建、更新、删除事件,还会定时检测已有的集群的健康状态,实时把集群的状态记录到 spec.status.conditions 中.
同时, 还提供了快速持久化, 监控, 自动化 redis 集群配置的能力. 只需一个 yaml 即可实现:
apiVersion: redis.kun/v1beta1
kind: RedisCluster
metadata:
name: redis
spec:
config: # redis集群配置
maxmemory: 1gb
maxmemory-policy: allkeys-lru
password: sfdfghc56s # redis密码配置
resources: # redis资源配置
limits:
cpu: '1'
memory: 1536Mi
requests:
cpu: 250m
memory: 1Gi
size: 3 # redis副本数配置
storage: # 持久化存储配置
keepAfterDeletion: true
persistentVolumeClaim:
metadata:
name: redis
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: nfs
volumeMode: Filesystem
sentinel: # 哨兵配置
image: 'redis:5.0.4-alpine'
exporter: # 启用监控
enabled: true
要扩容也很简单, 将上边的size: 3按需调整即可. 调整后, 自动申请资源, 扩容, 加存储, 改 redis 配置, 加入 redis 集群, 并且自动添加监控.
Kafka

🔖 备注:
有状态扩容第五层:
通过 Operator 统一编排和管理多个有状态组件的:
StatefulSet + Headless Service + … + 监控
这里以 Strimzi 为例 - Strimzi Overview guide (0.20.0). 这是一个 Kafka 的 Operator.
提供了 Apache Kafka 组件以通过 Strimzi 发行版部署到 Kubernetes。 Kafka 组件通常以集群的形式运行以提高可用性。
包含 Kafka 组件的典型部署可能包括:
- Kafka 代理节点集群集群
- ZooKeeper - ZooKeeper 实例的集群
- Kafka Connect 集群用于外部数据连接
- Kafka MirrorMaker 集群可在第二个集群中镜像 Kafka 集群
- Kafka Exporter 提取其他 Kafka 指标数据以进行监控
- Kafka Bridge 向 Kafka 集群发出基于 HTTP 的请求
Kafka 的组件架构比较复杂, 具体如下:
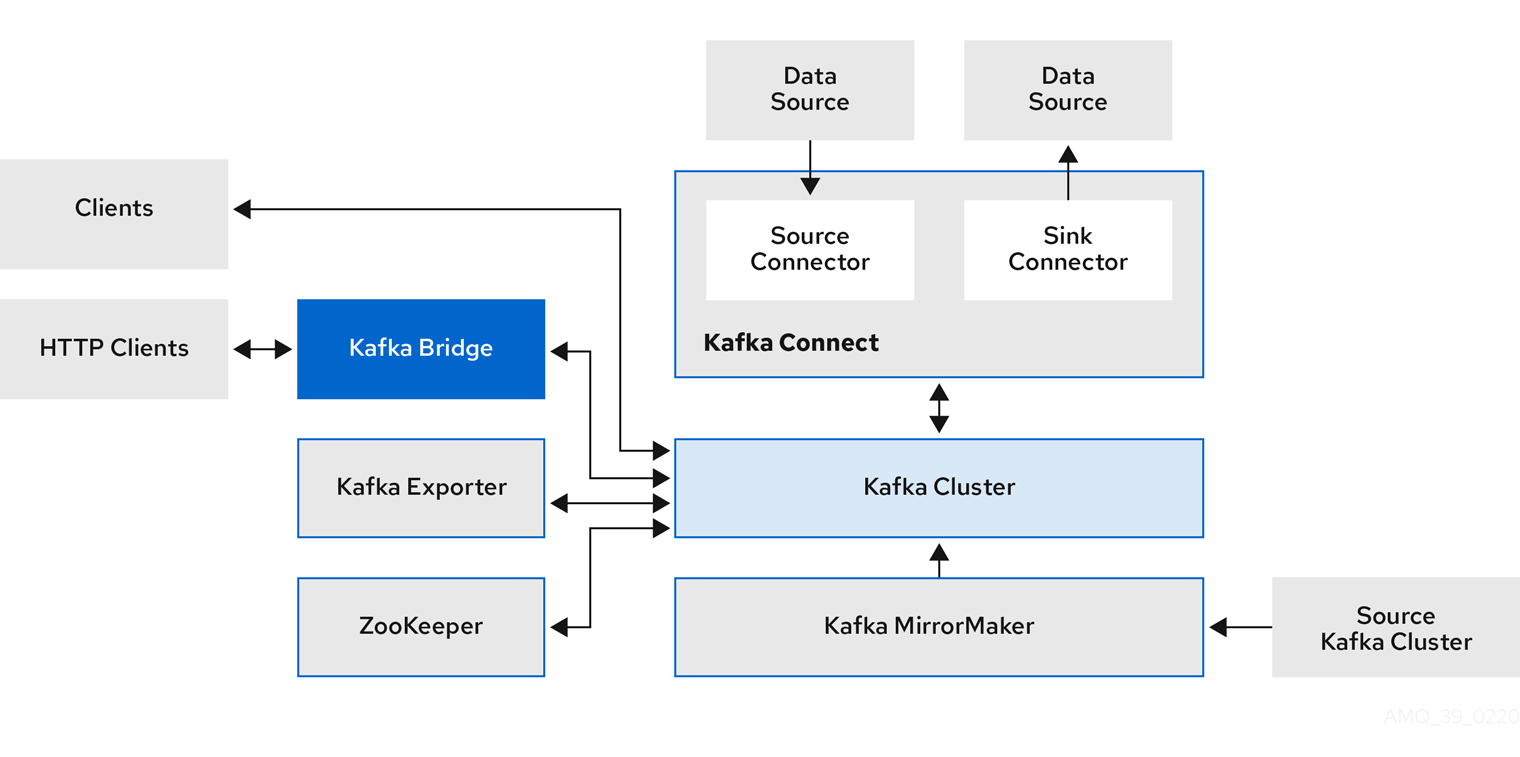
通过 Operator, 一个 YAML 即可完成一套复杂的部署:
- 资源请求(CPU /内存)
- 用于最大和最小内存分配的 JVM 选项
- Listeners (和身份验证)
- 认证
- 存储
- Rack awareness
- 监控指标
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
replicas: 3
version: 0.20.0
resources:
requests:
memory: 64Gi
cpu: "8"
limits:
memory: 64Gi
cpu: "12"
jvmOptions:
-Xms: 8192m
-Xmx: 8192m
listeners:
- name: plain
