Java教程
Prometheus Operator与kube-prometheus之二-如何监控1.23+ kubeadm集群

简介
- 系列文章: 标签 - Prometheus - 东风微鸣技术博客 (ewhisper.cn)
- Prometheus Operator 的上一篇: Prometheus Operator 与 kube-prometheus 之一 - 简介 - 东风微鸣技术博客 (ewhisper.cn)
kube-prometheus-stack捆绑了监控Kubernetes 集群所需的Prometheus Operator、Exporter、Rule、Grafana 和 AlertManager。
但要为使用kubeadm构建的Kubernetes集群定制Helm安装,还是有必要进行定制。
这一次结合近期比较新的 Kubernetes 版本 v1.23+, 以及较为常见的安装方式 kubeadm, 来实战说明:
- kubeadm 需要哪些特殊配置
- 如何安装 Prometheus Operator: 通过 kube-prometheus-stack helm chart
- 如何配置对 kubeadm 安装的集群的组件监控
开始!
前提条件
- kubeadm
- helm3
kubeadm 需要哪些特殊配置
为了后面能够正常通过 Prometheus Operator 获取到 kubeadm 搭建的 Kubernetes v1.23+ 集群的指标, 需要对 kubeadm 做一些特殊配置.
默认情况下,kubeadm将它的几个管理组件绑定到 node 的 localhost 127.0.0.1 地址上, 涉及到: Kube Controller Manager、Kube Proxy和Kube Scheduler。
然而,对于监控来说,我们需要这些端点的暴露,以便他们的指标可以被Prometheus提取。因此,我们需要将这些组件暴露在他们的 0.0.0.0 地址上。
当登录到kubeadm主节点时,运行以下修改:
Controller Manager 和 Scheduler 组件
默认情况下,kubeadm 并没有公开我们要监控的两个服务(kube-controller-manager 和 kube-scheduler)。因此,为了充分利用kube-prometheus-stack helm chart,我们需要对Kubernetes集群做一些快速调整。后面我们会监控kube-controller-manager和kube-scheduler,我们必须将它们的地址端口暴露给集群。
默认情况下,kubeadm 在你的主机上运行这些 pod,并绑定到 127.0.0.1。有几种方法可以改变这一点。建议改变这些配置的方法是使用 kubeadm config file。下面是配置示例:
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
...
controllerManager:
extraArgs:
bind-address: "0.0.0.0"
scheduler:
extraArgs:
bind-address: "0.0.0.0"
...
kubernetesVersion: "v1.23.1"
...
🐾上面的 .scheduler.extraArgs 和 .controllerManager.extraArgs。这样就把 kube-controller-manager 和 kube-scheduler 服务暴露给集群的其他组件。
另外, 如果你把 kubernetes 核心组件作为pods放在 kube-system namespace,就要确保kube-prometheus-exporter-kube-scheduler 和 kube-prometheus-exporter-kube-controller-manager service (这 2 个 service 是 kube-prometheus-stack 创建出来用于 Prometheus Operator 通过 ServiceMonitor 监控这两个组件用的)的spec.selector 值与pods的值一致。
如果你已经有一个部署了 kubeadm 的Kubernetes,可以直接 kube-controller-manager 和 kube-scheduler 的监听地址:
sed -e "s/- --bind-address=127.0.0.1/- --bind-address=0.0.0.0/" -i /etc/kubernetes/manifests/kube-controller-manager.yaml sed -e "s/- --bind-address=127.0.0.1/- --bind-address=0.0.0.0/" -i /etc/kubernetes/manifests/kube-scheduler.yaml
Kube Proxy 组件
📝Notes:
一般情况下, kube-proxy 总是绑定所有地址的, 但是对应的metricsBindAddress可能并不一定会follow 配置. 具体如下面的"改动前"
对于 Kube Proxy 组件, 在使用 kubeadm 安装完成之后, 需要修改 kube-system 下的 configmap kube-proxy 的 metricsBindAddress.
改动如下:
改动前:
... kind: KubeProxyConfiguration bindAddress: 0.0.0.0 metricsBindAddress: 127.0.0.1:10249 ...
