云计算
你还在用递归遍历目录吗?ForkJoin线程池代替传统递归遍历目录!大数据场景大量小文件磁盘IO优化方案

本文主要是介绍你还在用递归遍历目录吗?ForkJoin线程池代替传统递归遍历目录!大数据场景大量小文件磁盘IO优化方案,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
本文主要总结下工作中遇到的forkjoin线程池的使用场景,对大量小文件的磁盘IO优化
工作使用场景描述
公司大数据部服务器存有海量非结构化数据,文件格式是xml,量级千万级,需要编写java程序解析xml,单个文件只有几百KB到几MB ,j使用传统的递归逻辑遍历磁盘目录时文件处理速度非常慢,后选择使用forkjoin进行了速度上的优化。
ForkJoin线程池的概念
关于forkjoin线程池的概念,此处不再一一赘述,其他博客已经写的很清楚了,主要是任务的拆分,即大的任务会被划分成小的任务,还有是工作窃取。
直接上干货:ForkJoin和传统递归的运行结果对比
现在分别用递归和forkjoin对目录 C:/Windows遍历,文件操作为打印路径,对比两种方法的结果。
传统递归代码
import java.io.File;
import java.util.concurrent.atomic.AtomicLong;
public class DiguiTest {
private static AtomicLong counter = new AtomicLong(0L);
public static void main(String[] args) {
long start = System.currentTimeMillis();
digui(new File("C:/Windows"));
System.out.println("花费:"+(System.currentTimeMillis()-start)/1000.0+"秒");
}
private static void digui(File file) {
if (file != null) {
if (file.isDirectory()) {
File[] files = file.listFiles();
if (files!=null)
for (File son :files) {
digui(son);
}
} else {
System.out.println(counter.incrementAndGet()+"==>"+file.getAbsolutePath());
}
}
}
}
ForkJoin代码
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
public class Test {
private static AtomicLong counter = new AtomicLong(0L);
public static void main(String[] args) throws InterruptedException {
long start = System.currentTimeMillis();
ForkJoinPool forkjoinPool = new ForkJoinPool(6);
File file = new File("C:/Windows");
MyTask task = new MyTask(file);
forkjoinPool.invoke(task);
// 停止接收任务
forkjoinPool.shutdown();
//等待任务执行结束
forkjoinPool.awaitTermination(2, TimeUnit.SECONDS);
System.out.println("花费:" + (System.currentTimeMillis() - start) / 1000.0 + "秒");
}
public static class MyTask extends RecursiveAction {
private File path; // 当前要搜索的目录
public MyTask(File path) {
this.path = path;
}
@Override
protected void compute() {
try {
// 定义一个文件目录集合
List<MyTask> subTasks = new ArrayList<>();
// 根据当前要搜索目录的,找到所有的文件
File[] files = path.listFiles();
// 判断是否为空,不为空则继续往下搜索
if (null != files) {
for (File file : files) {
// 判断是否是目录
if (file.isDirectory()) {
subTasks.add(new MyTask(file));
// System.out.println(" 目录: " + file.getAbsolutePath());
} else {
// 判断不是目录,则是文件
// todo 处理文件 此处打印
System.out.println(counter.incrementAndGet() + "==>" + file.getAbsolutePath());
}
}
// 判断集合是否为空
if (null != subTasks && subTasks.size() > 0) {
for (MyTask subTask : invokeAll(subTasks)) {
// 等待子任务完成
subTask.join();
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
两者结果对比
运行时间对比
forkjoin运行结果:
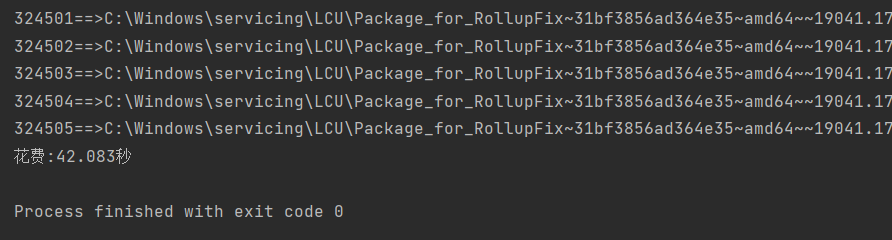
传统递归运行结果
磁盘IO对比
forkjoin运行IO:

传统递归运行IO:

结论
可见forkjoin线程池在处理大量小文件时,遍历目录比传统递归要快很多.
注意: forkjoin线程池的线程数并不是越大速度越快。
ForkJoin有返回值
上述的forkjoin示例是无返回,只需要打印下文件路径,并不需要子目录对上层目录传递计算结果。
新的需求: 遍历目录 C:/Windows, 将所有文件路径保存到mysql的一张表中,为了提高写入效率,每1000条路径作为一个批次,写入mysql。
ForkJoin有返回值代码
RecursiveTask后的泛型是返回值类型
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
public class Main {
private static AtomicLong counter = new AtomicLong(0L);
public static void main(String[] args) throws InterruptedException {
ForkJoinPool forkjoinPool = new ForkJoinPool(8);
File file = new File("C:/Windows");
Task task = new Task(file);
List<String> list = forkjoinPool.invoke(task);
forkjoinPool.awaitTermination(2, TimeUnit.SECONDS);//阻塞当前线程直到 ForkJoinPool 中所有的任务都执行结束
// 关闭线程池
forkjoinPool.shutdown();
// todo 缓存中不足1000条的剩余数据处理, 此处写入mysql逻辑省略
System.out.println(counter.addAndGet(list.size()));
}
private static class Task extends RecursiveTask<List<String>> {
private File file;
public Task(File file) {
this.file = file;
}
@Override
protected List<String> compute() {
List<String> buffer = new ArrayList<>();
if (file != null) {
if (file.isDirectory()) {
File[] sons = file.listFiles();
if (sons != null && sons.length > 0) {
for (File son : sons) {
Task task = new Task(son);
invokeAll(task);
List<String> join = task.join();
buffer.addAll(join);
if (buffer.size() > 1000) {
// todo 缓存批处理, 写入mysql逻辑省略
System.out.println(counter.addAndGet(buffer.size()));
buffer.clear();
}
}
}
} else {
buffer.add(file.getAbsolutePath());
// counter.incrementAndGet();
}
}
return buffer;
}
}
}
运行结果
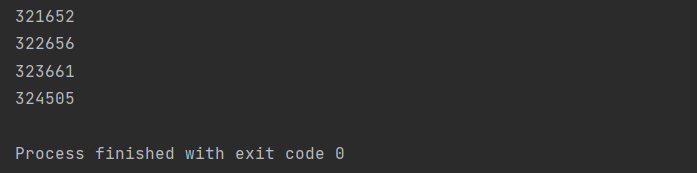
可见,ForkJoin有返回值的批处理和无返回值的处理数据条数相同。
这篇关于你还在用递归遍历目录吗?ForkJoin线程池代替传统递归遍历目录!大数据场景大量小文件磁盘IO优化方案的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
您可能喜欢
-
Fluss 写入数据湖实战12-23
-
揭秘 Fluss:下一代流存储,带你走在实时分析的前沿(一)12-22
-
DevOps与平台工程的区别和联系12-20
-
从信息孤岛到数字孪生:一本面向企业的数字化转型实用指南12-20
-
手把手教你轻松部署网站12-20
-
服务器购买课程:新手入门全攻略12-20
-
动态路由表学习:新手必读指南12-20
-
服务器购买学习:新手指南与实操教程12-20
-
动态路由表教程:新手入门指南12-20
-
服务器购买教程:新手必读指南12-20
-
动态路由表实战入门教程12-20
-
服务器购买实战:新手必读指南12-20
-
新手指南:轻松掌握服务器部署12-20
-
内网穿透入门指南:轻松实现远程访问12-20
-
网站部署入门教程12-20
栏目导航