port: 9092
type: internal
tls: false
useServiceDnsDomain: true
- name: tls
port: 9093
type: internal
tls: true
authentication:
type: tls
- name: external
port: 9094
type: route
tls: true
configuration:
brokerCertChainAndKey:
secretName: my-secret
certificate: my-certificate.crt
key: my-key.key
authorization:
type: simple
config:
auto.create.topics.enable: "false"
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 2
ssl.cipher.suites: "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384" (17)
ssl.enabled.protocols: "TLSv1.2"
ssl.protocol: "TLSv1.2"
storage:
type: persistent-claim
size: 10000Gi
rack:
topologyKey: topology.kubernetes.io/zone
metrics:
lowercaseOutputName: true
rules:
# Special cases and very specific rules
- pattern : kafka.server<type=(.+), name=(.+), clientId=(.+), topic=(.+), partition=(.*)><>Value
name: kafka_server_$1_$2
type: GAUGE
labels:
clientId: "$3"
topic: "$4"
partition: "$5"
# ...
zookeeper:
replicas: 3
resources:
requests:
memory: 8Gi
cpu: "2"
limits:
memory: 8Gi
cpu: "2"
jvmOptions:
-Xms: 4096m
-Xmx: 4096m
storage:
type: persistent-claim
size: 1000Gi
metrics:
# ...
entityOperator:
topicOperator:
resources:
requests:
memory: 512Mi
cpu: "1"
limits:
memory: 512Mi
cpu: "1"
userOperator:
resources:
requests:
memory: 512Mi
cpu: "1"
limits:
memory: 512Mi
cpu: "1"
kafkaExporter:
# ...
cruiseControl:
# ...
当然, 由于 Kafka 的特殊性, 如果要将新增的 brokers 添加到现有集群, 还需要重新分区, 这里边涉及的更多操作详见: Scaling Clusters - Using Strimzi
TiDB

🔖 备注:
有状态扩容第六层:
通过 Operator 统一编排和管理多个有状态组件的:
StatefulSet + Headless Service + … + 监控 + TidbClusterAutoScaler(类似 HPA 的实现)
甚至能做到备份和灾难恢复.