改动后:
kind: KubeProxyConfiguration bindAddress: 0.0.0.0 metricsBindAddress: 0.0.0.0:10249
并重启:
kubectl -n kube-system rollout restart daemonset/kube-proxy
Etcd 配置
Etcd 配置, 这里就不详细说明了, 可以直接参见: Prometheus Operator 监控 etcd 集群-阳明的博客
但是上面链接提到的方法比较麻烦, 推荐一个更简单的: 可以在 etcd 的配置中加上监听 Metrics URL 的flag:
# 在 etcd 所在的机器上 master_ip=192.168.1.5 sed -i "s#--listen-metrics-urls=.*#--listen-metrics-urls=http://127.0.0.1:2381,http://$master_ip:2381#" /etc/kubernetes/manifests/etcd.yaml
验证 kubeadm 配置
小结一下, 通过之前的这些配置, Kubernetes 组件的 Metrics 监听端口分别为:
- Controller Manager: (Kubernetes v1.23+)
- 端口: 10257
- 协议: https
- Scheduler: (Kubernetes v1.23+)
- 端口: 10259
- 协议: https
- Kube Proxy
- 端口: 10249
- 协议: http
- etcd
- 端口: 2381
- 协议: http
可以通过 netstat 命令查看之前的配置是否全部生效:
在 master 和 etcd node 上执行:
$ sudo netstat -tulnp | grep -e 10257 -e 10259 -e 10249 -e 2381 tcp 0 0 192.168.1.5:2381 0.0.0.0:* LISTEN 1400/etcd tcp 0 0 127.0.0.1:2381 0.0.0.0:* LISTEN 1400/etcd tcp6 0 0 :::10257 :::* LISTEN 1434/kube-controlle tcp6 0 0 :::10259 :::* LISTEN 1486/kube-scheduler tcp6 0 0 :::10249 :::* LISTEN 4377/kube-proxy # 测试etcd指标 curl -k http://localhost:2381/metrics # 测试 kube-proxy 指标 curl -k http://localhost:10249/metrics
通过 kube-prometheus-stack 安装并定制 helm values
这里直接完成上面提到的 2 步:
- 如何安装 Prometheus Operator: 通过 kube-prometheus-stack helm chart
- 如何配置对 kubeadm 安装的集群的组件监控
在我们用 Helm 安装kube-prometheus-stack之前,我们需要创建一个values.yaml来调整kubeadm 集群的默认 chart value。
为 Prometheus 和 AlertManager 配置持久化存储
推荐要为 Prometheus 和 AlertManager 配置持久化存储, 而不要直接使用 emptyDir.
存储具体如何配置根据您的集群的实际情况来, 这边就不做过多介绍.
- Prometheus 的配置改这里
- AlertManager 的配置改这里
etcd 相关配置
Kubeadm etcd 监控的端口是 2381(而不是Helm chart中指定的默认值: 2379)],所以我们需要明确覆盖这个值。
kubeEtcd:
enabled: true
service:
enabled: true
port: 2381
targetPort: 2381
Controller Manger 相关配置
这里不需要做太多配置, 关于 https 和 端口, 如果相关 key 为空或未设置,该值将根据目标Kubernetes 版本动态确定,原因是默认端口在Kubernetes 1.22中的变化。注意下面的: .kubeControllerManager.service.port 和 .kubeControllerManager.service.targetPort 以及 .kubeControllerManager.serviceMonitor.https 和 .kubeControllerManager.serviceMonitor.insecureSkipVerify.
如果配置后监控抓不到或有异常, 可以按实际情况调整.
kubeControllerManager:
enabled: true
...
service:
enabled: true
port: null
targetPort: null
serviceMonitor:
enabled: true
...
https: null
insecureSkipVerify: null
...
Kubernetes Scheduler
同上, 这里不需要做太多配置, 关于 https 和 端口, 如果相关 key 为空或未设置,该值将根据目标Kubernetes 版本动态确定,原因是默认端口在Kubernetes 1.23中的变化。注意下面的: .kubeScheduler.service.port 和 .kubeScheduler.service.targetPort 以及 .kubeScheduler.serviceMonitor.https 和 .kubeScheduler.serviceMonitor.insecureSkipVerify.
如果配置后监控抓不到或有异常, 可以按实际情况调整.
kubeScheduler:
enabled: true
...
service:
enabled: true
port: 10259
targetPort: 10259
serviceMonitor:
enabled: true
...
https: true
insecureSkipVerify: true
...
Kubernetes Proxy
也是如此, 根据 是否 https 和 端口进行调整, 如下:
kubeProxy:
enabled: true
endpoints: []
service:
enabled: true
port: 10249
targetPort: 10249
serviceMonitor:
enabled: true
...
https: false
...
通过 Helm 安装 kube-prometheus-stack
添加 Helm 仓库:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm repo list helm repo update prometheus-community
安装:
helm upgrade --install \ --namespace prom \ --create-namespace \ -f values.yaml \ monitor prometheus-community/kube-prometheus-stack
验证
这里主要验证 kubeadm 的 Kubernetes 组件有没有正常监控到, 可以通过 Prometheus UI 或 Grafana UI 直接查看进行验证.
可以通过 Ingress 或 NodePort 将 Prometheus UI 或 Grafana UI 地址暴露出去, 然后访问:
Status -> Targets 查看监控状态, 这里举几个组件来进行说明:
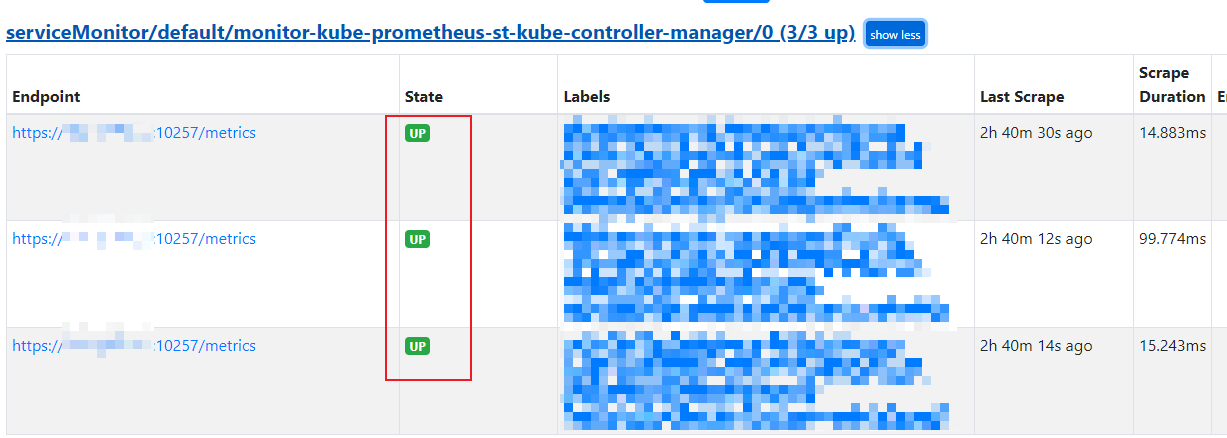