TiDB 更进一步, 可以实现 有状态应用自动扩容.
具体见这里: Enable TidbCluster Auto-scaling | PingCAP Docs
Kubernetes 提供了Horizontal Pod Autoscaler ,这是一种基于 CPU 利用率的原生 API。 TiDB 4.0 基于 Kubernetes,实现了弹性调度机制。
只需要启用此功能即可使用:
features: - AutoScaling=true
TiDB 实现了一个TidbClusterAutoScaler CR 对象用于控制 TiDB 集群中自动缩放的行为。 如果您使用过Horizontal Pod Autoscaler ,大概是您熟悉 TidbClusterAutoScaler 概念。 以下是 TiKV 中的自动缩放示例。
apiVersion: pingcap.com/v1alpha1
kind: TidbClusterAutoScaler
metadata:
name: auto-scaling-demo
spec:
cluster:
name: auto-scaling-demo
namespace: default
monitor:
name: auto-scaling-demo
namespace: default
tikv:
minReplicas: 3
maxReplicas: 4
metrics:
- type: "Resource"
resource:
name: "cpu"
target:
type: "Utilization"
averageUtilization: 80
需要指出的是: 需要向TidbClusterAutoScaler 提供指标收集和查询(监控)服务,因为它通过指标收集组件捕获资源使用情况。 monitor 属性引用TidbMonitor 对象(其实就是自动化地配置 TiDB 的 prometheus 监控和展示等)。 有关更多信息,请参见**使用TidbMonitor监视TiDB群集**。
总结
通过 6 个有状态软件, 我们见识到了层层递进的 K8S 上有状态应用的快速扩容甚至是自动扩容:
- 最简单实现: StatefulSet + Headless Service – Eureka
- 脚本/Init Container 自动化实现: StatefulSet + Headless Service + Init Container(自动化发现) + PVC – Nacos
- 通过插件实现扩容和监控:StatefulSet + Headless Service + 插件(自动化发现和监控) + PVC – RabbitMQ
- 通过 Operator 统一编排和管理: – Redis
- 对于复杂有状态, 是需要通过 Operator 统一编排和管理多个有状态组件的: – Kafka
- 通过 Operator 统一编排和管理多个有状态组件的: – TiDB
😂😂😂 解放开发和运维打工人, 是时候在 K8S 上部署有状态软件了! 💪💪💪
三人行, 必有我师; 知识共享, 天下为公. 本文由东风微鸣技术博客 EWhisper.cn 编写.
-
云原生周刊:利用 eBPF 增强 K8s12-23
-
/kubernetes 1.32版本更新解读:新特性和变化一目了然12-20
-
拒绝 Helm? 如何在 K8s 上部署 KRaft 模式 Kafka 集群?12-19
-
云原生周刊:Kubernetes v1.32 正式发布12-16
-
Kubernetes上运行Minecraft:打造开发者平台的例子12-13
-
深入 Kubernetes 的健康奥秘:探针(Probe)究竟有多强?12-12
-
运维实战:K8s 上的 Doris 高可用集群最佳实践12-10
-
2024年最好用的十大Kubernetes工具12-02
-
OPA守门人:Kubernetes集群策略编写指南12-02
-
云原生周刊:K8s 严重漏洞11-26
-
在Kubernetes (k8s) 中搭建三台 Nginx 服务器怎么实现?-icode9专业技术文章分享11-15
-
基于Kubernetes的自定义AWS云平台搭建指南11-05
-
基于Kubernetes Gateway API的现代流量管理方案11-05
-
在Kubernetes上部署你的第一个应用:Nginx服务器11-05
-
利用拓扑感知路由控制Kubernetes中的流量11-05