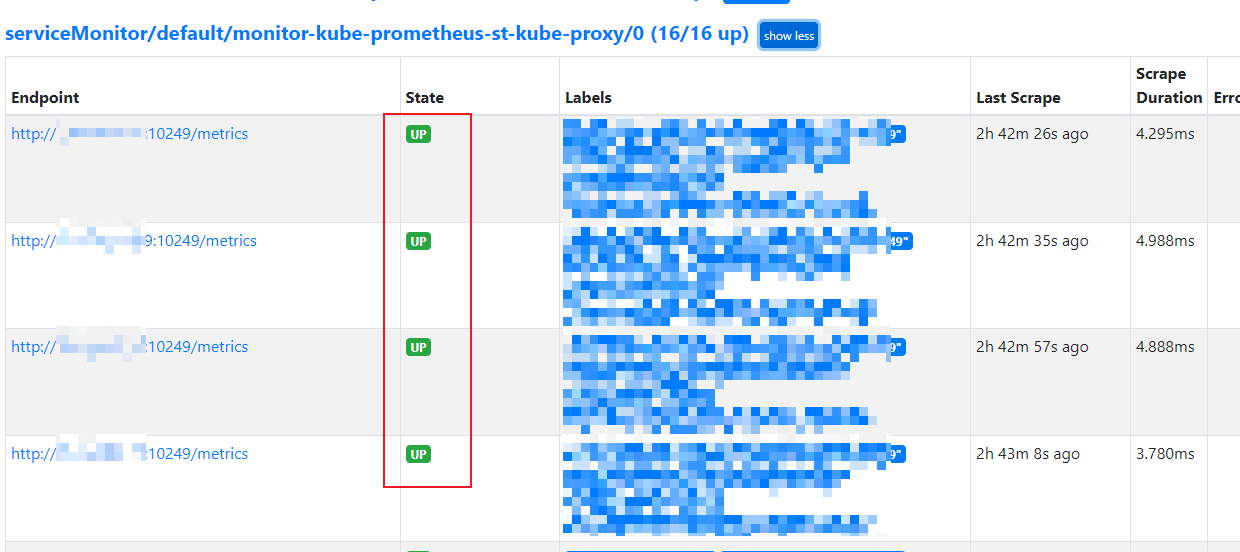
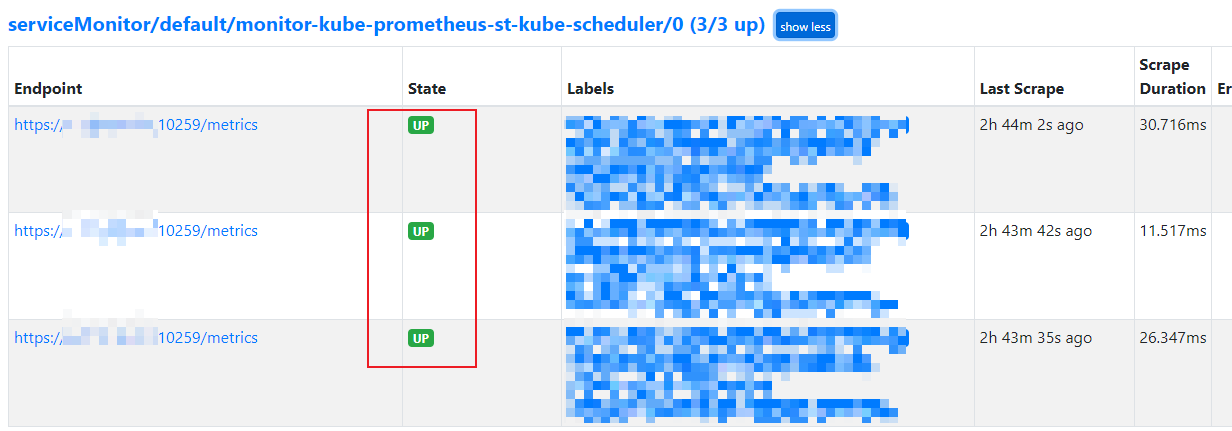
Grafana 可以直接登录后查看对应的仪表板, 如下图:
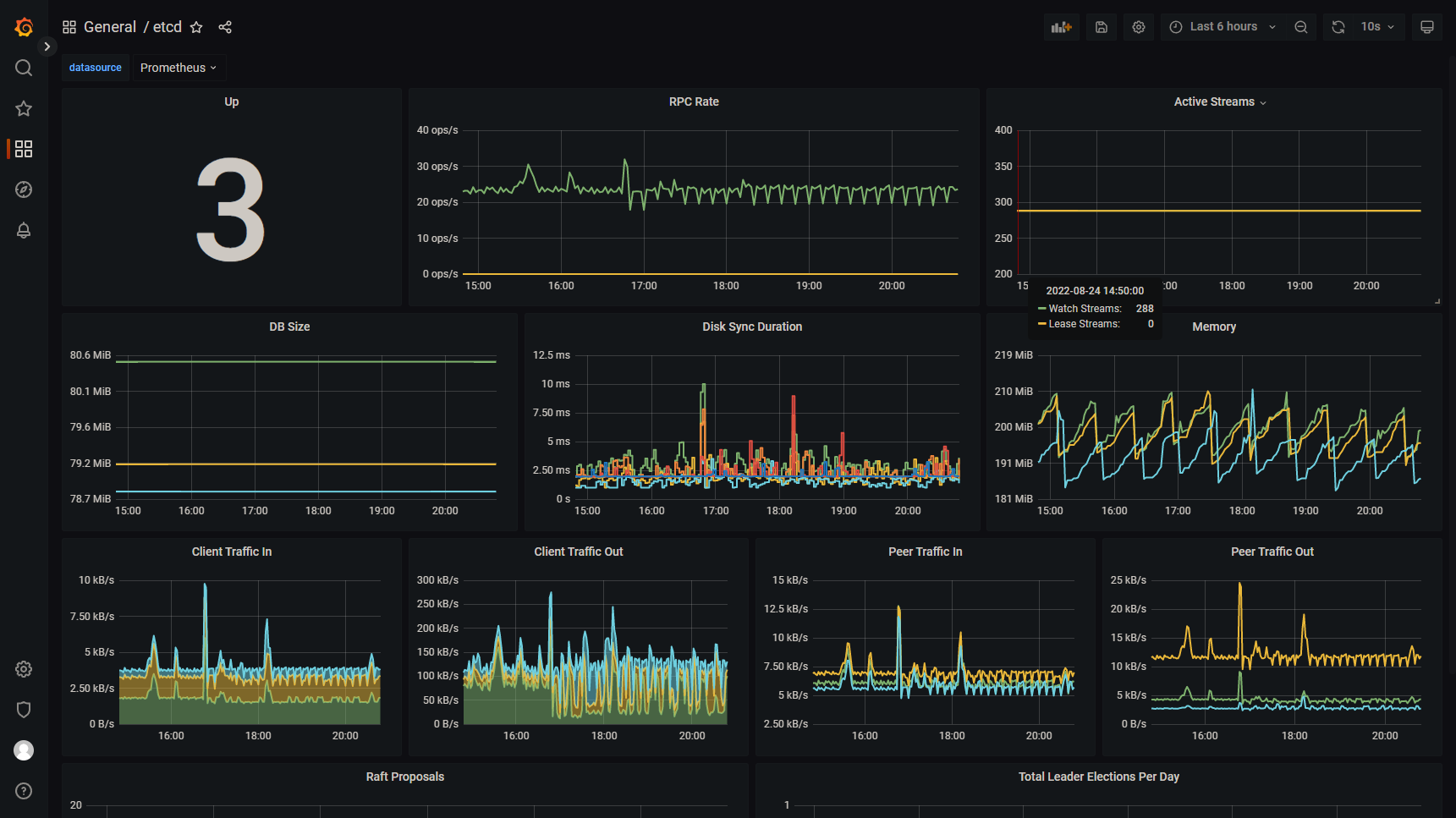
🎉🎉🎉
-
JavaMailSender是什么,怎么使用?-icode9专业技术文章分享11-15
-
JWT 用户校验学习:从入门到实践11-15
-
Nest学习:新手入门全面指南11-15
-
RestfulAPI学习:新手入门指南11-15
-
Server Component学习:入门教程与实践指南11-15
-
动态路由入门:新手必读指南11-15
-
JWT 用户校验入门:轻松掌握JWT认证基础11-15
-
Nest后端开发入门指南11-15
-
Nest后端开发入门教程11-15
-
RestfulAPI入门:新手快速上手指南11-15
-
Server Action入门:新手必读教程11-15
-
Server Component入门:新手必读教程11-15
-
抽离公共代码教程:简单易懂的入门指南11-15
-
动态路由教程:轻松入门与实战指南11-15
-
Restful API教程:入门与实践指南11-15
